一、Hadoop的概念
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
二、Hadoop的核心组成
Hadoop的三大核心组件分别是:
HDFS(Hadoop Distribute File System):hadoop的数据存储工具。
YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。
Hadoop MapReduce:分布式计算框架
1,HDFS数据存储工具
HDFS全称Hadoop Distributed File System,即分布式文件系统。HDFS具有高容错能力,可以部署到低成本的硬件上。它适用于大数据应用,对数据可以实现高吞吐量访问,并且可以实现流式的数据访问。
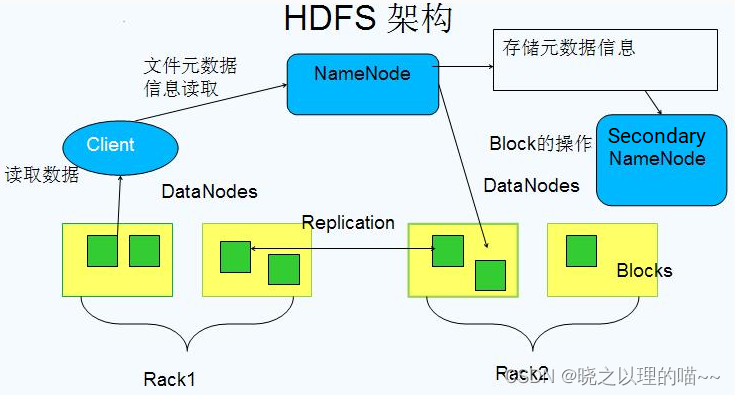
(1)NameNode
NameNode是存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小;一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度;数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护;NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性。
(2)Secondary NameNode
Secondary NameNode定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机。
(3)DataNode
DataNode保存具体的block数据,负责数据的读写操作和复制操作。DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息。DataNode之间会进行通信,复制数据块,保证数据的冗余性。
(4)Block数据块
Block数据块是基本存储单位,一般大小为64M;一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小;Block数据块是基本的读写单位,类似于磁盘的页,每次都是读写一个块,每个块都会被复制到多台机器,默认复制3份;
注意:HDFS2.x以后的block默认128M
2,YARN资源管理器
YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN基本流程:
(1)Job submission
从ResourceManager 中获取一个Application ID 检查作业输出配置,计算输入分片 拷贝作业资源(job jar、配置文件、分片信息)到 HDFS,以便后面任务的执行
(2)Job initialization
ResourceManager 将作业递交给 Scheduler(有很多调度算法,一般是根据优先级)Scheduler 为作业分配一个 Container,ResourceManager 就加载一个 application master process 并交给 NodeManager。管理 ApplicationMaster 主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个 Map task 和相应的 reduce task Application Master 还决定如何运行作业,如果作业很小(可配置),则直接在同一个 JVM 下运行。
(3)Task assignment
ApplicationMaster 向 Resource Manager 申请资源(一个个的Container,指定任务分配的资源要求)一般是根据 data locality 来分配资源。
(4)Task execution
ApplicationMaster 根据 ResourceManager 的分配情况,在对应的 NodeManager 中启动 Container 从 HDFS 中读取任务所需资源(job jar,配置文件等),然后执行该任务。
(5)Progress and status update
定时将任务的进度和状态报告给 ApplicationMaster Client 定时向 ApplicationMaster 获取整个任务的进度和状态。
(6)Job completion
Client定时检查整个作业是否完成 作业完成后,会清空临时文件、目录等。
3,MapReduce分布式计算框架
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce执行过程:
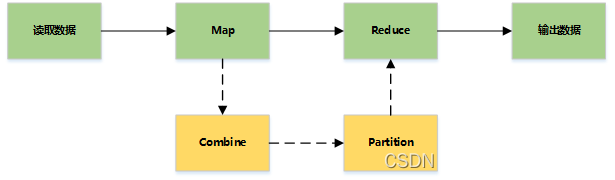
(1)读取数据
录阅读器会翻译由输入格式生成的记录,记录阅读器用于将数据解析给记录,并不分析记录自身。记录读取器的目的是将数据解析成记录,但不分析记录本身。它将数据以键值对的形式传输给mapper。通常键是位置信息,值是构成记录的数据存储块.自定义记录不在本文讨论范围之内.
(2)Map
在映射器中用户提供的代码称为中间对。对于键值的具体定义是慎重的,因为定义对于分布式任务的完成具有重要意义.键决定了数据分类的依据,而值决定了处理器中的分析信息.本书的设计模式将会展示大量细节来解释特定键值如何选择.
(3)Shuffle and Sort
ruduce任务以随机和排序步骤开始。此步骤写入输出文件并下载到本地计算机。这些数据采用键进行排序以把等价密钥组合到一起。
(4)Reduce
reduce采用分组数据作为输入。该功能传递键和此键相关值的迭代器。可以采用多种方式来汇总、过滤或者合并数据。当reduce功能完成,就会发送0个或多个键值对。
(5)输出数据
输出格式会转换最终的键值对并写入文件。默认情况下键和值以tab分割,各记录以换行符分割。因此可以自定义更多输出格式,最终数据会写入HDFS。
三、Hadoop的生态系统
构成Hadoop的整个生态系统的所有组件可划分为4个层次
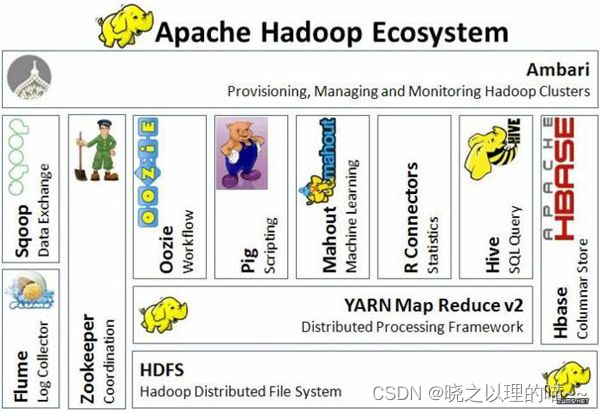
1,Ambari
pache Ambari设计的目的就是为了使Hadoop集群的管理更加简单,比如创建、管理、监视
Hadoop 的集群。
2,Hive
ive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
3,Hbase
Hbase是一个nosql数据库,相较于RDBMS,它不支持传统关系型数据库的typed columns(列类型), secondary indexes(二级索引), triggers(触发器), and advanced query languages(高级查询语言)等特性。它的长处在数据存储,是真正意义上的分布式数据库。通过添加RegionServer机器,即可实现hbase的线性和模块化扩展。
4,Pig
Apache Pig 在 MapReduce的基础上创建了更简单的过程语言抽象,为 Hadoop 应用程序提供了一种更加接近结构化查询语言 (SQL) 的接口。因此,我们不需要编写一个单独的MapReduce 应用程序,可以用 Pig Latin 语言写一个脚本,在集群中自动并行处理与分发该脚本。
5,Mahout
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
6,ZooKeeper
ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。由于ZooKeeper的开源特性,后来我们的开发者在分布式锁的基础上,摸索了出了其他的使用方法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
7,Oozie
Oozie是作业流调度系统。通过它,我们可以把多个Map/Reduce作业组合到一个逻辑工作单元中,从而完成更大型的任务。
8,Sqoop
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
9,Flume
Flume是日志收集工具,Cloudera开源的日志收集系统。
以上是Hadoop核心组成和生态系统的一些概念,内容信息来自于网络整理,供大家参考学习。