Optimizer_switch变量是支持对优化器行为的控制。是一组值标志,每个标志都有一个on或off的值,以指示是否启用或禁用相应的行为。
MySQL8.0里除了熟悉的hash join重大变化之外,其他方面也有优化。
mysql> SHOW VARIABLES LIKE 'OPTIMIZER_SWITCH'\G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,
index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,
mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,
materialization=on,semijoin=on,loosescan=on,firstmatch=on,
duplicateweedout=on,subquery_materialization_cost_based=on,
use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,
##下面是目前5.7 Vs 8.0差异内容##
use_invisible_indexes=off,skip_scan=on,hash_join=on,
subquery_to_derived=off,prefer_ordering_index=on,
hypergraph_optimizer=off,derived_condition_pushdown=onuse_invisible_indexes
MySQL8.0 开始支持隐藏索引,有时往往因为索引不合理,执行计划太差,需要大动干戈,现在不需要进行破坏性的更改,优化器方面配合是否使用不可见索引来构建查询执行计划.默认是关闭。当然这里主键以外。
#索引age隐藏
mysql> ALTER TABLE members ALTER INDEX idx_age INVISIBLE;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
#执行计划全表扫描
mysql> EXPLAIN select *from members where age > 10;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | members | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
#优化器可用隐藏索引打开。
mysql> SET SESSION optimizer_switch='use_invisible_indexes=on';
Query OK, 0 rows affected (0.00 sec)
#执行计划使用age 隐藏索引
mysql> EXPLAIN select *from members where age > 10;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | members | NULL | range | idx_age | idx_age | 5 | NULL | 3 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)备注: 在一些业务无法及时改变SQL语句的时,可以通过更改索引隐藏属性,有效控制手段。
特别是生产不确定索引性能影响的时候,可以在线操作,算是应急对策。
prefer_ordering_index
MySQL里对任何有LIMIT子句的ORDER BY或GROUP BY查询使用有序索引,覆盖优化器所做的任何其他选择,只要它确定这会导致更快的执行。因此做出这种判断的算法对数据分布和其他条件做出了某些假设,所以它可能并不总是完全正确,而且在某些情况下,此类查询选择不同的优化可能会提供更好的性能。
8.0.21版本中optimizer_switch变量的prefer_ordering_index设置来禁用这种优化算法。
optimizer_switch参数中的prefer_ordering_index进行控制对于order by limit的优化。prefer_ordering_index默认打开,表示MySQL会优先考虑通过order by列索引进行排序优化。
目前验证发现只在范围查询中,有算法干扰。所以使用范围查询,可要小心了。
#模拟表结构和数据
mysql>CREATE table `members`
(
id int unsigned NOT NULL AUTO_INCREMENT ,
first_name varchar(100) DEFAULT NULL ,
last_name varchar(100) DEFAULT NULL ,
age INT DEFAULT '0' ,
create_time timestamp DEFAULT CURRENT_TIMESTAMP,
update_time timestamp DEFAULT current_timestamp() ON UPDATE current_timestamp(),
primary KEY (id) ,
KEY idx_first_last(first_name(3),last_name(3)),
KEY idx_age(age)
);
mysql>INSERT INTO `members`(id,first_name,last_name,age)
VALUES(1,'AAAAA','BBBBB',12),(2,'AAAAA','CCCCC',20),(3,'DDDDD','EEEEE',30);
#排序优先开启
mysql>SET optimizer_switch = "prefer_ordering_index=on";
#优先ORDER BY 和 LIMIT 选择主键
mysql> EXPLAIN SELECT * FROM members WHERE age> 15 order by `id` DESC LIMIT 1;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | members | NULL | index | idx_age | PRIMARY | 4 | NULL | 1 | 66.67 | Using where; Backward index scan |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
#排序优先关闭
mysql> SET optimizer_switch = "prefer_ordering_index=off";
Query OK, 0 rows affected (0.00 sec)
#选择合理执行计划
mysql> EXPLAIN SELECT * FROM members WHERE age> 15 order by `id` DESC LIMIT 1;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | members | NULL | range | idx_age | idx_age | 5 | NULL | 2 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
subquery_to_derived
MySQL 8.0.21开始,优化器增加了subquery_to_derived(默认关闭)选项。优化器在许多情况下能够将SELECT、WHERE、JOIN或HAVING子句中的标量子查询转换为派生表上的左&外部连接(在某些情况下是内连接)。
所为的:
- subquery: 包含在 SELECT 中的子查询(不在 FROM子句中)。
- derived : 包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,
也称为派生表(derived).
