文章目录
- 前言
- 一、集合的整体结构
- 单列集合接口:
- 双列集合接口:
- 二、单列集合详解
- 1.List接口
- 1.1 ArrayList集合
- 特点:
- 扩容:
- 添加元素
- 遍历
- 1.2 LinkedList集合
- 特点:
- 添加元素:
- 2.Set接口
- 2.1 HashSet集合
- 特点:
- 重写equals()和hashcode()方法的必要性:
- 存储对象示例:
- 2.2 TreeSet集合
- 特点:
- 存储对象示例:
- 三、双列集合详解
- 1、Map集合
- 特点:
- 1.1.HashMap
- 特点:
- 1.1.1、LinkedHashMap
- 特点:
- 1.2.ConcurrentHashMap
- 特点:
- 1.3.TreeMap
- 特点:
- 4.HashTable
- 特点:
前言
集合是老生常谈的内容,关于集合有很多内容可以挖掘,本篇梳理一下。
一、集合的整体结构
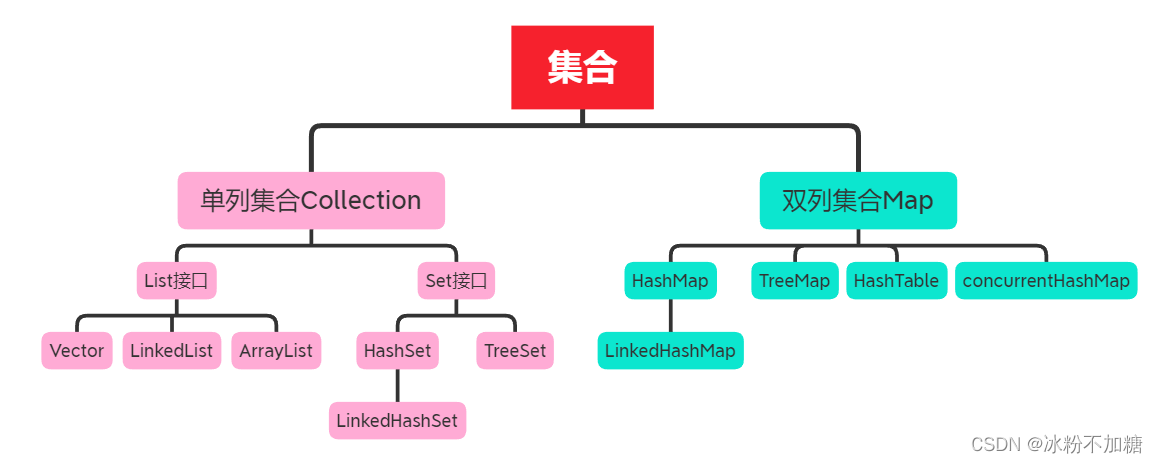
集合分为单列集合和双列集合
单列集合接口:
- Collection:单列集合的顶级接口,其下有两个子接口分别是List和Set
- List:有序,元素可重复
- Vector:所有方法线程同步,效率低,线程安全
- LinledList:双向链表,查找慢,增删快,线程不安全
- ArrayList:基于数组实现,查找快,增删慢,线程不安全
- set:无序,不可重复,最多存在一个null
- HashSet:底层是HashMap,将set中存储的值作为HashMap的key来处理
- LinkedHashSet:基于LinkedHashMap来实现,底层利用双向链表来实现的数据有序
- TreeSet:元素自然有序,需要实现Comparator接口,不能存在null
- List:有序,元素可重复
双列集合接口:
- Map :以键值存储,<key,value>,key不可重复,否则覆盖
- HashMap:基于Hash表实现,线程不安全,无序,key和value都可为null,jdk1.8 之前 HashMap 由 数组 + 链表 组成,jdk1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8 )并且当前数组的长度大于 64 时,此时此索引位置上的所有数据改为使用红黑树存储。
- LinkedHashMap:通过在HashMap的基础上增加一条双向链表来实现,实现了插入顺序和访问顺序一致。
- TreeMap:基于红黑树,有序存储,由Comparable或Comparator决定,需要自己实现比较器
- HashTable:数组+链表,数组+二叉树(链表树化),通过把关键码值映射到表中一个位置来访问记录(类似索引),以加快查找的速度。
- concurrentHashMap:底层可以看成一个HashTable数组,采用分段锁设计,线程安全。
- HashMap:基于Hash表实现,线程不安全,无序,key和value都可为null,jdk1.8 之前 HashMap 由 数组 + 链表 组成,jdk1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8 )并且当前数组的长度大于 64 时,此时此索引位置上的所有数据改为使用红黑树存储。
二、单列集合详解
1.List接口
List接口的特点:
- 存入的元素有序,且可重复。按照存储的顺序可以进行遍历操作。
- 初始长度为10,当存储长度不够时会自动扩容为原来的1.5倍
List接口的方法
增
- void add(int index,element);在指定位置插入指定元素。
- boolean addAll(int index,Collection<? extends E> e);将一个集合插入到另一个集合的指定位置
删:
- E remove(int index);删除指定位置的下标。返回被删除的元素。
改:
- E set(int index , E e);通过指定的索引修改元素。返回被修改的原数据。
查:
- E get(int index); 通过索引下标去获取指定元素
- int indexOf(Object obj);通过元素获取指定的下标的
- int lastIndexOf(object obj);通过元素获取最后一次出现的元素的下标
- List< E> subList(int formIndex, int toIndex);截取一部分出来
