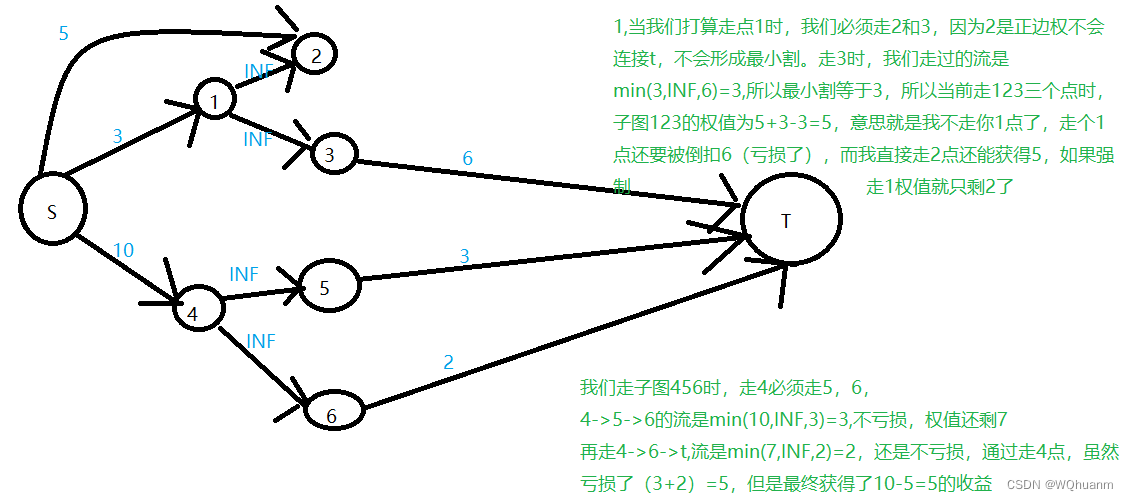
在服务器测试(storage)过程中,会看到很多人写跑fio的脚本用minimal格式来解析,因为这种格式返回的结果对与脚本(shell,python)解析log非常方便.下面介绍一下这种方式下,用Python来解析log
1 一般客户会要求结果中出现一下参数的值:
bandwidth
iops
clat_p99
clat_p999
clat_p9999
lat_max
lat_avg
那么就要知道这些参数的下标:
7 read_bandwidth_kb 带宽值
8 read_iops IOPS值
30 read_clat_pct13 p99的值
32 read_clat_pct15 p999的值
34 read_clat_pct17 p9999的值
39 read_lat_max_us lat max值
40 read_lat_mean_us lat平均值
48 write_bandwidth_kb 带宽值
49 write_iops IOPS值
71 write_clat_pct13 p99值
73 write_clat_pct15 p999的值
75 write_clat_pct17 p9999的值
80 write_lat_max_us lat最大值
81 write_lat_mean_us lat平均值
2 先写一个跑fio的脚本,以HDD为例子吧
#!/bin/bash
if [ $# != 2 ]; then
echo "You must input the time of each testcase (unit is second)"
exit -1
fi
hdd=$1
time=$2
date
echo " sequential random write test start"
for ioengine in libaio sync
do
for rw in write randwrite
do
for bs in 128k
do
for iodepth in 16
do
for jobs in 1
do
date
echo "$hdd $rw $bs iodepth=$iodepth numjobs=$jobs test satrt"
job_name="${ioengine}_${bs}B_${rw}_${jobs}job_${iodepth}QD"
fio --name=$job_name --filename=/dev/$hdd --ioengine=${ioengine} --direct=1 --thread=1 --numjobs=${jobs} --iodepth=${iodepth} --rw=${rw} --bs=${bs} --runtime=$time --time_based=1 --size=100% --group_reporting --minimal >>${hdd}_write.log
done
done
done
done
done
echo " sequential randrom read test start"
for ioengine in libaio sync
do
for rw in read randread
do
for bs in 128k
do
for iodepth in 16
do
for jobs in 1
do
date
echo "$hdd $rw $bs iodepth=$iodepth numjobs=$jobs test satrt"
job_name="${ioengine}_${bs}B_${rw}_${jobs}job_${iodepth}QD"
fio --name=$job_name --filename=/dev/$hdd --ioengine=${ioengine} --direct=1 --thread=1 --numjobs=${jobs} --iodepth=${iodepth} --rw=${rw} --bs=${bs} --runtime=$time --time_based=1 --size=100% --group_reporting --minimal >>${hdd}_read.log
done
done
done
done
done
echo " sequential randmon mix test"
date
for ioengine in libaio sync
do
for rw in rw randrw
do
for mixread in 80
do
for blk_size in 1024k
do
for jobs in 1
do
for queue_depth in 16
do
job_name="${ioengine}_${rw}_${blk_size}B_mix_read${mixread}_${jobs}job_QD${queue_depth}"
