今天面试,我把运行时数据区域答成了java内存模型,回来把这方面的问题给纠正一下。
以下内容阅读自《深入理解Java虚拟机》第12章
下面小段只做了解即可。重点是Java内存模型。
多任务处理在现代计算机操作系统中是必备的功能。
计算机运行速度与它的存储和通信子系统的速度差距太大,大量时间花费在磁盘I/O、网络通信或者数据库访问上。因此多处理器中,程序的并发将决定服务器能处理的事务数,也即TPS(Transactions Per Second,代表一秒内服务端能响应的请求总数),而这是衡量一个服务性能的好坏。
硬件的效率通过在处理器和内存之间增加高速缓存来解决处理器与内存之间速度的矛盾,同时也引入一个新问题:缓存一致性(Cache Coherence)。在多路处理器系统中,每个处理器都有自己的高速缓存,这种系统称为共享内存多核系统。为解决缓存一致性问题,要求各个处理器访问缓存时遵循一些协议,在读写时要根据协议进行操作,这类协议有MSI、MESI、MOSI、Synapse、Firefly及Dragon Protocol等。
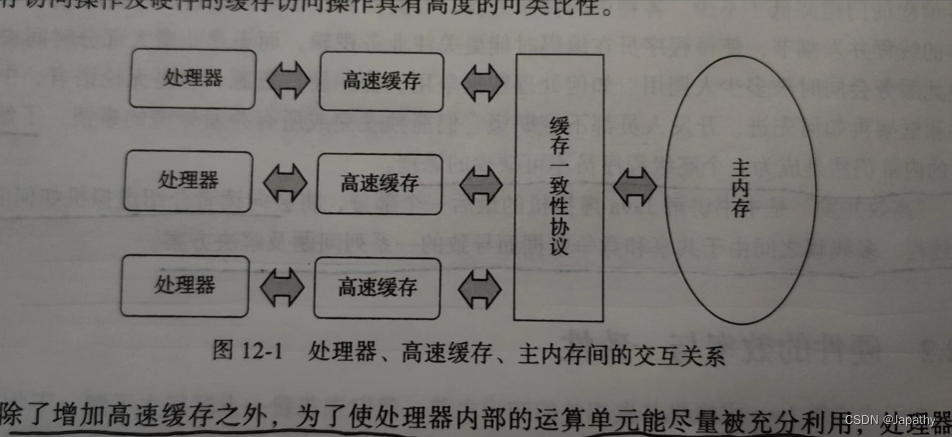
除了高速缓存以外,处理器可能会对输入代码进行乱序执行(Out-Of-Order-Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证对结果与顺序执行的结果一致。Java虚拟机的即时编译器也有指令重排(Instruction Reorder)优化。
Java内存模型
