机器学习笔记目录
- 1.绪论(内容概述)
- 2.机器学习和深度学习的基本概念
- transformer
1.绪论(内容概述)
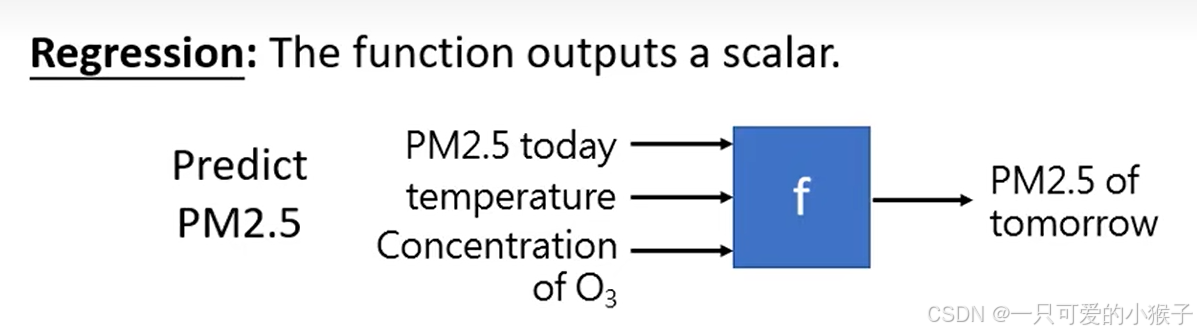
- 机器学习:让机器找一个函数,通过函数输出想要的结果。应用举例:语音识别,图像识别,alphago

- 深度学习:使用类神经网络去找一个函数
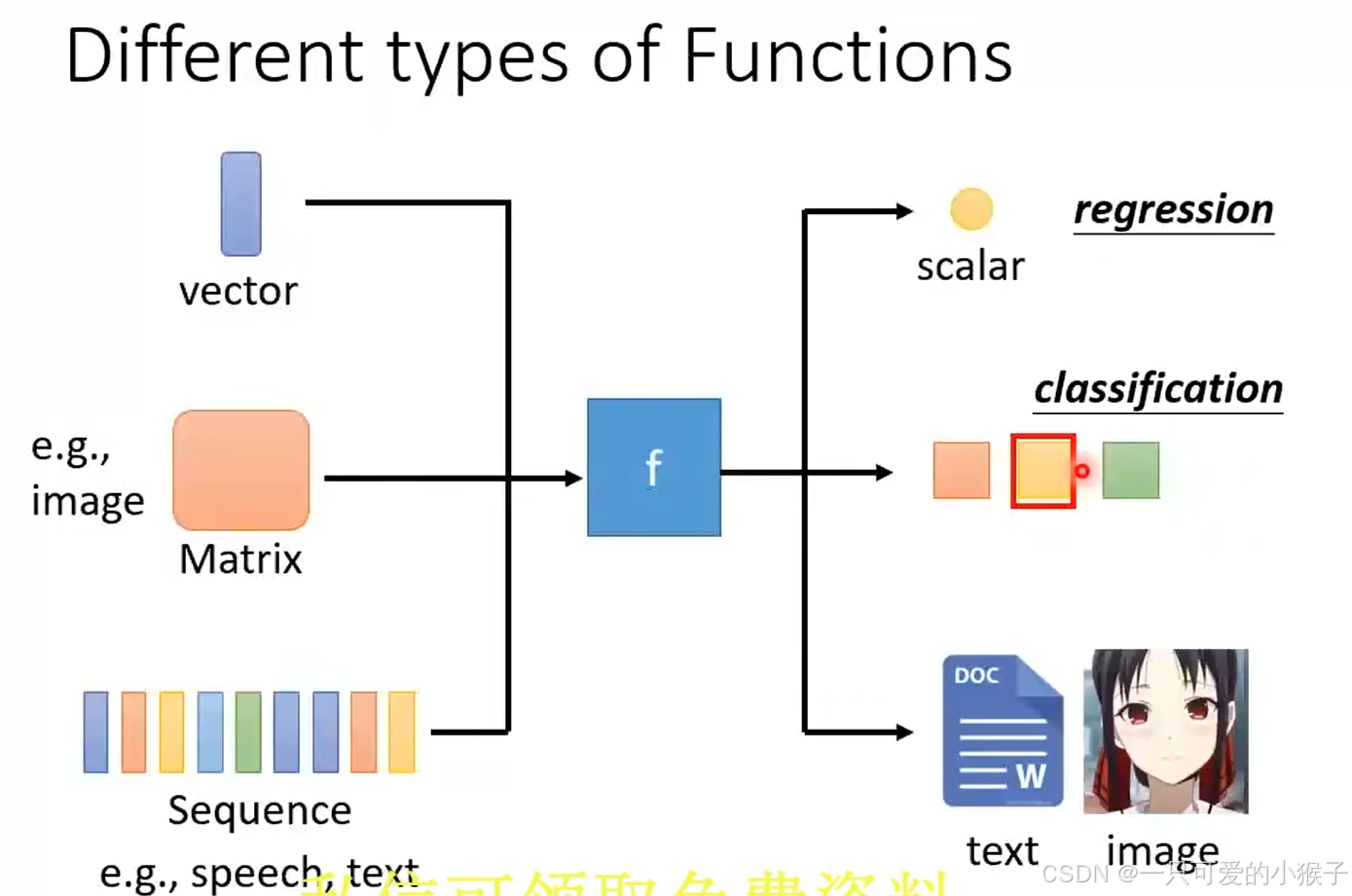
- 函数的输入可以是向量,矩阵(图像数据),序列(语音,一段文字),输出可以是一个数值(回归),一个类别(分类),一段文字或图片(结构化信息)
- 监督式学习:需要提前打标签,投喂学习
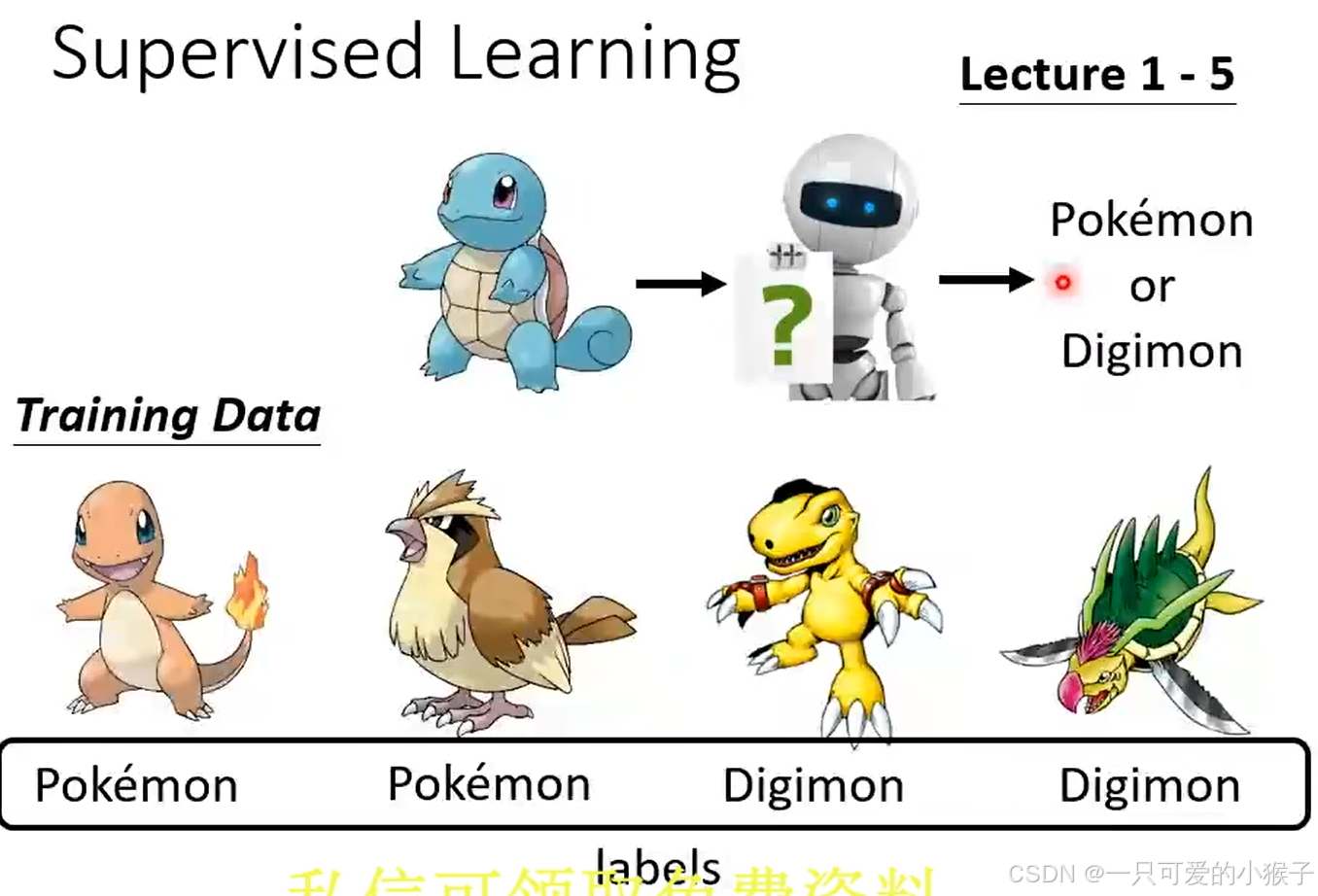
- 自监督式学习:不需要标记,在训练下游任务之前,会预训练(自己先学会如何分类)
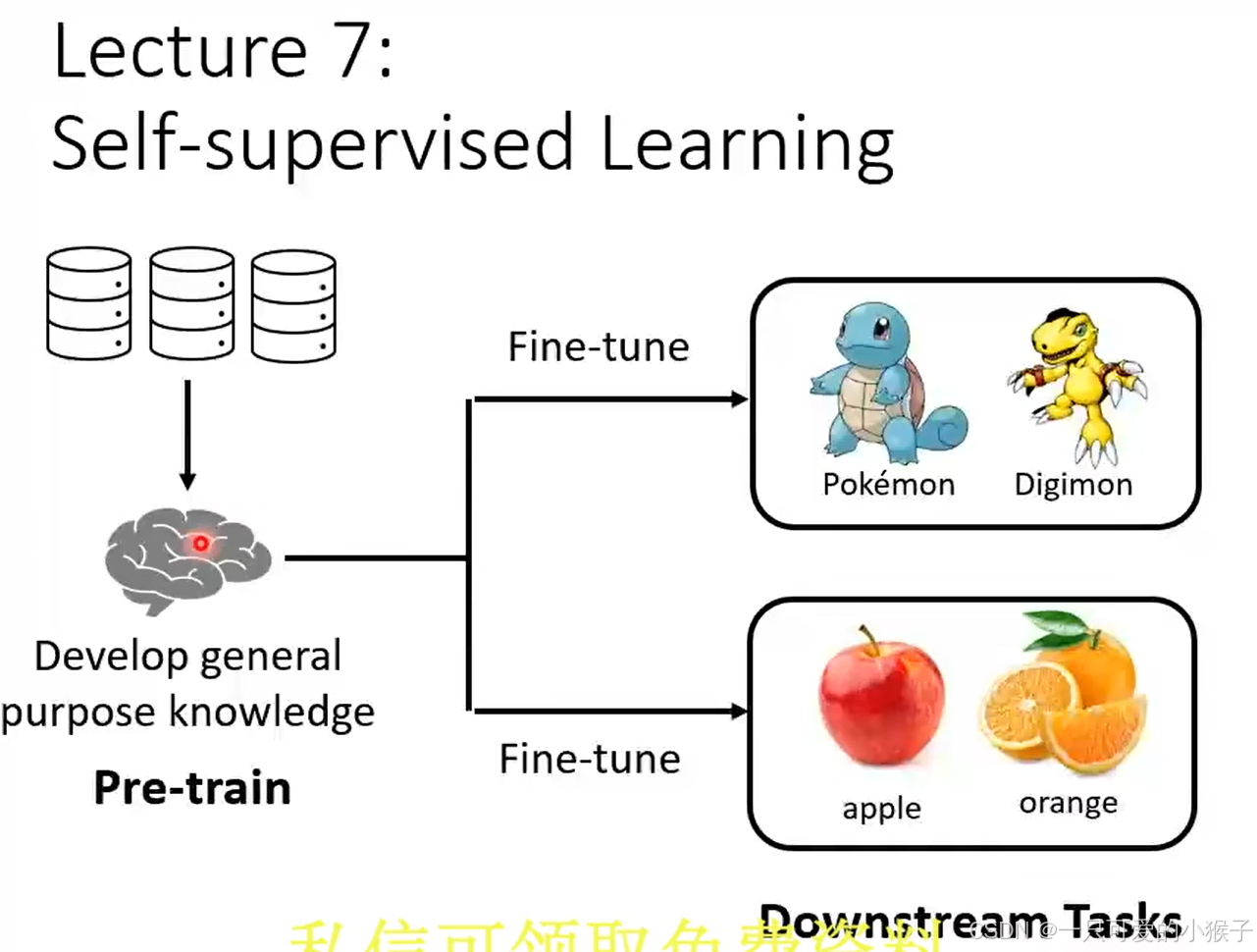
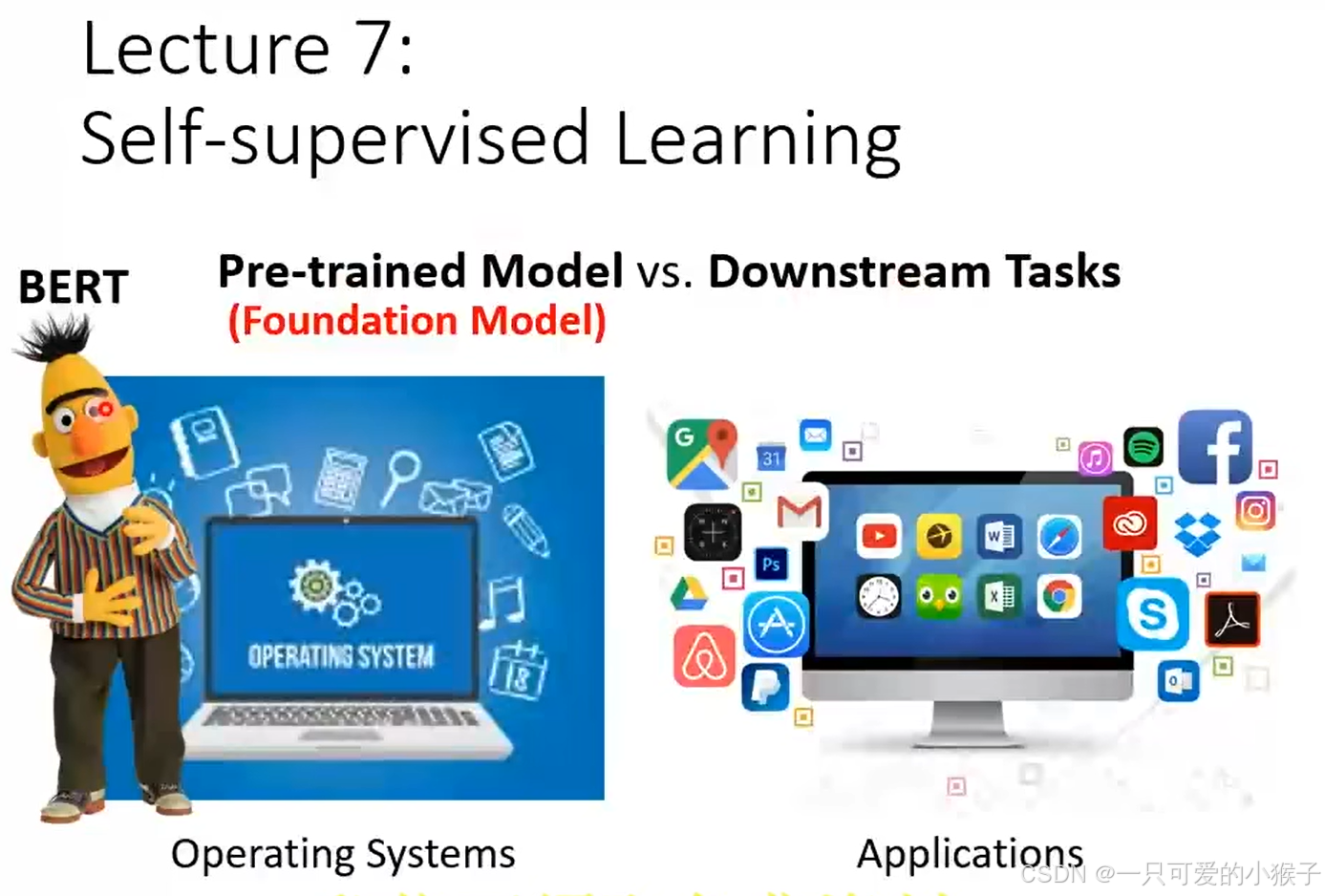
- 预训练模型和下游任务的关系就像操作系统和应用之间的关系一样,因为有了操作系统的支撑,所以开发应用才能如此便捷,预训练模型又称基础模型,经典的基础模型必然会提到BERT模型(有340M参数),后续又出现了更强的模型,例如,ELMo,GPT-2,GPT-3,T5等等