1.1 ArrayList集合
- 底层的数据结构为数组。
- 增删慢,查改快。(涉及到数组的扩容机制)
- 默认为10,会自动扩容为1.5倍。
特点:
ArrayList是List集合下面的一种集合,它的底层实现的数据结构为数组,所以它具有增删慢,查询修
改快的特点。特别适合于数据一旦固定,就不会在额外的增加删除或者增加删除较少,查询修改较多的业务。
扩容:
当我们使用默认的构造方法创建了一个ArrayList实例,在默认的情况下,当前实例的底层数组长度是为空的,当我们第一次调用该实例中的方法的时候,会将该数组大小设置为默认值10,ArrayList底层的数组是会随着我们元素的个数的增多,会进行扩容。ArrayList源码中有一个grow()方法,当我们调用add()方法的时候,ArrayList会先进行当前数组的最大容量(记为A),和我们(之前添加的数据个数+将要添加的数据个数 记为B)进行比对,如果A>B则正常的添加元素即可,否则则会调用grow()进行数组的扩容,扩容的方法是,我们会用B-A和A/2进行比较,如果B-A<A/2(B-A就是当前所需要的最小容量 A就是当前数组的最大容量),那么就采用默认的扩容机制,数组大小扩容为原来的1.5倍,这里的扩容是通过创建新的数组,然后讲原来的数组的元素移动到新的数组来完成的,效率较低,因此建议在初始化ArrayList的时候,就指定默认的数组大小,降低数组扩容的次
数从而提高效率。
添加元素
ArrayList使用add方法进行添加元素,add方法默认的情况下是采用尾插法进行元素的添加。也可以使用add(index,value) 指定元素插入的位置。
遍历
- 可以使用for循环遍历
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("张三");
for( var i = 0; i < list.size(); i ++){
System.out.println(list.get(i))
}
- 使用迭代器遍历
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("张三");
System.out.println(list);
ListIterator<String> sli = list.listIterator();
while (sli.hasNext()) {
System.out.println(sli.next());
}
//此时光标已经在最下面了
while (sli.hasPrevious()) {
System.out.println(sli.previous());
}
1.2 LinkedList集合
- 底层为双向带头链表
- 增删快,查找慢
- 非线程安全
- 实现了Serializable接口,因此它支持序列化
- 没有长度概念,理论来说容量无限
特点:
底层数据结构为带头双向链表,所以其特点为增删快,其增加删除元素只需要修改其指针的指向即可,不需要涉及到数据元素的移动,增删操作的时间复杂度为O(1) 就是因为其这样的特点,数据存储的不连续,导致其对数据的索引效率很低,需要从头节点进行遍历查找。底层的查询方法使用的是二分查找法,查找的时间复杂度为O(log2^n)。
它是非线程安全的,只在单线程下适合使用。
LinkedList没有长度的概念,所以不存在容量不足的问题。
添加元素:
插入元素时,需要新增一个节点,将新的元素设置为该节点的存储值,修改新节点的前驱为last节点的后继。新的节点作为链表的尾节点。
2.Set接口
Set接口的特点:
- 元素一旦存入,就会变得无序,不可能按照存入顺序,再取出
- 元素不可重复,最多只允许包含一个null
Set接口的方法:
由于其继承自Collection,所以方法和List接口一致,遍历不可根据索引,使用增强for循环。
2.1 HashSet集合
- HashSet的实现是依赖于HashMap
- 使用迭代器进行遍历是调用了map.keySet().iterator()
- HashSet实际上就是HashMap中键值对中的值的一半
- HashSet集合中存储对象,必须重写equals和hashcode方法
特点:
