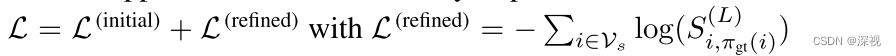Datawhale干货
作者:陈敬,中国移动云能力中心
前言
本文对多任务学习(multi-task learning, MTL)领域近期的综述文章进行整理,从模型结构和训练过程两个层面回顾了其发展变化,旨在提供一份 MTL 入门指南,帮助大家快速了解多任务学习的进化史。
1. 什么是多任务学习?
多任务学习:给定 m 个学习任务,这m个任务或它们的一个子集彼此相关但不完全相同。通过使用所有m个任务中包含的知识,有助于改善特定模型的学习。
多任务学习的特点:
具有相关联任务效果相互提升作用,即同时学习多个任务,若某个任务中包含对另一个任务有用的信息,则能够提高在后者上的表现;
具有正则化的效果,即模型不仅需要在一个任务上表现较好,还需要再别的任务上表现好,倾向于学习到在多个任务上表现都比较好的特征;
多任务模型可以共享部分结构,降低内存占用,在推理时减少重复计算,提高推理速度。
MTL 处理的任务应具有一定的关联性,若同时学习两个不相关甚至冲突的任务,模型表现可能会受到损害出现经常所说的跷跷板现象,即两个任务联合学习的时候,可能一个任务效果变好,另一个任务效果变差,这个现象称为负迁移。究其本质主要是训练过程中可能出现以下 3 个问题导致的:
多任务梯度方向不一致:同一组参数,不同的任务更新方向不同,导致模型参数出现震荡,任务之间出现负迁移的现象,一般出现在多个任务之间差异较大的场景。
多任务收敛速度不一致:不同的任务收敛速度不一样,有的任务简单收敛速度快,有的任务困难收敛速度慢,导致模型训练一定轮数后,有的任务已经过拟合,有的任务还是欠拟合的状态;
多任务 loss 取值量级差异大:不同的任务 loss 取值范围差异大,模型被 loss 比较大的任务主导,这种情况在两个任务使用不同损失函数,或者拟合值的取值差异大等情况下最为常见。
与标准的单任务学习相比,多任务学习的方法设计可以分别从网络结构与损失函数两个角度出发。模型网络结构的不断创新,解决的是多个任务之间如何最高效的实现参数的共享与分离,让模型既能融合不同任务之间的共性,又能给每个任务提供独立的空间防止干扰。另一个角度是如何优化多任务学习的训练过程,如损失函数的优化等,下面我们分别从这两个方面进行介绍。