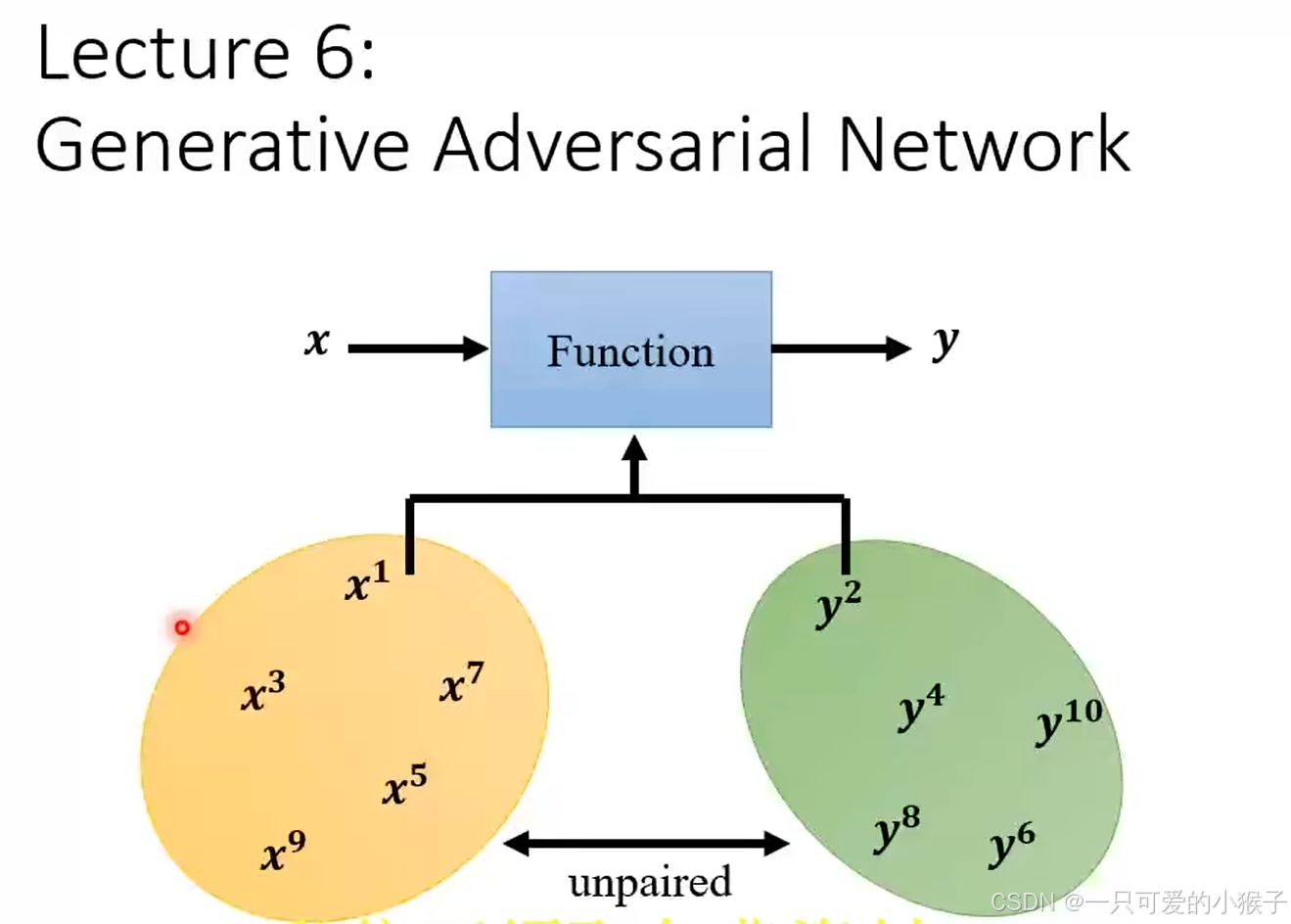
- 生成对抗网络:直接输入一系列x和一系列y,x与y之间不匹配,通过函数可以使x与y关联起来,例如输入很多段的语音,以及很多段的文字,对抗网络经过自我学习可以自动讲语音与文字结合起来,做到语音识别。
- 强化学习,当对数据的标记有困难时可以用强化学习,比如,教机器下围棋,人类也不知道该棋盘状态下那一步是最优的,但是人类知道下棋赢的规则,这个时候就可以使用强化学习,告诉机器赢的规则,让机器计算出最优的一步

- 异常检测是让机器具备异常检测的能力,比如在只投喂了A与B两类数据,面对C数据的测试,机器应该要具备说“我不知道”的能力,而不是在A与B中选择一个作为结果
- 可解释AI:让机器不仅能够辨别图片,还要让它说出这样分类的原因。
- 模型攻击:在图A上加上杂片干扰,模型使别之后结果完全不同

- 领域适配:将训练集和测试集统一,避免出现下图颜色不一样导致正确率大打折扣的问题

- 网络压缩:将网络压缩,这样可以将模型部署到资源受限的环境中,例如手表,无人机等

- 终身学习:希望机器能够自己学,越学越强大,就像有了自主思维一样可以自己思考学习
