72 优化算法【动手学深度学习v2】
深度学习学习笔记
学习视频:https://www.bilibili.com/video/BV1bP4y1p7Gq/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=75dce036dc8244310435eaf03de4e330
优化问题一般是最小化f(x) 。C 是可以限制的,具体的优化里面有不同的版本,深度学习常用将C 不设限。

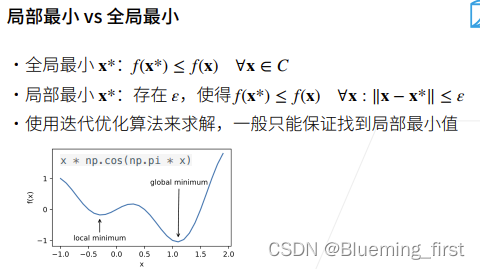
全局最小是说x* 比 C 中所有的 x还要小,局部最小x* 是指存在一个 s 使得 x* 与所有的 x 直接绝对值差小于等于 s。
一般迭代算法只能保证找到局部最小值。
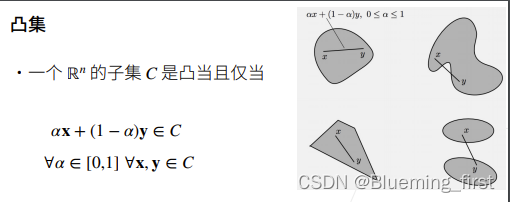
特例,凸集就是在区域中任选两个点相连,相连的那条线一定在区域里面。
在函数上任意取两点,函数值一定在两点连线值的下面。
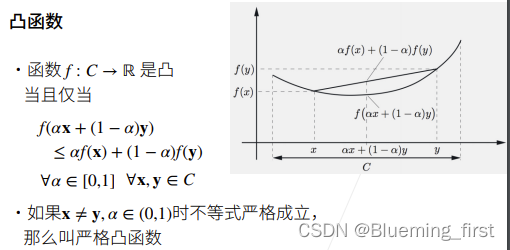
如果一个代价函数,f 是个凸函数,限制集合也是凸的,那么就是凸优化问题,那么优化函数找到的最小值一定是全局的最小值。
严格凸优化问题有唯一的全局最小值。

机器学习中绝大多数是非凸的,只有两个是凸函数 线性回归和Softmax回归。
卷积本身是线性的,但加上激活函数后就不是了。

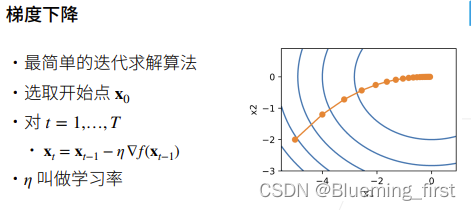
梯度下降是最简单的迭代求解算法,每次选取一个开始点x0,然后对每个时间t在当前点求梯度,当前点减去 学习率乘以梯度。
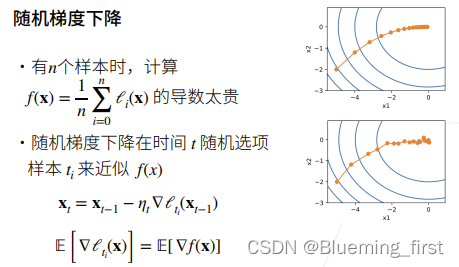
当你有n个样本时 f(x) 是所有样本上的损失的平均,那么样本很多的时候求梯度是很贵的,所有通常是用的随机梯度下降。
随机梯度下降是说在时间t的时候随机选一个样本ti,在ti上计算梯度来近似整个数据上的梯度,因为导数是线性可加的,随机取的和整体上的期望是差不多的。
真实用的是小批量随机梯度下降,是由于计算的原因。
随机梯度下降用单样本算梯度,单样本随机梯度下降很难完全利用硬件资源,因为CPU/GPU都是多线程,单样本的计算量不足以占据整个硬件的资源,所以用多个样本算梯度,这样并行度就提高了。
小批量随机梯度下降是说在时间t采样一个样本子集,样本子集大小是b(批量大小),对采样的b个样本都算梯度并取平均值 作为近似整个样本的梯度,期望没有变,好处是降低了方差(在方向上的抖动性变好了一点)。
随机梯度下降比梯度下降慢是因为每次算一个样本用不了硬件的并行度。

冲量法是说使用一个平滑过的梯度对权重进行更新,在真实数据中的loss函数是比较不平滑的,所以冲量法维护一个惯性(比较平滑的改变方向)。假设在样本上算的梯度是gt,vt是冲量,再更新权重时减去 学习率 乘以 vt。
展开vt的计算公式 实际上vt并不完全取决于上一个时刻的梯度,β 是小于 0的值,随着过去的gti 成指数级减小。

最多使用的优化算法。Adam 未必比SGD+冲量法好,好处是对学习率没那么敏感(它是一个非常平滑的SGD,它做了非常多的平滑)一旦很平滑对学习率那么敏感,如果你没有太多时间去调参的话,Adam是个很好的选择。
Adam 为记录一个vt,公式中β1是不需要调的,通常取0.9 (冲量法中β是需要调的)。

Adam 还要记录一个st,gt^2 是每个元素的平滑,β2通常等于0.999,计算后重新调整gt。
整理来讲Adam是比较稳定的。

QA:
- faster RCNN 或者Yolo是自己实现好,还是直接用开源的好?
当然如果自己能够实现一遍就很好,但是会难一点。建议自己实现一个简单的版本,然后去看开源的实现的细节(因为开源的细节处理会好很多)。 - 大数据集用相对大的模型,小数据集用相对于小的模型。相对的对应效果会好一些。
- 写代码写不出来没关系,最重要的是能看懂,能用别人的代码。