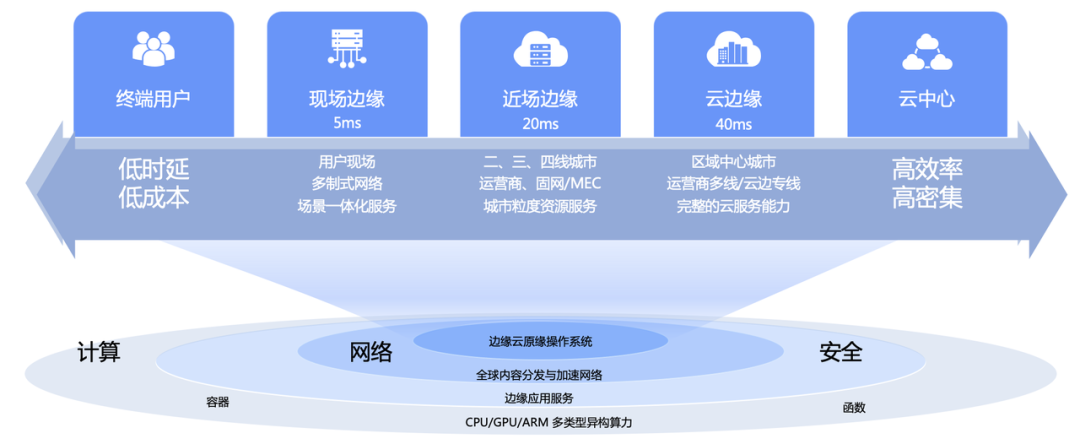
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算、网络、存储、安全、智能为核心能力的新一代分布式云计算解决方案。
边缘存储主要面向适配边缘计算的典型业务场景,如边缘渲染。火山引擎边缘渲染依托底层海量算力资源,可助力用户实现百万渲染帧队列轻松编排、渲染任务就近调度、多任务多节点并行渲染,极大提升渲染效率。
边缘场景存储挑战
这里简单介绍一下在边缘渲染中遇到的存储问题:
需要对象存储与文件系统的元数据统一,实现数据通过对象存储接口上传以后,可以通过 POSIX 接口直接进行操作;
满足高吞吐量的场景需求,尤其是在读的时候;
完全实现 S3 接口和 POSIX 接口。
为了解决在边缘渲染中遇到的存储问题,团队花了将近半年的时间开展了存储选型测试。最初,团队选择了公司内部的存储组件,从可持续性和性能上来说,都能比较好的满足我们的需求。
但是落地到边缘场景,有两个具体的问题:
首先,公司内部组件是为了中心机房设计的,对于物理机资源和数量是有要求的,边缘某些机房很难满足;
其次,整个公司的存储组件都打包在一起,包括:对象存储、块存储、分布式存储、文件存储等,而边缘侧主要需要文件存储和对象存储,需要进行裁剪和改造,上线稳定也需要一个过程。
团队讨论后,形成了一个可行的方案:CephFS + MinIO 网关。MinIO 提供对象存储服务,最终的结果写入 CephFS,渲染引擎挂载 CephFS,进行渲染操作。测试验证过程中,文件到千万级时,CephFS 的性能开始下降,偶尔会卡顿,业务方反馈不符合需求。
同样的,基于 Ceph 还有一个方案,就是使用 Ceph RGW + S3FS。这个方案基本能满足要求,但是写入和修改文件的性能不符合场景要求。
经过三个多月的测试之后,我们明确了边缘渲染中对于存储的几个核心诉求:
运维不能太复杂:存储的研发人员能够通过运维文档上手操作;后期扩容以及处理线上故障的运维工作需要足够简单。
数据可靠性:因为是直接给用户提供存储服务,因此对于写入成功的数据不允许丢失,或者出现跟写入的数据不一致的情况。
使用一套元数据,同时支持对象存储和文件存储:这样业务方在使用的时候,不需要多次上传和下载文件,降低业务方的使用复杂度。
针对读有比较好的性能:团队需要解决的是读多写少的场景,因此希望有比较好的读性能。
社区活跃度:在解决现有问题以及积极推进新功能的迭代时,一个活跃的社区能有更快的响应。
明确核心诉求之后,我们发现前期的三个方案都不太满足需求。
初识 JuiceFS
火山引擎边缘存储团队在 2021 年 9 月了解到了 JuiceFS,并跟 Juicedata 团队进行了一些交流。经过交流我们决定在边缘云场景尝试一下。JuiceFS 的官方文档非常丰富,可读性很高,通过看文档就可以了解比较多的细节。
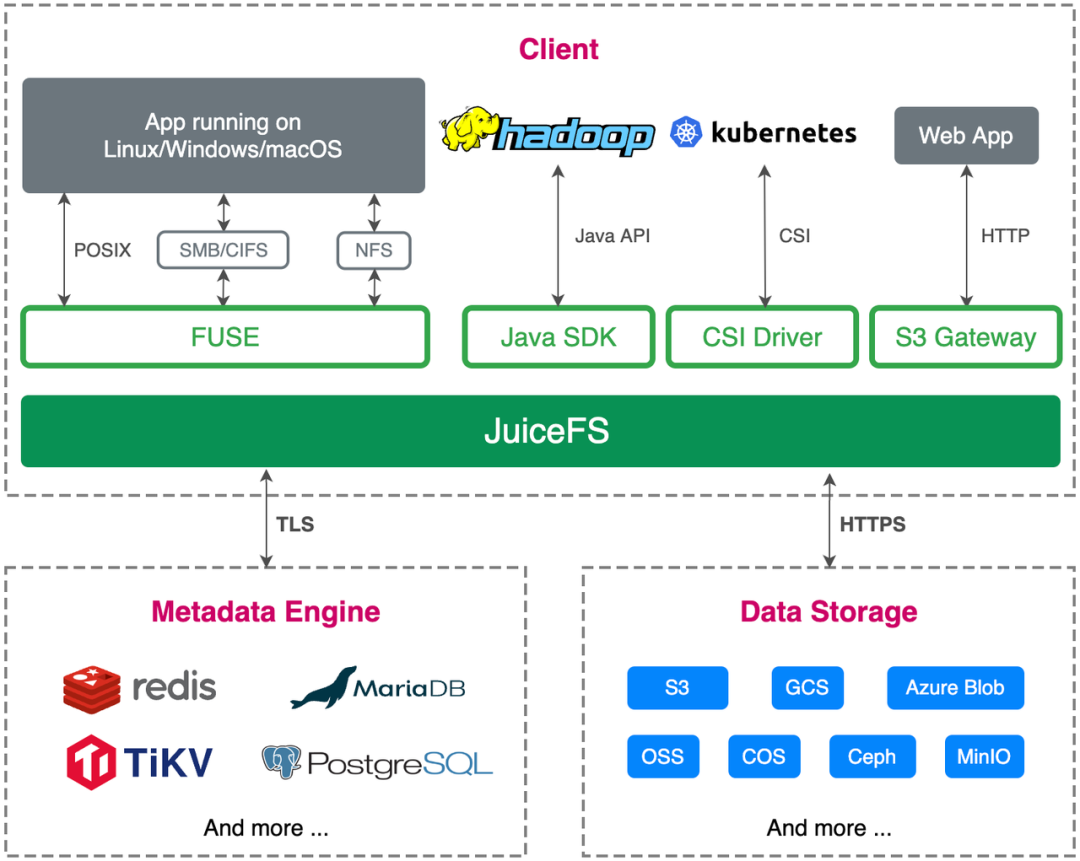