- 小样本学习(也叫做元数据学习):机器不再是根据人类告诉他的学习算法进行学习,而是机器根据数据自己思考出学习的算法,再根据算法学习,也就是机器要学会如何学习
2.机器学习和深度学习的基本概念
- 机器学习的底层就是为了找一个函数,根据输入,由函数来输出结果,函数有好几种类型,其中有回归(Regression),分类(Classification),结构性学习(Structured Learning)。
- 回归就是让函数输出一个数值,例如预测PM值,输入今天的空气含量值,通过函数可以预测明天的PM浓度,这个预测的过程就是一个回归的过程
- 机器学习拟合函数的过程可以分为以下几步
- 先根据特征构造一个带有未知参数的函数,其中除了已知特征值x以外,还应该具有w权重,b偏移值等

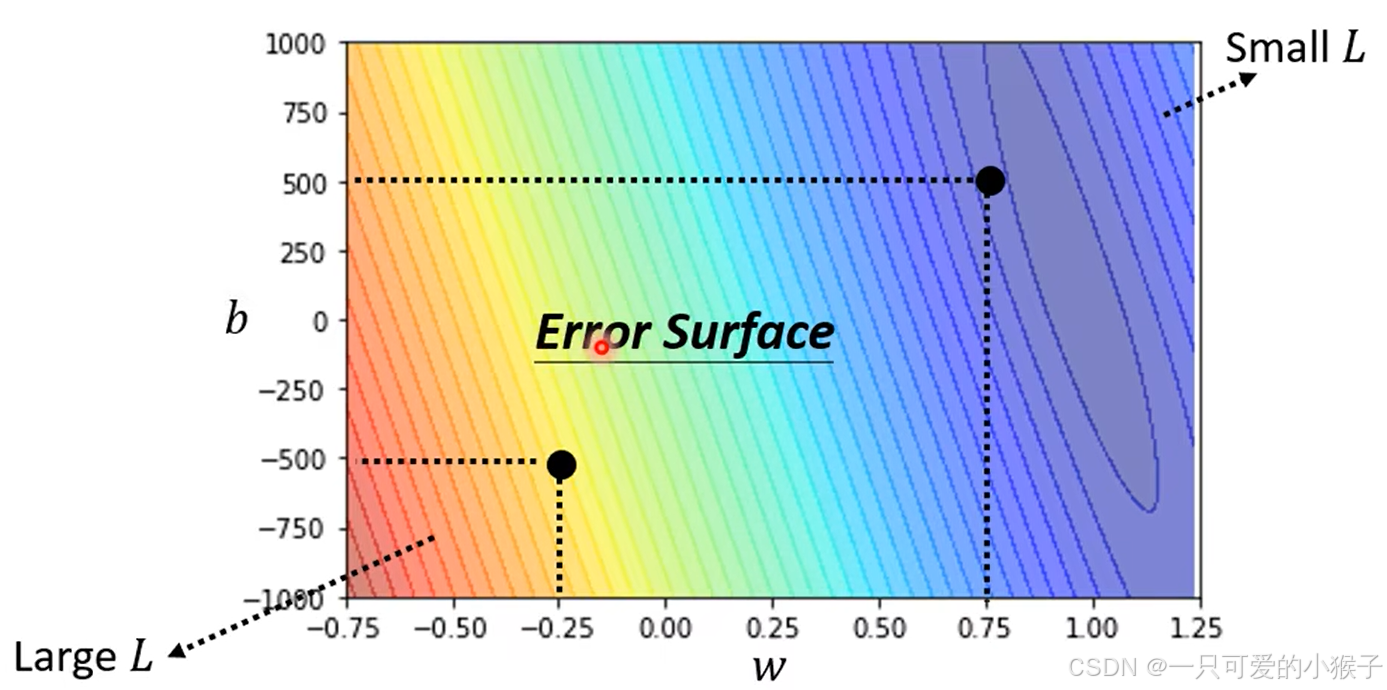
- 定义损失函数,损失函数的输入就是(w,b),输出就是判断训练出来的w和b的数值是否好,那么如何量化这个好的程度呢?我们可以根据已知数据,输入第a天的访问量,使用函数预测a + 1 天的访问量,再将预测结果与实际结果做差,计算出n天的差值,将所有差值进行平均求和,得到的数值就可以量化超参选的是否好,预测结果是否与实际结果较吻合,明显的,损失函数的值越小越好。