前言
hi~大家好呀,欢迎点进我的C++学习笔记~
我的前一篇C++笔记链接~
【C++】多态_柒海啦的博客-CSDN博客
本篇需要用到的基础二叉树C语言实现链接~
用c语言实现一个简单的链表二叉树_柒海啦的博客-CSDN博客_c语言建立二叉树链表
我们知道,查找一个数据会有很多的方法。在以前,我们查找效率最快的也就是一个二分查找。但是二分查找的前提必须是一个有序的数组。那么,我们有没有什么好的结构来帮助我们去查找数据呢?
现在就介绍一种利用非线性结构对每次插入的数据进行整理,从而能够达到查找最优效率为log_2 N,并且也为之后的容器map、set做好基础(AVL树和红黑树的实现前提)的二叉搜索树。

(唯~φ(>ω<*) )
目录
一、二叉搜索树的实现思路
二叉搜索树概念
二叉树搜索树实现结构
二、二叉搜索树的实现
1.构造、析构
结点构造
构造
拷贝构造
析构
赋值重载
2.插入
非递归实现:
递归实现:
3.寻找
非递归实现:
递归实现:
4.删除
非递归实现:
递归实现:
5.遍历
6.综合代码
一、二叉搜索树的实现思路
首先,需要具备一定的二叉树基础,也就是对树的基本构造需要了解,感兴趣的可以看我文章顶部二叉树基础链接哦~
那么我们如何利用二叉树这个数据结构实现一个便于我们查找数呢?
二叉搜索树概念
二叉搜索树又称二叉排序树,它可以是一个空树也可以具有如下的性质:
1.如果右子树不为空,那么右子树上所有结点值大于根结点的值。
2.如果左子树不为空,那么左子树上所以结点值小于根结点的值。
3.左右子树的每个结点均满足上述条件。
二叉树有key、和keyvalue版本。但是两者实现结构不冲突,均是以key值进行比较。
根据上述特性,比如下面就是二叉搜索树:
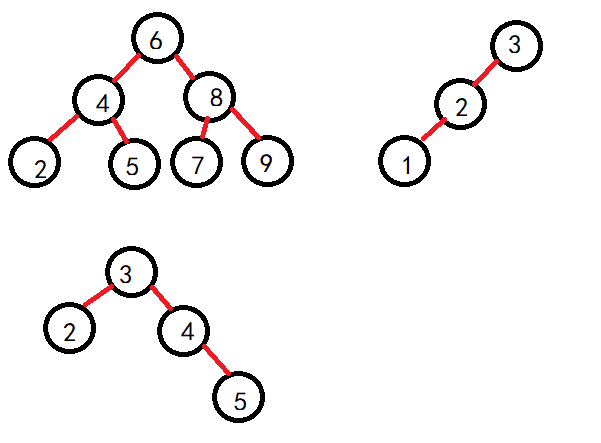
只要子树中一个不满足上述规则,也就不是二叉搜索树了:
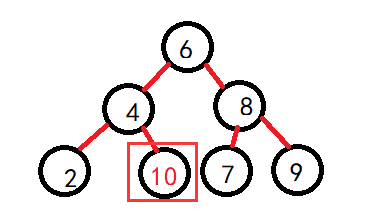
其实,看一个二叉树是否为搜索树,只需要中序遍历一下即可,查看数据是否从小到大排序,是那么就是了。
二叉树搜索树实现结构
那么现在我们如何实现出这样的一个结构呢?在前面的基础二叉树C语言实现中我们知道,使用链式最佳,并且定义一个结点结构,有指向左和右子树的指针,以及存放值的(key就只有key一个,key-value就存在key和value成员),那么现在在二叉搜索树这个类型里,只需要保存根结点,然后进行插入、寻找、删除等操作即可。
那么实现核心就是插入和删除后需要保持二叉搜索树的这个性质,寻找便就可以按照二叉搜索树的左小右大的顺序去寻找。因为二叉搜索树结点可以存key或者key-value。两者实现效果一致,为了方便下面只实现了key版本。
二、二叉搜索树的实现
首先,为了区别key和keyvalue的实现,可以分别放到不同的命名空间哦~下面只演示key,放在namespace key中的哦~
1.构造、析构
结点构造
在构造之前,首先我们需要的是结点类型,结点分为key/key-value,left指向左子树,right指向右子树。初始化时需要向此类型传值初始化key,左右子树置为空。其次注意key值弄成模板参数,这样便就可以模板类,适应更多的类型哦~
template<class K>
struct BStreeNode // 二叉树节点
{
BStreeNode* left;
BStreeNode* right;
K key;
BStreeNode(const K& k)
:key(k)
,left(nullptr)
,right(nullptr)
{}
};构造
现在就开始正式的写代码,确定名字为BSTree(BinarySearchTree),首先确定存在一个属性的变量:存结点的头指针。(在为了方便写结点类型的前提下,可以进行typedef)
template<class K>
class BStree
{
typedef BStreeNode<K> Node;
// ......