由于不同平台上内存模型有差异,对于C/C++等语言的并发在不同平台上经常出错。而Java要达到各种平台下运行达到一致的内存访问效果,就需要屏蔽各种硬件和操作系统的内存访问差异。就需要定义Java内存模型,这个内存模型必需足够严谨,才能让Java的并发内存访问操作不会产生歧义;但是也必需定义得足够宽松,使得虚拟机得实现能有足够得自由空间去利用硬件得各种特性来获取更好的执行速度。Jdk5发布之后,内存模型终于成熟和完善起来。
主内存和工作内存
Java内存模型主要目的是定义程序中各种变量的访问规则,即关注主内存和工作内存中变量读取和存储的底层细节。
这里的变量不同于Java中的变量,它包含了实例字段、静态字段、构成数组对象的元素,但是不包含局部变量和参数变量,因为后者是线程私有的,不会被共享。
每个Java线程都有一份自己的工作内存以及一份所有线程共有的主内存,每个线程的变量都是主内存的副本,Java线程不能直接跟主内存通信,必须经过工作内存和主内存通信。
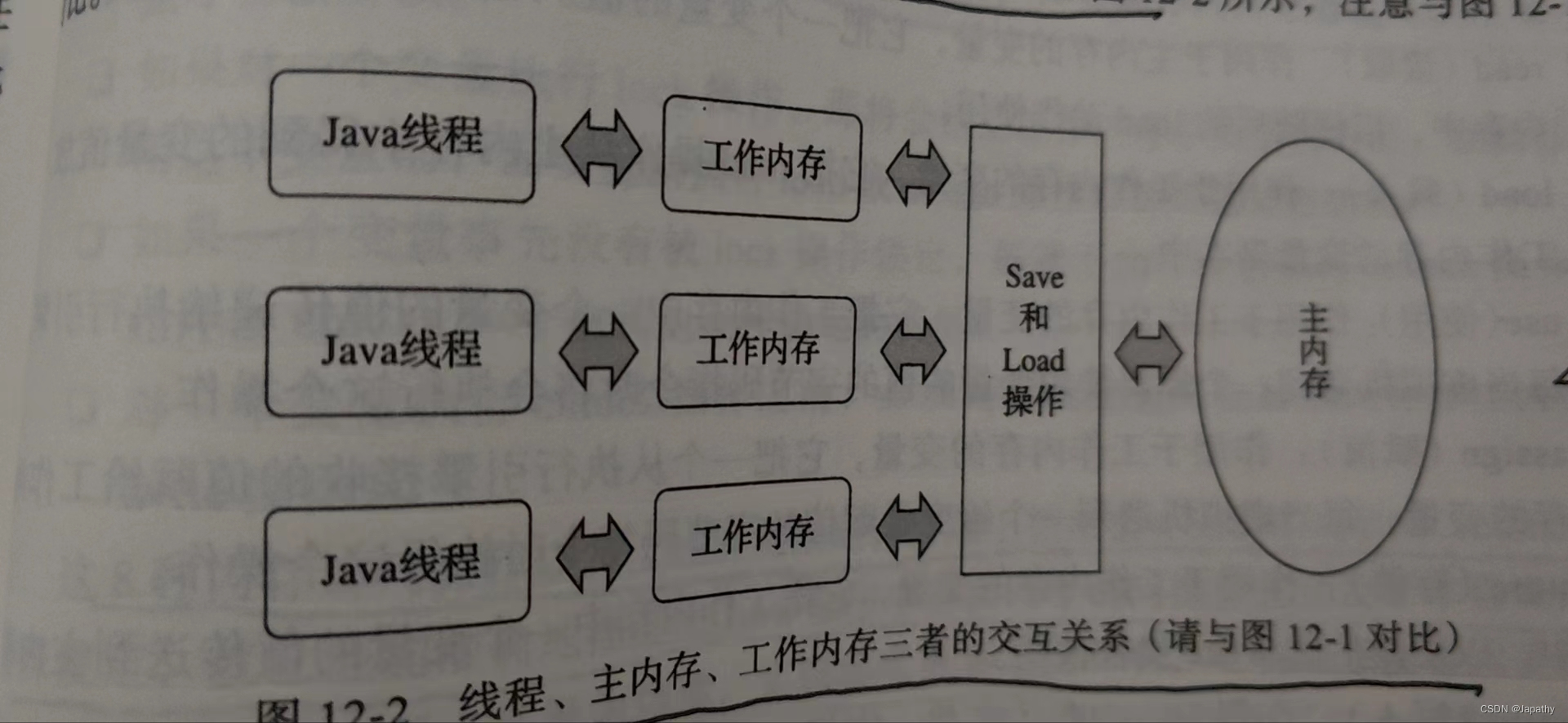
内存交互操作
以下内存只做了解即可。
包括lock、unlock、read、load、use、assign、store、write
lock:锁定,用于主内存中变量,标识该变量被一条线程独占状态
unlock:解锁,用于主内存中变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read:读取,用于主内存中变量,把一个变量从主内存传输到线程的工作内存,以便少候load动作使用。
load:加载,作用于工作内存,把read读取的主内存中的值放入到工作内存的副本中。
use:使用,作用于工作内存,把工作内存中的一个变量传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
assign:赋值,作用于工作内存的变量,他把一个从执行引擎接受的值赋给工作内存,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
