文章目录
- Hinge Loss 和 Zero-One Loss
- Hinge Loss
- Zero-One Loss
Hinge Loss 和 Zero-One Loss
维基百科:https://en.wikipedia.org/wiki/Hinge_loss

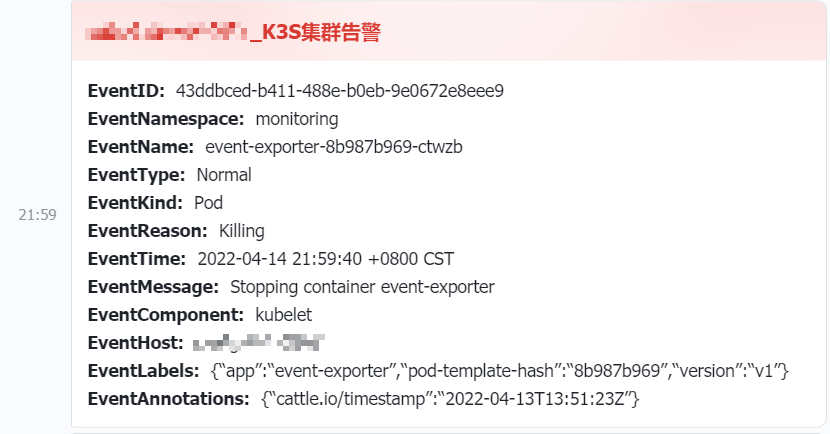
图表说明:
- 纵轴表示固定 t = 1 t=1 t=1 的 Hinge loss(蓝色)和 Zero-One Loss(绿色)的值,而横轴表示预测值 y y y 的值。
- 该图显示,Hinge loss 惩罚了预测值 y < 1 y < 1 y<1,对应于支持向量机中的边际概念。
Hinge Loss
Hinge Loss是一种常用的机器学习损失函数,通常用于支持向量机(SVM)模型中的分类问题。该函数的定义如下:
L
(
y
,
f
(
x
)
)
=
max
(
0
,
1
−
y
i
⋅
f
(
x
)
)
f
(
x
)
=
w
T
x
i
+
b
(1)
L(y, f(x)) = \max(0, 1 - y_i \cdot f(x)) \\ f(x)=w^{\mathrm{T}}x_i+b \tag{1}
L(y,f(x))=max(0,1−yi⋅f(x))f(x)=wTxi+b(1)
其中,
y
i
y_i
yi 是样本的真实标签,
f
(
x
)
f(x)
f(x) 是模型的预测值。该函数的取值范围是非负实数,当预测值和真实值之间的误差越大时,损失函数的值越大。
当样本被正确分类时,即 y i ⋅ f ( x ) > 0 y_i \cdot f(x) > 0 yi⋅f(x)>0,此时 Hinge Loss 的取值为0,表示模型分类正确,没有产生误差。
当样本被错误分类时,即 y i ⋅ f ( x ) < 0 y_i \cdot f(x) < 0 yi⋅f(x)<0,此时 Hinge Loss 的取值为 1 − y i ⋅ f ( x ) 1 - y_i \cdot f(x) 1−yi⋅f(x),表示模型的分类错误,并且分类误差越大,Hinge Loss 的值就越大。
Hinge Loss 的目标是最小化分类误差,同时鼓励模型产生较大的间隔(即正确分类和分类超平面之间的距离)。
在支持向量机中,目标是找到一个最大间隔的超平面来分类样本,因此,可以将 Hinge Loss 和间隔相关联。对于一个样本点
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi),其与超平面之间的距离为:
y
i
w
T
x
i
+
b
∥
w
∥
(2)
\frac{y_i w^T x_i + b}{\|w\|} \tag{2}
∥w∥yiwTxi+b(2)
其中,
w
w
w 和
b
b
b 是支持向量机模型中的权重和偏置。将这个距离记为
γ
i
\gamma_i
γi,可以将 Hinge Loss 重新表达为:
L
(
y
i
,
f
(
x
i
)
)
=
max
(
0
,
1
−
y
i
(
γ
i
∥
w
∥
)
)
(3)
L(y_i, f(x_i)) = \max(0, 1 - y_i (\gamma_i \|w\|)) \tag{3}
L(yi,f(xi))=max(0,1−yi(γi∥w∥))(3)
因此,Hinge Loss 不仅能够表达分类误差,还能够促进模型产生较大的间隔,从而增加模型的泛化能力。
Zero-One Loss
Zero-One Loss 是机器学习中的一种常见的分类损失函数。对于一个二分类问题,假设
y
∈
−
1
,
1
y \in {-1, 1}
y∈−1,1 为真实标签,
f
(
x
)
f(x)
f(x) 为模型对样本
x
x
x 的预测值,Zero-One Loss 定义为:
L
(
y
,
f
(
x
)
)
=
{
0
if
y
=
f
(
x
)
1
otherwise
(4)
L(y, f(x)) = \begin{cases} 0 & \text{if } y = f(x) \\ 1 & \text{otherwise} \end{cases} \tag{4}
L(y,f(x))={01if y=f(x)otherwise(4)
也就是说,当模型的预测结果与真实标签一致时,Zero-One Loss为0;否则,Loss为1。从表达式上可以看出,Zero-One Loss对预测的错误惩罚非常高,因为无论错误的预测有多么接近正确,Loss都会被计算为1。与其他的损失函数相比,Zero-One Loss往往被认为是一种非常严格的评估方式。
然而,由于 Zero-One Loss 本身是不可导的,因此在训练模型时通常会选择使用一些可导的近似函数,如 Hinge Loss 或 Cross Entropy Loss 等。相对于 Zero-One Loss,这些损失函数更为平滑,可以帮助模型更快、更稳定地收敛。
需要注意的是,尽管 Zero-One Loss 在评估模型性能时非常严格,但在实际应用中往往不是最优的选择。特别是当数据集中的标签存在一定的噪声时,使用 Zero-One Loss 可能会导致模型过于拟合训练集,而无法有效地泛化到测试集。因此,在实际应用中,我们通常会使用更加平滑的损失函数,同时结合一些常见的正则化技术,如L1/L2正则化等,来控制模型的复杂度和泛化能力。