目录
一、基本概念
(一)什么是Hive
(二)优势和特点
(三)Hive元数据管理
二、Hive环境搭建
1.自动安装脚本
2./opt/soft/hive312/conf目录下创建hive配置文件hive-site.xml
3.拷贝一个jar包到hive下面的lib目录下
4.删除hive的guava,拷贝hadoop下的guava
5.重启环境变量
6.启动hadoop服务
7.启动历史服务器
8.Hive初始化数据到mysql中
一、基本概念
(一)什么是Hive
Hive是基于Hadooop的数据仓库解决方案,将结构化的数据文件映射为数据库表,Hive提供类sql的查询语言HQL(Hive Query Language),Hive让更多的人使用Hadoop。
Hive官网:https://hive.apache.org/
(二)优势和特点
- 提供了一个简单的优化模型
- HQL类SQL语法,简化MR开发
- 支持在不同的计算框架上运行
- 支持在HDFS和HBase上临时查询数据
- 支持用户自定义函数、格式
- 常用于ETL操作和BI
- 稳定可靠(真是生产环境)的批处理
- 有庞大活跃的社区
- MapReduce执行效率更快,Hive开发效率更快
(三)Hive元数据管理
记录数据仓库中模型的定义、各层级间的映射关系
Hive存储在关系数据库中,默认的Hive默认数据库是Derby,轻量级内嵌SQL数据库,Derby非常适合测试和演示,存储在.metastore_db目录中,实际生产一般存储在MySql中,修改配置文件hive-site.xml。
HCatalog:将Hive元数据共享给其他应用程序。
hive的数据存储在hdfs上,Hive的select语句交给mapreduce来操作,减少写mapreduce的操作。
二、Hive环境搭建
1.自动安装脚本
(解压、修改文件名、配置环境变量)
#! /bin/bash
echo 'auto install begining...'
# global var
hive=true
if [ "$hive" = true ];then
echo 'hive install set true'
echo 'setup apache-hive-3.1.2-bin.tar.gz'
tar -zxf /opt/install/apache-hive-3.1.2-bin.tar.gz -C /opt/soft/
mv /opt/soft/apache-hive-3.1.2-bin /opt/soft/hive312
sed -i '73a\export PATH=$PATH:$HIVE_HOME/bin' /etc/profile
sed -i '73a\export HIVE_HOME=/opt/soft/hive312' /etc/profile
sed -i '73a\# HIVE_HOME' /etc/profile
echo 'setup hive success!!!'
fi
2./opt/soft/hive312/conf目录下创建hive配置文件hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/soft/hive312/warehouse</value>
<description></description>
</property>
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
<description></description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.180.141:3306/hive147?createDatabaseIfNotExist=true</value>
<description></description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description></description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description></description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description></description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>关闭schema验证</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>提示当前数据库名</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>查询输出时带列名一起输出</description>
</property>
</configuration>3.拷贝一个jar包到hive下面的lib目录下

4.删除hive的guava,拷贝hadoop下的guava
[root@lxm147 lib]# ls ./ | grep mysql-connector-java-8.0.29.jar
mysql-connector-java-8.0.29.jar
[root@lxm147 lib]# ls ./ | grep guava-19.0.jar
guava-19.0.jar
[root@lxm147 lib]# rm -f ./guava-19.0.jar
[root@lxm147 lib]# ls ./ | grep guava-19.0.jar
[root@lxm147 lib]# find /opt/soft/hadoop313/ -name guava*
/opt/soft/hadoop313/share/hadoop/common/lib/guava-27.0-jre.jar
/opt/soft/hadoop313/share/hadoop/hdfs/lib/guava-27.0-jre.jar
[root@lxm147 lib]# cp /opt/soft/hadoop313/share/hadoop/common/lib/guava-27.0-jre.jar ./
[root@lxm147 lib]# ls ./ | grep guava-27.0-jre.jar
guava-27.0-jre.jar
5.重启环境变量
source /etc/profile6.启动hadoop服务
start-dfs.sh
start-yarn.sh7.启动历史服务器
[root@lxm147 hive312]# mr-jobhistory-daemon.sh start historyserver
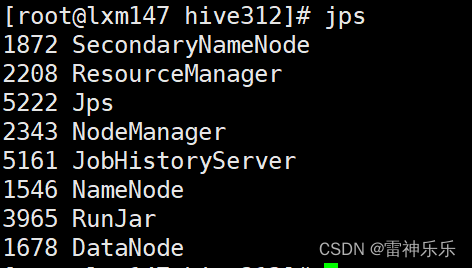
8.Hive初始化数据到mysql中
[root@lxm147 hive312]# schematool -dbType mysql -initSchema如果初始化出现错误,需要将mysql数据库中的hive147删除,然后hive再重新初始化