2. 多任务学习的网络结构
一个高效的多任务网络,应同时兼顾特征共享部分和任务特定部分,既需要学习任务之间的泛化表示 以避免过拟合,又需要学习每个任务独有的特征以避免欠拟合。根据模型在处理不同任务时网络参数的共享程度,MTL 方法的网络结构可分为:
硬参数共享 (Hard Parameter Sharing):模型的主体部分共享参数,输出结构任务独立。
软参数共享 (Soft Parameter Sharing) :不同任务采用独立模型,模型参数彼此约束。
具体区别如下图所示:
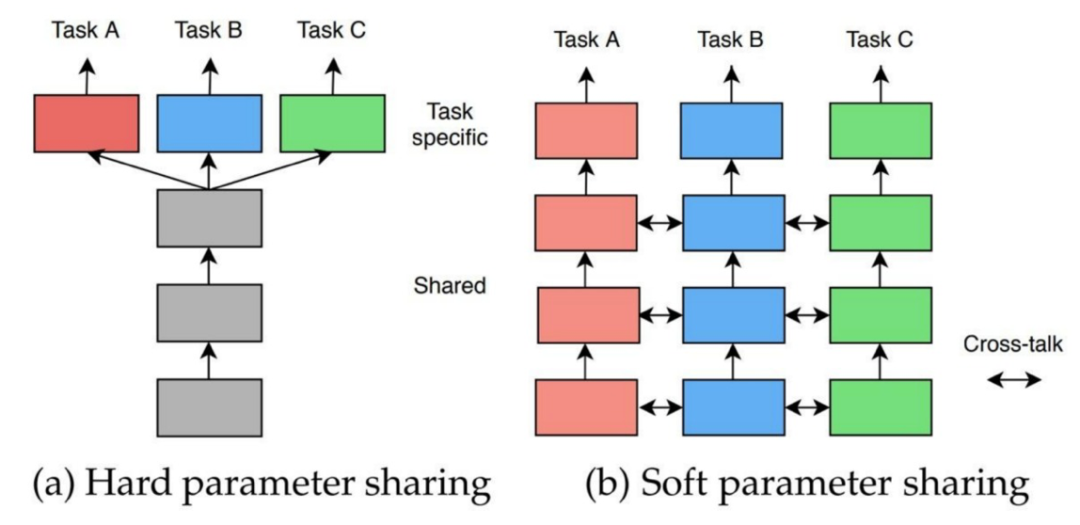
图 1:硬参数和软参数共享示例图
下面我们会分别针对硬参数共享和软参数共享分别进行 MTL 网络结构的进展介绍。
2.1 硬参数共享
硬参数共享是指模型在处理不同任务时,其主体部分共享参数,针对不同任务使用不同的输出结构。这类方法通过在不同任务上学习共享的特征,降低模型在单个任务上过拟合的风险。
MT-DNN框架
MT-DNN[1] 是微软开源的框架,主要是利用学习文本的自然语言理解任务通常可以利用多任务学习和预训练两种途径解决的思想,因此二者的结合可以增强文本理解能力,基于以上提出 MT-DNN 框架,集成了 MTL 和 BERT 语言模型预训练二者的优势,在 10 项 NLU 任务上的表现都超过了 BERT,并在通用语言理解评估(GLUE)、斯坦福自然语言推理(SNLI)以及 SciTail 等多个常用 NLU 基准测试中取得了当前最佳成绩。
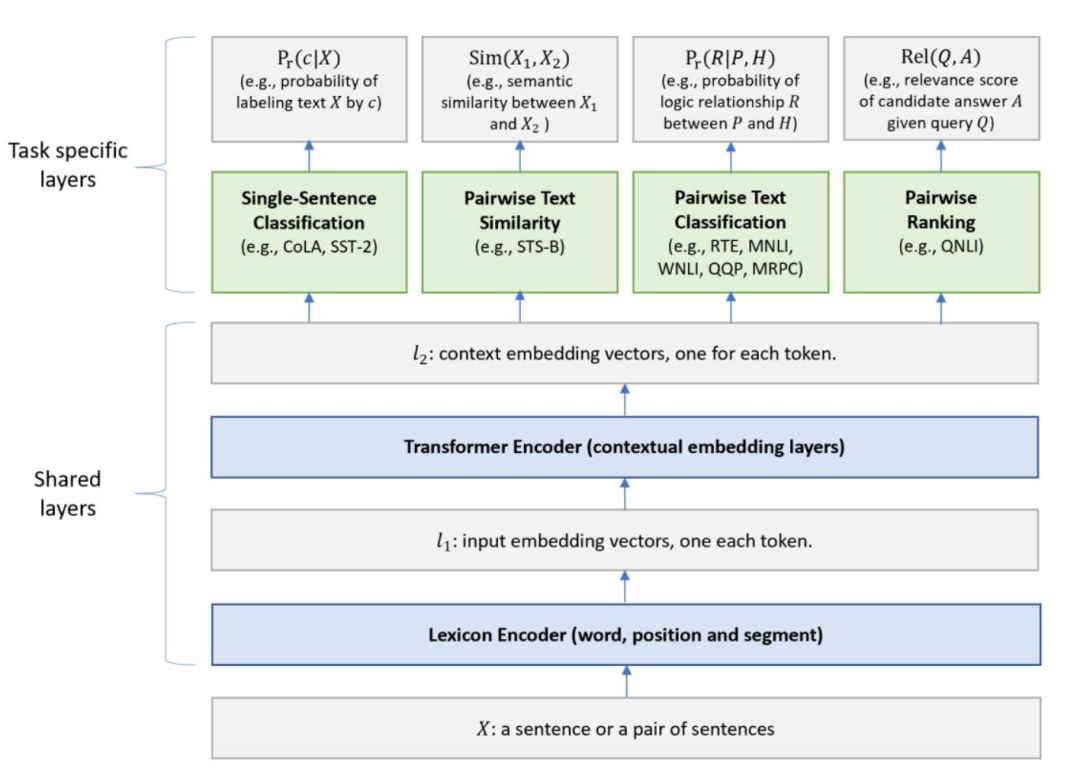
图 2:MT-DNN框架图
共享部分
Lexicon Encoder:输入一个句子(一个句子对),遵循 BERT 的输入,添加 [CLS]、[SEP] 等标签,并加入word、segment 和 position representation;
Transformer Encoder:与 BERT 一样使用多层 Transformer 模型;特定任务部分;
特定任务部分
Single-Sentence Classification:对单一的文本进行分类。[CLS] 的 embedding 喂入线性层 + softmax 进行分类;
