定时任务
InfluxDB的定时任务本质上是定时执行一个Flux脚本,一般回先查询数据再聚合修改最后可以写回另外一个bucket中
常用的定时任务使用场景
- 降采样 : 如果数据的输入频率特别快比如IOT温度计设备每秒往InfluxDB写入一条数据会有大量的数据写入一个InfluxDB的bucket (因为该Bucket的数据会有大量堆积占用磁盘空间此时可以过期天数设置小一些比如2d),类似温度数据前后几秒不敏感的数据,可以启动一个定时任务每min获取最后一个数据点写入另外一个bucket,该bucket因为数据经历了降采样,量会小很多此时可以把过期时间设置的更长.
- 预聚合 : 在需要开窗聚合的时候每次都会从一个Bucket中的一个时间段进行计算,会消耗更多的资源,可以通过定时任务对需要的时间窗口进行计算好了之后放入另外一个Bucket做到预处理的工作,下次查询直接查询处理好的bucket
通过WEB UI 创建定时任务
假定需求
- 30s执行一次
- 查询最近30s的数据 聚合取mean
- 将数据转成Json
- 发送给一个HTTP服务器
-
新建一个bucket
-
通过influx Line Protocol插入一些测试数据
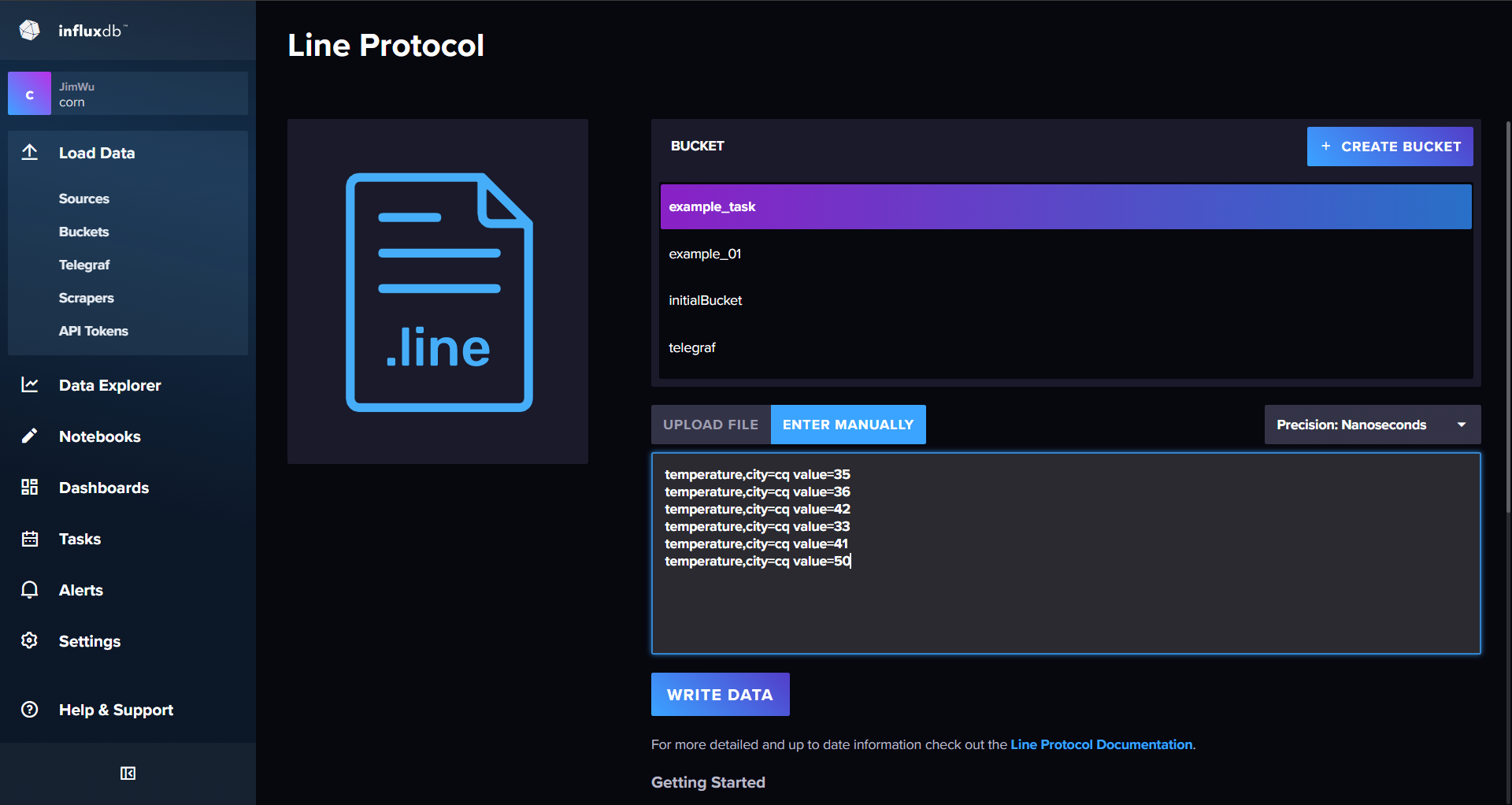
temperature,city=cq value=35 1671073531000 temperature,city=cq value=36 1671073543000 temperature,city=cq value=42 1671073545000 temperature,city=cq value=33 1671073550000 temperature,city=cq value=41 1671073553000 temperature,city=cq value=50 1671073563000 -
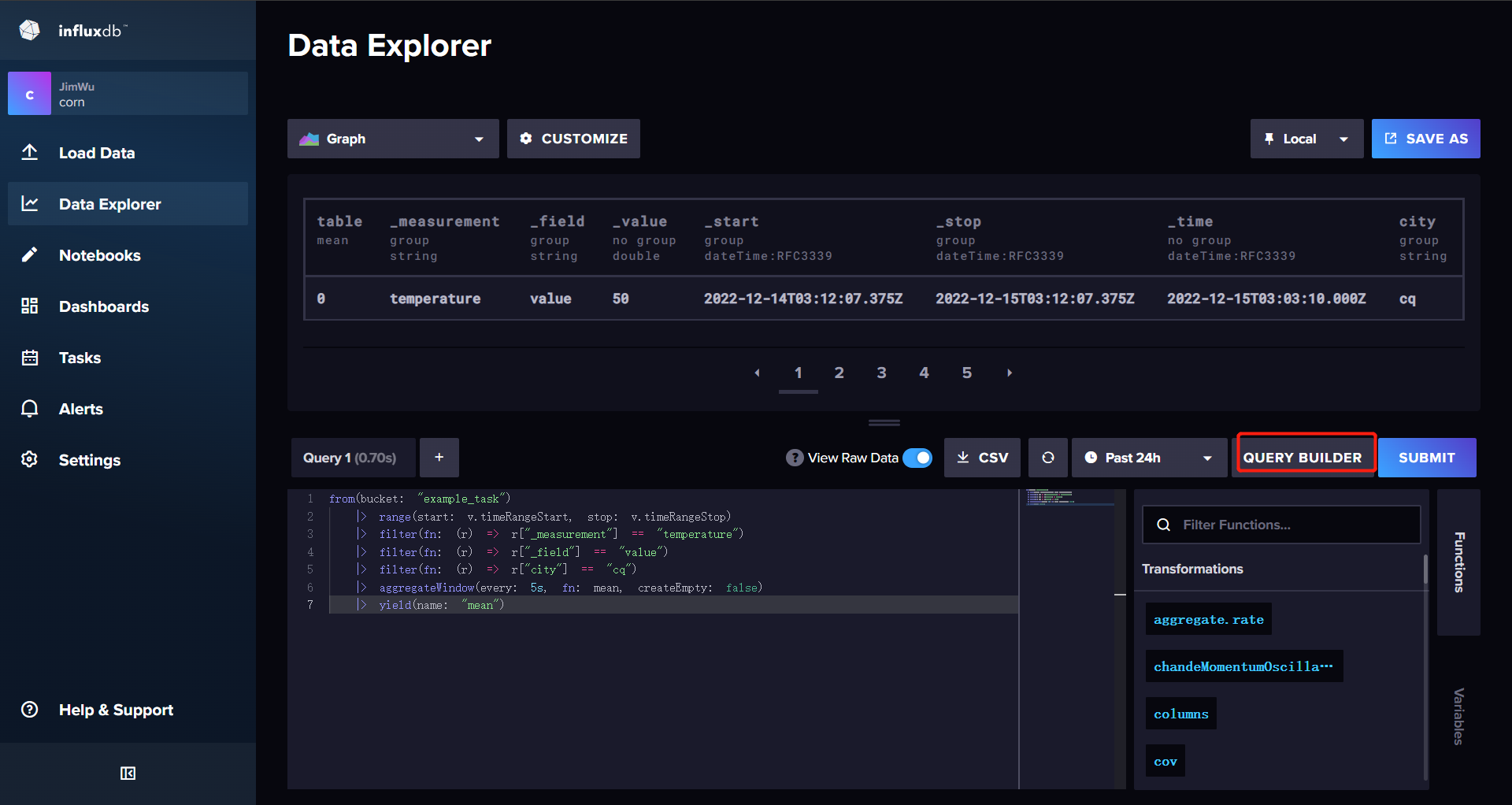
从Data Explorer中自动构建好FLUX查询脚本 开窗时间建议改小一点统计出来的数据点会多一点
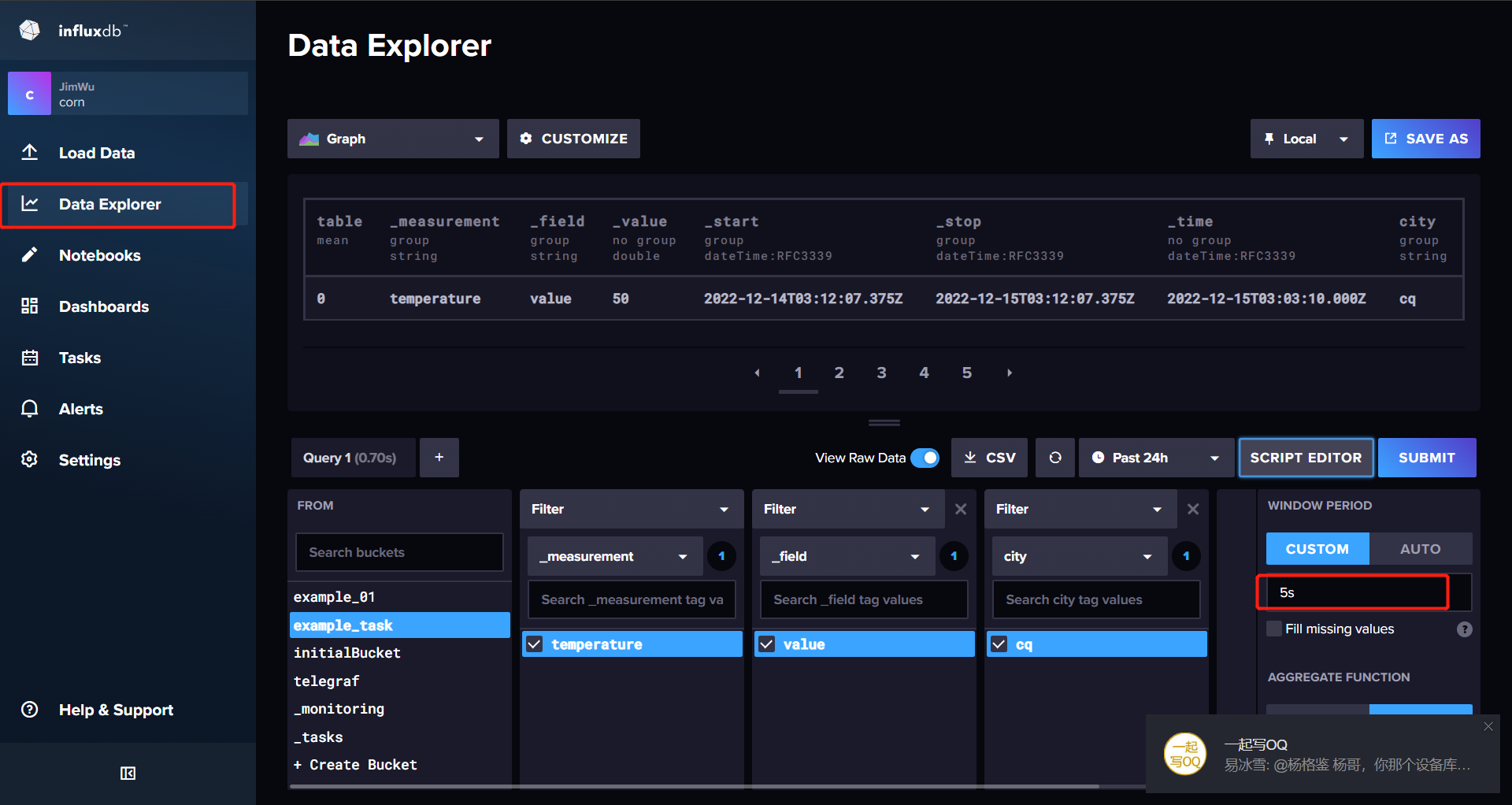
-