echo "$hdd $job_name test satrt"
fio --name=${job_name} --filename=/dev/$hdd --ioengine=libaio --direct=1 --thread=1 --numjobs=${jobs} --iodepth=${queue_depth} --rw=${rw} --bs=${blk_size} --rwmixread=$mixread --runtime=$time --time_based=1 --size=100% --group_reporting --minimal >> "$hdd"_mix_data.log
done
done
done
done
done
done
mkdir $hdd
mkdir $hdd/test_data
mkdir $hdd/test_log
mv $hdd*.log $hdd/test_log
mv $hdd*.csv $hdd/test_data
echo "test has been finsished"
执行一下这脚本如下:
bash hdd-single-fio.sh sdb 1
以混合mix的log为例,先看下这个log
[root@dhcp-10-131-201-78 test_log]# cat sdb_mix_data.log
3;fio-3.19;libaio_rw_1024kB_mix_read80_1job_QD16;0;0;221184;141512;138;1563;8;215;20.126759;15.524727;7460;70547;30223.547625;18514.367104;1.000000%=7766;5.000000%=7766;10.000000%=11468;20.000000%=15138;30.000000%=15663;40.000000%=19005;50.000000%=23199;60.000000%=29491;70.000000%=39583;80.000000%=50069;90.000000%=60555;95.000000%=67633;99.000000%=70778;99.500000%=70778;99.900000%=70778;99.950000%=70778;99.990000%=70778;0%=0;0%=0;0%=0;7477;70557;30243.804338;18512.970716;147456;230400;100.000000%;188928.000000;58650.264859;59392;37998;37;1563;17;70;43.056138;10.402632;10657;1018269;309182.507707;302540.018880;1.000000%=10682;5.000000%=22151;10.000000%=30015;20.000000%=61603;30.000000%=93847;40.000000%=125304;50.000000%=152043;60.000000%=183500;70.000000%=396361;80.000000%=641728;90.000000%=775946;95.000000%=943718;99.000000%=1019215;99.500000%=1019215;99.900000%=1019215;99.950000%=1019215;99.990000%=1019215;0%=0;0%=0;0%=0;10698;1018299;309225.685569;302542.033998;18432;54400;95.836623%;36416.000000;25433.216706;0.128041%;0.320102%;276;0;1;0.4%;0.7%;1.5%;2.9%;94.5%;0.0%;0.0%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;4.74%;32.48%;28.10%;20.07%;6.57%;2.55%;3.28%;1.46%;0.73%;0.00%;sdb;297;60;0;0;8639;12462;21101;95.45%
