呼应此前一篇文章《在Spark上使用JDBC连接Trino》,继续在AWS Glue上测试JDBC连接Trino,同样,这是一个非常不典型的应用用场景,本文仅记录测试步骤和结果,不做评论。本文地址:https://laurence.blog.csdn.net/article/details/129098423,转载请注明出处!
1. 测试环境
| 信息项 | 设定值 |
|---|---|
| 测试环境 | AWS Glue 3.0 + Trino 398 ( over EMR 6.9.0 ) |
| Metastore | Glue Data Catalog |
| Trino Server | 10.0.129.105 |
| Trino端口 | 8889 ( 区别于开源默认端口8080 ) |
2. 测试目标
测试在Glue上使用JDBC读写Trino的可行性
3. 操作步骤
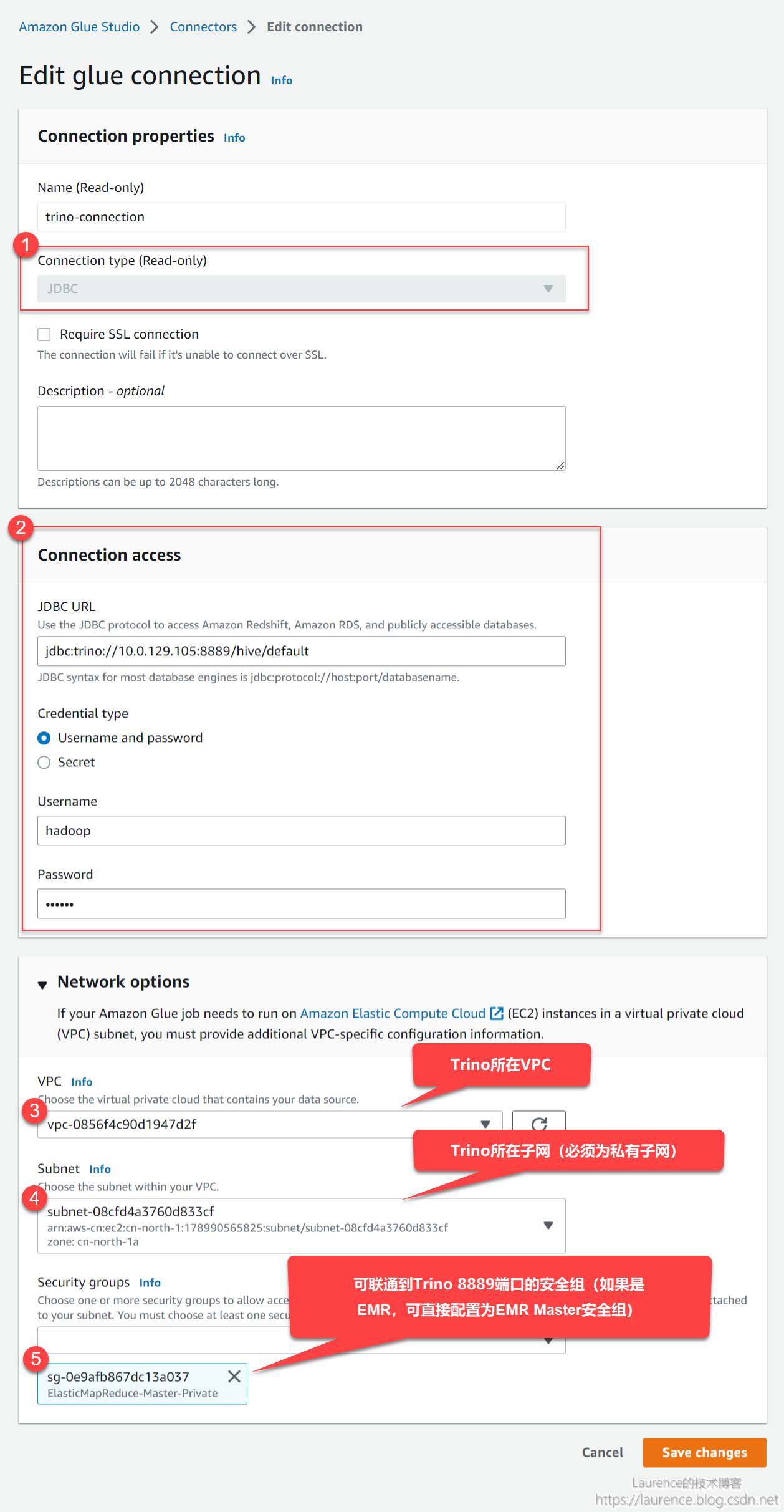
① 创建Glue Connection
选择JDBC类型的Connection,配置好JDBC URL和网络,Glue Connection最重要的作用是配置Glue Worker到目标数据源的网络联通性,所以务必要清楚Trino所在VPC,子网以及可确保联通的安全组:
② 将Trino JDBC Driver上传至S3
# 在Trino所在EMR主节点上执行
aws s3 cp /usr/lib/trino/trino-jdbc/trino-jdbc-398-amzn-0.jar s3://YOUR_BUCKET/trino-jdbc-398-amzn-0.jar
