本内容来自公众号“布博士”------(擎创科技资深产品专家)
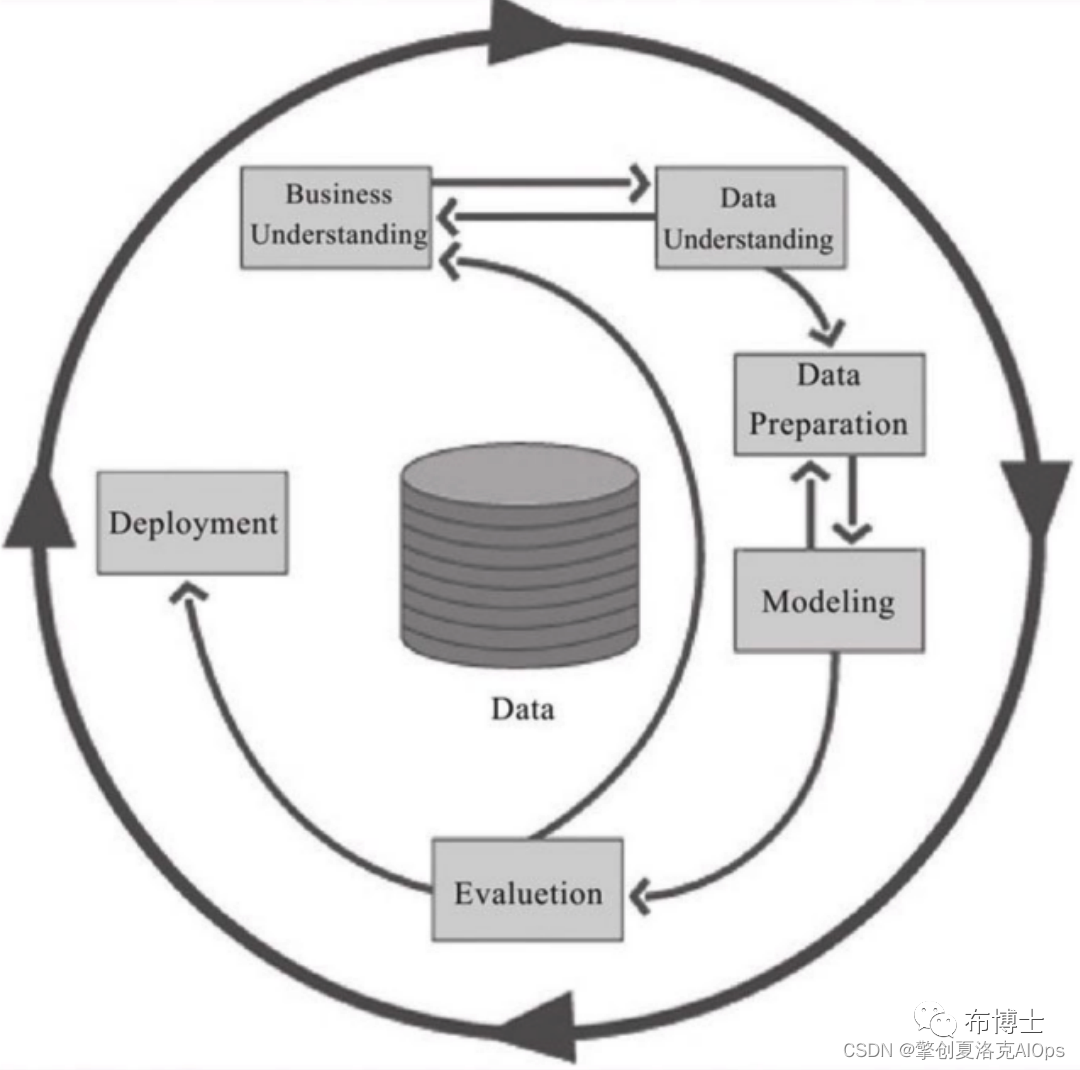
在上期内容中,我们了解到跨行业数据挖掘标准流程包括6大过程,分别为业务理解(Business Understanding)、数据理解(Data Understanding)、数据准备(DataPreparation)、模型搭建(Modeling)、模型评估(Evaluation)和模型发布(Deployment)。这6大过程的顺序不是固定不变的,在不同的项目中,可有不同的流转过程。其次,6大过程是循环的,每次针对不同业务目标的深入理解会不断地进行优化和调整,后续的循环过程可以不断从上一次的6大过程中得到借鉴和启发。
前面已经说完了前三个过程,上期内容回顾,戳→案例分享 | 某券商利用AI技术进行告警关联分析(上)
今天要跟大家分享的内容主要分为下面这几点:
●告警关联分析模型建立过程介绍(模型搭建、模型评估、模型发布)
● 下一步:产品化
一、告警关联分析模型建立过程介绍
1.模型搭建(Modeling)
该环节是6大过程中最核心的环节,也是数据科学家发挥的主战场,在该环节,主要完成:
模型选择:在模型选择阶段,数据科学家需要针对业务的理解、数据特征、期望的结果来选择适当的算法,在本例中我们选择FP-Growth算法加create Association Rules算子来生成最终的关联模式。
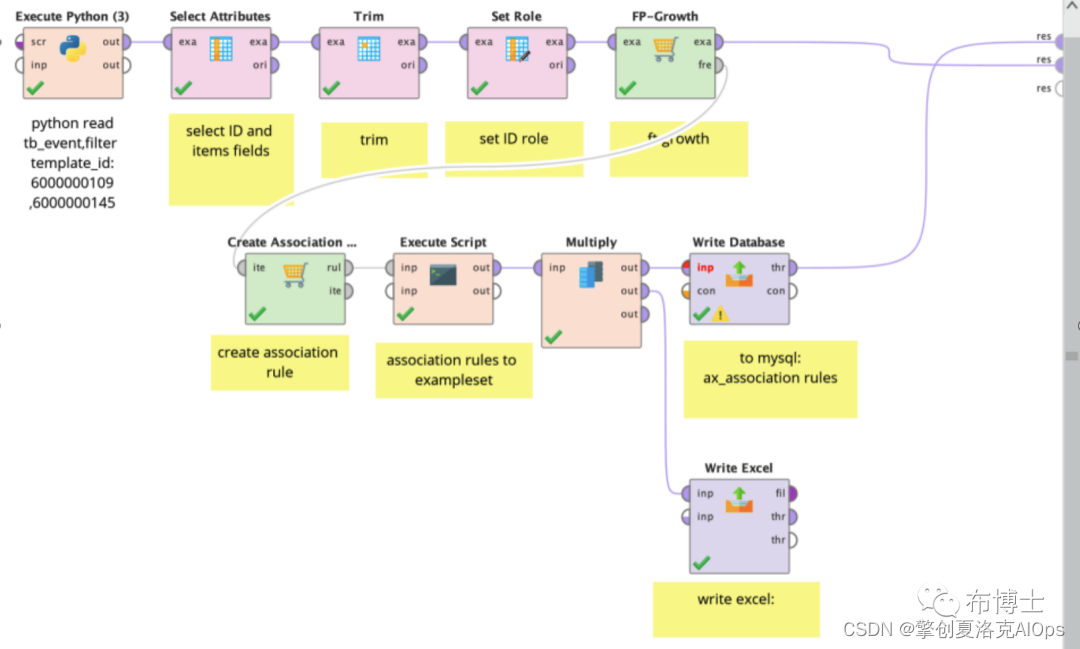
创建模型:创建模型是一个整体的流程,包括选择数据、对数据的预处理、空值的过滤、选择数据集中的特征字段、处理后结果输入算法、算法结果输出到数据库或外部文件,如下图是我们用rapidminer设计的完整流程。
评估模型:通常用于评价模型产生的结果好坏程度,在该场景下也用于对模型产生的结果进行筛选,关联分析算法FP-Growth产生的结果有三个非常重要的评价指标:
支持度:用于统计某一个关联分析结果在所有历史事件中出现的比例。如:在本例中我们的历史事件一共1万左右,而某个关联分析结果在历史上可能一共出现30次,则该关联分析结果的支持度=30/10000。通常情况下,我们会在出现的结果中会选择一些比较频繁出现的关联分析结果。分值越高,代表该关联分析结果发生越频繁。
置信度:用于衡量关联分析结果中前导出现且同时出现后继的比例,反映的是该分析结果的可靠程度。假设x历史上发生100次,(x,y)历史上同时发生的次数为30次,则(x,y)的置信度为30/100=0.3,分值越高代表该关联分析结果的可信度越高。在本次的项目中我们筛选出来的置信度在0.8以上的才会推荐出来。
提升度:是为了避免某一种告警在历史上发生太频繁了,以至于“碰巧”会跟其它告警经常一起发生的情况,导致支持度和置信度都非常高,这种情况在该项目中就发生了,如该券商对关键的密码策略会进行检测以发现到期后没有进行密码修改的主机,并产生告警,通常这种只是提醒,在该券商的大多系统管理员不会处理,这样就导致这种告警每天都会发生,也产生了很多的关联分析结果,通过提升度我们可以将这些结果有效排除。通常提升度的取值需要>1,且越大越好。
2.模型评估(Evaluation)
模型评估,一方面是在建模型阶段数据科学家对产生结果的初次评估,另外针对产生的结果在模型评估阶段数据科学家需要对模型产生的结果整理模型评估报告由客户方运维专家来验证模型所产生的结果是否符合预期。