3;fio-3.19;libaio_randrw_1024kB_mix_read80_1job_QD16;0;0;73728;55226;53;1335;14;60;25.792681;5.446517;10041;908942;180405.286694;196438.088237;1.000000%=10027;5.000000%=21364;10.000000%=29753;20.000000%=49545;30.000000%=66846;40.000000%=80216;50.000000%=112721;60.000000%=145752;70.000000%=191889;80.000000%=256901;90.000000%=375390;95.000000%=666894;99.000000%=910163;99.500000%=910163;99.900000%=910163;99.950000%=910163;99.990000%=910163;0%=0;0%=0;0%=0;10062;908956;180431.227708;196437.318347;43008;75911;100.000000%;59459.500000;23265.934421;24576;18408;17;1335;29;52;45.625042;5.136300;2266;913806;334865.698542;330929.496869;1.000000%=2277;5.000000%=2342;10.000000%=2375;20.000000%=2375;30.000000%=4227;40.000000%=11730;50.000000%=212860;60.000000%=492830;70.000000%=549453;80.000000%=700448;90.000000%=759169;95.000000%=851443;99.000000%=910163;99.500000%=910163;99.900000%=910163;99.950000%=910163;99.990000%=910163;0%=0;0%=0;0%=0;2296;913852;334911.450250;330931.072562;2048;19381;58.205671%;10714.500000;12256.281838;0.074963%;0.149925%;97;0;1;1.0%;2.1%;4.2%;8.3%;84.4%;0.0%;0.0%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;7.29%;2.08%;4.17%;12.50%;18.75%;26.04%;12.50%;11.46%;5.21%;0.00%;0.00%;sdb;119;19;0;0;11431;4186;15616;91.45%
3;fio-3.19;sync_rw_1024kB_mix_read80_1job_QD16;0;0;247808;237591;232;1043;13;46;23.595277;5.565957;5485;234301;37825.893731;26041.930279;1.000000%=9633;5.000000%=14614;10.000000%=18743;20.000000%=22675;30.000000%=24248;40.000000%=28180;50.000000%=34865;60.000000%=41680;70.000000%=45350;80.000000%=49020;90.000000%=53739;95.000000%=58458;99.000000%=233832;99.500000%=233832;99.900000%=233832;99.950000%=233832;99.990000%=233832;0%=0;0%=0;0%=0;5532;234314;37849.606860;26040.562642;238664;238664;100.000000%;238664.000000;0.000000;63488;60870;59;1043;14;57;37.554565;10.139959;4380;356638;120652.004097;97710.572417;1.000000%=4358;5.000000%=5472;10.000000%=10682;20.000000%=25821;30.000000%=56360;40.000000%=78118;50.000000%=101187;60.000000%=135266;70.000000%=166723;80.000000%=189792;90.000000%=295698;95.000000%=308281;99.000000%=358612;99.500000%=358612;99.900000%=358612;99.950000%=358612;99.990000%=358612;0%=0;0%=0;0%=0;4409;356674;120689.674952;97710.473096;58053;58053;95.372104%;58053.000000;0.000000;0.000000%;0.767018%;305;0;1;0.3%;0.7%;1.3%;2.6%;95.1%;0.0%;0.0%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;2.96%;11.18%;56.91%;17.43%;9.21%;2.30%;0.00%;0.00%;0.00%;0.00%;sdb;255;53;0;0;7514;6259;13773;90.30%