private:
Node* _root = nullptr; // 这样使用默认的构造函数即可
}可以注意到,因为属性只有一个指针类型,所以我们给了缺省值,这样在默认构造函数中就能初始化,并且也不用自己写构造函数了。但是考虑到之后会写拷贝构造函数,这样的话不存在默认的构造函数,可以利用C++11的语法,给构造函数后面加上=default就让编译器也生成默认构造函数啦。
public:
BStree() = default; // C++11 即使写其他构造函数,也会生成默认构造函数拷贝构造
因为是二叉树,所以如果是要复制一份二叉树的话,可以利用前序遍历的办法,结合C++的特性传指针引用,递归的将每个结点给拷贝复制一份。当然是直接以当前结点值最为new新结点对象作为一份拷贝啦,递归终止条件就是nullptr了。另外,由于构造函数的特殊性,无法返回值,所以我们可以在私有区域定义一个子函数进行递归即可:
BStree(const BStree<K>& b)
{
_BStree(_root, b._root);
}
// .......
private:
// 拷贝构造递归
void _BStree(Node*& node1, const Node* node2)
{
if (node2 == nullptr) return;
node1 = new Node(node2->key);
_BStree(node1->left, node2->left);
_BStree(node1->right, node2->right);
}析构
析构可以和拷贝构造反着来,后序遍历,首先删除左子树的所有结点,在删除右子树的所有结点,最后删除根结点。同样的结合析构函数特点,需要弄一个子函数进行辅助~
~BStree()
{
_delBStree(_root);
}
// ......
// 递归清理资源
private:
void _delBStree(Node*& node)
{
if (node == nullptr) return;
_delBStree(node->left);
_delBStree(node->right);
delete node;
node = nullptr;
}析构和拷贝构造形参是引用是非常精华的存在哦~细细评味吧~~~
赋值重载
既然讲到拷贝构造了,这里顺便也将赋值重载讲了。实际上,赋值和拷贝构造非常像,直接复用拷贝构造的逻辑即可,既然要复用,我们可以利用形参,传参发生拷贝构造来帮助我们完成这件事情:
// 赋值重载 当一个资本家,让别人帮自己工作
BStree& operator=(BStree<K> b)
{
swap(b);
return *this;
}
// 内部交换属性函数
void swap(BStree<K>& b)
{
Node* tmp = b._root;
b._root = _root;
_root = tmp;
}
// ......内部交换属性函数自己写哦~
2.插入
现在来到了二叉搜索树第一个利用其特性的地方了。对于插入的一个数,我们判断其key值是比当前结点的key值大还是小,大的话就去右子树找,小的话就去左子树找。如果遇到相同,就不插入(不允许数据冗余)。一直到空,此时就可以对其插入。当前对于插入来说有递归和非递归实现:
非递归实现:
对于上面的总体思路一致,利用c结点去走循环即可,只不过出来时有可能存在特殊情况,比如第一次插入,就应该在_root结点。除此之外需要c遍历的同时用p记录它上一次的父节点,最后判断是属于其父左还是右-(利用搜索二叉树特性)就可以插入了:
// 插入 - 非递归
bool insert(const K& k)
{
Node* n = new Node(k);
Node* p = _root;
Node* c = _root;
while (c)
{
if (c->key > k)
{
p = c;
c = c->left;
}
else if (c->key < k)
{
p = c;
c = c->right;
}
else
return false; // 相等
}
if (p == nullptr) _root = n;
else if (p->key > k) p->left = n;
else p->right = n;
return true;
}按理说非递归就够用,但是这里也可以利用传入指针引用的特性来进行说明:
递归实现:
大逻辑还是如上,只不过不用找父节点了,如果为空,直接构造节点插入即可。(指针引用,传入的就是原本的本身)。大于递归右子树,小于递归左子树,相等返回false:
因为,在插入的时候只会传入一个key参数,递归的话是需要节点指针的,所以可以考虑子函数进行递归实现:
bool insertR(const K& k)
{
return _insertR(_root, k);
}
// ......