此外根据对预测结果与实际结果的计算方式不同,可以分为两种平均绝对误差(MAE)和均方误差(MSE),除了这两种评价指标外,还有很多别的评价指标。特别的,如果预测结果和实际结果都是概率的话,我们通常会采用交叉熵(Cross-entropy)作为评价指标。根据选取不同的w和b计算损失值,可以画出误差曲面(error surfface)

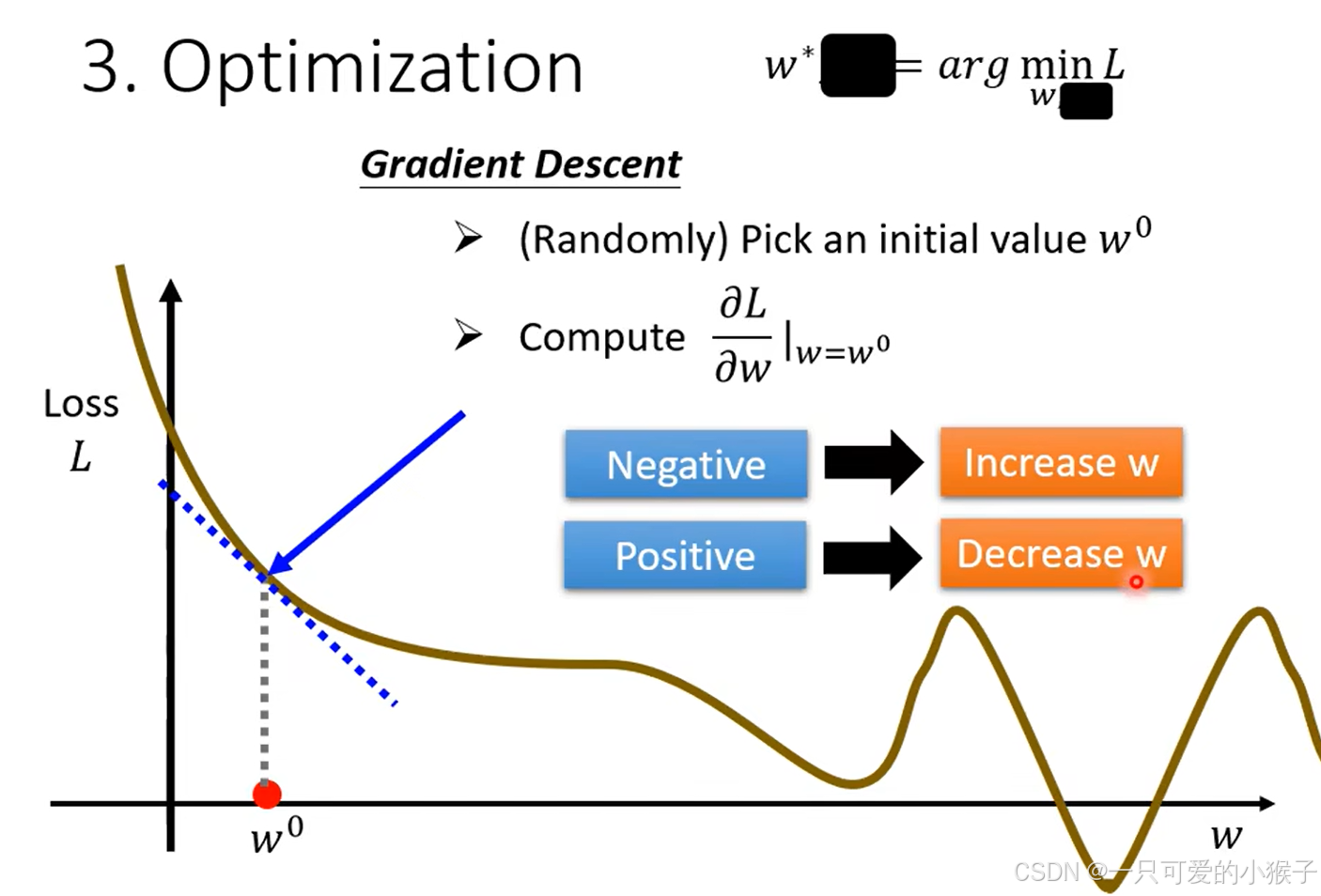
- 优化,方法:梯度下降。以只有一个参数w举例,随机选取 一个w0,计算在w0这一点w对L的微分(也就是斜率),如果斜率是负的,说明曲线在递减,那么随着w增大,Loss会更小,所以应该扩大w,如果斜率是正的,则相反,曲线呈递增状态,应该减小w,使loss减小。那么对w的增大或减小,到底应该一步增/减多少呢?我们使用一个学习速率η来表示一步的大小,这个参数是自设的超参,可以根据斜率的大小来设置的,如果斜率越抖,则w变化的幅度越大。这个方法有一个问题,因为当移动到斜率为0的地方,w就会停止移动了,但是有可能只是移动到了曲线上的一个较低点,不是整个曲线的最低点(出现了局部最优的问题)
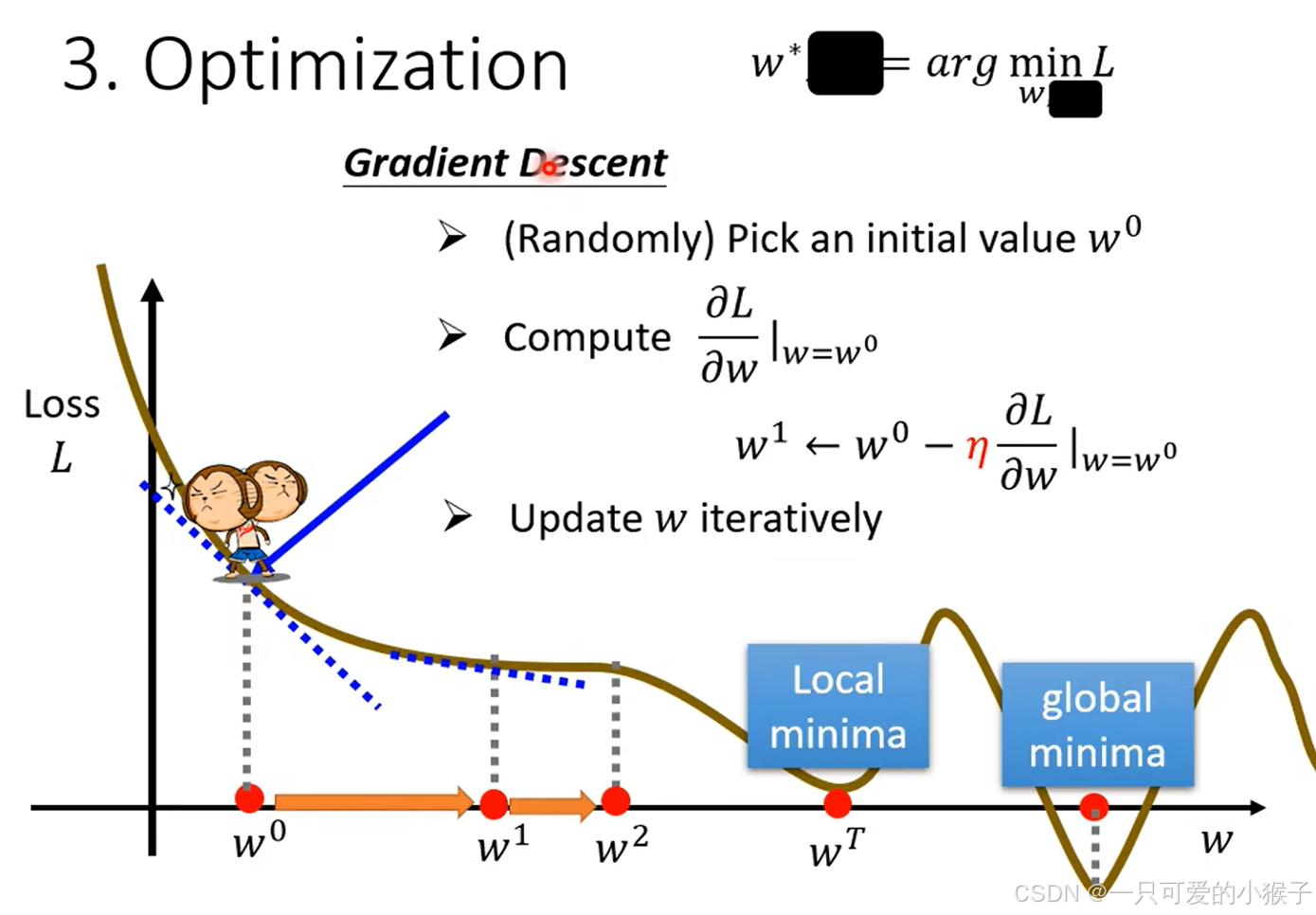