于是,我们就开始在测试环境做 PoC 测试,主要关注的点是可行性验证,运维和部署的复杂度,以及跟上游业务的适配,是否符合上游业务的需求。
我们部署了 2 套环境,一个环境是基于单节点的 Redis + Ceph 搭建,另一个环境是基于单实例的 MySQL + Ceph 搭建。
在整个环境搭建方面因为 Redis、MySQL 和 Ceph(通过 Rook 部署)都比较成熟,部署运维方案可以参考的资料也比较全面,同时 JuiceFS 客户端也能够简单和方便地对接这些数据库和 Ceph,因此整体的部署流程非常流畅。
业务适配方面,边缘云是基于云原生开发和部署的,JuiceFS 支持 S3 API,同时完全兼容 POSIX 协议,还支持 CSI 的方式挂载,完全满足我们的业务需求。
综合测试后,我们发现 JuiceFS 完全契合业务方的需求,可以在生产上进行部署运行,满足业务方的线上需求。
使用 JuiceFS 的收益
业务流程优化
在使用 JuiceFS 之前,边缘渲染主要利用字节跳动内部的对象存储服务(TOS),用户上传数据到 TOS 中,渲染引擎再从 TOS 上将用户上传的文件下载到本地,渲染引擎读取本地的文件,生成渲染结果,再将渲染结果上传回 TOS,最后用户从 TOS 中下载渲染结果。整体的交互流程有好几个环节,而且中间涉及到比较多的网络以及数据拷贝,所以在这个过程中会存在网络抖动或者时延偏高的情况,影响用户体验。

使用 JuiceFS 后的简化流程
使用 JuiceFS 之后,流程变成了用户通过 JuiceFS S3 网关进行上传,由于 JuiceFS 实现了对象存储和文件系统的元数据的统一,可以直接将 JuiceFS 挂载到渲染引擎中,渲染引擎以 POSIX 接口对文件进行读写,最终用户直接从 JuiceFS S3 网关中下载渲染结果,整体的流程更加简洁和高效,同时也更稳定。
读文件加速,大文件顺序写加速
得益于 JuiceFS 的客户端缓存机制,我们可以将频繁读取的文件缓存到渲染引擎本地,极大加速了文件的读取速度。我们针对是否打开缓存做了对比测试,发现使用缓存后可以提升大约 3-5 倍的吞吐量。
同样,因为 JuiceFS 的写模型是先写内存,当一个 chunk(默认 64M)被写满,或者应用调用强制写入接口(close 和 fsync 接口)时,才会将数据上传到对象存储,数据上传成功后,再更新元数据引擎。所以,在写入大文件时,都是先写内存,再落盘,可以大大提升大文件的写入速度。
目前边缘的使用场景主要以渲染类为主,文件系统读多写少,文件写入也是以大文件为主。这些业务场景的需求和 JuiceFS 的适用场景非常吻合,业务方在存储替换为 JuiceFS 后,整体评价也很高。
在边缘存储中如何使用 JuiceFS
JuiceFS 主要是在 Kubernetes 上部署,每个节点都有一个 DaemonSet 容器负责挂载 JuiceFS 文件系统,然后以 HostPath 的方式挂载到渲染引擎的 pod 中。如果挂载点出现故障,DaemonSet 会负责自动恢复挂载点。