3;fio-3.19;sync_randrw_1024kB_mix_read80_1job_QD16;0;0;103424;86619;84;1194;13;54;25.225010;5.761086;11167;897215;186167.299069;170611.347990;1.000000%=16908;5.000000%=21626;10.000000%=23986;20.000000%=38535;30.000000%=65798;40.000000%=94896;50.000000%=147849;60.000000%=200278;70.000000%=244318;80.000000%=283115;90.000000%=383778;95.000000%=488636;99.000000%=876609;99.500000%=893386;99.900000%=893386;99.950000%=893386;99.990000%=893386;0%=0;0%=0;0%=0;11192;897239;186192.659624;170611.730086;63488;88832;87.925282%;76160.000000;17920.914262;33792;28301;27;1194;27;63;41.979727;7.398398;2228;8460;2903.612667;1232.327555;1.000000%=2244;5.000000%=2277;10.000000%=2342;20.000000%=2342;30.000000%=2375;40.000000%=2506;50.000000%=2539;60.000000%=2572;70.000000%=2637;80.000000%=2899;90.000000%=3260;95.000000%=6127;99.000000%=8454;99.500000%=8454;99.900000%=8454;99.950000%=8454;99.990000%=8454;0%=0;0%=0;0%=0;2262;8488;2945.728455;1229.188149;20480;37148;100.000000%;28814.000000;11786.055829;0.000000%;0.419111%;135;0;1;0.7%;1.5%;3.0%;6.0%;88.8%;0.0%;0.0%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;22.39%;2.24%;2.99%;17.16%;10.45%;23.88%;17.91%;1.49%;1.49%;0.00%;0.00%;sdb;152;35;0;0;16193;101;16295;91.85%
3 下面开始用Python来解析这个log,我们需要用到Python中文件函数open,调用两个模块sys和argparse模块 如下:
#!/usr/bin/python
import argparse
import sys
inputfile = sys.argv[1]
resultfile = sys.argv[2]
rwm = sys.argv[3]
sys.argv[n]是传递Python脚本的第几个参数,这里我主要用到三个参数:
inputfile :代表要打开的fio log文件
resultfile:代表要输出的解析结果
rwm: 代表read.write,mix三种读写模式
(1)下面用open函数来处理一下sdb_mix_data.log
先用换行符进行分割,因为总共有4个workload,也就是4个换行,分割之后,列表里就会有5个元素第5个元素为空,需要用函数pop(-1)去掉最后一个元素空
#!/usr/bin/python
import argparse
import sys
inputfile = "sdb_mix_data.log"
resultfile = "sdb_mix.csv"
rwm = "read"
datastr = open(inputfile).read()
data = datastr.split('\n')
data.pop(-1)
print "len(data)"
执行结果:

(2) 第二步就是用open函数write一个输出表格 如下:
#!/usr/bin/python
import argparse
import sys
inputfile = "sdb_mix_data.log"
resultfile = "sdb_mix.csv"
rwm = "read"
datastr = open(inputfile).read()