HashSet构造方法是创建了一个HashMap,所以我们可以说HashSet的实现是依赖于HashMap,我们在对HashSet使用迭代器进行遍历的时候,实际上也是调用了map.keySet().iterator(),所以HashSet实际上就是HashMap中键值对中的值的一半,在比如说调用HashSet中的add方法,实际上就是调用了map.put(e, PRESENT) == null。在使用add方法时,必须要对 equals()和hashcode()方法进行重写 ,保证对象不会在集合中重复存储。
重写equals()和hashcode()方法的必要性:
我们都知道,java的机制决定了当我们new创建对象时。即使两个对象的内容一模一样,它们的内存地址也不一样。hashcode()是Object类的方法,其作用是用来获取Hash码,返回值是一个int类型的整数。hash是当前对象在hash表中的索引位置。这会造成一种现象:即使是两个对象的内容一模一样,它们的hash值却不一定相等。当我们在HashMap中存储元素时,会自动调用equals()方法去比较集合中的对象和将要存储的对象的内存地址,这样无论如何比较,得到的永远是false。所以我们必须重写hashcode和equals方法,让代码帮我们比较它们的内容。以此来保证HashMap中存储内容不相同的元素。
存储对象示例:
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
class Car{
private String carId;
private String color;
private String brand;
//有参无参,getter和setter省略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Objects.equals(carId, car.carId) && Objects.equals(color, car.color) && Objects.equals(brand, car.brand);
}
@Override
public int hashCode() {
return Objects.hash(carId, color, brand);
}
}
public class Demo2 {
public static void main(String[] args) {
Set<Car> carSet = new HashSet<>();
carSet.add(new Car("豫A.88888","银色","保时捷"));
carSet.add(new Car("豫A.66666","火烈鸟","法拉利"));
carSet.add(new Car("豫A.QQ123","军绿色","拖拉机"));
Car car1 = new Car("豫A.12345","黑色","五菱之光");
Car car2 = new Car("豫A.12345","黑色","五菱之光");
System.out.println(car1.hashCode());//哈希值一样且内容也一样,则不能添加进集合。
System.out.println(car2.hashCode());//哈希值一样,内容不一样则能添加进集合
System.out.println(carSet.add(car1));//返回true
System.out.println(carSet.add(car2));//返回false
for (Car car : carSet) {
System.out.println(car);
}
}
}
2.2 TreeSet集合
- 底层依靠TreeMap实现,TreeMap底层是红黑树、故元素有序
- 添加的元素要实现Comparable或者添加操作时实现Comparator接口
- 添加元素较为繁琐,删除查找时需要遍历二叉树
- 效率低,时间复杂度为O(logN)
特点:
TreeSet的底层的实现时依靠TreeMap,而TreeMap的底层是红黑树,所以其元素是有序的,这就导致了一个问题,要么这个元素具有自然顺序,要么用户给这个元素增加一个Comparable的能力,要么在进行add操作的时候,提供Comparator比较方式,这就导致其添加元素较为繁琐,同样其在进行删除,查找等操作的时候需要遍历这棵二叉树, 效率较低,时间复杂夫为O(logn)。
存储对象示例:
如果想要在TreeSet集合中添加对象,那么必须实现Comparable()接口,重写compareTo方法,让其对对象内部的int属性进行排序。
抽象方法:
int compareTo(T o)将此对象与指定的对象进行比较以进行排序。
返回一个负整数,0,或者正整数,表示该对象小于、等于、或大于该对象
