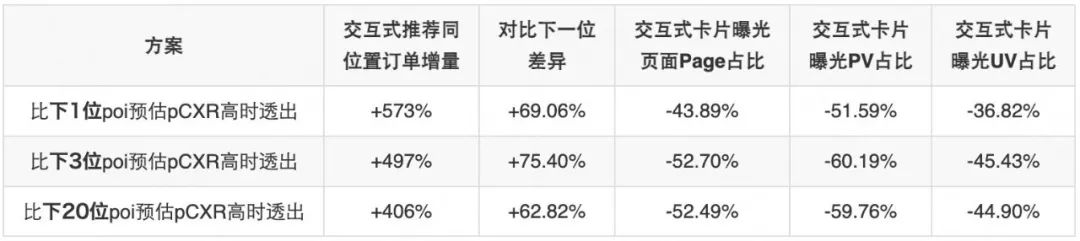
GPT3(二)
前言
因为上一篇文章 从GPT到chatGPT(三):GPT3(一)阅读量挺高,给了我继续更新对该论文进行解读的莫大动力。这篇文章主要讲原论文的第三章(Results),讲的是GPT3在9个不同类型的数据集上表现如何。其实对于包括我在内的大多数读者或工程师来说,模型的实际效果才是最重要的,所以也很有必要好好地来看看这一章的内容。另外,下文中我尽可能以翻译为主,个人理解为辅的方式来进行,所以会以作者的第一人称来叙述。
正文
在前文中 从GPT到chatGPT(三):GPT3(一)我们提到了有8个参数量大小不同的GPT3模型,除此以外,再加上6个更小的语言模型,我们可以去验证 [KMH+20]提出的模型在有效训练后,语言建模性能(由交叉损失函数度量)和模型参数大小遵循幂律,如图一所示。人们可能会担心,交叉熵损失的提升仅仅来自于对训练语料库的虚假细节进行建模。然而,我们将在以下几节中看到,交叉熵损失的改善会在广泛的自然语言范围内带来一致的性能提高。

1 Language Modeling, Cloze, and Completion Tasks
在本节中,我们测试GPT-3在传统的语言建模任务上的性能,以及涉及预测单个感兴趣的单词、完成句子或段落,或在可能完成的文本之间进行选择的相关任务
1.1 Language Modeling
我们在[RWC+19]中测量的Penn Tree Bank(PTB)[MKM+94]数据集上计算zero-shot困惑度(perplexity)。我们在这项工作中省略了4个与维基百科相关的任务,因为它们完全包含在我们的训练数据中,我们还省略了10亿个单词的基准测试,因为我们的训练集中包含了大量数据集。PTB避开了这些问题,因为它早于现代互联网。
我们最大的GPT3模型在PTB上到达了新的SOTA,比原SOTA模型大幅提高了15%,达到了20.50的困惑,表一所示。注意,由于PTB是一个传统的语言建模数据集,因此它没有明确的示例来定义one-shot或few-shot评估,因此我们只测量zeo-shot。

1.2 LAMBADA
LAMBADA数据集[PKL+16]测试了文本中长期依赖性的建模——该模型被要求预测需要阅读一段上下文的句子的最后一个单词。最近有人提出,语言模型的不断扩展正在使这个困难的基准任务的回报率逐渐下降。[BHT+20]反思了最近两项最新研究成果([SSP+19]和[Tur20])之间模型尺寸翻倍所取得的1.5%的微小改进,并认为“继续以数量级的方式扩展硬件和数据尺寸不是前进的道路”。但是,我们发现,这条路仍然充满希望,在zero-shot设置下,GPT-3在LAMBADA上达到76%,比以前的技术水平提高了8%!!!如表二所示:

LAMBADA还展示了少镜头学习的灵活性,因为它提供了一种解决该数据集典型问题的方法。虽然LAMBADA中的完成总是句子中的最后一个单词,但标准语言模型无法知道这个细节。因此,它不仅为正确的结尾赋予了概率,也为段落的其他有效延续赋予了概率。这个问题在过去已经通过停止词过滤器[RWC+19](禁止“继续”词)得到了部分解决。少数镜头设置反而让我们将任务“框”成完形填空测试,并让语言模型从示例中推断出只需要完成一个单词。我们使用以下空白格式填写:

GPT-3在few-shot设置中实现了86.4%的准确率,比以前的SOTA提高了18%以上。我们观察到,few-shot性能随着模型尺寸的增加而显著提高,如图2所示。另外,one-shot总是比zero-shot的效果更差,也许这是因为所有模型仍然需要几个示例来识别模式。