上图即为本次模型挖掘所产生之关联分析结果,经过客户的评审确认,客户认为这些挖掘出来的关联分析结果非常有意义,各列代表的意义详述如下:
{premise,Conclusion}两列的组合代表一条完整的告警关联分析结果
Premise:代表关联分析结果的前驱节点
Conclusion:代表关联分析结果的后继节点
Support:代表支持度,代表前驱及后续节点同时发生的情况下的事件总数,占统计时段(本项目为近6个月的历史数据)所有事件总数的比例,上一节做了详细的介绍
Confidence:代表置信度,上一节做了详细的介绍,本例中我们只关注算法结果中置信度超过80%的结果,以第一行为例,当前驱节点6000000116(告警模板ID)告警发生时,后续节点600000906有81.8%的可能性会发生,而最后一条记录前驱节点{600000116,6000001494}发生时,后续节点600000906是百分之百会发生的,这些挖掘出来的模式都是强模式结果。
Lift:代表提升度,从本例中可以看到所有的取值都大于1,代表这些算法给出的结果都是可用的。
{600000116,6000001494,600000906}是告警辨析产品对告警内容进行归纳之后,生成的告警模型ID,在评审阶段需要转换为如下的模板信息,才能够有效协助运维专家对告警关联分析结果进行评审,如下图所示

