长字段的索引调优
当某张表需要给一个长字段创建索引时,因为索引长度越长,效率越差,所以我们需要对其进行优化。
创建额外的长字段的Hash值列
当长字段需要创建索引时,我们可以为其创建额外的一列,用其Hash值作为值,在Hash值这一列上创建索引。例如,first_name这一字段长度很长,而它有常常作为where条件出现,我们就可以增加一列first_name_hash用first_name字段的值的hash值作为该列的值,可以用CRC32(first_name)赋值。然后在first_name_hash上创建索引。在选用hash算法时,第一考虑hash冲突的情况,第二要考虑hash计算后的长度。
使用前缀索引
上述方法,在进行全值查询时可用,但在进行模糊查询时则不适用,这时候我们可以使用前缀索引解决。
alter table employees add key(first_name(5));
first_name后的括号中的数字表示使用前几位作为索引,这个值多少合适,这时候我们需要进行完整列的选择性计算:
select count(distinct first_name)/count(*) from employees;
得到的值就是该字段的最大选择性了。
然后使用:
select count(distinct left(first_name,X))/count(*) from employees;
逐步增大X的值,直到达到最大选择性的值,那么这个时候的X的值,就是我们要选择的值了。
单列索引vs组合索引
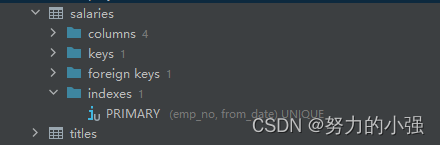
from_date,to_date两个字段没有索引的情况下执行
select *
from salaries
where from_date = '1986-06-26'
and to_date = '1987-06-26';
执行时间为

然后分别为from_date和to_date创建索引
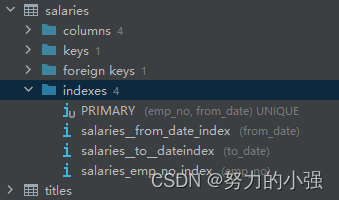
再次执行上面的SQL查询,时间为

删除单独索引,创建from_date和to_date的组合索引
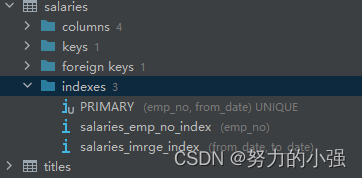
执行时间为

总结:
- SQL存在多个条件,多个单列索引,会使用索引合并
- 如果出现索引合并,往往说明索引不够合理
- 如果SQL暂时没有性能问题,可以暂时不进行调优
- 使用组合索引时要注意列的顺序【要遵循最左前缀原则】
覆盖索引
对于索引X,SELECT的字段只需要从索引就能获得,而无需得到表数据里获取,这要的索引就叫覆盖索引。
现在salaries表有以下索引
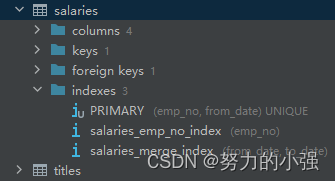
执行
select *
from salaries
where from_date = '1986-06-26'
and to_date = '1987-06-26';
用时

当我们仅仅查询组合索引覆盖的字段时
select from_date,to_date
from salaries
where from_date = '1986-06-26'
and to_date = '1987-06-26';
用时

总结:
当查询时,使用到覆盖索引时,可以减少查询次数,从而提高查询效率。所以,在查询时尽量只返回想要的字段,这样第一有可能使用到覆盖索引提高查询效率,第二减少了网络传输的开销。
重复索引、冗余索引、未使用的索引
重复索引
- 在相同的列上按照相同的顺序创建的索引
- 尽量避免重复索引,如果发现存在重复索引应该删除
冗余索引
- 如果已经存在索引index(A,B),又创建了index(A),那么index(A)就是index(A,B)的冗余索引
- 一般要避免,但有特例!要避免掉进陷阱里!
示例,现在有表salaries表,索引情况如下:
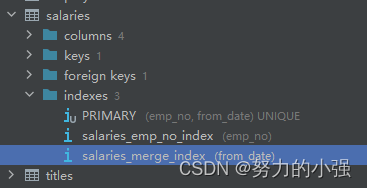
存在单例索引emp_no,以及from_date单列索引。执行
explain
select *
from salaries
where from_date = '1986-06-26'
order by emp_no;
结果

这时候type为ref,Extra额外信息为空
修改索引如下:
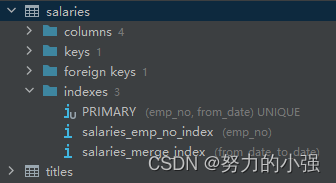
有emp_no单列索引和from_date、to_date的组合索引
再次运行执行计划结果

虽然type还是ref,但是Extra的值为Using filesort,也就是说order by语句没有用到emp_no索引。
因为第一种情况可以视为使用了组合索引index(from_date,emp_no),所以在排序的时候可以用到索引,而第二种情况,可以当作使用了索引index(from_date,to_date,emp_no),因为跳过了to_date,根据最左前缀原则,emp_no索引是失效的,所以排序是filesort。
未使用的索引
在表中有时候会有提前创建的索引,但在后续的开发中发现并没有用到,那么这种未使用的索引就是累赘,因为维护索引也是要消耗性能,有时间成本的,所以对于这种索引要删除掉。

![String类 [上]](https://img-blog.csdnimg.cn/b8b268ef999044a4b09a861ccce2309a.png)

![[计算机操作系统(慕课版)]第二章 进程的描述与控制(学习笔记)](https://img-blog.csdnimg.cn/e5b8c57be2a9443aa7d09b9562da1e03.png)