实现Comparable接口重写方法
package com.lzl.day017;
import java.util.Set;
import java.util.TreeSet;
class Student implements Comparable<Student>{
private String name;
private Integer age;
//省略构造和getter和setter方法
@Override
public int compareTo(Student o) {
int num = this.age - o.age;
return num;
}
}
public class Demo3 {
public static void main(String[] args) {
Set<Student> studentSet = new TreeSet<>();
studentSet.add(new Student("大飞", 25));
studentSet.add(new Student("任老板", 26));
studentSet.add(new Student("UZI", 23));
studentSet.add(new Student("厂长", 30));
for (Student s : studentSet) {
System.out.println(s);
}
}
}
使用比较器的方法实现存储
package com.lzl.day018;
import java.util.Comparator;
import java.util.TreeSet;
class Weapon{
private Integer id;
private String name;
private String description;
//省略无参有参,getter和setter,toString方法
}
class MyComparator implements Comparator<Weapon> {
@Override
public int compare(Weapon o1, Weapon o2) {
int num = o1.getId() - o2.getId();
if (o1.getId() == o2.getId()&& o1.getName().compareTo(o2.getName())!=0){
return o1.getName().compareTo(o2.getName());
}
if (o1.getId() == o2.getId() && o1.getName().compareTo(o2.getName())==0){
return o1.getDescription().compareTo(o2.getDescription());
}
return num;
}
}
public class Demo {
public static void main(String[] args) {
TreeSet<Weapon> weapons = new TreeSet<>(new MyComparator());
weapons.add(new Weapon(3,"赤霄","传说是一把帝道之剑,汉高祖刘邦曾用它斩杀白蛟"));
weapons.add(new Weapon(4,"泰阿(太阿)","泰阿剑是一把诸侯威道之剑,早已存在,只是无形无迹,但是剑气早已存于天地之间,只等待时机凝聚起来,天时、地利、人和三道归一,此剑即成。"));
weapons.add(new Weapon(5,"七星龙渊","剑传说是由欧冶子和干将两大剑师联手所铸。" +
"欧冶子和干将为铸此剑,凿开茨山,放出山中溪水,引至铸剑炉旁成北斗七星环列的七个池中,是名“七星”。剑成之后,俯视剑身,如同登高山而下望深渊,飘渺而深邃,仿佛有巨龙盘卧。是名“龙渊”。后改名为龙泉剑"));
weapons.add(new Weapon(1,"轩辕剑","黄金色之千年古剑,传说是天界诸神赐予轩辕黄帝击败蚩尤之旷世神剑;其内蕴藏无穷之力,为斩妖除魔的神剑。"));
weapons.add(new Weapon(2,"湛卢","君贤能,剑在侧,国兴旺。君无能,剑飞弃,国破败。五金之英,太阳之精,出之有神,服之有威。"));
weapons.add(new Weapon(9,"纯钧","剑是天人共铸的不二之作。为铸这把剑,千年赤堇山山破而出锡,万载若耶江江水干涸而出铜。铸剑之时,雷公打铁,雨娘淋水,蛟龙捧炉,天帝装炭。铸剑大师欧冶 子承天之命呕心沥血与众神铸磨十载,此剑方成。剑成之后,众神归天,赤堇山闭合如初,若耶江 波涛再起,欧冶子也力尽神竭而亡,这把剑已成绝唱."));