点击SCRIPT EDITOR 获取WEB UI 生成好的Flux脚本 ,稍微修改
简单的SpringBoot写的echo接口
@RestController
public class EchoController {
@PostMapping("/echo")
public void echo(@RequestBody String echo) {
System.out.println(echo);
}
}
import "http"
import "json"
from(bucket: "example_task")
// 修改前12小时
|> range(start: -12h)
|> filter(fn: (r) => r["_measurement"] == "temperature")
|> filter(fn: (r) => r["_field"] == "value")
|> filter(fn: (r) => r["city"] == "cq")
// 转化为json 发送Post请求
|> map(fn: (r) => {
data = json.encode(v:r)
code = http.post(url: "http://172.29.128.1:8080/echo", data: data)
return r
})
// 开窗聚合
|> aggregateWindow(every: 5s, fn: mean, createEmpty: false)
|> yield(name: "mean")

-
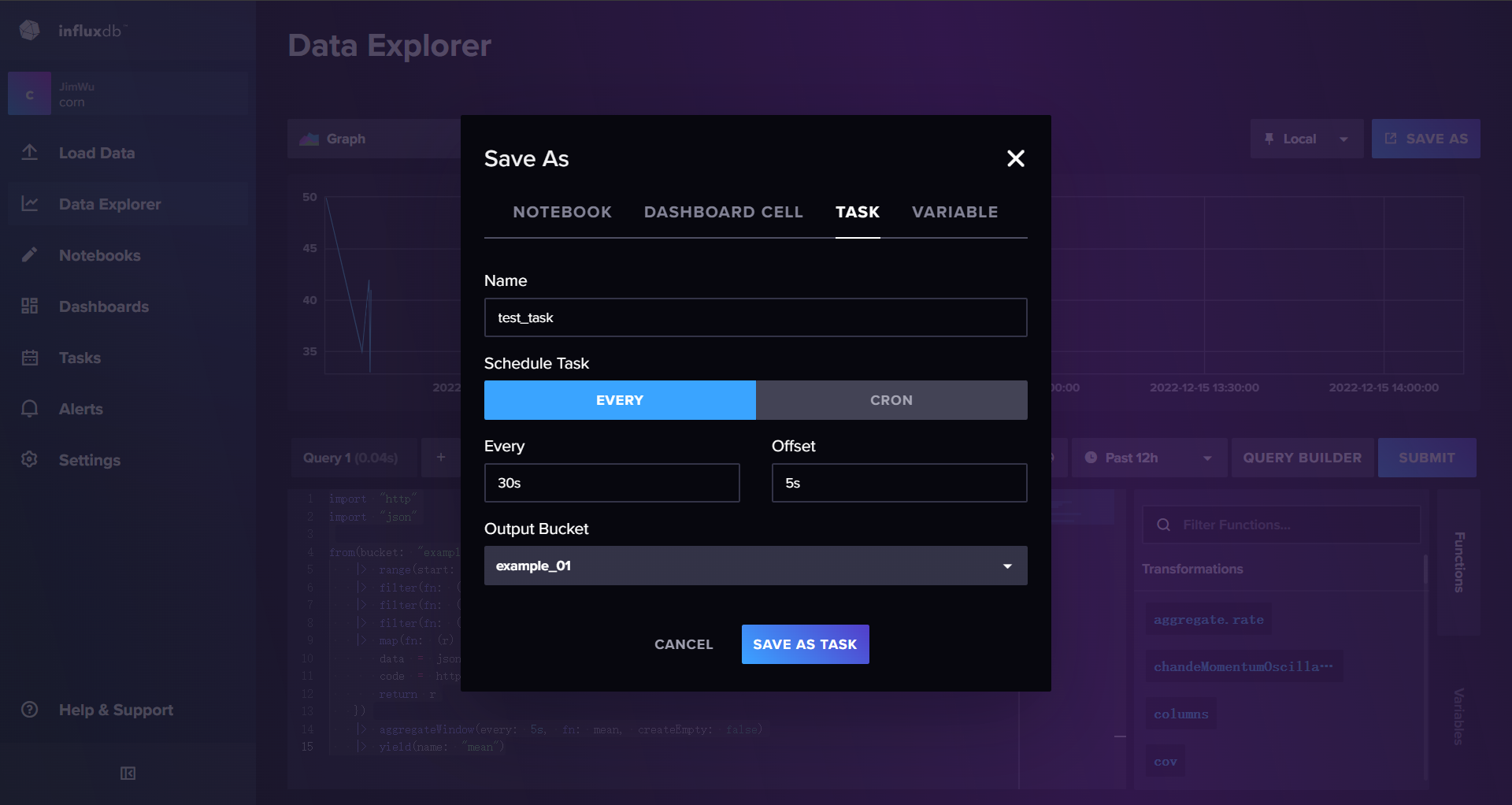
点击右上角SAVE AS 保存为一个新的存储桶
- task任务的调度有两种模式EVERY 表示每X时间执行一次 Offset表示延迟多久统计 因为网络存在延迟比如窗口30s 应该统计0-30秒的数据但是因为网络延迟 00:28的数据在32秒的时候才达到 此时使用offset会使得influx延迟5秒在35秒的时候回统计00 - 30的数据
- CRON表达式模式
- Output Bucket 指定结果输出到的bucket
除了通过WEB-UI能够创建TASK也可以通过Influx-CLI创建TASK本质也是通过FLUX脚本