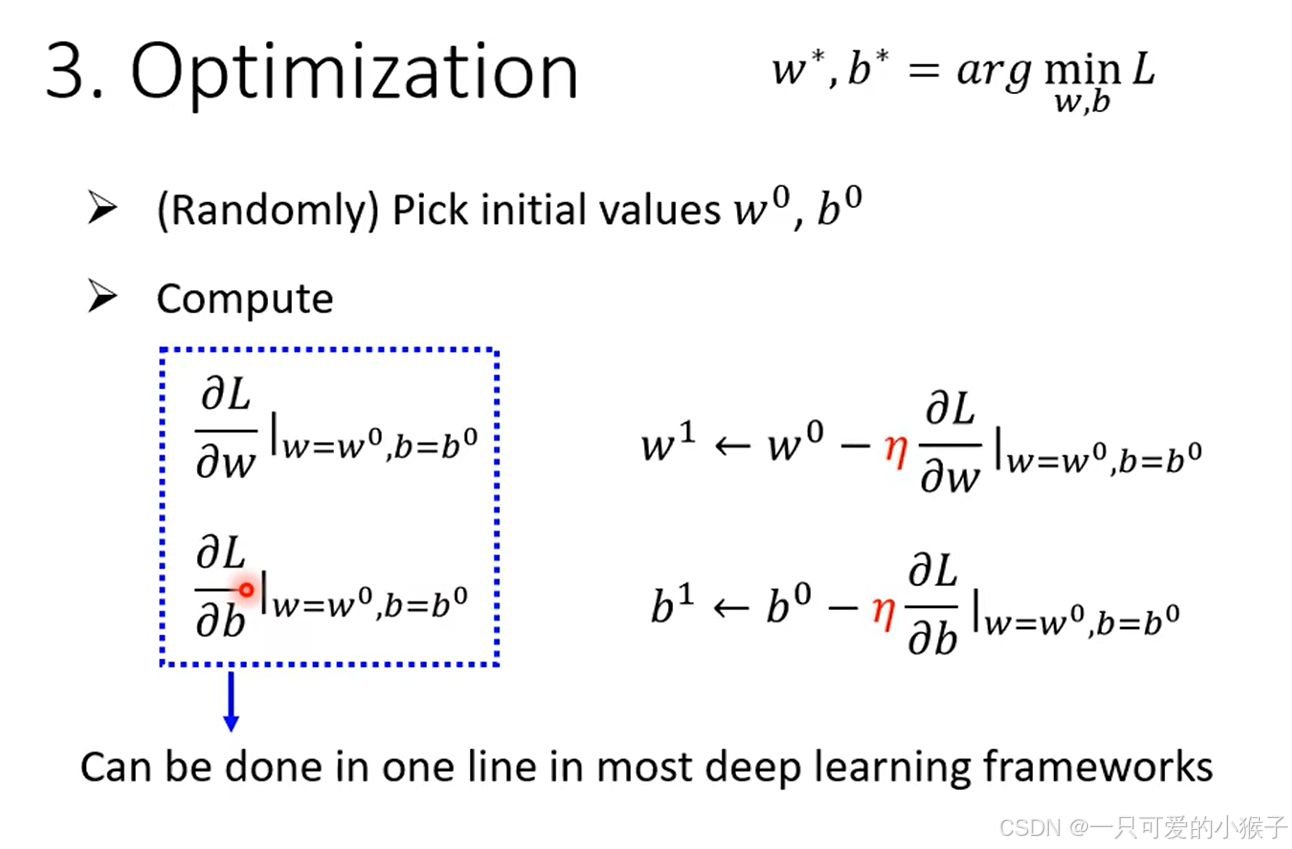
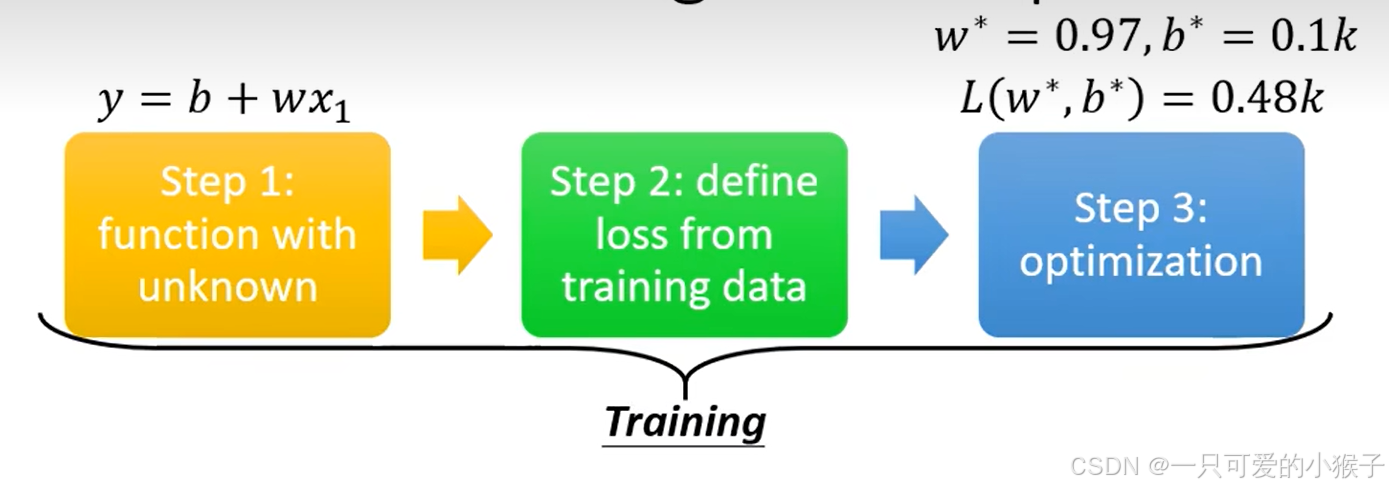
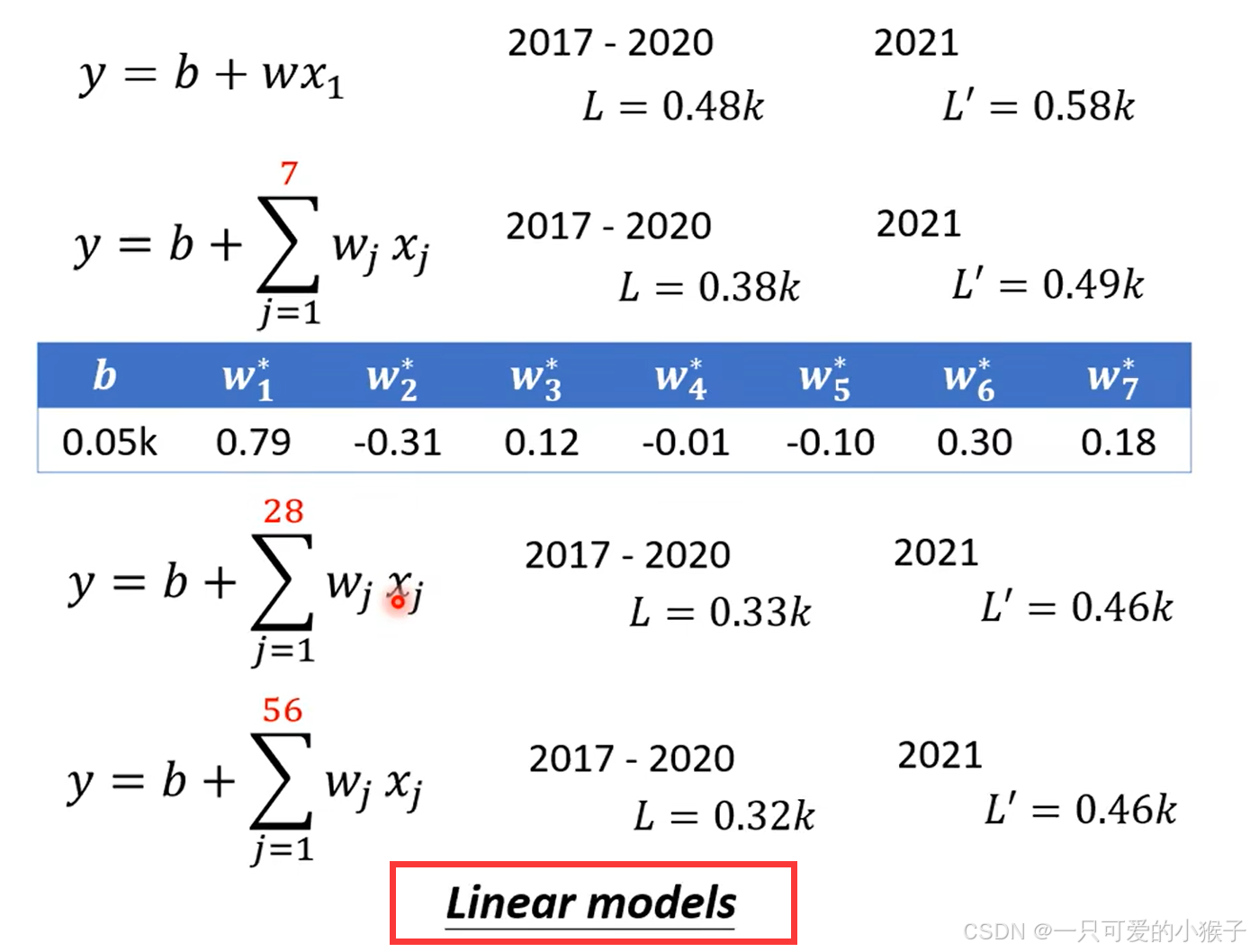
根据上述步骤完成之后,发现一开始设置的函数可能不太贴合数据,可以根据可视化的结果重新设置函数,将特征值×权重 + 偏移的这种构造方法叫做线性模型。根据下面的图我们可以看到,当函数进行修改后,误差是在不断减小的,说明根据数据的特有性,合理的设置函数非常重要,当然这个优化也是有局限的,所以除了最简单基础的线性模型以外,还应该探索更复杂的函数去拟合实际问题,使误差能够进一步的减少。
-
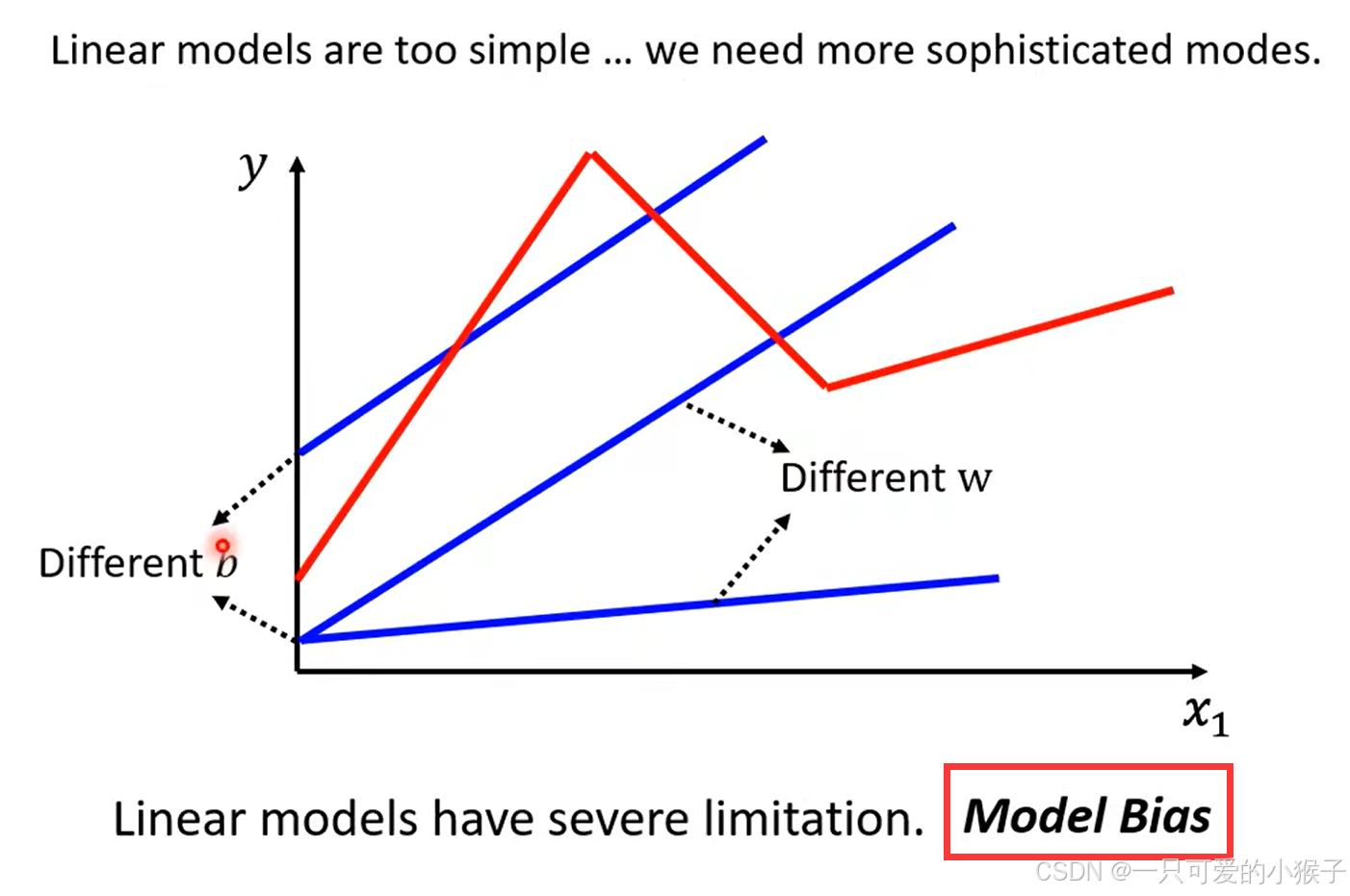
线性模型具有局限,不能更好的拟合曲线的波动,这样的问题我们可以称为model bias
-
红色函数可以通过函数+一堆蓝色函数去表示,当出现转角的时候就可以用一个蓝色函数去拟合
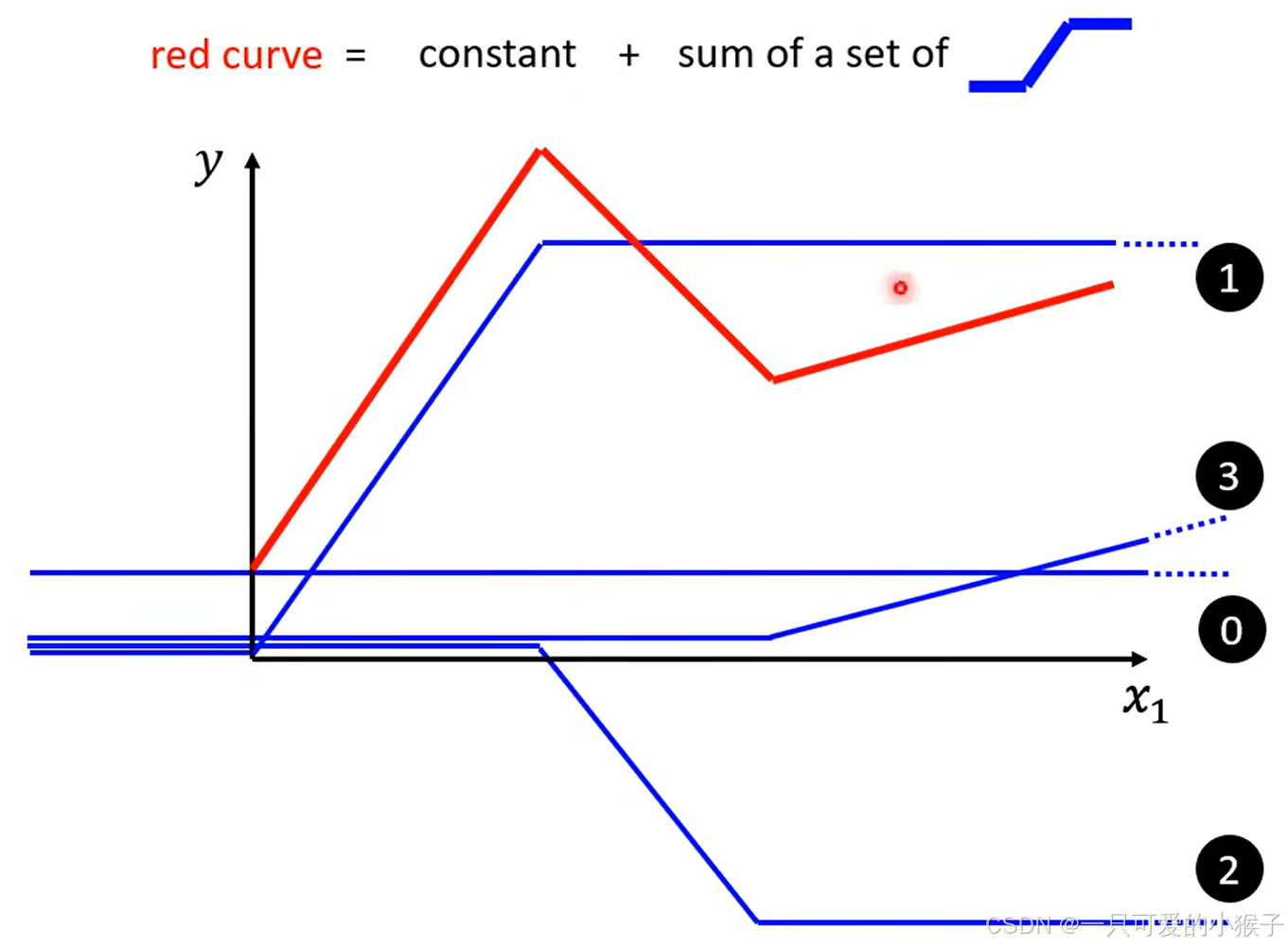
-
所有的分段线性曲线都可以通过常数项+蓝色函数进行拟合
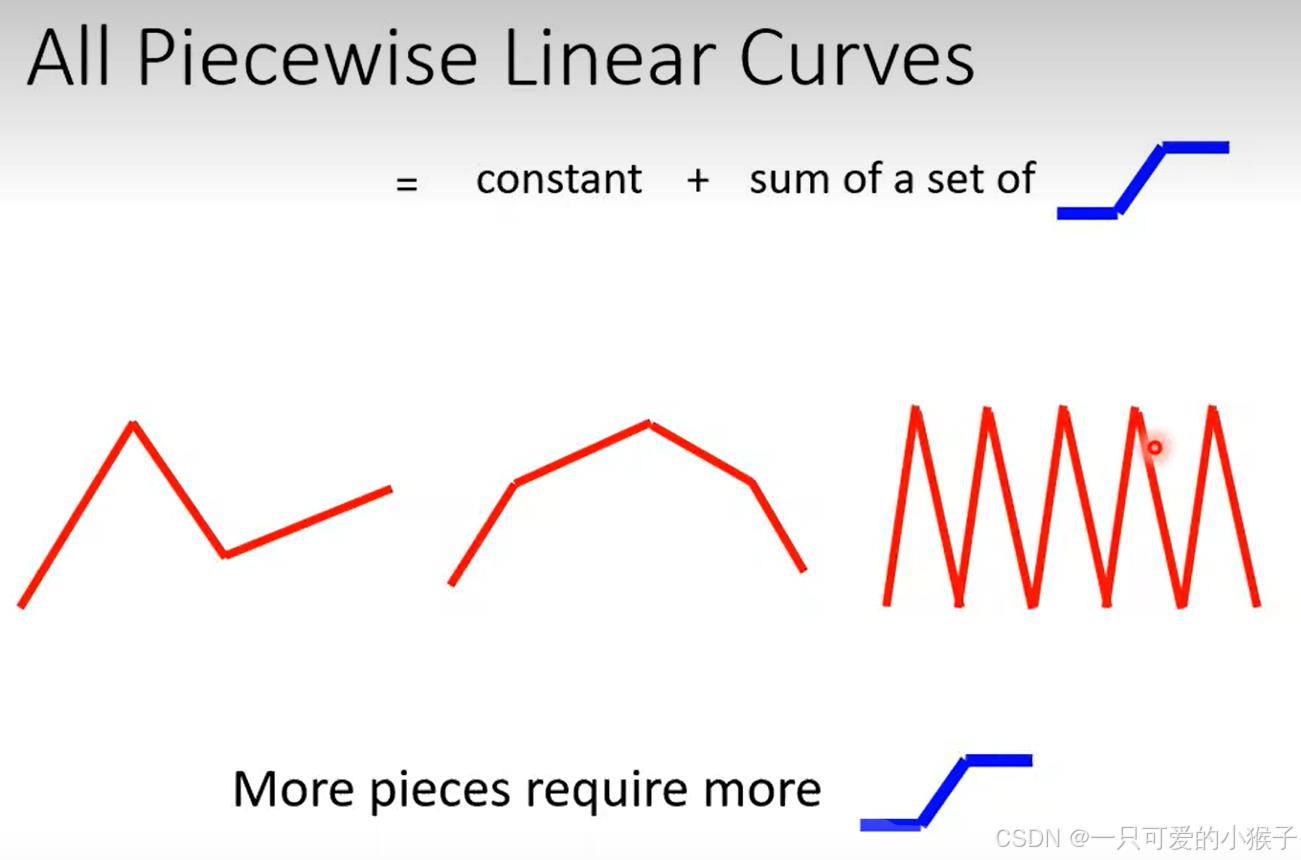
-