data = datastr.split('\n')
data.pop(-1)
if rwm == "read":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
生成表格如下:

(3)第三步 就是把log的数据追加到CSV里
#!/usr/bin/python
import argparse
import sys
inputfile = "sdb_mix_data.log"
resultfile = "sdb_mix.csv"
rwm = "read"
datastr = open(inputfile).read()
data = datastr.split('\n')
data.pop(-1)
if rwm == "read":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[6] + "," + oneCaseList[7] + "," + oneCaseList[39].split(".")[0] + "," + oneCaseList[29].split("=")[1] + "," + oneCaseList[31].split("=")[1] + "," + oneCaseList[33].split("=")[1] + "," + oneCaseList[38].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
结果如下图:

(4)这个是read的数据,下面看看write的数据
#!/usr/bin/python
import argparse
import sys
inputfile = "sdb_mix_data.log"
resultfile = "sdb_mix.csv"
rwm = "write"
datastr = open(inputfile).read()
data = datastr.split('\n')
data.pop(-1)
if rwm == "read":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[6] + "," + oneCaseList[7] + "," + oneCaseList[39].split(".")[0] + "," + oneCaseList[29].split("=")[1] + "," + oneCaseList[31].split("=")[1] + "," + oneCaseList[33].split("=")[1] + "," + oneCaseList[38].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
if rwm == "write":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
结果如下:

(5) 因为是读写混合数据,是要把read和write的数据放在同一个CSV里边的 如下:
#!/usr/bin/python
import argparse
import sys
inputfile = "sdb_mix_data.log"
resultfile = "sdb_mix.csv"
rwm = "mix"
datastr = open(inputfile).read()
data = datastr.split('\n')
data.pop(-1)
if rwm == "read":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[6] + "," + oneCaseList[7] + "," + oneCaseList[39].split(".")[0] + "," + oneCaseList[29].split("=")[1] + "," + oneCaseList[31].split("=")[1] + "," + oneCaseList[33].split("=")[1] + "," + oneCaseList[38].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
if rwm == "write":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
if rwm == "mix":
f=open(resultfile,"a")
