问题描述
在使用服务器多核跑程序的时候,需要把核心的程序抽取出来,然后提供迭代参数。然后就可以使用多核去跑程序了。但是在执行的过程中报错如下:
Exception has occurred: TypeError
unhashable type: 'list'
File "/home/LIST_2080Ti/njh/CHB-MIT-DATA/epilepsy_eeg_classification/preprocessing.py", line 396, in <module> p.map(data_pro, namelista) TypeError: unhashable type: 'list'

解决方案
我把上面的namelist转换为tuple也不行,仍旧是如上报错。
转换语句为:
namelista = tuple(namelist)并且也测试了类型,但是,就是报相同的错。
搞了几个小时都不行。
昨天弄到凌晨五点半都没弄好。
但是,今天下午一过来,仔细检查了程序,发现,原来我的程序中还有其它的没有转换为tuple的list。
你仔细检查会发现,一旦需要送入到处理器去,就需要把所有相关的list都转换为tuple才行。否则仍旧会报一样的错。
从昨天的晕头转向到今天的一句程序搞定,真的是颇有戏剧性。增加的就是这么一句。
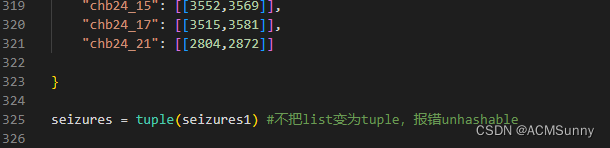
前面声明的数据是list类型,仍旧需要变换为tuple,否则会报错。但是这次报错不会直接指示到这里,只会定位到这一句。
p.map(data_pro, namelista)然后程序就跑起来了。%CPU一栏就是使用的核数。这是用了15核,防止用的太多,别人没得用,毕竟服务器不是自己一个人的。一个核就是100%,15核,就是1500%。
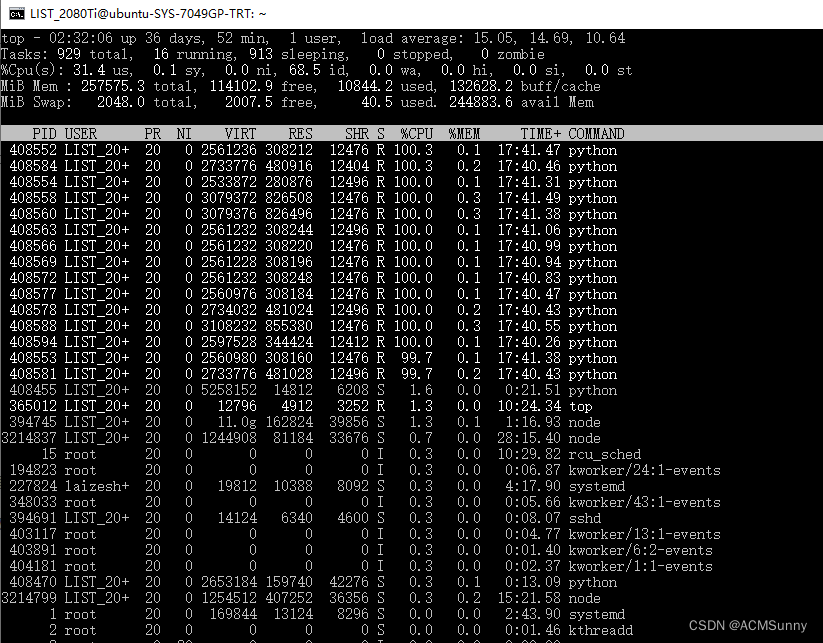
使用top就可查看服务器的使用情况。
top下面的主要参数是第三行%Cpu(s) 第一个us项目是使用的CPU占总CPU的比例,第四个id是剩余的CPU占比。在没有使用这个多核程序的时候,我的id能达到97.9%。现在这说明已经成功的用上了多核。
想要知道电脑的核数。所以我的电脑就是1个物理CPU,2核3线程(逻辑CPU)。
核数
(cat) C:\Users\asus>cat /proc/cpuinfo| grep "cpu cores"| uniq
cpu cores : 2
物理CPU数
(cat) C:\Users\asus>cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
1
逻辑CPU数
(cat) C:\Users\asus>cat /proc/cpuinfo| grep "processor"| wc -l
3更linux相关的命令看这个:linux服务器信息查询命令_ACMSunny的博客-CSDN博客
想看使用多核与单核跑程序的区别,看这个图:
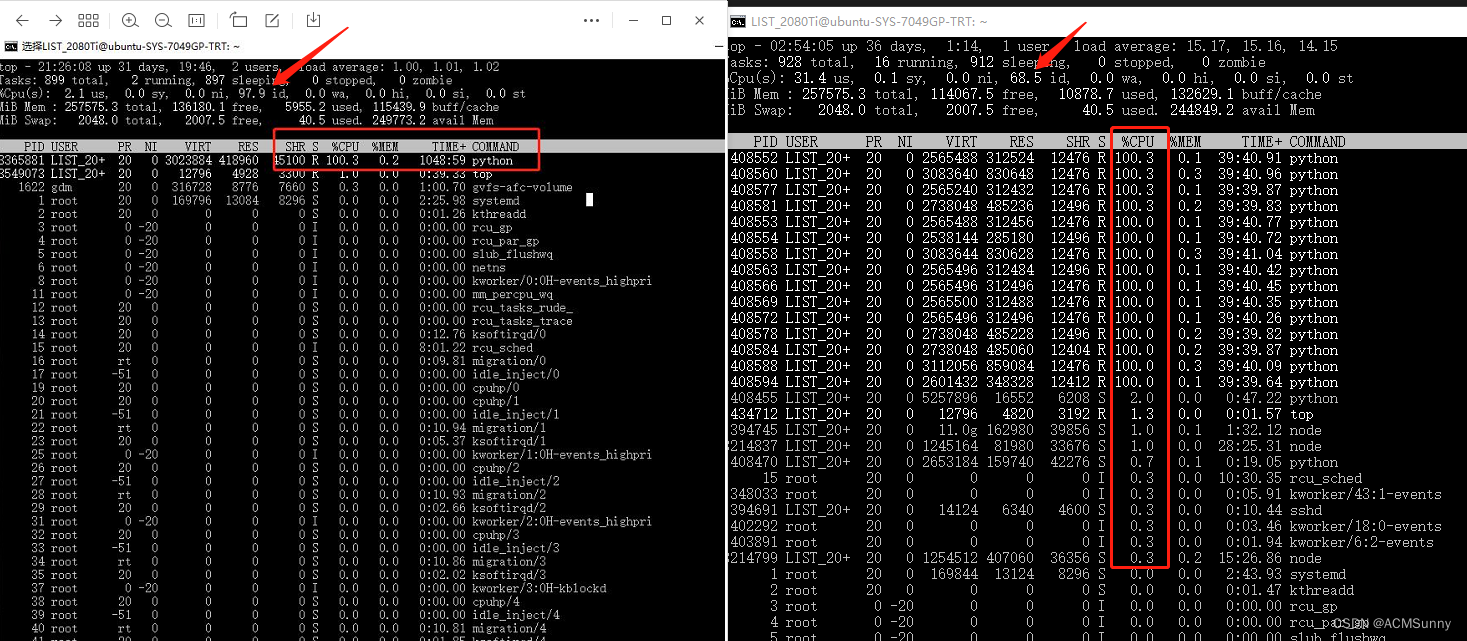 程序并发执行,差不多是原来15倍的差距。原来的需要跑两个多月,现在估计5天就可以了。
程序并发执行,差不多是原来15倍的差距。原来的需要跑两个多月,现在估计5天就可以了。
分析总结
(1)使用多核的程序段