但是如果对于不是线性曲线,其实我们也是可以使用蓝色函数进行拟合的,只是需要的数量需要非常大。
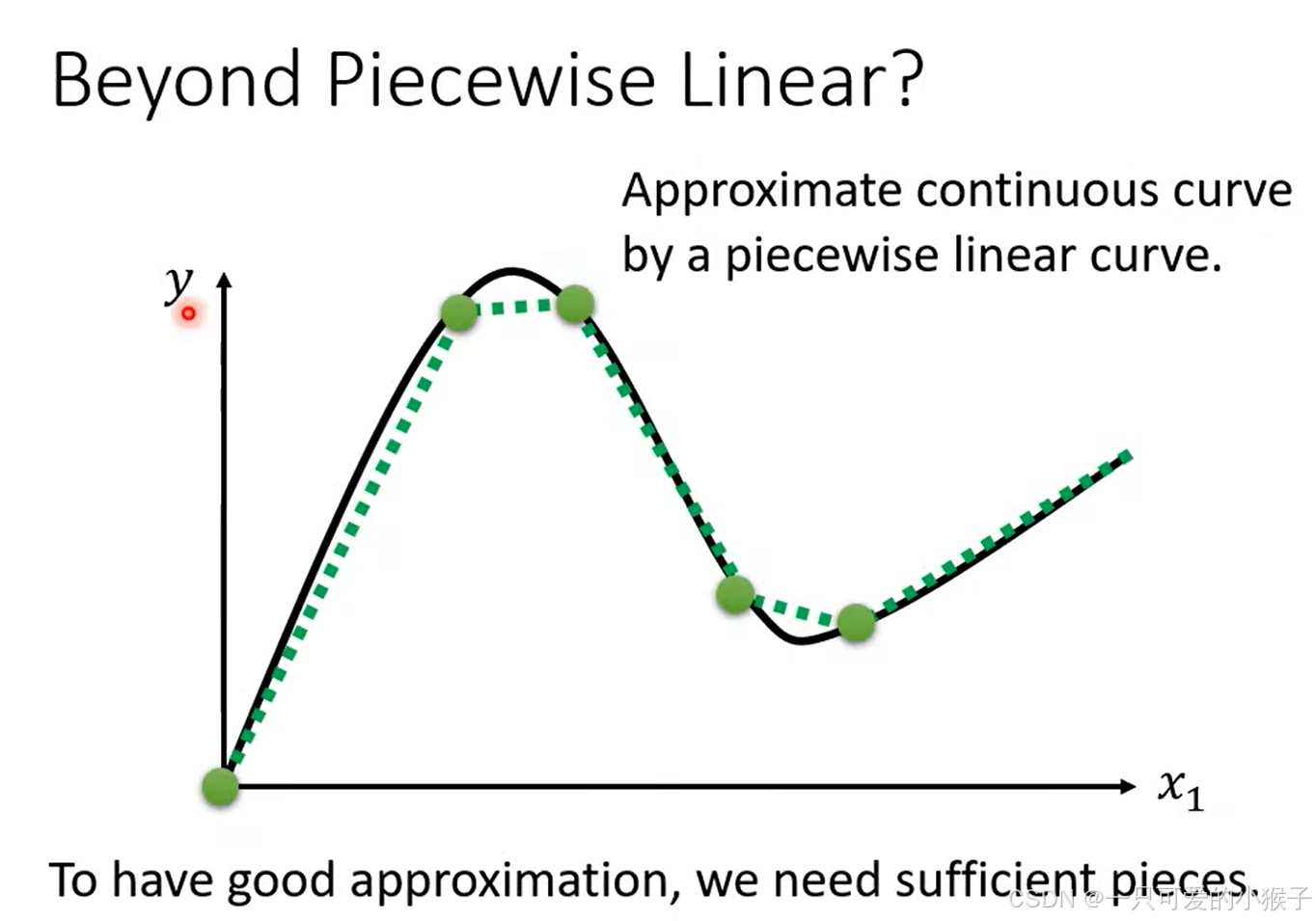
-
前面一直用蓝色函数进行代称,其实这个蓝色的函数通常叫做hard sigmoid,在实际应用中我们通常使用sigmod函数(s型函数)去拟合
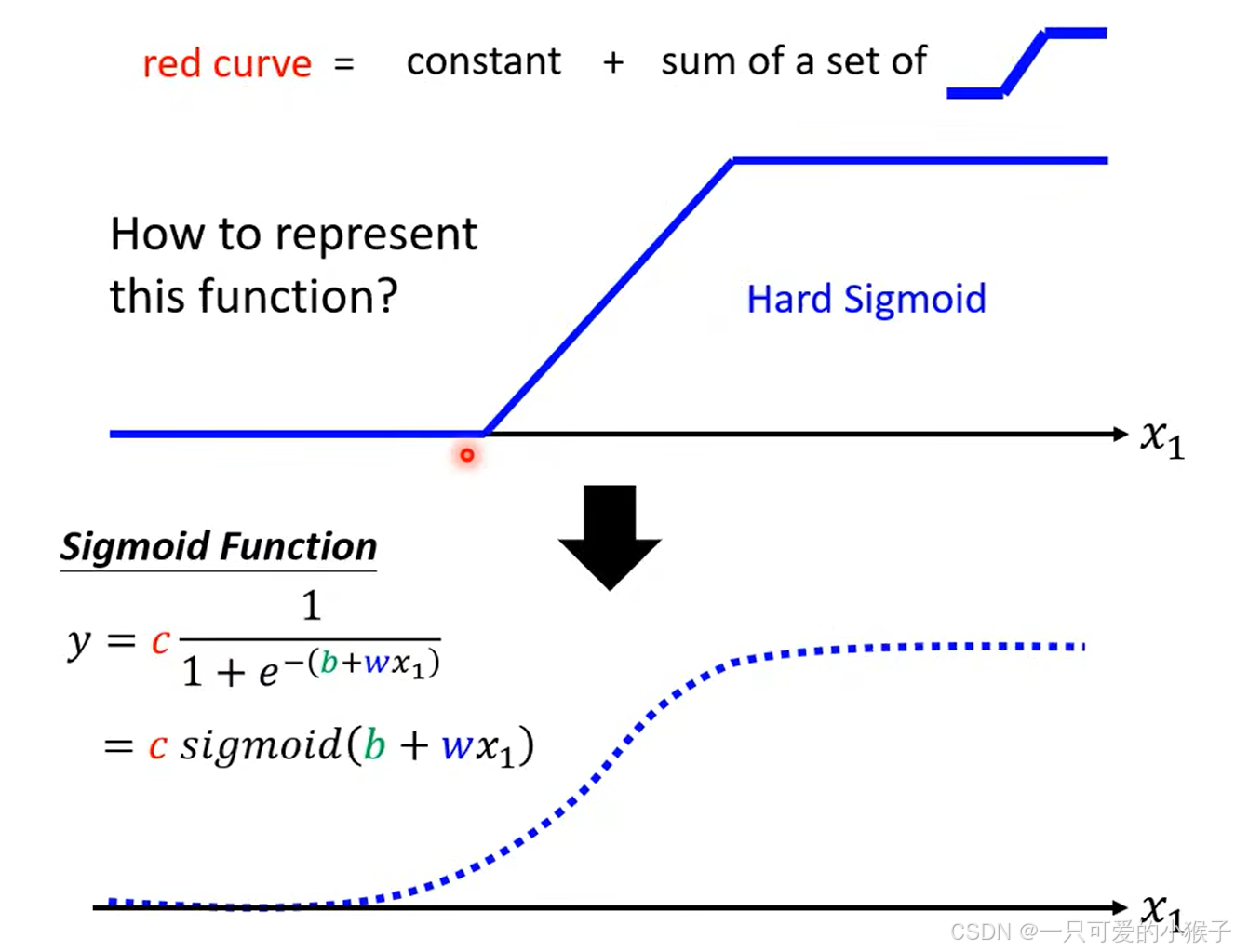
transformer
-
sequence-to-sequence的model,输入序列,输出也是一个序列,但是输出序列的长度由模型决定。
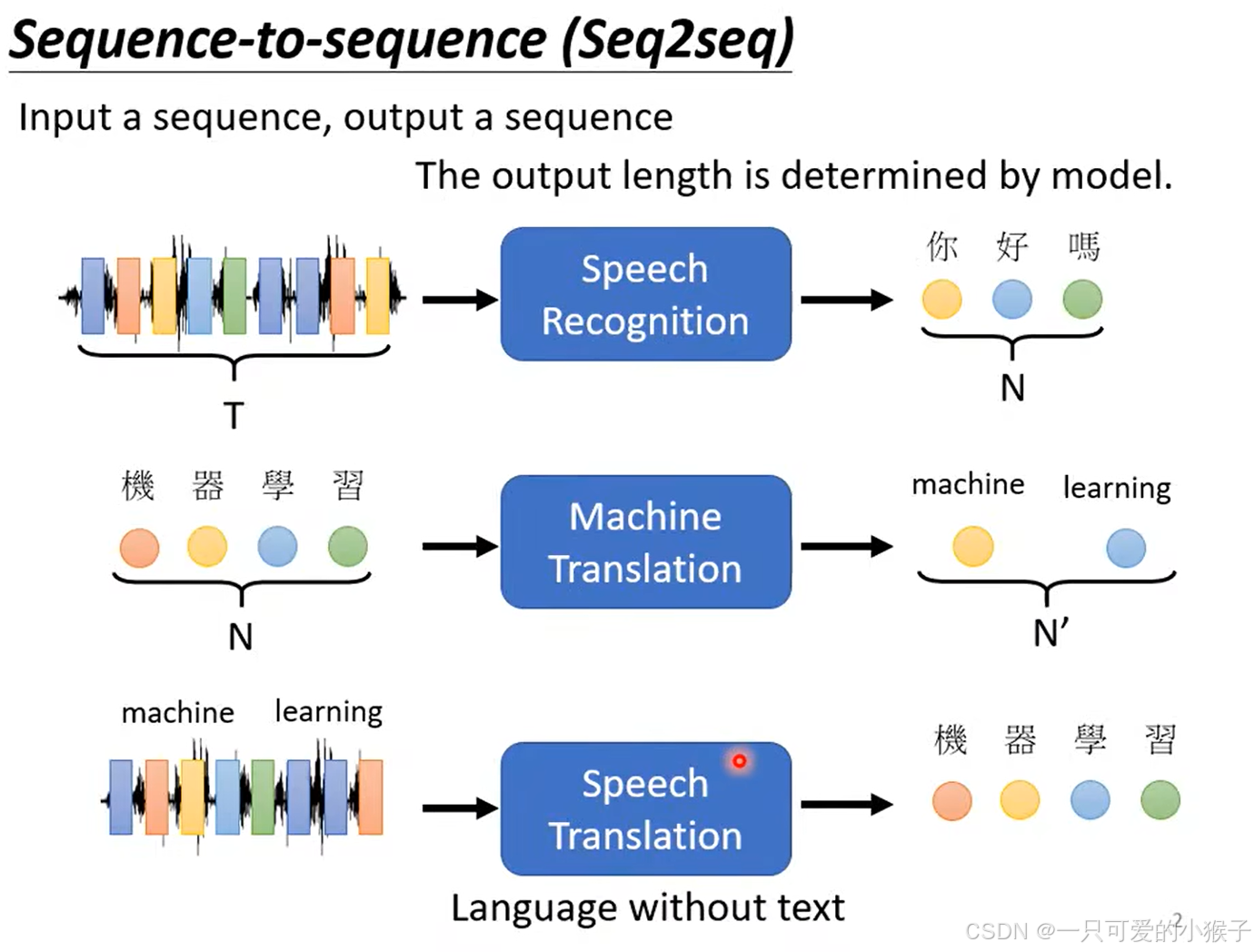
-
绝大多数的nlp问题都可以看成是问答问题(QA),所有的QA都可以使用seq2seq的模型进行求解。当然,针对各式各样的内容,例如语音辨识,能够专门根据语音的特性设计一个专用模型来处理,效果肯定是最佳的,但是这里想强调的是seq2seq的模型可以处理,但是不是最好用的。
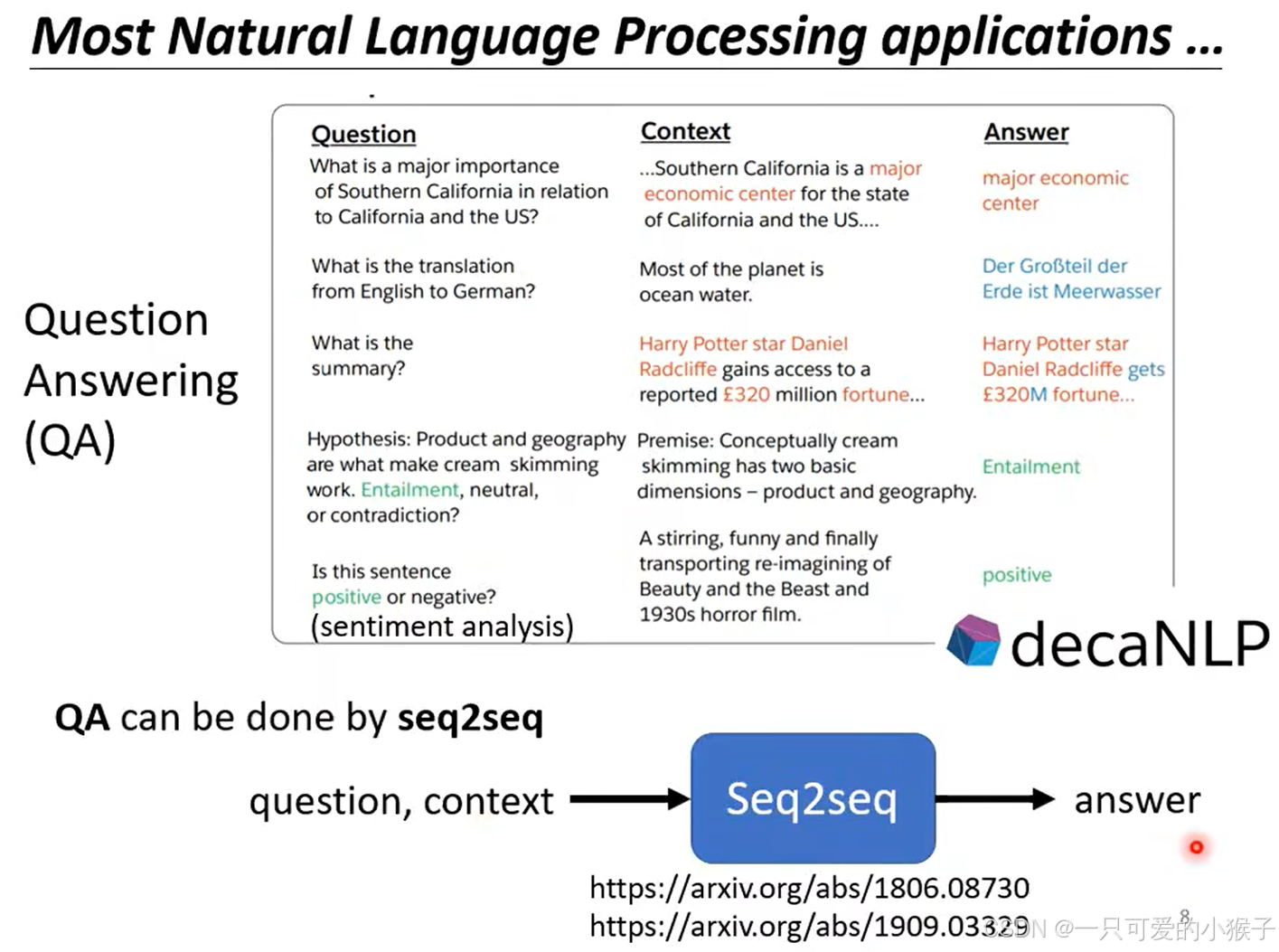
-