private:
// 递归插入子函数
bool _insertR(Node*& node, const K& k)
{
if (node == nullptr)
{
node = new Node(k);
return true;
}
if (node->key > k) return _insertR(node->left, k);
else if (node->key < k) return _insertR(node->right, k);
else return false; // 相同插入失败
}3.寻找
对于寻找来说的话,同样利用搜索二叉树的特性,相等就返回true,小于走左子树,大于走右子树,同样的递归和非递归实现:
非递归实现:
// 查找 - 是否存在key值,存在返回true
bool find(const K& k)
{
Node* c = _root;
while (c)
{
if (c->key > k) c = c->left;
else if (c->key < k) c = c->right;
else return true;
}
return false;
}递归实现:
bool findR(const K& k)
{
return _findR(_root, k);
}
// ......
private:
// 递归寻找子函数
bool _findR(Node* node, const K& k)
{
if (node == nullptr) return false;
if (node->key > k) return _findR(node->left, k);
else if (node->key < k) return _findR(node->right, k);
else return true;
}4.删除
对于二叉搜索树来说,删除的逻辑较为复杂。因为一个结点下有左右孩子,并且删除后需要保证二叉搜索树的逻辑不被遭到破坏,所以一般分为如下的几种删除情况:
对于如下树来说,删除2这个结点:
1.结点无左右孩子
直接删除即可。
2.结点有一个孩子
只有左子树。继承2的位置。
只有右子树。继承2的位置。
3.结点有两个孩子
如上,找2结点右子树的最左结点(右子树最小),替换2结点,然后被替换结点发生继承(此时无法在往左走,要么剩下右子树或者空,右子树继承即可)
或者,找2结点的左子树的最右结点(左子树最小),替换2结点,然后被替换结点发生继承(此时无法在往右走,要么剩下左子树或者空,左子树继承即可)
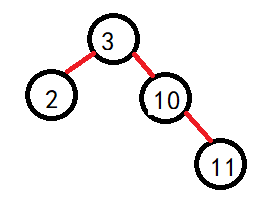
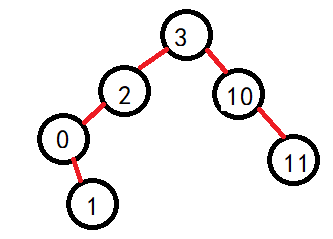
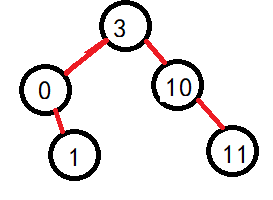


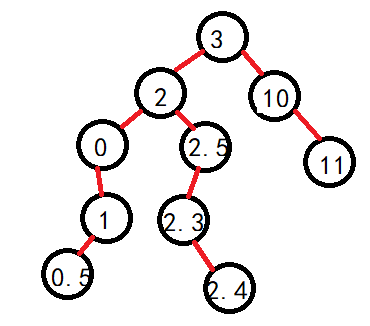


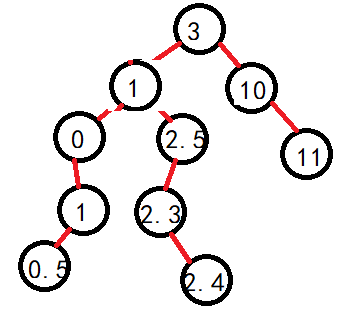
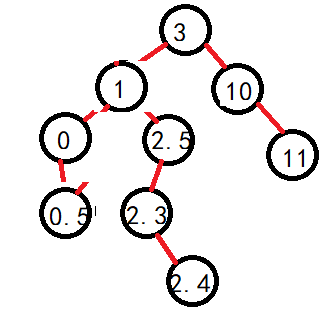
根据如上的图解,我们可以归类为两种情况:1.不存在两个孩子。2.存在两个孩子。因为可以发现,存在一个孩子和不存在孩子都可以通过继承法进行维持搜索二叉树的性质。1.但是由于是当前结点删除,判断左右,然后直接赋值就需要判断是否是头结点的情况,直接是头结点的话,那么就要修改root了。
2.对于存在两个孩子的话,为什么可以找左子树的最大值或者右子树的最小值呢?因为你可以看到被删除结点在当前以其为根的子树中就是中间值,那么要把它删掉我们自然需要下一个接班人,接班人是有条件的,那就是有足够的精力维护两边的平衡。
现在设需要删除结点为父,取父的左子树最大值或者右子树的最小值。另外需要注意的是替换后,在替换的那个节点的原本位置就需要执行1的那个过程,因为继承的话如果是左子树最大值,那么就是左子树最大值的左边,即由其父的右边继承。
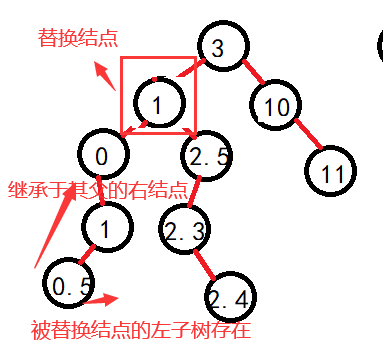
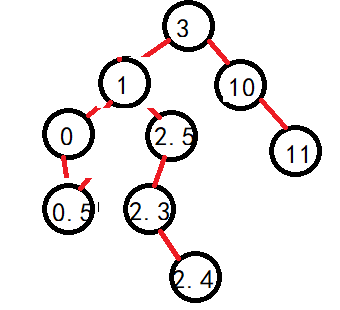
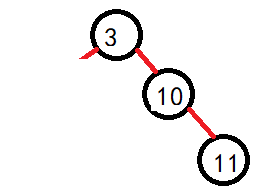
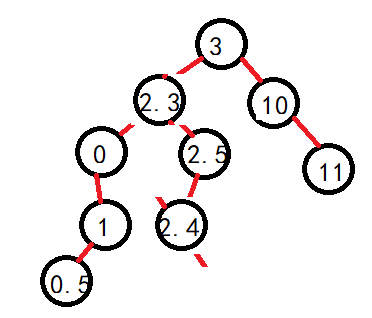
但是需要注意的是,既然是其父,那么如果左子树的最大值就是父的左呢?比如:
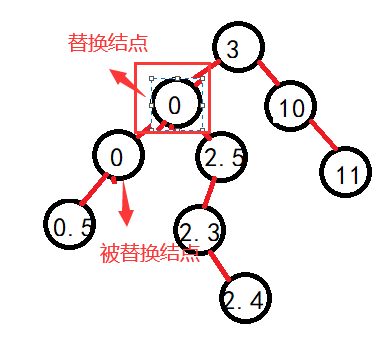
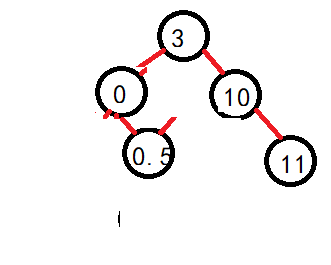
可以看到,如果按照原本的逻辑走,就会出现错误,原本结点的右子树大量丢失,所以因为此时父的左子树没有发生变化,那么父也就不会随着其找最大值时变化,这个时候进行判断一下。直接将父节点的左子树继承即可:
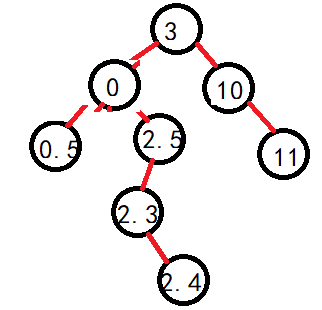