Text Similarity:对两个输入文本计算回归值。[CLS] 的 embedding 喂入线性层计算未归一化的相似度;
Pairwise Text Classification:对输入的两个文本进行分类匹配。完全使用 stochastic answer network (SAN) 模型解决文本匹配问题(例如NLI);
Relevance Ranking:输入一个文本 Q ,以及若干候选文本 A ,Q 与每个 A 进行拼接后并计算得分:最后根据所有得分取最大对应的 A 作为预测结果;
在训练过程中,将所有任务的 batch 训练数据混合成数据集 D ,每次从 D 中拿出一个任务的 batch 进行训练。相比于交替训练(先训练任务 A 再训练任务 B ),这样做的好处是避免偏向某个任务。
multi-task-NLP
multi_task_NLP[2] 是一个实用工具箱,使 NLP 开发人员能够轻松地训练和推断出多个任务的单一模型。支持大多数 NLU 任务的各种数据格式和多种基于变压器的编码器(如 BERT、Distil-BERT、ALBERT、RoBERTa、XLNET等),整体框架如下图所示。
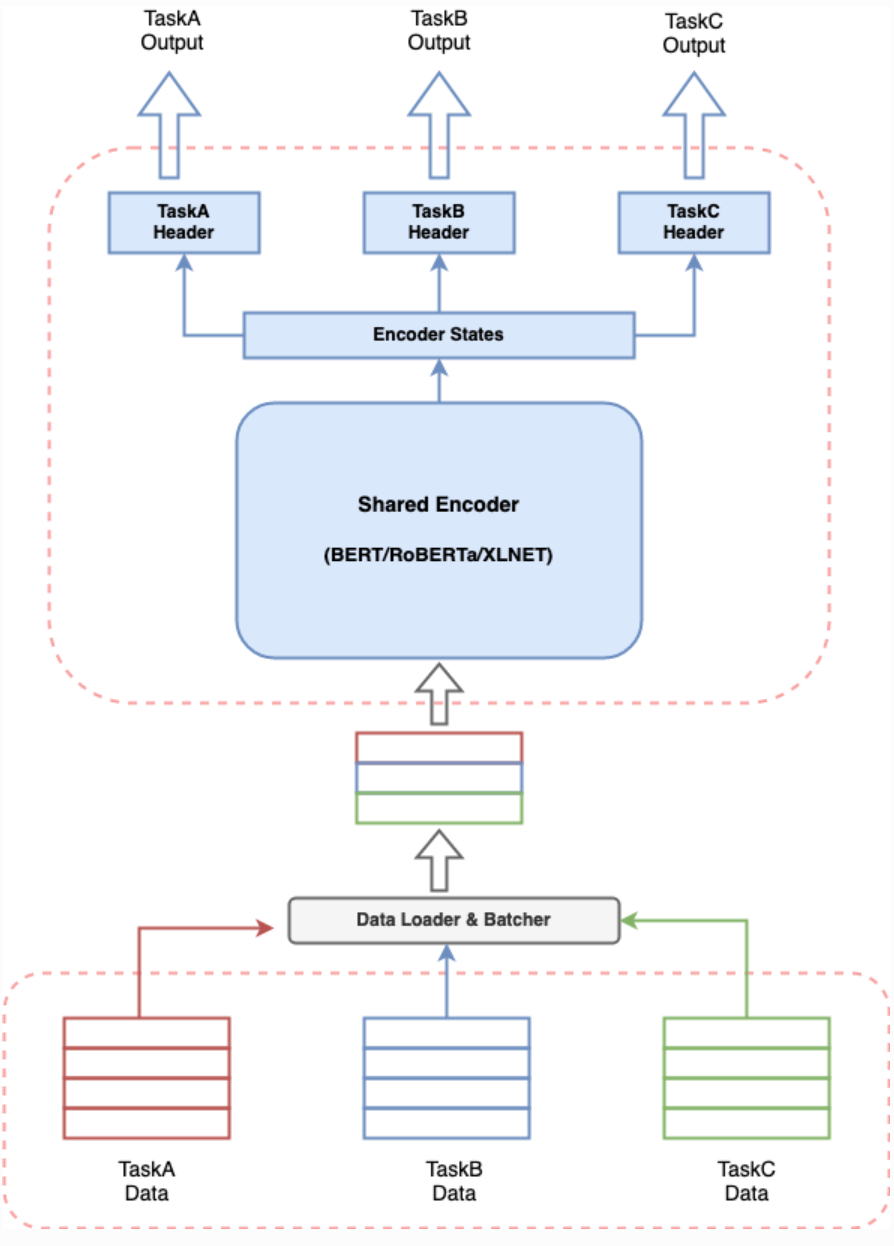
图 3:multi-task-NLP框架图
multi_task_NLP 整体框架与 MT-DNN 相似,共享了 Encoder 部分的向量信息,在输出部分,通过不同的 Header 区分不同任务,使您能够一起定义多个任务,并训练一个同时学习所有已定义任务的模型。这意味着可以执行多个任务,其延迟和资源消耗相当于单个任务。
2.2 软参数共享
软参数共享即底层共享一部分参数,自己还有独特的一部分参数不共享;顶层有自己的参数。底层共享的、不共享的参数如何融合到一起送到顶层,是研究人员们关注的重点。
MMOE结构
MMOE[3] 模型结构(下图 b 和 c)和最左边(a)的硬参数共享相比,(b)和(c)都是先对Expert 0 - 2(每个 expert 理解为一个隐层神经网络就可以了)进行加权求和之后再送入 Tower A 和 B(还是一个隐层神经网络),通过 Gate(还是一个隐藏层)来决定到底加权是多少。另外 MMOE 在 MOE 的基础上,多了一个 GATE,意味着:多个任务既有共性,也必须有自己的独特性。