除了上面介绍的语音辨识或者翻译等任务可以使用seq2seq以外,例如还有多分类问题,我们也可以使用seq2seq模型直接输出类别,假设对一篇文章分类,我们并不能确定类别结果的个数,多以可以直接使用seq2seq模型得到结果。甚至对于目标检测的任务我们也可以使用seq2seq的模型硬解得到结果。
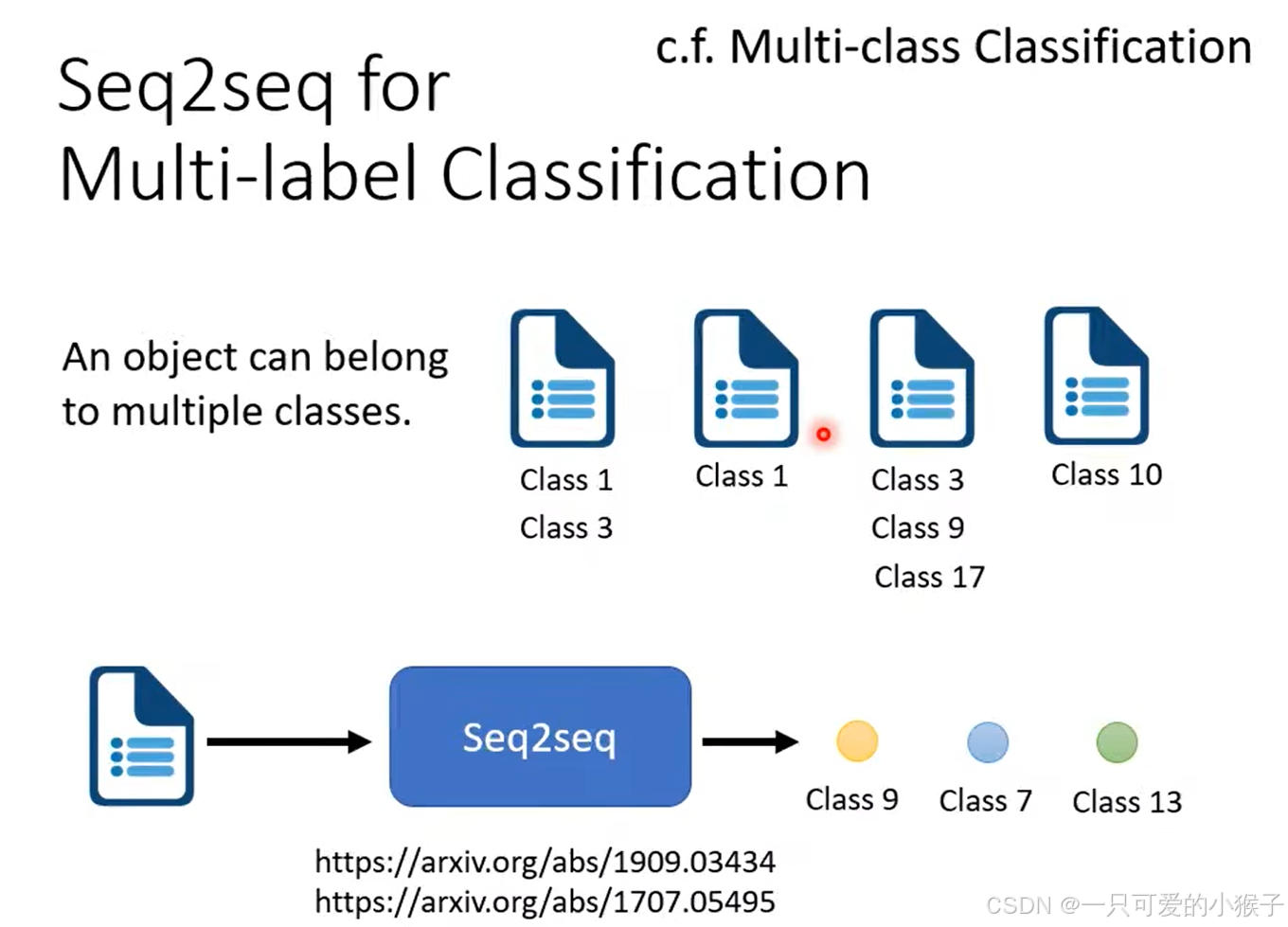
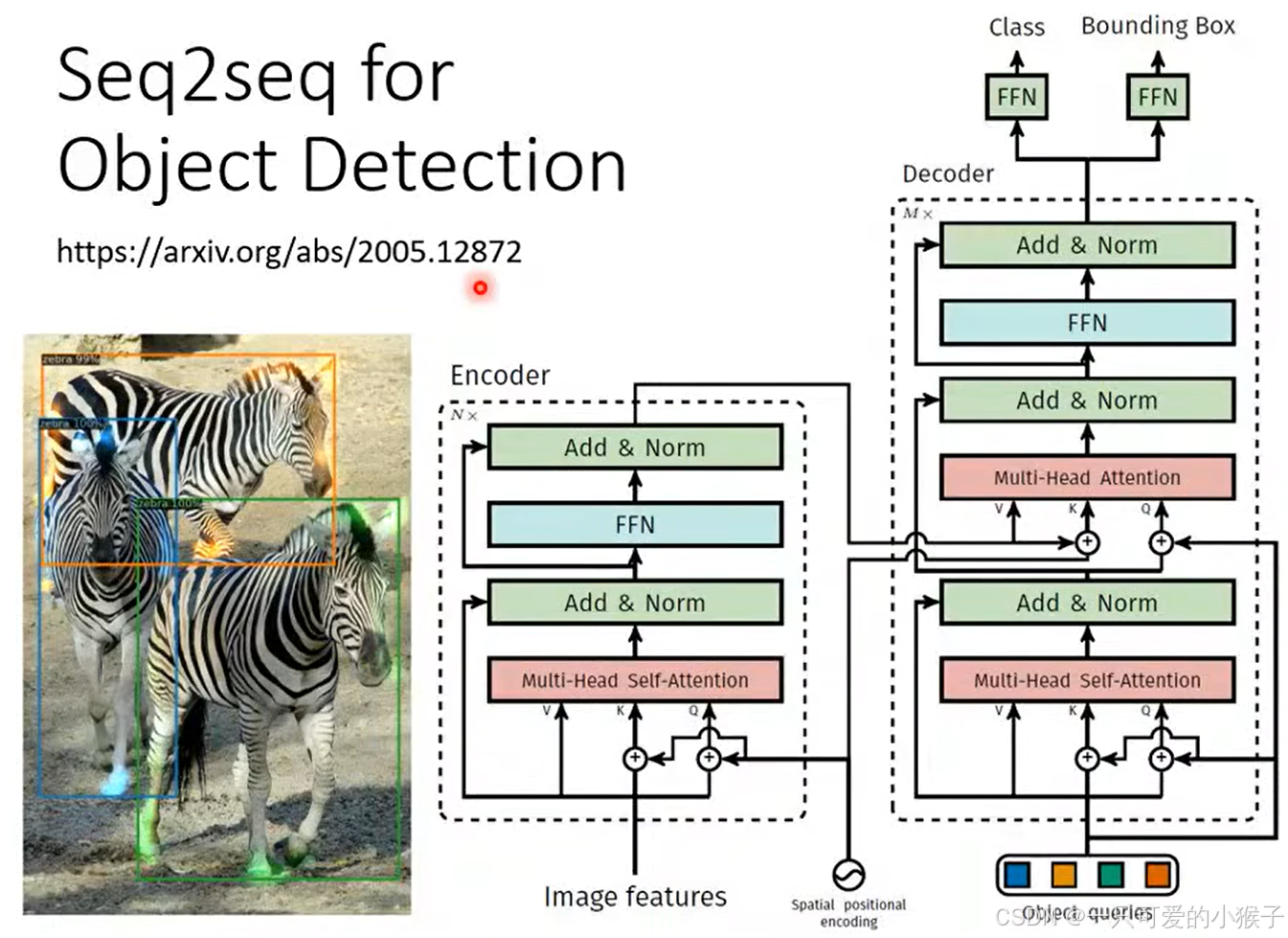
-
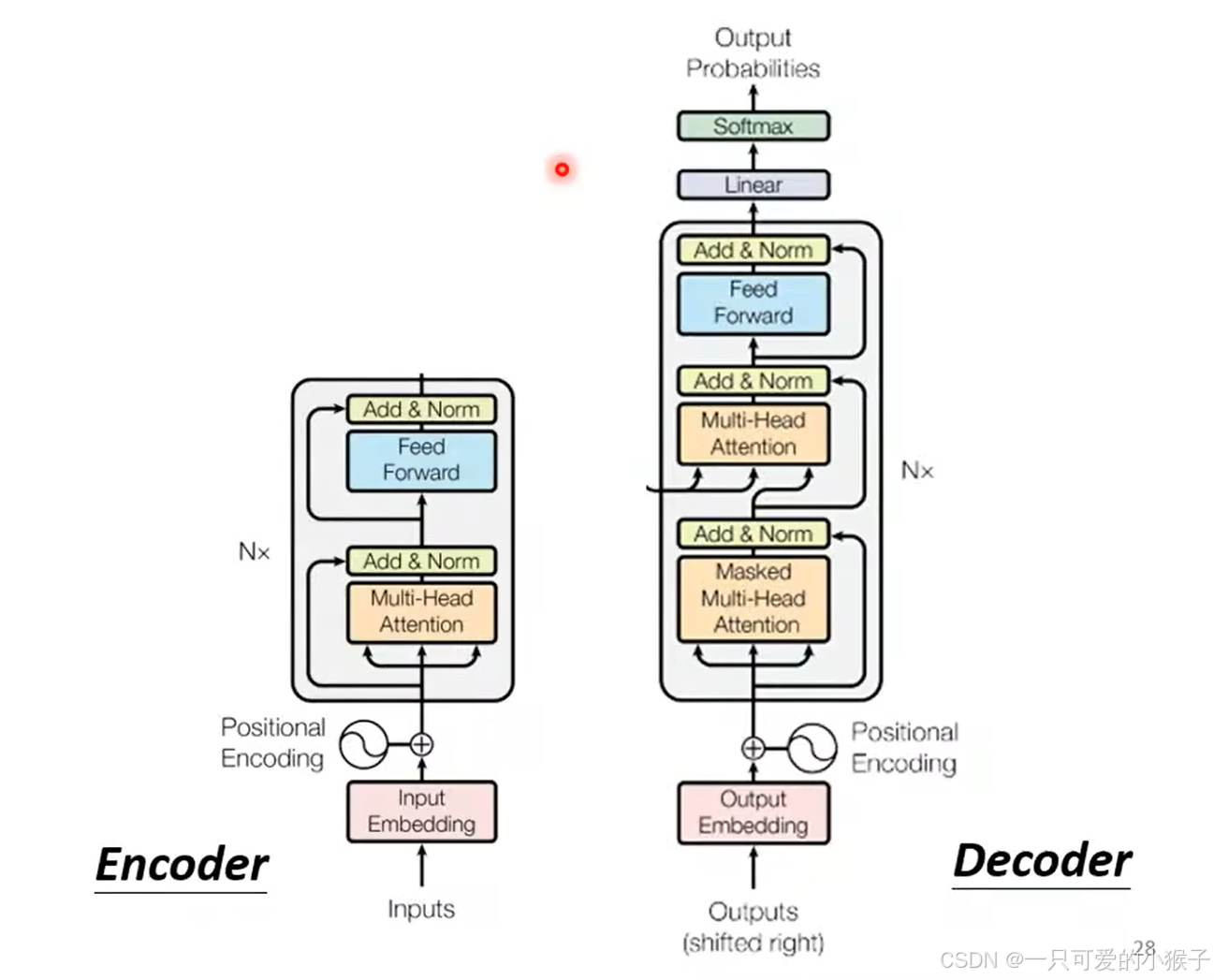
说到seq2seq的模型,最容易想到的就是现在流行的transformer模型,如下图所示
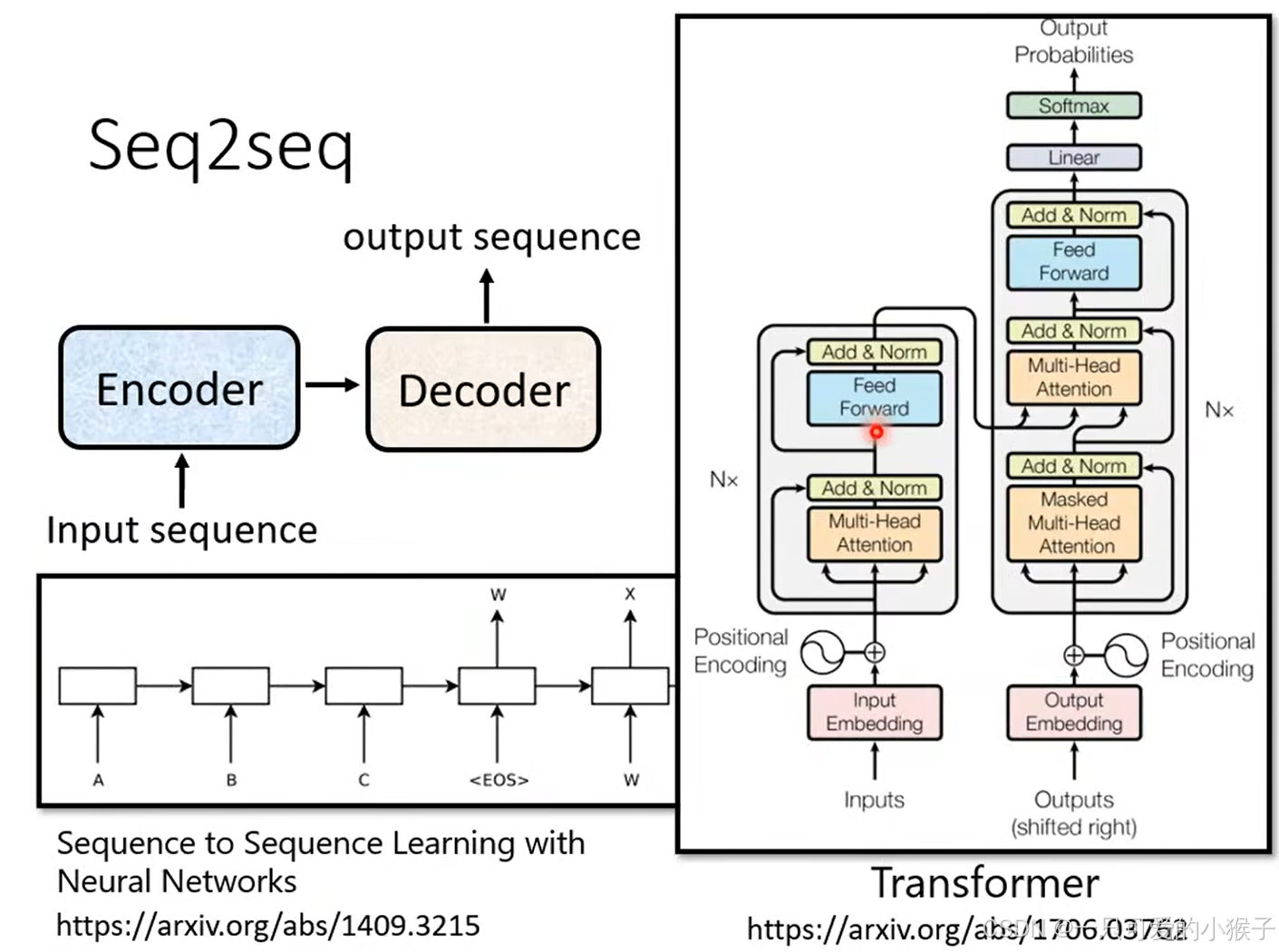
-
seq2seq模型的encoder部分需要做的事情就是对于输入的一排向量,输出也是一排向量,当然RNN和CNN等模型也可以做到输入一排向量,输出一排向量。
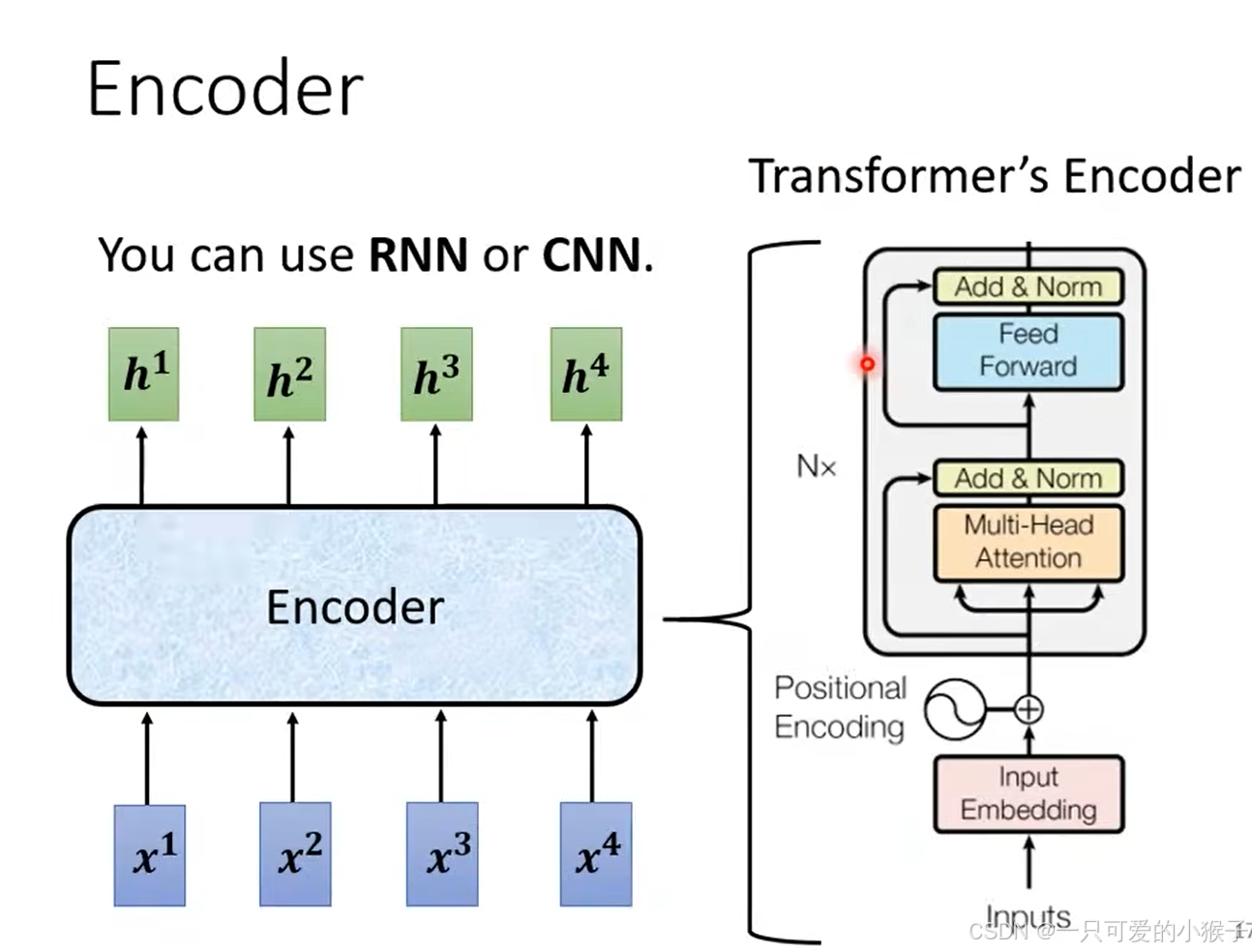
-
在encoder里面,输入的向量要经过好几个block的处理,才可以得到输出的向量,其中一个block又是有好几个层构成。
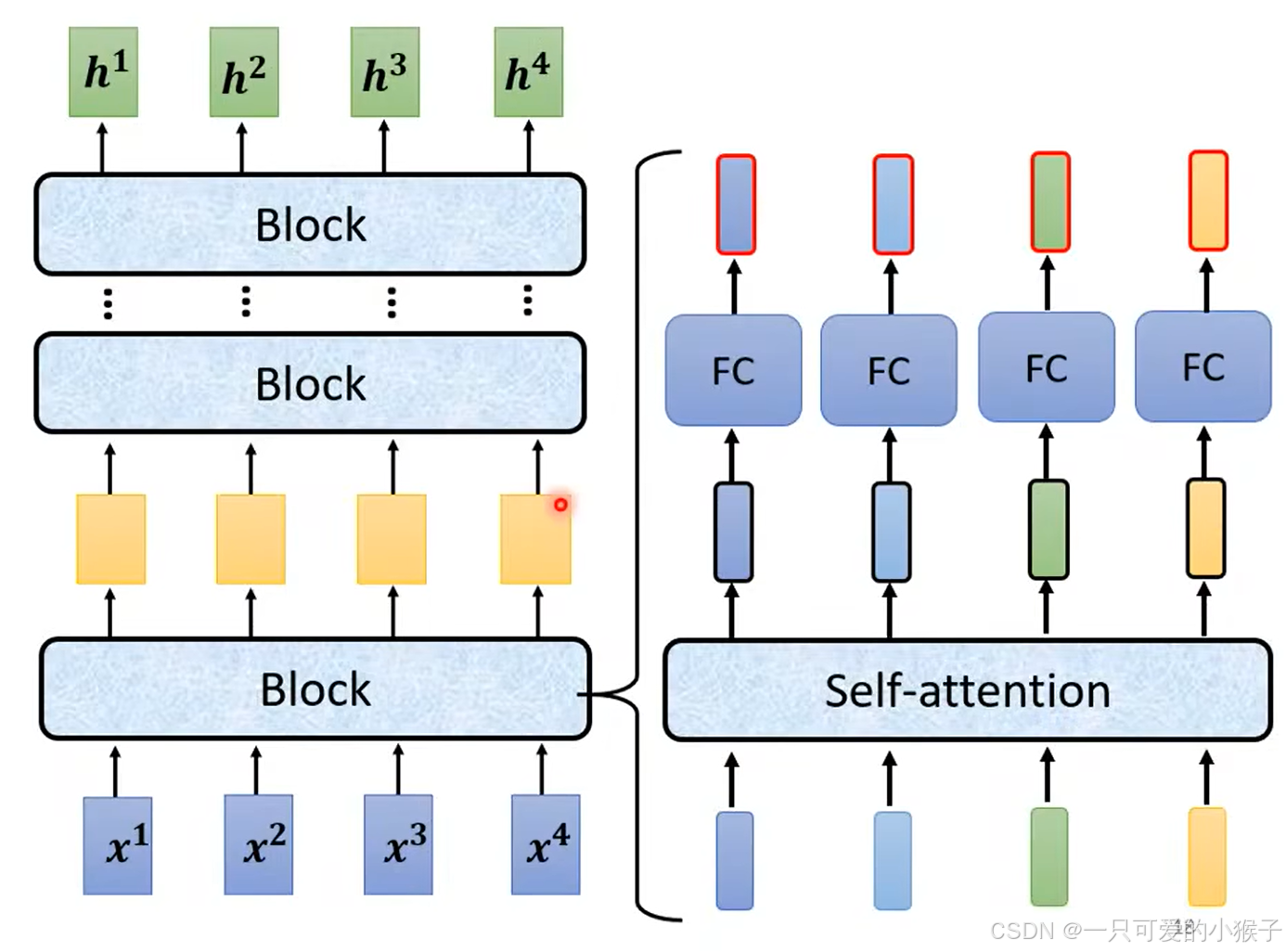
-
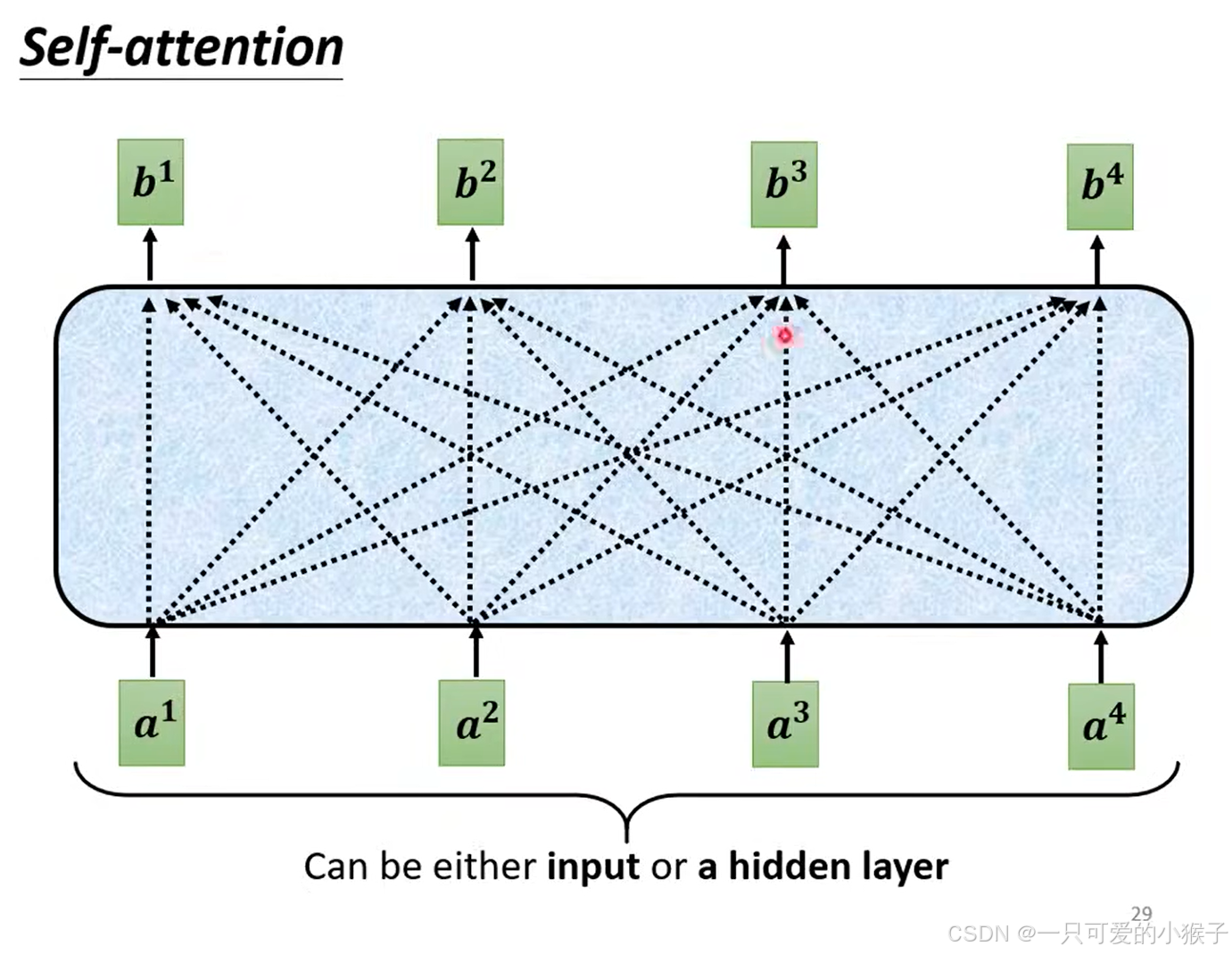