同理,如果是找右子树的最小值相反着来即可。
非递归实现:
首先删除逻辑同上,因为是非递归,判断循环结束条件为空即可,如果真为空,就表示找不到此结点,大于走右子树,小于走左子树。相等就进行删除操作。删除成功后就直接进行返回。删除分为上面的情况,谨慎处理细节:
// 删除 - 非递归
bool erase(const K& k)
{
Node* p = _root;
Node* c = _root;
while (c)
{
if (c->key > k)
{
p = c;
c = c->left;
}
else if (c->key < k)
{
p = c;
c = c->right;
}
else
{
// 删除分为三种情况:1.两个孩子都没有 2.有一个孩子 3.有两个孩子 12可以归为一类,进行继承操作。3使用替换法
if (c->left == nullptr)
{
// 小心就是删除_root结点
if (c == _root) _root = c->right;
// 判断继承于哪边孩子
else if (p->key > k) p->left = c->right;
else p->right = c->right;
delete c;
}
else if (c->right == nullptr)
{
if (c == _root) _root = c->left;
else if (p->key > k) p->left = c->left;
else p->right = c->left;
delete c;
}
else
{
// 替换法
Node* maxc = c->left;
Node* maxp = c;
// 找到左子树的最大值或者右子树的最小值即可
while (maxc->right)
{
// 左子树最大值,一直往右找
maxp = maxc;
maxc = maxc->right;
}
c->key = maxc->key; // 交换值
//maxp->right = maxc->left; // 后面的需要继承 无论nullptr 千万注意maxp的问题 如果maxp没有动的话,此时就会出现问题
if (maxp == c) maxp->left = maxc->left;
else maxp->right = maxc->left;
delete maxc;
}
// 删除成功 -- 找的到目标key值
return true;
}
}
return false;
}递归实现:
由于递归删除有着可以传入指针引用的特点,所以在第一种的情况下直接继承的话直接给递归来的指针对应的继承指针即可。此时就不用怕是否为根结点了。因为即使是根节点,此时修改的也就是根节点。
对于两个孩子都存在的情况下,首先找替换不变,直接走循环即可。继承的话我们可以不用之前那么复杂的分析,可以就从当前被删结点的左子树(或者右子树开始),删除被替换结点即可。此时走的一定是上面的继承逻辑。完美展现了复用的好处。
bool eraseR(const K& k)
{
return _eraseR(_root, k);
}
private:
// 递归删除子函数
bool _eraseR(Node*& node, const K& k)
{
if (node == nullptr) return false; // 没有找到,无法删除
if (node->key > k) return _eraseR(node->left, k);
else if (node->key < k) return _eraseR(node->right, k);
else
{
Node* tmp = node; // 记录当前指针,方便释放空间
// 找到了,进行删除操作
// 第一种情况 存在一个孩子或者没有孩子
if (node->left == nullptr)
{
node = node->right;
}
else if (node->right == nullptr)
{
node = node->left;
}
else
{
// 第二种情况 两个孩子存在
Node* maxc = node->left; // 找左子树的最大值
while (maxc->right)
{
maxc = maxc->right;
}
node->key = maxc->key;
// 交换值之后,不再进行复杂的分析如何接后面的情况,继续递归给别人,将此交换点干掉即可
return _eraseR(node->left, maxc->key); // 必须从左树开始找,不能直接传maxc,否则只是修改形参里的值,传回了释放的空间就成野指针了
}
delete tmp;
return true;
}
}5.遍历
相对于之前的代码实现,遍历就简单太多了,直接中序遍历即可:使用递归即可
// 中序遍历 - 递归
void order()
{
_order(_root);
cout << endl;
}
// ......
