一、作者
Chen Zhang, Qiuchi Li, and Dawei Song. 2019. Syntax-Aware Aspect-Level Sentiment Classification with Proximity-Weighted Convolution Network. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’19). Association for Computing Machinery, New York, NY, USA, 1145–1148. https://doi.org/10.1145/3331184.3331351
二、背景
在方面级情感分析任务中,对方面及其上下文的语义相关性进行建模一直是一个巨大的挑战。
LSTM 与注意力机制和记忆网络的结合在一定程度上提高了对于方面和上下文之间的语义交互的建模能力,但这些方法往往会忽视句子中的句法关系,比如对于句子 Its size is ideal and the weight is acceptable.,传统的基于语义相关性方法很大可能会将 ideal 描述为 acceptable ,但从句法的角度分析,二者是没有直接联系的。同时,现有的句法分析往往聚焦于单词级别的分析,在处理短语组成的上下文时便会显得捉襟见肘。
三、创新点
为了解决上述局限性,作者提出了一个新的 ABSA 框架,该框架利用方面与其上下文之间的句法关系,基于 LSTM 在 N 元语法(n-gram)的级别上聚合特征。同时受位置机制(position mechanism)的启发,该框架利用邻近权重(proximity weight,上下文词与方面词的句法接近度)来确定上下文词在句子中的重要性。然后邻近权重会被集成到卷积网络中以捕获 N 元句法信息,称为邻近加权卷积网络(Proximity-Weighted Convolution Network)。最后,通过最大池化来选择最重要的特征进行预测。
四、具体实现
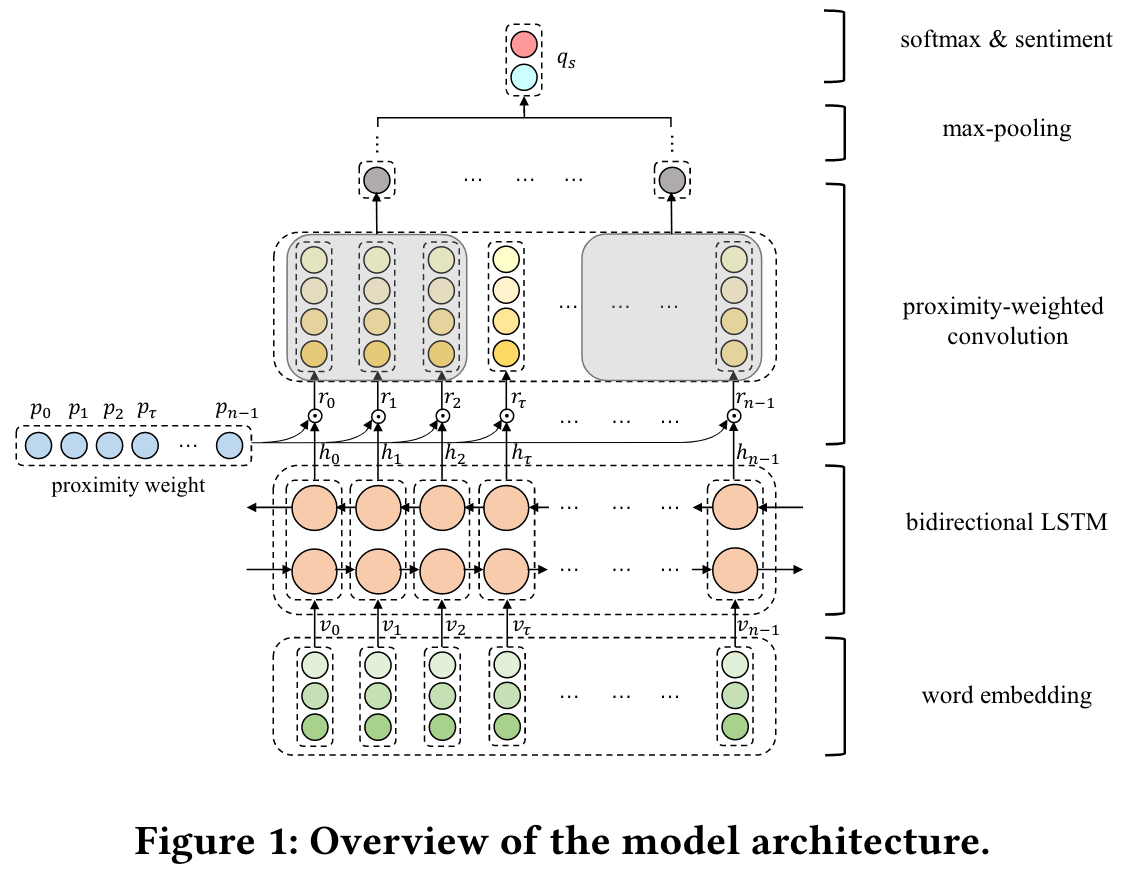
模型总体结构如上图所示。一个长度为 n 的句子可以表示为 S = { w 0 , w 1 , ⋯ , w τ , w τ + 1 , ⋯ , w τ + m − 1 , ⋯ , w n − 1 } \mathbf{S} = \{w_0, w_1, \cdots, w_\tau, w_{\tau + 1}, \cdots, w_{\tau + m - 1}, \cdots, w_{n - 1}\} S={w0,w1,⋯,wτ,wτ+1,⋯,wτ+m−1,⋯,wn−1},其中 τ \tau τ 代表方面术语的起始 token,然后通过词嵌入得到单词向量 V = { e 0 , ⋯ , e n − 1 } \mathbf{V} = \{e_0, \cdots, e_{n-1}\} V={e0,⋯,en−1},再通过双向LSTM得到隐藏状态向量 H = h 0 , ⋯ , h n − 1 \mathbf{H} = {h_0, \cdots, h_{n - 1}} H=h0,⋯,hn−1。
1.邻近权重
作者在模型中将句法依赖信息形式化为临近权重,用于描述上下文词与方面词之间的接近程度。依照此思路,作者通过位置邻近和依赖邻近,分别对上下文词和方面术语之间的句法依赖进行了建模。
a.位置邻近
位置邻近很容易理解,通常情况下,一个方面词的上下文词更可能在该方面词周围,因此作者将句子中的单词位置信息视为近似的句法邻近度量,位置邻近权重的计算公式如下:
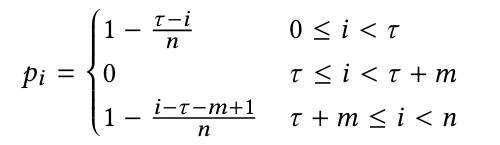
很显然,位置邻近权重会随着上下文词与方面词之间距离的增加而相应减少。
b.依赖邻近

依赖邻近基于句子的句法依存树。对于给定的句子,首先通过spaCy工具构建其句法依存树,然后计算每个单词与方面词之间的依存距离(即每个单词与方面词在依存树中的最短路径长度),对于多词方面短语,考虑对于对于方面边界的最短距离,而对于多句法树的情况,需要手动将其他句法树中的距离设定为句子长度的一半。该距离会被存储到 d = { d 0 , d 1 , ⋯ , d τ , d τ + 1 , ⋯ , d τ + m − 1 , ⋯ , d n − 1 } \mathbf{d} = \{d_0, d_1, \cdots, d_\tau, d_{\tau + 1}, \cdots, d_{\tau + m - 1}, \cdots, d_{n - 1}\} d={d0,d1,⋯,dτ,dτ+1,⋯,dτ+m−1,⋯,dn−1}中。最后,根据 d \mathbf{d} d 即可计算依赖邻近权重,计算过程如下:
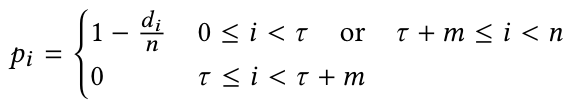
2.邻近加权卷积
邻近加权卷积的本质是在长度为 l 的卷积核上的一维卷积,同时会在卷积计算之前分配邻近权重,从而得到的句子中第 i 个词的邻近加权表示 r i = p i h i r_i = p_ih_i ri=pihi。此外,作者还对句子进行了零填充以确保卷积操作输入的句子和输出的句子具有相同的长度。
卷积操作可以表示为 q i = max ( W c ⊤ [ r i − t ⊕ ⋯ ⊕ r i ⊕ ⋯ ⊕ r i + t ] + b c , 0 ) q_{i}=\max \left(\mathbf{W}_{c}^{\top}\left[r_{i-t} \oplus \cdots \oplus r_{i} \oplus \cdots \oplus r_{i+t}\right]+b_{c}, 0\right) qi=max(Wc⊤[ri−t⊕⋯⊕ri⊕⋯⊕ri+t]+bc,0),其中 t = ⌊ l 2 ⌋ t = \lfloor \frac{l}{2} \rfloor t=⌊2l⌋, W c \mathbf{W}_{c} Wc 和 b c b_c bc 分别为为卷积核的权重和偏置。由于只有少数卷积层的输出特征对分类有指导意义,因此还要通过最大池化来获最显著的特征 q s q_s qs。最后 q s q_s qs会被送到全连接层,通过 softmax 归一化以获得情感极性的分布。
模型的训练采用标准的梯度下降算法,采用交叉熵损失函数以及 L 2 L_2 L2 正则化。
五、实验
作者采用了 Laptop(Pontiki et al., 2014)和 Restaurant(Pontiki et al., 2014)两个数据集作为实验数据集。
作者对 PWCN-Pos(位置邻近的 PWCN)和 PWCN-Dep(依赖邻近的 PWCN)分别进行了实验,对比的模型除了 LSTM、RAM、IAN和TNet-LF以外,还包括两个模型变体 Att-PWCN-Pos(邻近权重会乘以归一化后的注意力权重,用来验证句法依赖与语义相关性是否可以相互结合)和 Point-PWCN-Pos(l 元语法被转化为一元语法以验证 N 元语法的有效性)。
作者对三次随机初始化后的实验结果进行了平均,最终的结果如下图所示:

实验结果也表明句法依赖方法的效果优于语义相关性的方法。