之所以这样干的目的是,使用多核跑程序预处理。
想要这样做的一个前提就是需要把核心程序抽取出来,然后把下面四句作为主程序就行。
from multiprocessing.pool import Pool
if __name__ == '__main__':
with Pool(15) as p:
p.map(data_pro, namelista)上面程序中,15是使用的服务器核数,data_pro是处理的核心程序。namelist是需要迭代的次数。
特别需要注意的是,namelista必须是可哈希的。
否则会报错:unhashable type: 'list'
(2)python可哈希的列表
Python中的hashable objects的例子:
int, float, decimal, complex, bool, string, tuple, range, frozenset, bytes
Python中的unhashable objects的例子:
list, dict, set, bytearray, user-defined classes
(3)弯路
在没有检测出我前面的数据是list的时候,报错一直没有指示正确的位置,这导致我一直以为把namelist使用tuple转换后不起作用。
我之前还用了torch方法,但是不知道什么原因,这个方法对我没有用。
按照博主lei_qi所讲,安装了torch后,直接在你原有的程序上添加以下配置就能直接设置运行的线程数。但是我安装完了之后,再添加这些配置,重启vscode,但是cpu仍旧如之前一样没有任何变化。
限制或增加pytorch的线程个数!指定核数或者满核运行Pytorch!!!_lei_qi的博客-CSDN博客
import os
cpu_num = 1 # 这里设置成你想运行的CPU个数
os.environ ['OMP_NUM_THREADS'] = str(cpu_num)
os.environ ['OPENBLAS_NUM_THREADS'] = str(cpu_num)
os.environ ['MKL_NUM_THREADS'] = str(cpu_num)
os.environ ['VECLIB_MAXIMUM_THREADS'] = str(cpu_num)
os.environ ['NUMEXPR_NUM_THREADS'] = str(cpu_num)
torch.set_num_threads(cpu_num)
以下的参考文章给我了很大帮助,希望这个攻略能够给所有的朋友以帮助。如果本文不能解决你的问题,你也可以看看下面的资料。
这一篇可以说是简短精炼的讲了多核的使用方法:
Python多进程multiprocessing模块介绍 - 简书
这一篇讲了python速度慢的原因:
python速度慢的两大原因_happy_wealthy的博客-CSDN博客_python运行慢的原因
这篇讲了python提速方法:
3行代码,Python数据预处理提速6倍!(附链接)
这一篇是并行程序大总结:
python-16-python并行计算程序multiprocessing_皮皮冰燃的博客-CSDN博客_python并行计算
还有下面的文章都给了我很多启示和帮助,感谢这些文章的作者们。
参考文献