private:
// 中序遍历递归
void _order(Node* node)
{
if (node == nullptr) return;
_order(node->left);
cout << node->key << " ";
_order(node->right);
}6.综合代码
综上,对于key模型的二叉搜索树我们的总体实现代码如下:
// 二叉搜索树 - key&&key/value 版本 满足每个子树(包括整个树)左子树小于结点,结点小于右子树 (均针对的树上的所有值)
namespace Key
{
template<class K>
struct BStreeNode // 二叉树节点
{
BStreeNode* left;
BStreeNode* right;
K key;
BStreeNode(const K& k)
:key(k)
,left(nullptr)
,right(nullptr)
{}
};
template<class K>
class BStree
{
typedef BStreeNode<K> Node;
public:
BStree() = default; // C++11 即使写其他构造函数,也会生成默认构造函数
// 拷贝构造
BStree(const BStree<K>& b)
{
_BStree(_root, b._root);
}
~BStree()
{
_delBStree(_root);
}
// 赋值重载 当一个资本家,让别人帮自己工作
BStree& operator=(BStree<K> b)
{
swap(b);
return *this;
}
// 内部交换属性函数
void swap(BStree<K>& b)
{
Node* tmp = b._root;
b._root = _root;
_root = tmp;
}
// 中序遍历 - 递归
void order()
{
_order(_root);
cout << endl;
}
非递归-插入-寻找-删除///
// 插入 - 非递归
bool insert(const K& k)
{
Node* n = new Node(k);
Node* p = _root;
Node* c = _root;
while (c)
{
if (c->key > k)
{
p = c;
c = c->left;
}
else if (c->key < k)
{
p = c;
c = c->right;
}
else
return false; // 相等
}
if (p == nullptr) _root = n;
else if (p->key > k) p->left = n;
else p->right = n;
return true;
}
// 查找 - 是否存在key值,存在返回true
bool find(const K& k)
{
Node* c = _root;
while (c)
{
if (c->key > k) c = c->left;
else if (c->key < k) c = c->right;
else return true;
}
return false;
}
// 删除 - 非递归
bool erase(const K& k)
{
Node* p = _root;
Node* c = _root;
while (c)
{
if (c->key > k)
{
p = c;
c = c->left;
}
else if (c->key < k)
{
p = c;
c = c->right;
}
else
{
// 删除分为三种情况:1.两个孩子都没有 2.有一个孩子 3.有两个孩子 12可以归为一类,进行继承操作。3使用替换法
if (c->left == nullptr)
{
// 小心就是删除_root结点
if (c == _root) _root = c->right;
// 判断继承于哪边孩子
else if (p->key > k) p->left = c->right;
else p->right = c->right;
delete c;
}
else if (c->right == nullptr)
{
if (c == _root) _root = c->left;
else if (p->key > k) p->left = c->left;
else p->right = c->left;
delete c;
}
else
{
// 替换法
Node* maxc = c->left;
Node* maxp = c;
// 找到左子树的最大值或者右子树的最小值即可
while (maxc->right)
{
// 左子树最大值,一直往右找
maxp = maxc;
maxc = maxc->right;
}
c->key = maxc->key; // 交换值