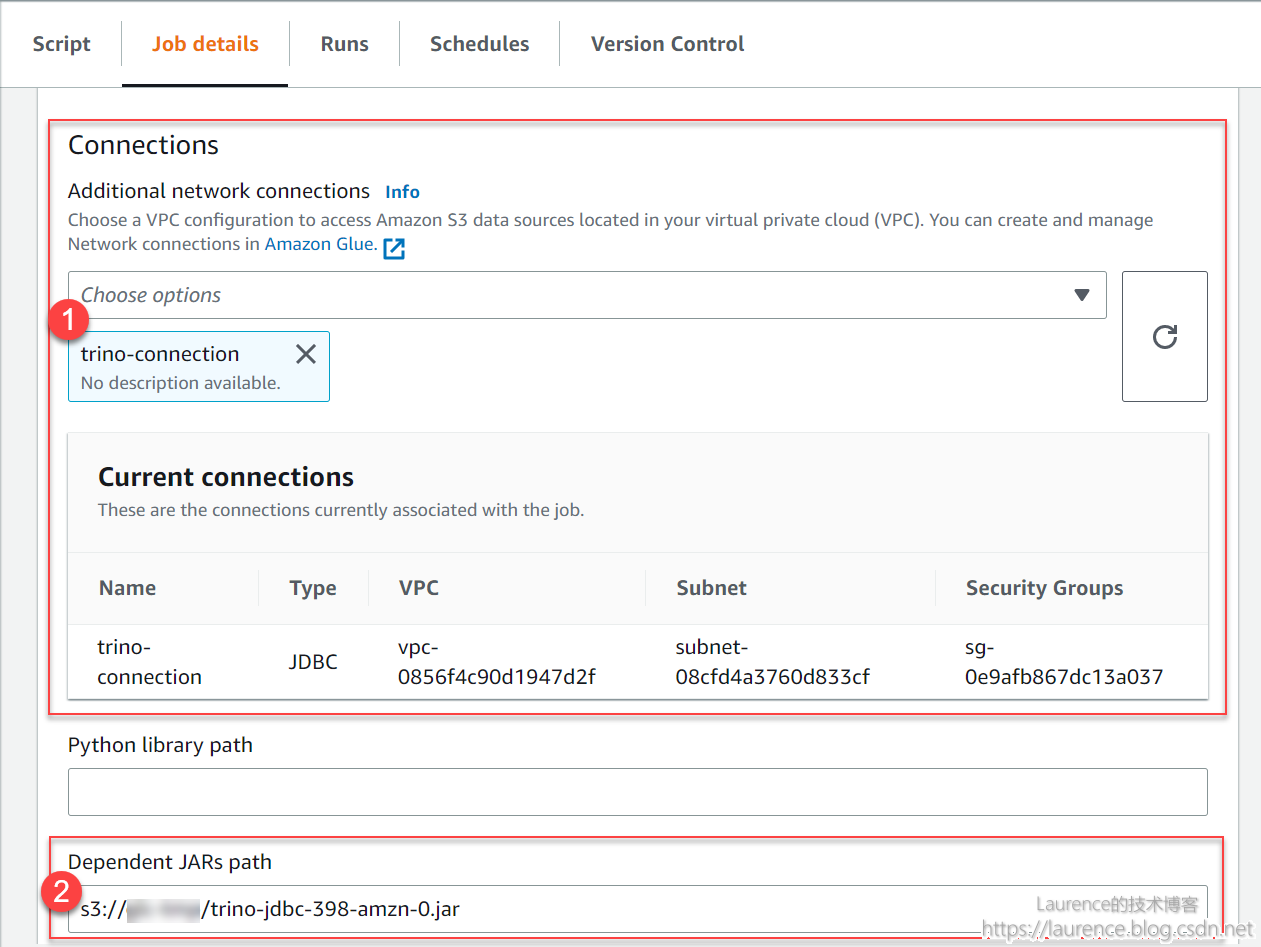
③ 创建Glue Job
有两点区别于普通Glue Job:
- 需attach上一步创建的connection
- 需指定trino jdbc driver路径 (即为第②步中上传的jar包路径)
④ 编写测试代码
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext()
glueContext = GlueContext(sc)
job = Job(glueContext)
# Please update the values in the options to connect to your own data source
options = {
"dbTable":"orders",
"url" : "jdbc:trino://10.0.129.105:8889/hive/default",
"user": "hadoop",
"password": "",
"className" : "io.trino.jdbc.TrinoDriver"
}
datasource = glueContext.create_dynamic_frame_from_options(
connection_type = "custom.jdbc",
connection_options = options,
transformation_ctx = "datasource")
datasource.show()
job.commit()
⑤ 程序输出