Python: TypeError: unhashable type: ‘list‘_笨牛慢耕的博客-CSDN博客_list unhashable
(1)CPU占比使用情况
Linux提高CPU使用率并设置固定占比_phubing的博客-CSDN博客_nohup dd if=/dev/zero of=/dev/null &
linux:如何指定进程运行的CPU - 疯子123 - 博客园
Linux top命令详解:持续监听进程运行状态
【python】详解multiprocessing多进程-Pool进程池模块(二)_brucewong0516的博客-CSDN博客_from multiprocessing import pool
深度学习PyTorch,TensorFlow中GPU利用率较低,CPU利用率很低,且模型训练速度很慢的问题总结与分析_是否龙磊磊真的一无所有的博客-CSDN博客_深度学习 显卡利用率不高
为什么你的程序跑不满CPU?——简单聊聊多核多线程_我我我只会printf的博客-CSDN博客_多核多线程
(2)限制程序运行线程数
限制或增加pytorch的线程个数!指定核数或者满核运行Pytorch!!!_lei_qi的博客-CSDN博客
Python 基本功: 14. 多核并行计算 - 知乎
CPU占满:pytorch常见问题之cpu占满 - 简书
——————————————
(3)pytorch
https://www.cnblogs.com/bamtercelboo/p/7097933.html
pytorch训练占用cpu过高,num_works和set_num_threads设置均无效,发现是数据扩增的问题_林中化人的博客-CSDN博客_pytorch训练cpu占用率很高
_____________________________________
(4)多核、多进程、多线程
python 的多核利用_yuanzhoulvpi的博客-CSDN博客_python 多核
Python torch.set_num_threads方法代码示例 - 纯净天空
https://www.cnblogs.com/cc-world/p/14465202.html
Python多进程multiprocessing模块介绍 - 简书
python-16-python并行计算程序multiprocessing_皮皮冰燃的博客-CSDN博客_python并行计算
(5)pool
Python 多进程pool.map()方法的使用_埃菲尔没有塔尖的博客-CSDN博客_pool.map
Multiprocessing using Pool in Python
(6)GPU无法调用:
gpu无法调用解决方案记录_Takoony的博客-CSDN博客_iframe gpu无法调用
用GPU跑python代码_编程小飞的博客-CSDN博客_如何用显卡跑代码
(7)linux top监听
Linux top命令详解:持续监听进程运行状态
https://www.cnblogs.com/Chary/p/16394567.html






![pvs中pv显示[unknown]解决方法、正确剔除一个vg流程方法【不影响vg已有的lv数据】、vgs容量和硬盘容量显示不一致解决方法](https://img-blog.csdnimg.cn/71b82d1c3d7c49b29f5cfd3f44d432d8.jpeg)