weapons.add(new Weapon(10,"承影","天色愈暗,长剑又归于无形,远古的暮色无声合拢,天地之间一片静穆。"));
weapons.add(new Weapon(7,"莫邪","干将、莫邪是两把剑,但是没有人能分开它们。干将、莫邪是两个人,同样也没有人能将他(她)们分开。"));
weapons.add(new Weapon(6,"干将","干将、莫邪是两把剑,但是没有人能分开它们。干将、莫邪是两个人,同样也没有人能将他(她)们分开。"));
weapons.add(new Weapon(8,"鱼肠","夫专诸之刺王僚,飞鹰击殿"));
//测试数据
weapons.add(new Weapon(1,"假的轩辕剑","黄金色之千年古剑,传说是天界诸神赐予轩辕黄帝击败蚩尤之旷世神剑;其内蕴藏无穷之力,为斩妖除魔的神剑。"));
weapons.add(new Weapon(1,"假的轩辕剑","天界诸神赐予轩辕黄帝击败蚩尤之旷世神剑;其内蕴藏无穷之力,为斩妖除魔的神剑。"));
for (Weapon weapon : weapons) {
System.out.println(weapon);
}
}
}
三、双列集合详解
1、Map集合
特点:
Map是双列集合的顶级接口,存储的是键值对映射,一个键对应一个值,底层采用双边队列
常用方法
增:
- v put(k key , v value); 向集合中添加数据。
【注意】键key必须是唯一的。- void putAll(Map<? extends K> k,<? extends V> v);将一个Map集合存入另一个Map集合。
删:
- remove(K key); 返回值是删除的value。
改:
- v put(K key,V value);当键值存在的时候,会覆盖原来的内容。
查:
- int size(); 获得集合中元素的个数。
- boolean isEmpty(); 是否为空。
- boolean containsKey();是否包含键名。
- boolean containsValue();是否包含值。
- v get(K key); 通过键名获取值。
- set< k > keySet(); 获取map集合中的键,然后存到Set集合。
- Collection< v > values(); 获取map集合的值,然后存在Collection集合里边。
- Set< Map.Entry< K,V >> entrySet(); 将map集合的键值对,存到Set集合。
Map.Entry方法:
getKey():获取键值对的键
getValue():获取键值对的值
1.1.HashMap
特点:
- 非线程安全
- 无序键值对
- 1.7之前是哈希表+链表
- 1.8哈希表+链表+红黑树
- 当HashMap中的元素个数超过数组大小*负载因子时,就会进行数组扩容
- 默认长度为16,负载因子为0.75,
1.1.1、LinkedHashMap
特点:
- LinkedHashMap是基于HashMap实现的,LinkedHashMap重写了HashMap,在其基础上在Entry节点上增加了一个next元素,用来指向当前节点的下一个节点,即:HashMap和双向链表的合二为一
- 可以实现元素按照插入的顺序来进行顺序的输出
- LinkedHashMap的key 和value都可以为空
- 非线程安全
1.2.ConcurrentHashMap
特点:
- 线程安全
- key和value均不可以为null
- 在JDK1.8之前,采用分段锁机制来保证线程安全的,一定程度上提高了并发执行效率
- 从JDK1.8开始, ConcurrentHashMap数据结构与1.8中的HashMap保持一致,均为数组+链表+红黑树
- 通过乐观锁+Synchronized来保证线程安全
1.3.TreeMap
特点:
- 可以实现元素的有序排列,需要提供比较器,或者实现Comparble接口
- 底层基于红黑树实现
- 非线程安全
- key不可为null
- 存储元素需要自己传入比较器,或者元素自然有序,根据key值排序
4.HashTable
特点:
- 线程安全
- key和value均不可以为null
- 通过给整张散列表加锁的方式来保证线程安全,并发执行效率底下
- 处理哈希冲突可以使用,拉链法,开放寻址法等