简介
先前的知识表示方法:TransE、TransH、TransR、TransD、TranSparse等。的损失函数仅单纯的考虑 h + r h + r h+r和 t t t在某个语义空间的欧氏距离,认为只要欧式距离最小,就认为 h 和 t h和t h和t的关系为r。显然这种度量指标过于简单,虽然先前的工作在得分函数上做出了不错的改进,但训练的损失函数约束了表示的能力,因此,本文TransA模型的提出,主要对损失函数进行改进。
虽然TransA的提出是在TransD、TranSparse之前,但实践表明TransA的提出很有价值
简要信息

摘要与引言
知识表示在人工智能领域内是非常重要的任务,许多研究试图将知识库中的实体和关系表示为一个连续的向量。通过这些尝试,基于翻译模型的表示方法是通过最小化头实体到尾实体的损失函数。尽管这些策略非常成功,但其损失函数过于简单,不能够很好的表示复杂多变的知识图谱。为了解决这些问题,我们提出TransA,一种对表示向量的自适应度量方法。根据度量学习的想法提出一个更灵活的嵌入方法。实验在几个基线数据集上完成,我们的模型获得了最优效果。
* 根据度量学习提出一个更为灵活的嵌入方法。
最近研究均涉及到知识图谱,像问答系统等需要对图谱进行表示,现如今提出的方法有TransE、TransH等。然而这些方法的度量标准仅仅是实体之间的欧氏距离,过于简单的损失函数不能够处理复杂多变的图谱。
(1)由于缺乏灵活的损失函数,当前的翻译模型均是应用球形等位超平面,因此越靠近中心,实体对与对应关系的向量越相似。如图所示,这是TransE模型在FreeBase上训练的向量通过PCA降维得到的图:
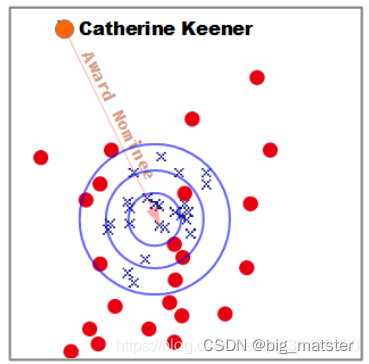
橘黄色的为头实体,橘黄色的线与箭头则为对应的关系向量。蓝色的叉表示正确的尾实体,红色的圆点则是错误的尾实体,可知当简单的使用欧式距离来评判,会掺和进大量错误的实体。由于图谱是复杂多变的**,这一点很难避免**
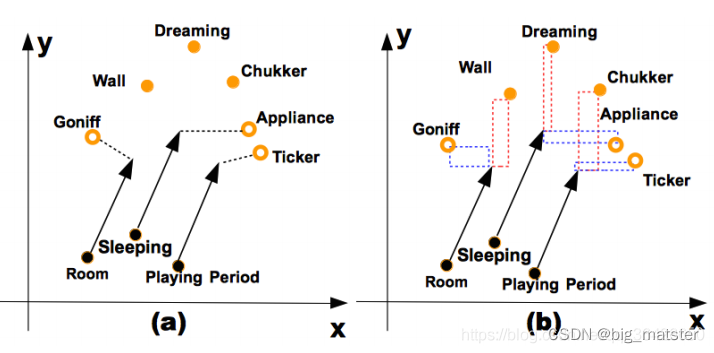
)另外,由于过于简单的损失函数,使得当前几种翻译模型在对向量的每一个维度的训练处理方法相同。如图所示:

相关工作主要贡献

TransA
自适应度量分值函数

椭球面

特征加权

实现细节
采用距离排序损失函数
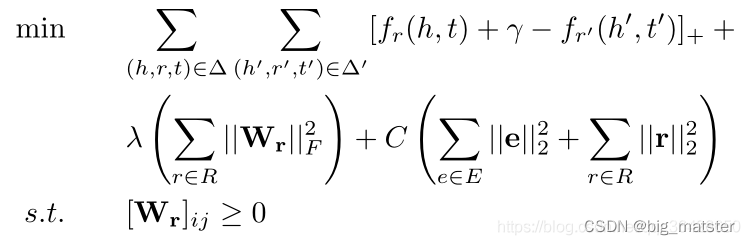
可以采用拉格朗日求梯度进行最小化。
经验
度量学习没了解过,先大致了解,后续深入研究,将其全部都搞定都行啦的样子与打算。