//maxp->right = maxc->left; // 后面的需要继承 无论nullptr 千万注意maxp的问题 如果maxp没有动的话,此时就会出现问题
if (maxp == c) maxp->left = maxc->left;
else maxp->right = maxc->left;
delete maxc;
}
// 删除成功 -- 找的到目标key值
return true;
}
}
return false;
}
递归-插入-寻找-删除///
bool insertR(const K& k)
{
return _insertR(_root, k);
}
bool findR(const K& k)
{
return _findR(_root, k);
}
bool eraseR(const K& k)
{
return _eraseR(_root, k);
}
private:
// 递归删除子函数
bool _eraseR(Node*& node, const K& k)
{
if (node == nullptr) return false; // 没有找到,无法删除
if (node->key > k) return _eraseR(node->left, k);
else if (node->key < k) return _eraseR(node->right, k);
else
{
Node* tmp = node; // 记录当前指针,方便释放空间
// 找到了,进行删除操作
// 第一种情况 存在一个孩子或者没有孩子
if (node->left == nullptr)
{
node = node->right;
}
else if (node->right == nullptr)
{
node = node->left;
}
else
{
// 第二种情况 两个孩子存在
Node* maxc = node->left; // 找左子树的最大值
while (maxc->right)
{
maxc = maxc->right;
}
node->key = maxc->key;
// 交换值之后,不再进行复杂的分析如何接后面的情况,继续递归给别人,将此交换点干掉即可
return _eraseR(node->left, maxc->key); // 必须从左树开始找,不能直接传maxc,否则只是修改形参里的值,传回了释放的空间就成野指针了
}
delete tmp;
return true;
}
}
// 递归寻找子函数
bool _findR(Node* node, const K& k)
{
if (node == nullptr) return false;
if (node->key > k) return _findR(node->left, k);
else if (node->key < k) return _findR(node->right, k);
else return true;
}
// 递归插入子函数
bool _insertR(Node*& node, const K& k)
{
if (node == nullptr)
{
node = new Node(k);
return true;
}
if (node->key > k) return _insertR(node->left, k);
else if (node->key < k) return _insertR(node->right, k);
else return false; // 相同插入失败
}
// 递归清理资源
void _delBStree(Node*& node)
{
if (node == nullptr) return;
_delBStree(node->left);
_delBStree(node->right);
delete node;
node = nullptr;
}
// 拷贝构造递归
void _BStree(Node*& node1, const Node* node2)
{
if (node2 == nullptr) return;
node1 = new Node(node2->key);
_BStree(node1->left, node2->left);
_BStree(node1->right, node2->right);
}
// 中序遍历递归
void _order(Node* node)
{
if (node == nullptr) return;
_order(node->left);
cout << node->key << " ";
_order(node->right);
}
Node* _root = nullptr; // 这样使用默认的构造函数即可
};
}综上就是key模型的二叉搜索树的实现啦~~,key-value就直接增加一个成员即可,构造时传上其参数即可,其余均不变,因为仍然用key进行比较的。代码仅供参考,还请大佬多多指正!