f.write("workload,read,bandwith(kb/s),IOPS,Lantency(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,write,bandwith(kb/s),IOPS,Lantency(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + "read" + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "," + "write" + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
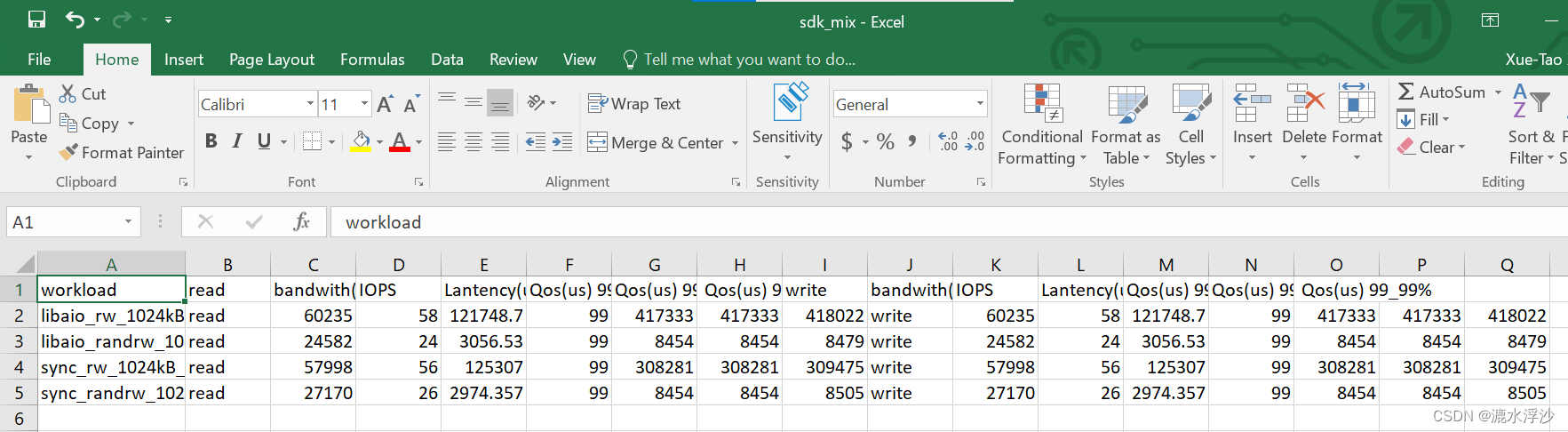
结果如下图:

(6) 把三个参数(inputfile , resultfile ,rwm )写进函数里 最终的Python脚本如下:
#!/usr/bin/python
import argparse
import sys
def fiodata(inputFile, resultFile,rwm):
datastr = open(inputfile).read()
data = datastr.split('\n')
data.pop(-1)
if rwm == "read":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[6] + "," + oneCaseList[7] + "," + oneCaseList[39].split(".")[0] + "," + oneCaseList[29].split("=")[1] + "," + oneCaseList[31].split("=")[1] + "," + oneCaseList[33].split("=")[1] + "," + oneCaseList[38].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
if rwm == "write":
f=open(resultfile,"a")
f.write("workload,bandwith(kb/s),IOPS,lat-avg(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,lat-max(us)\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
if rwm == "mix":
f=open(resultfile,"a")
f.write("workload,read,bandwith(kb/s),IOPS,Lantency(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%,write,bandwith(kb/s),IOPS,Lantency(us),Qos(us) 99%,Qos(us) 99_9%, Qos(us) 99_99%\n")
f.close()
for i in data:
oneCaseList = i.split(";")
caseName = oneCaseList[2]
oneCaseRes = caseName + "," + "read" + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "," + "write" + "," + oneCaseList[47] + "," + oneCaseList[48] + "," + oneCaseList[80] + "," + oneCaseList[70].split(".")[0] + "," + oneCaseList[72].split("=")[1] + "," + oneCaseList[74].split("=")[1] + "," + oneCaseList[79].split(".")[0] + "\n"
f = open(resultfile,"a")
f.write(oneCaseRes)
f.close()
inputfile = sys.argv[1]
resultfile = sys.argv[2]
rwm = sys.argv[3]
fiodata(inputfile,resultfile,rwm)
运行:
python3 minmal.py sdb_mix_data.log result.csv mix
结果:
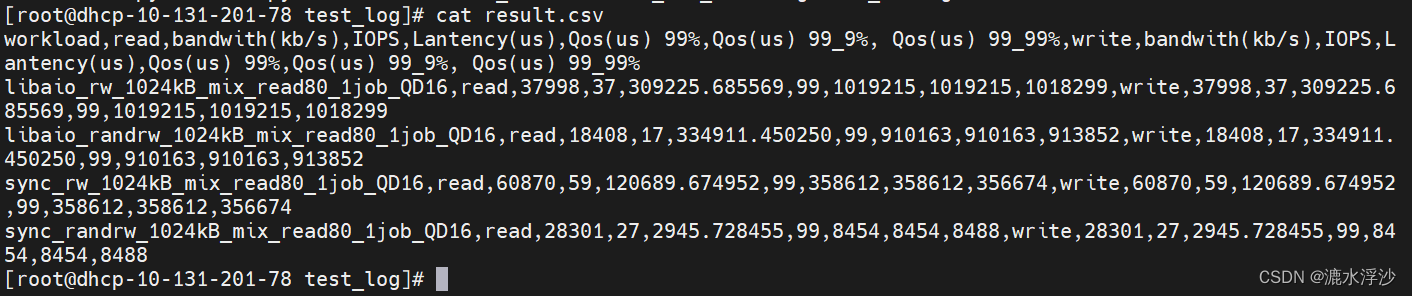
4 接下来需要在shell脚本里调用Python脚本 如下:
#!/bin/bash
if [ $# != 2 ]; then
echo "You must input the time of each testcase (unit is second)"
exit -1
fi
hdd=$1
time=$2
date
echo " sequential random write test start"
for ioengine in libaio sync
do