在权限控制上,边缘存储是通过 LDAP 服务来认证 JuiceFS 集群节点的身份,JuiceFS 集群的每个节点都通过 LDAP 的客户端与 LDAP 服务进行验证。

我们目前应用的场景主要还是以渲染为主,后期会扩展到更多业务场景。在数据访问上,边缘存储目前主要通过 HostPath 的方式进行访问,后期如果涉及到弹性扩容的需求,会考虑使用 JuiceFS CSI Driver 来部署。

JuiceFS 存储生产环境实践经验
元数据引擎
JuiceFS 支持了非常多的元数据引擎(如 MySQL、Redis),火山引擎边缘存储生产环境采用的是 MySQL。我们在评估了数据量与文件数的规模(文件数在千万级,大概几千万,读多写少场景),以及写入与读取性能以后,发现 MySQL 在运维、数据可靠性,以及事务方面都做得比较好。
MySQL 目前采用的是单实例和多实例(一主二从)两种部署方案,针对边缘不同的场景灵活选择。在资源偏少的环境,可以采用单实例的方式来进行部署,MySQL 的吞吐在给定的范围之内还是比较稳定的。这两种部署方案都使用高性能云盘(由 Ceph 集群提供)作为 MySQL 的数据盘,即使是单实例部署,也能保证 MySQL 的数据不会丢失。
在资源比较丰富的场景,可以采用多实例的方式来进行部署。多实例的主从同步通过 MySQL Operator 提供的 orchestrator 组件实现,两个从实例全部同步成功才认为是 OK 的,但是也设置了超时时间,如果超时时间到了还没有同步完成,则会返回成功,并打出报警。待后期的容灾方案健全后,可能会采用本地盘作为 MySQL 的数据盘,进一步提升读写性能,降低时延以及提升吞吐。
MySQL 单实例配置
容器资源:
CPU:8C
内存:24G
磁盘:100G(基于 Ceph RBD,在存储千万级文件的场景下元数据大约占用 30G 磁盘空间)
容器镜像:mysql:5.7
MySQL 的 my.cnf 配置:
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要删除这个配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G对象存储
对象存储采用自建的 Ceph 集群,Ceph 集群通过 Rook 部署,目前生产环境用的是 Octopus 版本。借助 Rook,可以以云原生的方式运维 Ceph 集群,通过 Kubernetes 管控 Ceph 组件,极大降低了 Ceph 集群的部署和管理复杂度。
Ceph 服务器硬件配置:
128 核 CPU
512GB 内存
系统盘:2T * 1 NVMe SSD
数据盘:8T * 8 NVMe SSD
Ceph 服务器软件配置:
操作系统:Debian 9
内核:修改 /proc/sys/kernel/pid_max
Ceph 版本:Octopus
Ceph 存储后端:BlueStore
Ceph 副本数:3