1.3 HellaSwag
HellaSwag数据集[ZHB+19]涉及选择故事或指令集的最佳结尾。这些例子对语言模型来说是困难的,而对人类来说是容易的(准确率达到95.6%)。GPT-3在zero-shot中实现了78.1%的准确性,在few-shot中达到了79.3%的准确性,超过了fine-tune的1.5B参数语言模型[ZHR+19]的75.4%的准确性,但仍远低于fine-tune的多任务模型ALUM实现的85.6%的SOTA效果,如表二所示。
1.4 StoryCloze
我们接下来在StoryCloze 2016数据集[MCH+16]上评估GPT-3,这涉及为五个句子长的故事选择正确的结尾句子。这里,GPT-3在zero-shot中达到83.2%,在few-shot中(K=70)达到87.7%。这仍然比使用基于BERT的模型[LDL19]的微调SOTA低4.1%,但比之前的zero-shot模型提高了大约10%,如表二所示。
2 Closed Book Question Answering
在本节中,我们衡量GPT-3回答有关广泛事实知识的问题的能力。
由于可能的查询量巨大,通常通过使用信息检索系统和文本生成模型(根据输入的query和检索系统召回的文本)来查找/生成相关文本来完成此任务。由于此设置允许系统搜索并条件化可能包含答案的文本,因此称为“开卷”。[RS20]最近证明,一个大型语言模型可以在不依赖辅助信息的情况下,以惊人的速度直接回答问题。他们将这种限制性更强的评估设置称为“闭卷”。他们的研究表明,更高容量的模型也可以表现得更好,我们用GPT-3测试了这一假设。
我们在[RS20]中的三个数据集上评估GPT-3:Natural Questions[KPR+19]、WebQuestions[BCFL13]和TriviaQA[JCWZ17],使用相同的分割。请注意,我们使用的few-shot、one-shot和zero-shot评估比以前的闭卷QA工作更为严格:除了不允许外部内容辅助外,也不允许对问答数据集本身进行微调。
GPT3和一些SOTA模型的对比如下表三所示:

可以看到,在TriviaQA数据集上,GPT3甚至超过了fintune的模型和"开卷"的模型。
但是在NAtrualQS和WebQS数据集上,效果要差一些,而且我们发现从zero-shot到few-shot,效果提升十分明显。我们猜测可能是GPT3的训练数据分布和这两个数据集差距较大,所以效果较差,而且通过few-shot,GPT3也在努力试图适应这两个数据集的分布。
3 Translation
如第上一篇文章所述,我们的大部分数据都是从原始Common Crawl中导出的,只有基于质量的过滤。尽管GPT-3的训练数据仍然主要是英语(按字数计算占93%),但它也包含7%的其他语言文本。这些语言记录在补充材料中。为了更好地理解翻译能力,我们还扩展了我们的分析,以包括另外两种常用语言,德语和罗马尼亚语。
现有的无监督机器翻译方法通常将一对单语数据集上的预处理与反向翻译[SHB15]结合起来,以受控的方式桥接两种语言。相比之下,GPT-3从以自然方式将多种语言混合在一起的训练数据中学习,在单词、句子和文档级别将它们组合在一起。GPT-3还使用一个单独的训练目标,该目标不是为任何任务特别定制或设计的。然而,我们的一次/几次拍摄设置与之前的无监督工作没有严格的可比性,因为它们使用了少量成对的示例(1或64)。这对应于多达一页或两页的上下文训练数据。(个人理解这段话,就是说GPT3不是专门拿来做翻译任务的,所以和专门的翻译模型进行对比不太公平,而且GPT3训练语料是多国语言,且英语占了绝大部分,所以效果差是很正常的。)
结果见表四。zero-shot的GPT-3,仅接收任务的自然语言描述,仍然不如最近的无监督NMT结果。然而,仅为每个翻译任务提供一个示例演示,就可以将性能提高7个BLEU以上,并与之前的工作接近竞争性能。GPT-3在few-shot下进一步提高了另一个4 BLEU,达到先前的无监督NMT工作的平均性能。GPT-3在性能上有明显的偏差,这取决于语言方向。对于所研究的三种输入语言,GPT-3在翻译成英语时显著优于先前的无监督NMT工作,但在另一方向翻译时表现不佳。En-Ro的性能是一个明显的异常值,比之前的无监督NMT工作差很多。由于重复使用GPT-2的字节级BPE标记器,这可能是一个弱点,GPT-2是为几乎完全英语的训练数据集开发的。对于Fr-En和De-En来说,few-shot的GPT-3能够超过我们所能找到的最佳监督结果,但由于我们对文献的不熟悉,以及这些是非竞争性基准,我们怀疑这些结果是否代表了真正的技术水平。对于Ro-En,few-shotGPT-3只比SOTA少不到0.5BLEU,这是通过组合无监督预训练、对608K标记示例的监督微调和反向翻译实现的[LHCG19b]。