通过对这些结果的数据科学家评审和客户的评审之后,我们就可以将这些结果应用于告警关联场景中,每次捕获这种关联场景时即生成关联告警。
3.模型发布(Deployment)
本次项目,我们使用该券商核心业务系统过去6个月,约33万条告警数据,经过5轮的学习过程、两次结果的评审过程,生成了22笔有意义的关联分析结果,针对这些有意义的结果如何在生产环境进行使用,如何进行模型发布,是我们本章要讨论的主要内容。
一般模型在进行评审和运维专家审核完成认为合格之后,就涉及到模型要发布到生产环境使用,通常会包括三种方式:
生成模型文件:会生成一个针对该项目的解决特定问题的模型文件,由该模型文件来对实时接入的告警数据进行识别,并打上结果标签。
在线学习模式:比较适用于有监督的学习方法,生成模型之后会对实时接入的告警数据进行判别,并打上结果标签,后续人工在复核的过程中如果发现结果有问题,可以进行人工修改,而后台算法会根据人为的反馈结果进行模型的优化。
规则化:针对算法生成的结果,人工来进行审核并总结特征,然后通过配置规则的方式来完成对实时接入告警的识别。
考虑到模型未来的快速部署、对结果准确性、模型可解析性等的综合要求,我们建议采用第三种方案,针对由数据科学家和运维专家确认之后的关联分析结果进行总结、归纳生成专家规则,这样后续告警再接入时通过专家规则进行匹配,命中之后生成关联场景。
二、下一步:产品化

整个告警辨析中心产品我们划分成了两个主要的部分:
标准版:对标竞争对手的统一告警管理平台,定位在解决告警信息的集成接入、标准化、过滤、维护期管理、告警压缩降噪、告警通知等能力。
高级版:定位为告警的智能分析及处置平台,主要完成分析模型构建、告警的智能分析、处置、对处置结果的优化总结和回顾,而告警的关联分析我们定位为高级版中的一部分。在未来的版本规划中,我们将实现对整个过程的在线化和产品化,如下图所示:

接入告警:完成对不同监控源告警的接入。
数据转换处理:按算法的要求,由产品自身完成对告警数据的在线转换处理,并生成算法所需要的输入数据。
算法进行关联分析:算法在线接收转换处理后的告警数据,定期对告警数据进行关联分析。
生成关联分析结果:算法生成关联分析结果。
在线评审:针对生成的结果,数据科学家和运维专家可以在线对产生的结果进行审核。
评审结果规则化:针对评审后的结果,进行总结和归纳,生成关联场景的专家规则。
生成关联场景:在线接收告警之后,通过关联场景的专家规则进行匹配,最终生成关联场景,运维工程师可以在告警工作台看到关联之后的告警并进行处置。
关于《某券商利用AI技术进行告警关联分析》的分享到这里就告一段落了,有什么问题或疑惑,欢迎大家评论区留言一起讨论~

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司致力于协助企业客户提升对运维数据的洞见能力,优化运维效率,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

更多运维思路与案例持续更新中,敬请期待
随手点关注,更新不迷路~