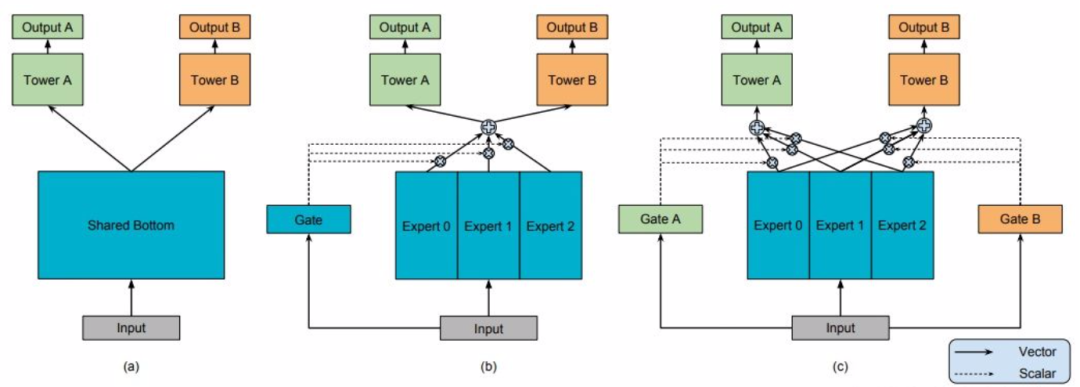
图 4:MMOE进化图
MMOE 共性和独特性权衡的方式就是针对每个任务搞一个专门的权重学习网络(GATE),让模型自己去学,学好了之后对 expert 进行融合送给各自任务的 tower,最后给到输出。其实 MMOE 框架本质上就是一种集成学习方法,在实践中最简单的实现方法,可以将 gating network 分配的权重全为 1,也就是在实现的时候直接将 Expert 0 ~ Expert 2 结果进行相加。
腾讯PLE模型
前面的 MMOE 模型存在以下两方面的缺点,第一个是 MMOE 中所有的 Expert 是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声;第二个是不同的 Expert 之间没有交互,联合优化的效果有所折扣。Progressive Layered Extraction(PLE)[4] 针对上面第一个问题,每个任务有独立的Expert,同时保留了共享的 Expert,模型结构如下图所示:
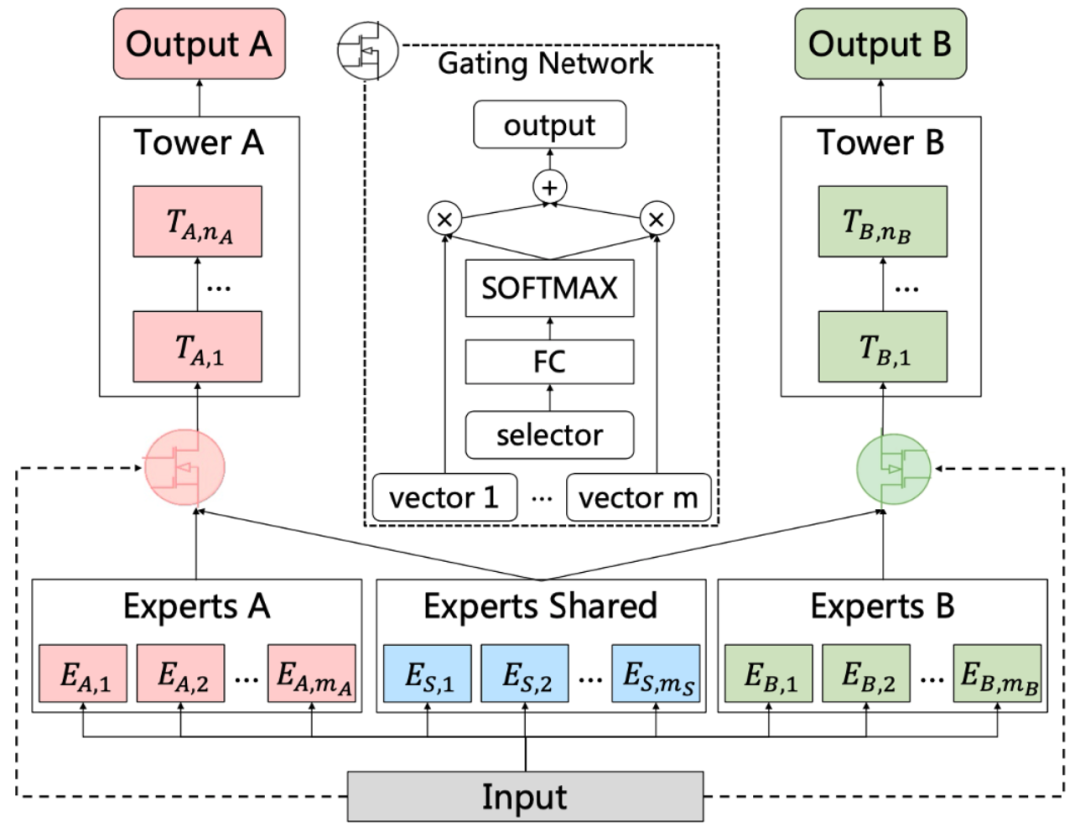
图 5:CGC模型框架图
如上图所示。CGC 可以看作是 PLE 的简单版本,所以先对其进行介绍。CGC 可以看作是Customized Sharing 和MMOE 的结合版本。对任务A来说,将 Experts A 里面的多个 Expert 的输出以及 Experts Shared 里面的多个 Expert 的输出,通过类似于 MMOE 的门控机制之后输入到任务A的上层网络中。
PLE 针对前面的第二个问题,在 CGC 的基础上,PLE 考虑了不同的 Expert 之间的交互,可以看作是 Customized Sharing 和 ML-MMOE 的结合版本,模型结构如下图所示:
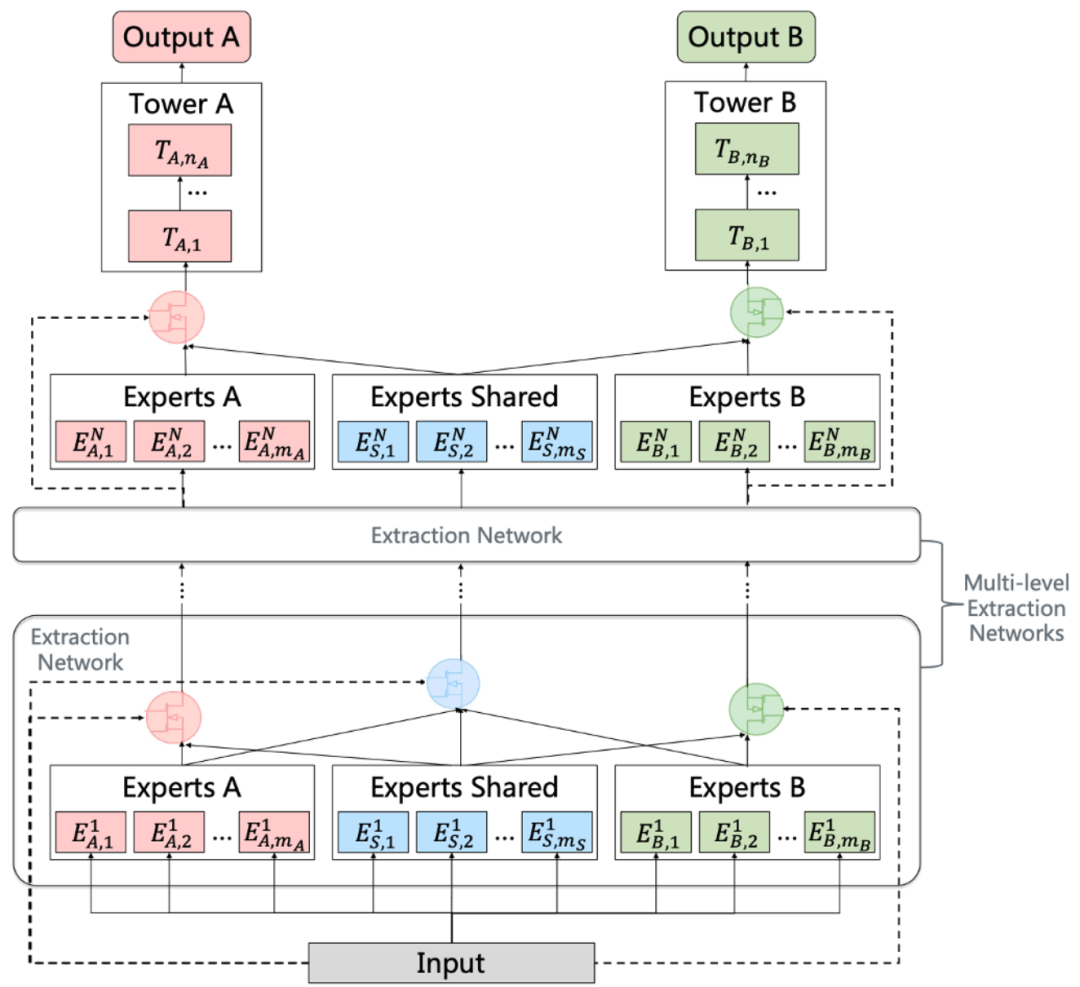
图 6:PLE框架图