for rw in write randwrite
do
for bs in 128k
do
for iodepth in 16
do
for jobs in 1
do
date
echo "$hdd $rw $bs iodepth=$iodepth numjobs=$jobs test satrt"
job_name="${ioengine}_${bs}B_${rw}_${jobs}job_${iodepth}QD"
fio --name=$job_name --filename=/dev/$hdd --ioengine=${ioengine} --direct=1 --thread=1 --numjobs=${jobs} --iodepth=${iodepth} --rw=${rw} --bs=${bs} --runtime=$time --time_based=1 --size=100% --group_reporting --minimal >>${hdd}_write.log
done
done
done
done
done
python3 minimal.py ${hdd}_write.log ${hdd}_rw_write.csv write
echo " sequential randrom read test start"
for ioengine in libaio sync
do
for rw in read randread
do
for bs in 128k
do
for iodepth in 16
do
for jobs in 1
do
date
echo "$hdd $rw $bs iodepth=$iodepth numjobs=$jobs test satrt"
job_name="${ioengine}_${bs}B_${rw}_${jobs}job_${iodepth}QD"
fio --name=$job_name --filename=/dev/$hdd --ioengine=${ioengine} --direct=1 --thread=1 --numjobs=${jobs} --iodepth=${iodepth} --rw=${rw} --bs=${bs} --runtime=$time --time_based=1 --size=100% --group_reporting --minimal >>${hdd}_read.log
done
done
done
done
done
python3 minimal.py ${hdd}_read.log ${hdd}_rw_read.csv read
echo " sequential randmon mix test"
date
for ioengine in libaio sync
do
for rw in rw randrw
do
for mixread in 80
do
for blk_size in 1024k
do
for jobs in 1
do
for queue_depth in 16
do
job_name="${ioengine}_${rw}_${blk_size}B_mix_read${mixread}_${jobs}job_QD${queue_depth}"
echo "$hdd $job_name test satrt"
fio --name=${job_name} --filename=/dev/$hdd --ioengine=libaio --direct=1 --thread=1 --numjobs=${jobs} --iodepth=${queue_depth} --rw=${rw} --bs=${blk_size} --rwmixread=$mixread --runtime=$time --time_based=1 --size=100% --group_reporting --minimal >> "$hdd"_mix_data.log
done
done
done
done
done
done
python3 minimal.py ${hdd}_mix_data.log ${hdd}_mix.csv mix
mkdir $hdd
mkdir $hdd/test_data
mkdir $hdd/test_log
mv $hdd*.log $hdd/test_log
mv $hdd*.csv $hdd/test_data
echo "test has been finsished"
5 OK 到这里测试脚本已经完成,测试一下:
bash hdd-single-fio.sh sdk 1 (跑一个HDD 1秒钟)
结果如下:
read的结果
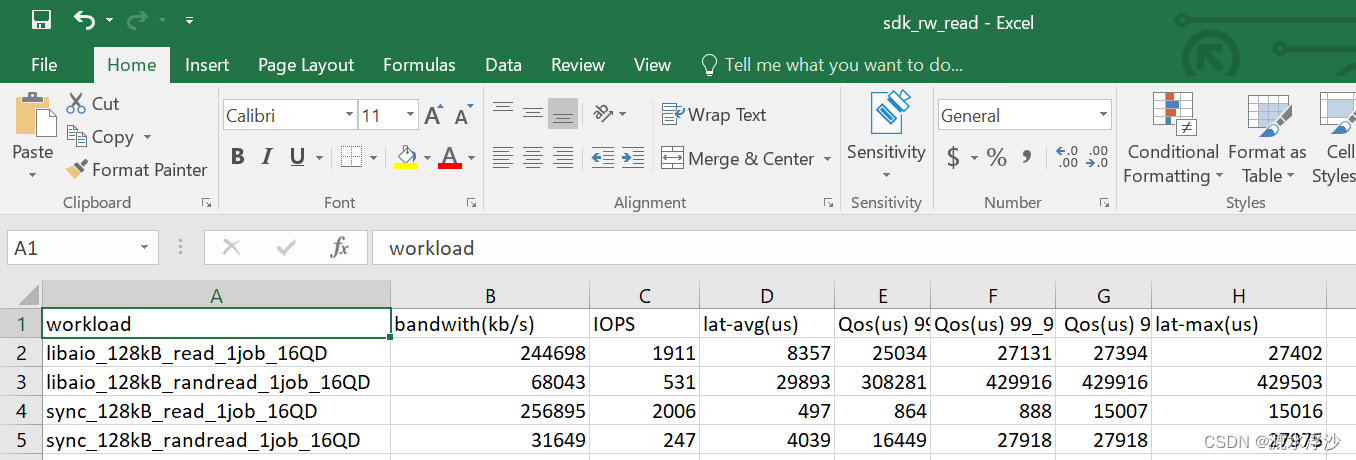 write的结果
write的结果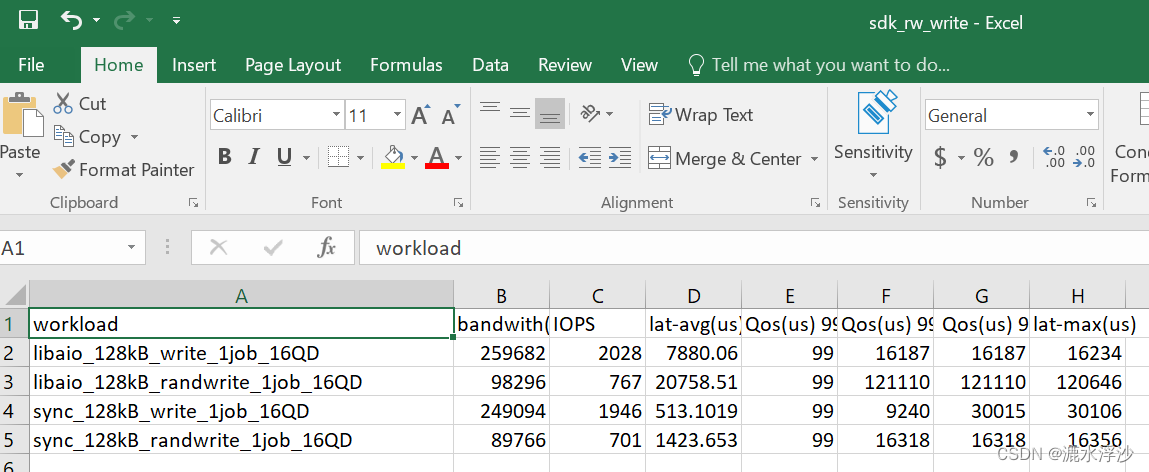
混合结果