关闭 Placement Group 的自动调整功能
边缘渲染主打的就是低时延高性能,所以在服务器的硬件选择方面,我们给集群配的都是 NVMe 的 SSD 盘。其它配置主要是基于火山引擎维护的版本,操作系统我们选择的是 Debian 9。数据冗余上为 Ceph 配置了三副本,在边缘计算的环境中可能因为资源的原因,用 EC 反而会不稳定。
JuiceFS 客户端
JuiceFS 客户端支持直接对接 Ceph RADOS(性能比对接 Ceph RGW 更好),但这个功能在官方提供的二进制中默认没有开启,因此需要重新编译 JuiceFS 客户端。编译之前需要先安装 librados,建议 librados 的版本要跟 Ceph 的版本对应,Debian 9 没有自带与 Ceph Octopus(v15.2.*)版本匹配的 librados-dev 包,因此需要自己下载安装包。
安装好 librados-dev 之后,就可以开始编译 JuiceFS 客户端。我们这边使用了 Go 1.19 来编译,1.19 中新增了控制内存分配最大值(https://go.dev/doc/gc-guide#Memory_limit)这个特性,可以防止极端情况下 JuiceFS 客户端占用过多内存而出现 OOM。
make juicefs.ceph复制代码
编译完 JuiceFS 客户端即可创建文件系统,并在计算节点挂载 JuiceFS 文件系统了,详细步骤可以参考 JuiceFS 官方文档。
未来和展望
JuiceFS 是一款云原生领域的分布式存储系统产品,提供了 CSI Driver 组件能够非常好的支持云原生的部署方式,在运维部署方面为用户提供了非常灵活的选择,用户既可以选择云上,也可以选择私有化部署,在存储扩容和运维方面较为简单。完全兼容 POSIX 标准,以及跟 S3 使用同一套元数据的方式,可以非常方便地进行上传、处理、下载的操作流程。由于其后端存储是对象存储的特点,在随机小文件读写方面有较高的延迟,IOPS 也比较低,但在只读场景,结合客户端的多级缓存,以及大文件场景,还有读多写少的场景,JuiceFS 有比较大的优势,非常契合边缘渲染场景的业务需求。
火山引擎边缘云团队未来与 JuiceFS 相关的规划如下:
更加云原生:目前是以 HostPath 的方式来使用 JuiceFS,后面我们考虑到一些弹性伸缩的场景,可能会切换到以 CSI Driver 的方式来使用 JuiceFS;
元数据引擎升级:抽象一个元数据引擎的 gRPC 服务,在其中提供基于多级缓存能力,更好地适配读多写少的场景。底层的元数据存储,可能会考虑迁移到 TiKV 上,以支持更多的文件数量,相对于 MySQL 能够更好地通过横向扩展来增加元数据引擎的性能;
新功能及 bug 修复:针对当前业务场景,会增加一些功能以及修复一些 bug,并期望为社区贡献 PR,回馈社区。
关于作者
何兰州,火山引擎边缘计算高级开发工程师,负责边缘存储的技术选型,演进和稳定性;研究领域主要有分布式存储和分布式缓存;云原生开源社区爱好者。