对于 PLE 来说,不同任务在共享 Expert 上的权重是有较大差异的,其针对不同的任务,能够有效利用共享 Expert 和独有 Expert 的信息,这也解释了为什么其效果比 MMOE 更好。
百度UFO大模型
针对预训练大模型落地所面临的问题,百度提出统一特征表示优化技术(UFO:Unified Feature Optimization)[5],在充分利用大数据和大模型的同时,兼顾落地成本及部署效率。
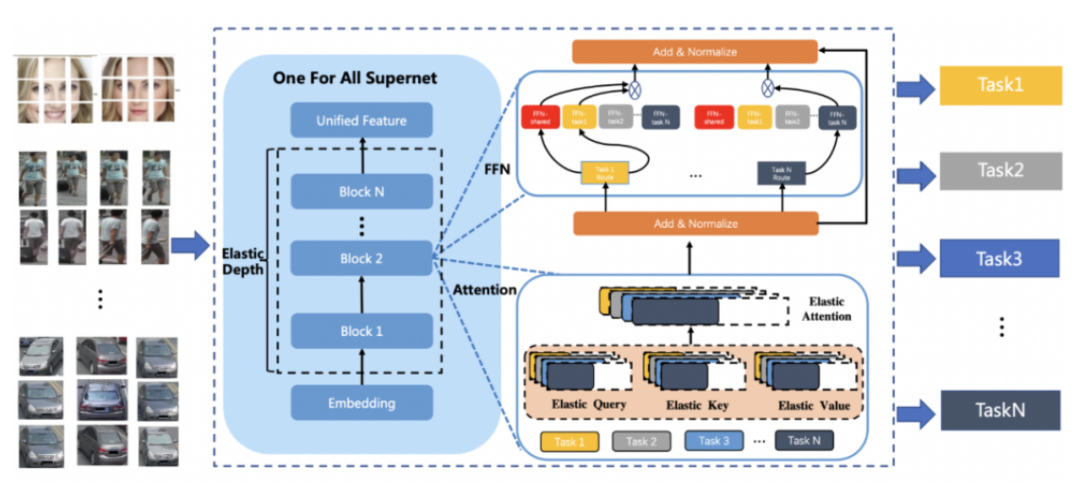
图 7:UFO超网模型结构图
UFO 综合了硬参数共享和软参数共享的方式,基于 Vision Transformer 结构设计了多任务多路径超网络。与谷歌 Switch Transformer 以图片为粒度选择路径不同,UFO 以任务为粒度进行路径选择,这样当超网络训练好以后,可以根据不同任务独立抽取对应的子网络进行部署,而不用部署整个大模型。UFO 超网中不同的路径可以选择不同 FFN 单元,多路径 FFN 超网模块,每个任务都有两种不同的路径选择,即选择共享 FFN(FFN-shared)或者专属 FFN(FFN-task)。
3. 多任务学习中的损失函数
多任务学习将多个相关的任务共同训练,其总损失函数是每个任务的损失函数的加权求和式:
权重的选择应能够平衡每个任务的训练,使得各任务都获得有益的提升。多任务学习的目的是寻找模型的最优参数,若该参数任意变化都会导致某个任务的损失函数增大,则称该参数为帕累托最优解。帕累托最优意味着每个任务的损失都比较小,不能通过牺牲某个任务来换取另一个任务的性能提升。关于损失函数权重的设置方法主要分类两种:手动设置和自动设置,下面我们针对这两种设置方法做一下简要介绍。
3.1 手动设置方法
根据初始状态设置权重
在没有任何任务先验的情况下,总损失可以设置为所有任务损失的算术平均值,即。然而每个任务的损失函数的数量级和物理量纲都不同,因此可以使用损失函数初始值的倒数进行无量纲化:
该权重具有缩放不变性,即任务 k 的损失大小进行缩放后结果不会变化。
根据先验状态设置权重
若能够预先获取数据集的标签信息,则可以根据其统计值构造损失函数的先验状态,并用作权重:
先验状态可以代表当前任务的初始难度,比如某分类任务中统计每个类别的出现频率为,则先验状态为。