store:存储,作用于工作内存的变量,他把一个工作内存中的变量的值传送到主内存中,以便随后的write操作使用。
write:写入,作用于主内存的变量,他store操作从工作内存中得到的变量的值放入到主内存的变量中。
书本里介绍了一系列规则,不一一介绍,有兴趣可以找这本书看下。
作者提到对此无需过分担忧,除了进行虚拟机开发的团队外,大概没有其他开发人员会议这种方式思考并发问题,我们只需要理解Java内存模型的定义即可。
volatile型变量的特殊规则
用通俗且不那么正式的话来说:volatile保证变量对所有线程的可见性。
只保证每次执行引擎获取工作内存的数据时,是取到的最新的值,但是由于Java运算操作符并非原子性的,导致即使是volatile变量的运行在并发下一样不安全。
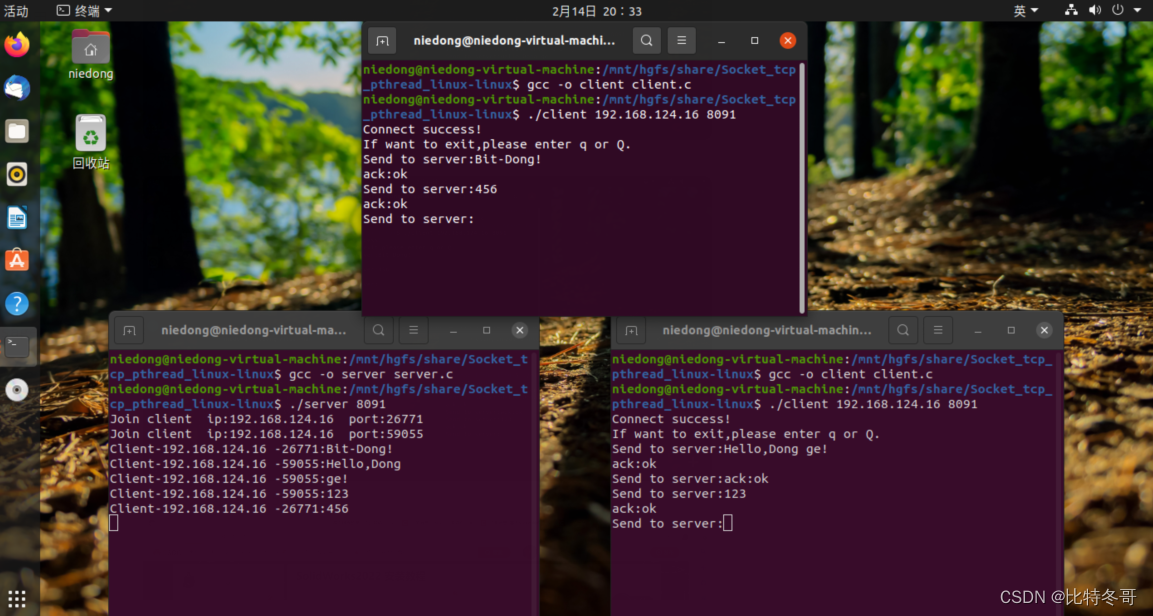
具体可以自行尝试开20个线程,对int类型的volatile变量进行++操作,可以发现值小于应该等于的那个值。如:volatile int race = 0; 那么20个线程,每个线程对这个race变量进行10000个++操作,会得到200000,实际都会小于这个值,因为每次工作线程读取的值都是栈顶最新的值,但是由于其他线程在读取线程后操作了该变量的值,导致了原来读取的值总会小于实际最新的值。可以自行javap反编译查看字节码指令。




![[oeasy]python0085_ASCII之父_Bemer_COBOL_数据交换网络](https://img-blog.csdnimg.cn/img_convert/c5b72143b86c9720e37caa39f837f91b.png)