下面这张图就是上图的一个block中的细节,首先输入的向量先采用注意力机制,
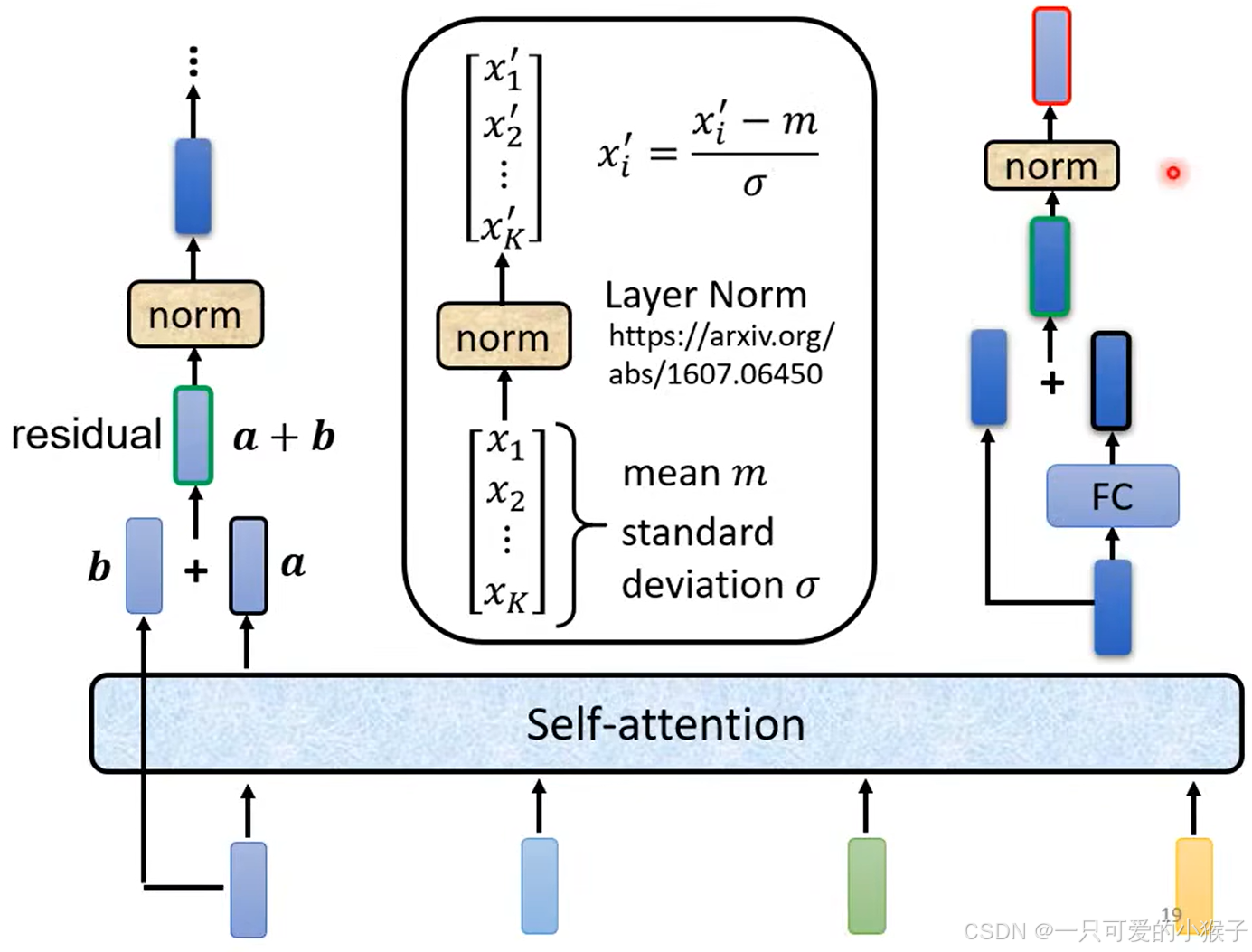
BERT确实是Transformer模型中Encoder部分的一个应用实例,主要利用了Transformer模型中的Encoder部分,来捕捉文本的上下文信息。结合特殊的预训练任务和输入表示方法,成为了一种非常有效的预训练语言表示模型。
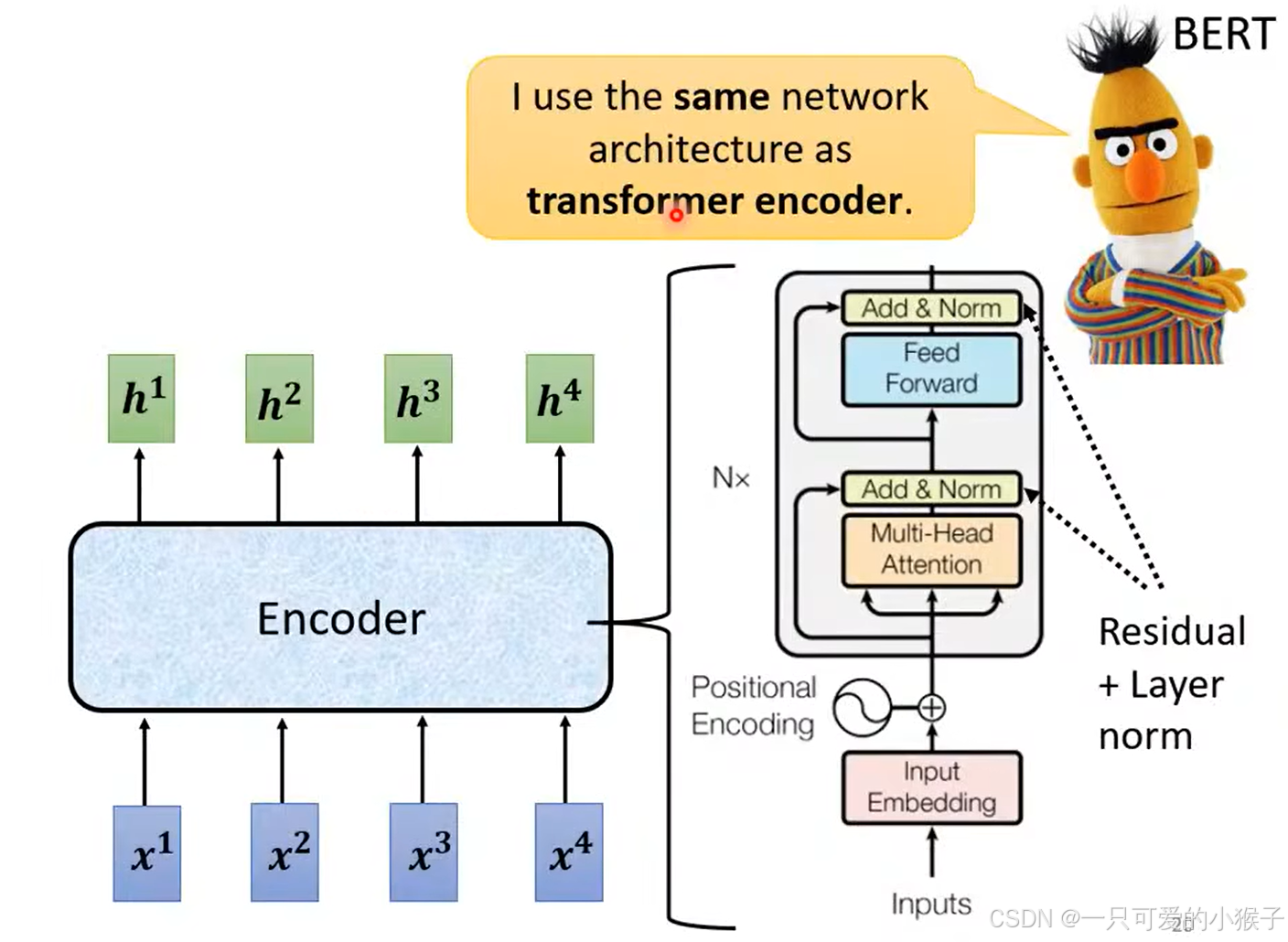
-
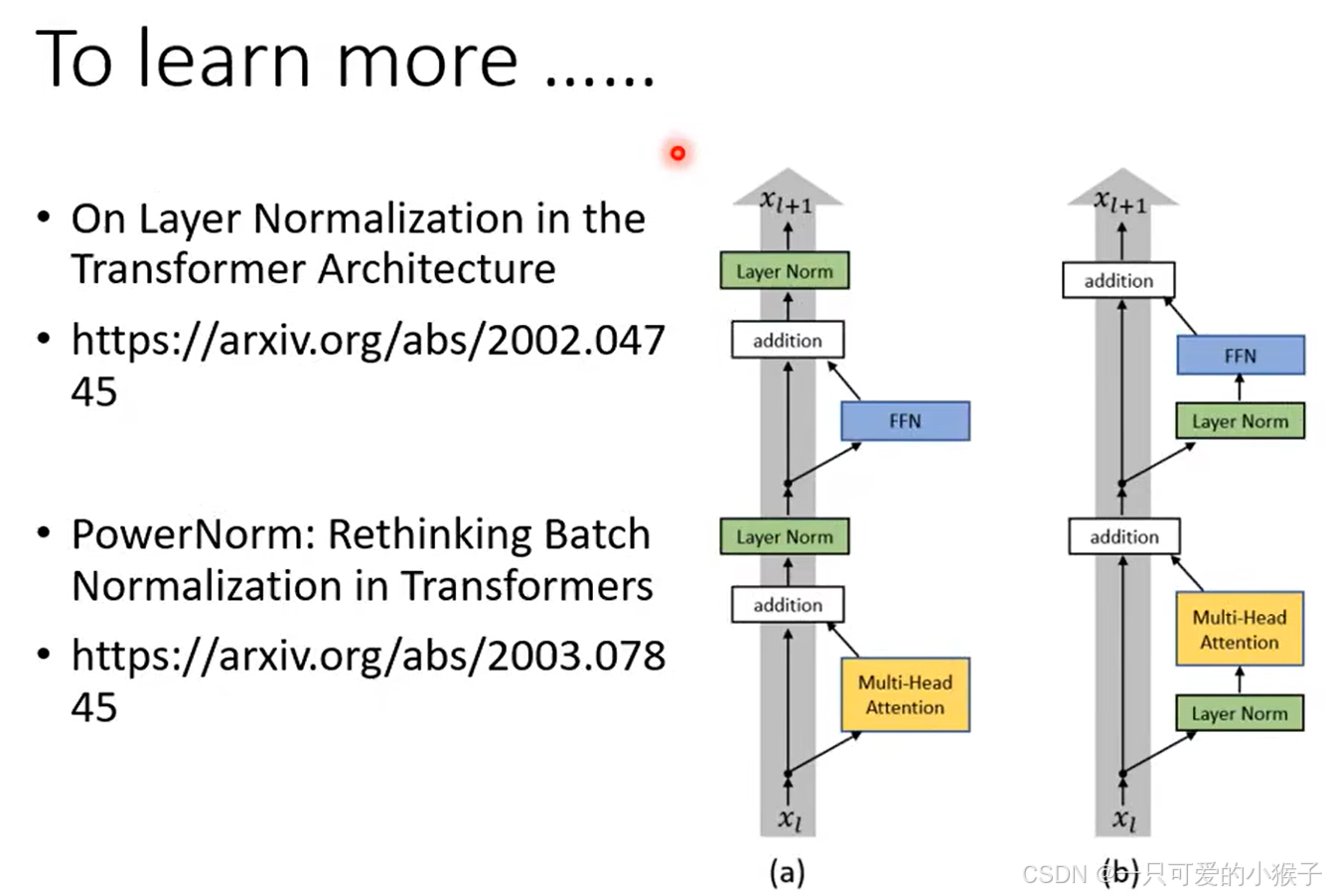
当然上面讲解的是transformer最原始的encoder架构,后人也对这个架构进行了一些升级改造取得了更好的结果,例如下图b改变了norm步骤的顺序也使模型更优了,此外 也可以考虑别的norm方法进行改进,可以自行深入了解
-
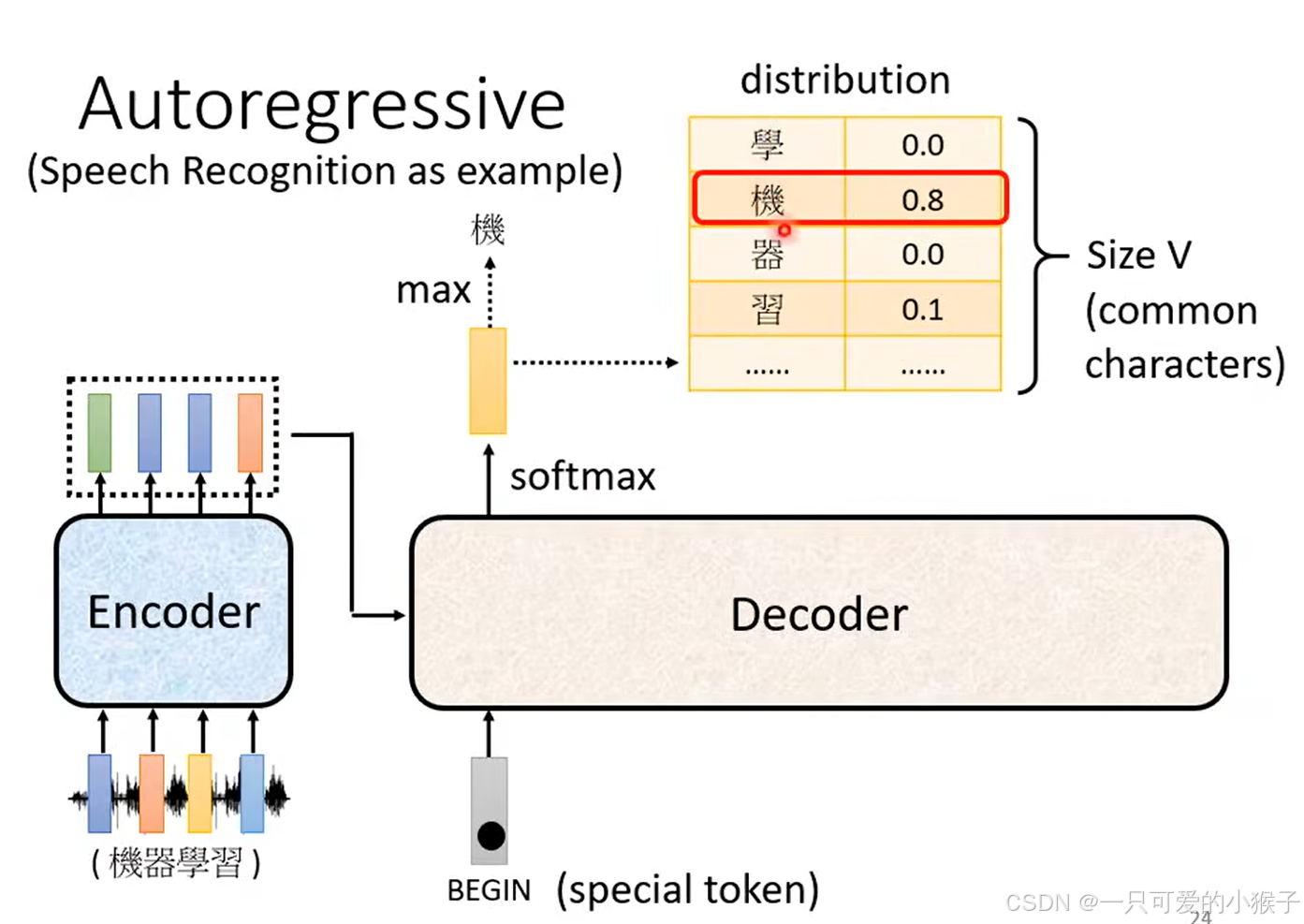
选取一个得分最高的作为下一轮的输入
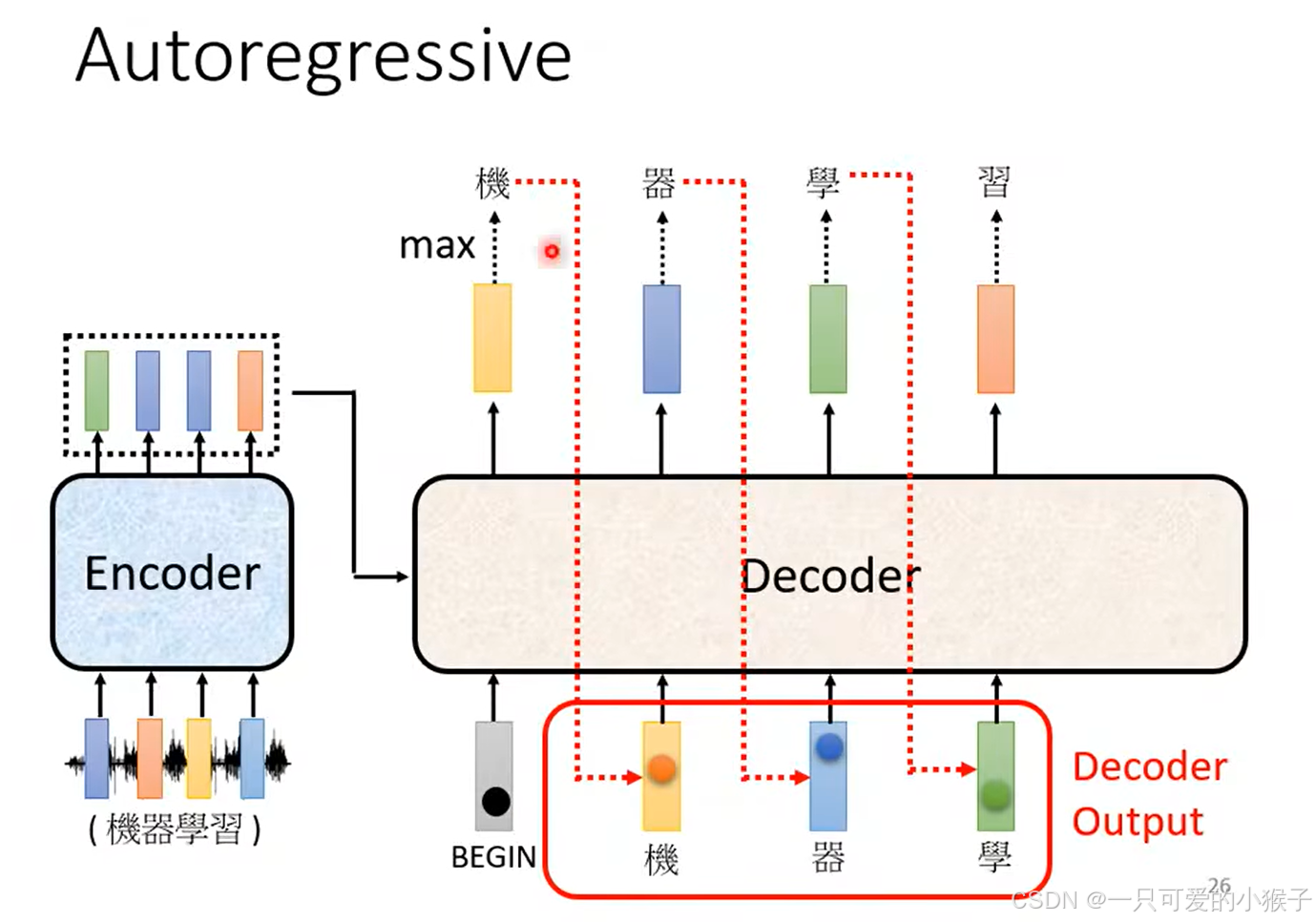
后面内容不打算更新啦,考试过了,哈哈哈
复习的时候发现b站上有一篇文字版的整理,特别详细
想看后面的可以去b站上搜索一下