根据实时状态设置权重
根据初始状态和先验状态设定的权重都是固定值,更合理的方案是根据训练过程中的实时状态动态的调整权重:
其中 sg(.) 表示 stop gradient,即在反向传播时不计算其梯度,在 pytorch 中可以通过 .detach() 方法实现。在该权重设置下,虽然每个任务的损失函数恒为 1 ,但是梯度不为 0 。
根据梯度状态设置权重
以上几种权重设置都具有缩放不变性;却不具有平移不变性,即任务k的损失加上一个常数后结果会发生变化。因此考虑采用损失函数梯度的模长来代替损失本身,以构造权重:
该权重同时具备缩放和平移不变性。
3.2 自动设置方法
根据同方差不确定度设置权重
论文[6]提出一种根据任务 loss 的不确定性设定各个任务 loss 权重的方法。本文提出的 loss 采用了如下形式:
其中,其中每个 loss 前面权重的分母,代表任务的不确定性。不确定性大的任务,loss 的权重就会对应缩小。
根据梯度量级和训练速度更新权重
论文[7]提出的一种缓解不同 loss 量级差异影响的方法。不同任务的量级差异大会导致训练过程中每个任务的梯度大小差异大,造成某个任务主导的问题。为了缓解这个问题,文中给每个任务的 loss 设定了一个可学习的权重,用来自动控制每个任务 loss 的强度,进而影响每个任务更新梯度的大小。
如何确定这个权重呢?首先计算出每个任务的梯度 L2 范数,求所有任务梯度范数的均值,得到一个平均的梯度取值范围。这个取值范围可以视为一个标准范围。此外,计算出每个任务的学习速度,使用更新 t 步后的 loss 和最开始的 loss 求比例。这两项相乘,可以得到一个目标的梯度,公式如下:
这个公式确定目标梯度范数的含义是,希望在所有任务平均的梯度大小基础上,考虑各个任务的更新速度,更新开的梯度就小一点,更新慢的梯度大一点。
根据损失相对下降率设置权重
论文[8]提出了 DWA 方法,用来动态调整多任务的权重。DWA 借鉴了 GradNorm 的思路,利用 loss 的变化情况来衡量任务的学习速度,每个任务的权重可以表示为如下的计算公式:
上面的公式计算每个任务连续两个 step 的 loss 变化情况,作为这个任务的学习速度,归一化后得到每个任务的权重。如果一个任务 loss下降的很快,对应的 w 就比较小,得到的归一化权重比较小,就减小了学习比较快的任务的 loss 权重。
根据损失变化设置权重
论文[9]提出了 Loss-Balanced Task Weighting 方法,能够在模型训练时动态更新任务权重。对于每轮训练的每个任务,考虑当前损失与初始损失之比,并引入超参数 α 平衡权重的影响:
根据动态任务优先级设置权重
论文[10]提出使用模型的表现而不是损失来衡量不同任务的学习难度,为每个任务定义关键绩效指标 (KPI) ,记为。KPI 指标衡量每个任务的学习难度,通常用任务的评估指标 (如分类任务的准确率) 计算。KPI 指标越大,表明任务的学习难度越小:
其中,在第 τ 轮训练中,通过指数滑动更新任务 t 的 KPI 指标:
作者认为优先学习困难的任务能够提高多任务的表现。通过采用 KPI 指标设置不同任务的优先级。
4. 小结
本文介绍了多任务学习的特点,并从模型结构优化角度和训练过程优化(主要是损失函数的优化)角度分别进行了介绍。
在模型结构优化层面分别从硬参数更新和软参数更新角度举例进行介绍,列举了当前比较经典的多任务模型结构的解决方案;在训练过程优化角度,主要是损失函数优化,介绍了不同角度的损失函数优化解决方案,核心是通过梯度或者各个任务损失函数的权重,调节多任务学习过程的平衡性,减小不同任务之间的冲突,进而提升多任务学习的效果。
参考文献
[1] Liu X , He P , Chen W , et al. Multi-Task Deep Neural Networks for Natural Language Understanding[J]. 2019.
[2] https://multi-task-nlp.readthedocs.io/en/latest/
[3] Ma J , Zhe Z , Yi X , et al. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. ACM, 2018.
[4] Tang H , Liu J , Zhao M , et al. Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations[C]// RecSys '20: Fourteenth ACM Conference on Recommender Systems. ACM, 2020.
[5] XI T, SUN Y, YU D, et al. UFO: Unified Feature Optimization[Z]. arXiv, 2022(2022–07–21). DOI:10.48550/arXiv.2207.10341.
[6] Kendall A , Gal Y , Cipolla R . Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
[7] Chen Z , Badrinarayanan V , Lee C Y , et al. GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks[J]. 2017.
[8] Liu S , Johns E , Davison A J . End-to-End Multi-Task Learning with Attention:, 10.1109/CVPR.2019.00197[P]. 2018.
[9] Liu S , Liang Y , Gitter A . Loss-Balanced Task Weighting to Reduce Negative Transfer in Multi-Task Learning[C]// National Conference on Artificial Intelligence. Association for the Advancement of Artificial Intelligence (AAAI), 2019.
[10] Guo M , Haque A , Huang D A , et al. Dynamic Task Prioritization for Multitask Learning[C]// European Conference on Computer Vision. Springer, Cham, 2018.
 开源学习,点赞三连↓
开源学习,点赞三连↓