在大多数情况下,启用此优化不会产生任何明显的性能改进(在许多情况下甚至会使查询运行得更慢),视情况而定,所以选择默认值即可。
SHOW WARNINGS信息下,可以看到语句改写情况:
mysql> SET SESSION optimizer_switch='subquery_to_derived=OFF';
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN SELECT * FROM t1 WHERE t1.a > (SELECT COUNT(a) FROM t2);
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | PRIMARY | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where |
| 2 | SUBQUERY | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS;
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `test`.`t1`.`a` AS `a`
from `test`.`t1`
where (`test`.`t1`.`a` > (/* select#2 */ select count(`test`.`t2`.`a`) from `test`.`t2`)) |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SET SESSION optimizer_switch='subquery_to_derived=ON';
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN SELECT * FROM t1 WHERE t1.a > (SELECT COUNT(a) FROM t2);
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | PRIMARY | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where; Using join buffer (hash join) |
| 2 | DERIVED | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
3 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS;;
+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `test`.`t1`.`a` AS `a`
from `test`.`t1` join (
/* select#2 */ select count(`test`.`t2`.`a`) AS `COUNT(a)`
from `test`.`t2`) `derived_1_2`
where (`test`.`t1`.`a` > `derived_1_2`.`COUNT(a)`) |
+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)derived_condition_pushdown
Mysql 8.0.22之后的版本支持派生条件回移(Derived Condition Pushdown)优化。该优化可以减少derived派生表处理的行数从而提高查询执行的效率。
比方如下查询:
SELECT * FROM
(SELECT i, j FROM t1) AS dt
WHERE i > constant
# ↓ ↓ ↓ 通过派生条件回移优化后类似如下形式(WHERE条件拿到派生表的里面)
SELECT * FROM (SELECT i, j FROM t1 WHERE i > constant)就是说 将外部WHERE条件下推到派生表中应该会减少需要处理的行数,从而加快查询的执行速度。
MySQL 8.0.29及以后版本中,派生表条件下推优化可以用于UNION查询。
不能下推情况:内部表,包含子查询的条件,公共表表达式,LIMIT子句,变量的赋值 等场景。
skip_scan
MySQL从8.0.13版本开始支持一种新的range scan方式。就是说 组合索引(f1,f2)的时候,查询条件里 只有f2的时候 也可以实现索引扫描的功能.范围扫描比全索引扫描更有效,优化器可以执行多个范围扫描,每个值对应一个f1,使用一种称为Skip Scan的方法,类似于松散索引扫描。
从上述描述可以看到使用skip-scan的方式避免了全索引扫描,从而提升了性能,尤其是在索引前缀列区分度比较低的时候。可以说 避开了索引前缀原则。
mysql> ALTER TABLE t1 ADD PRIMARY KEY(f1, f2);
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40;;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------+
| 1 | SIMPLE | t1 | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 53 | 100.00
| Using where; Using index for skip scan |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------+
1 row in set, 1 warning (0.00 sec)hypergraph_optimizer
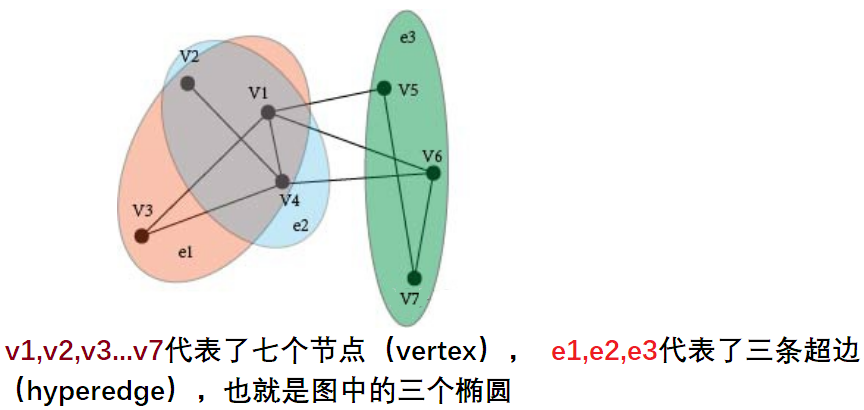
MySQL 8.0.23提供了优化器支持hypergraph(超图)的模型。目前实际还不支持,需要在debug下进行验证测试,是不成熟的优化方案。
hypergraph是数学中用的概念。在数据算法中,描述对象之间建立联系而用的。个人理解,就是通过边界算法,把对应的数据关联点,范围等圈出来。
由此多表关联下,从5.7的nest loop 进化到8.0的hash join,在hash join进一步提升效率的的算法。这个算法非常切合B+Tree配合使用。
mysql> SET SESSION optimizer_switch='hypergraph_optimizer=ON';
ERROR 3999 (42000): The hypergraph optimizer does not yet support 'use in non-debug builds'总结
优化器行为变更,可能会导致不同版本SQL语句性能体现不一样。当然变化是往好的方面延伸的,但对于复杂的情况,可能也会出现退化效果。所以版本升级的时候,需要特别关注下。
在这里特别感兴趣hypergraph(超图)优化方案。因为MySQL对于多表关联是一个致命的问题,关联表数量越多性能越差。对于hypergraph的算法本质上的理解,可以说结合B+Tree性能提升空间很大。