什么是循环依赖 ?
一个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成一个环形调用,有下面 3 种方式。
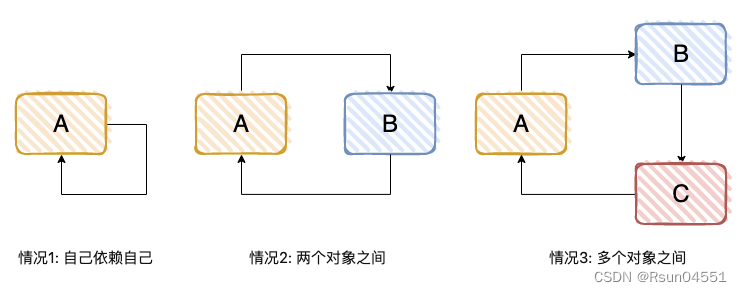
我们看一个简单的 Demo,对标“情况 2”。
@Service
public class Louzai1 {
@Autowired
private Louzai2 louzai2;
public void test1() {
}
}
@Service
public class Louzai2 {
@Autowired
private Louzai1 louzai1;
public void test2() {
}
}
这是一个经典的循环依赖,它能正常运行,后面我们会通过源码的角度,解读整体的执行流程。
三级缓存
解读源码流程之前,spring 内部的三级缓存逻辑必须了解,要不然后面看代码会蒙圈。
第一级缓存:singletonObjects,用于保存实例化、注入、初始化完成的 bean 实例;
第二级缓存:earlySingletonObjects,用于保存实例化完成的 bean 实例;
第三级缓存:singletonFactories,用于保存 bean 创建工厂,以便后面有机会创建代理对象。
这是最核心,我们直接上源码:
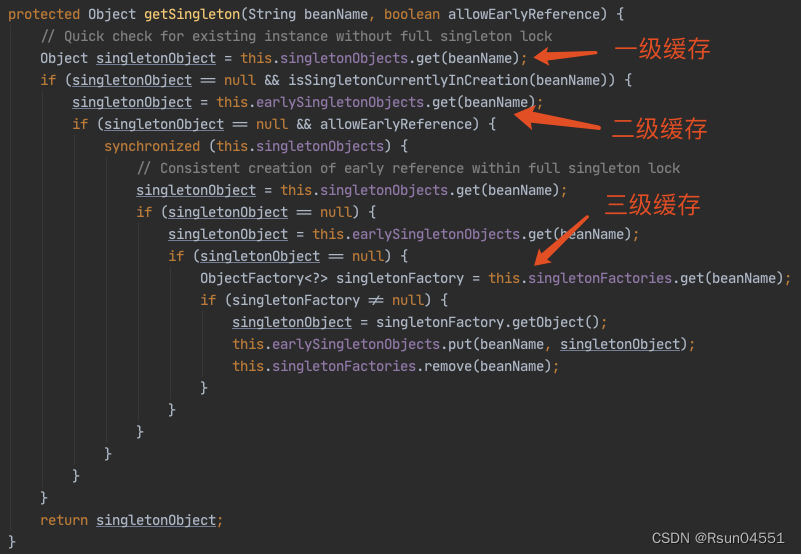
执行逻辑:
先从“第一级缓存”找对象,有就返回,没有就找“二级缓存”;
找“二级缓存”,有就返回,没有就找“三级缓存”;
找“三级缓存”,找到了,就获取对象,放到“二级缓存”,从“三级缓存”移除。
原理执行流程
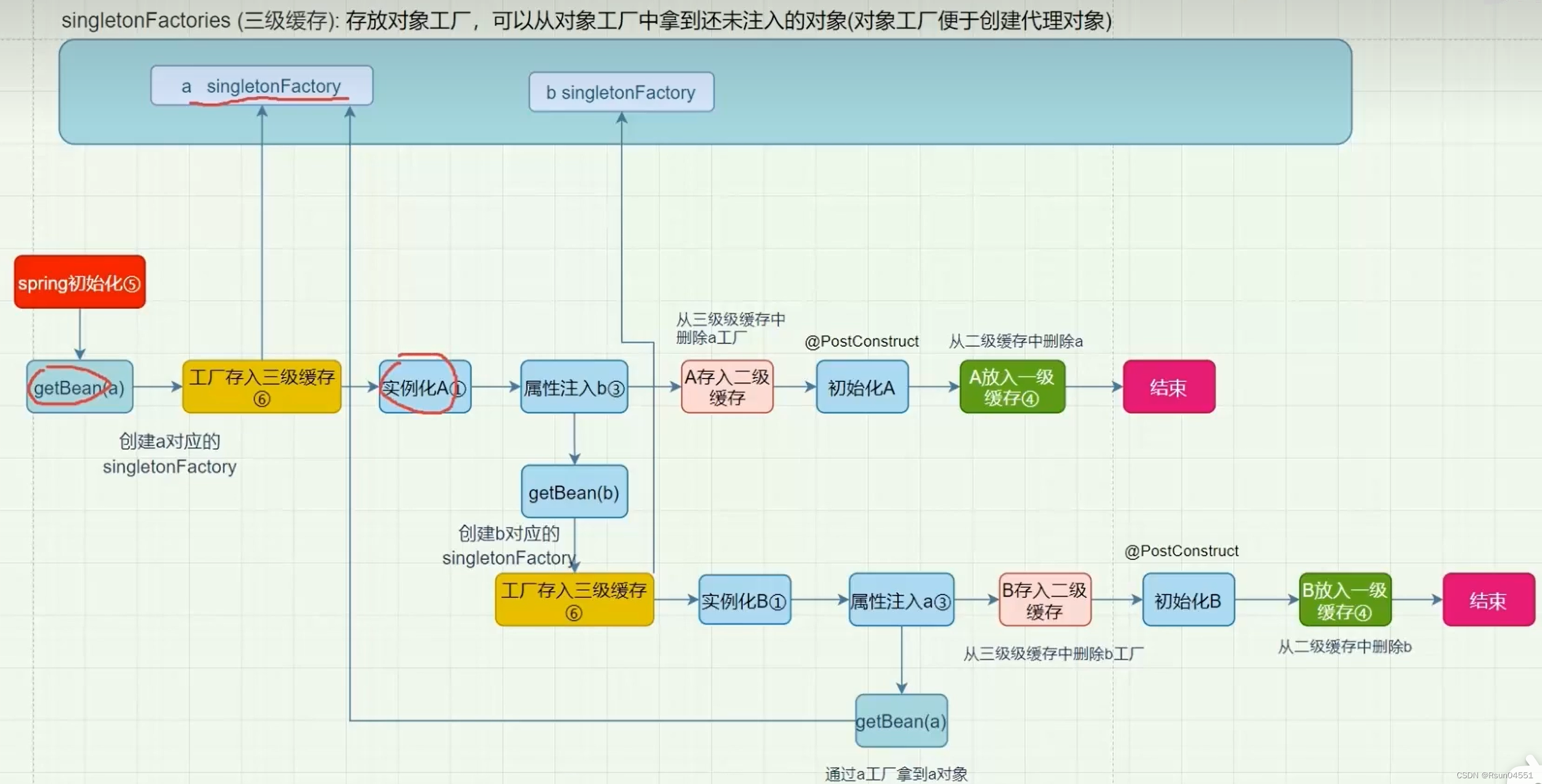
我把“情况 2”执行的流程分解为下面 3 步,是不是和“套娃”很像 ?
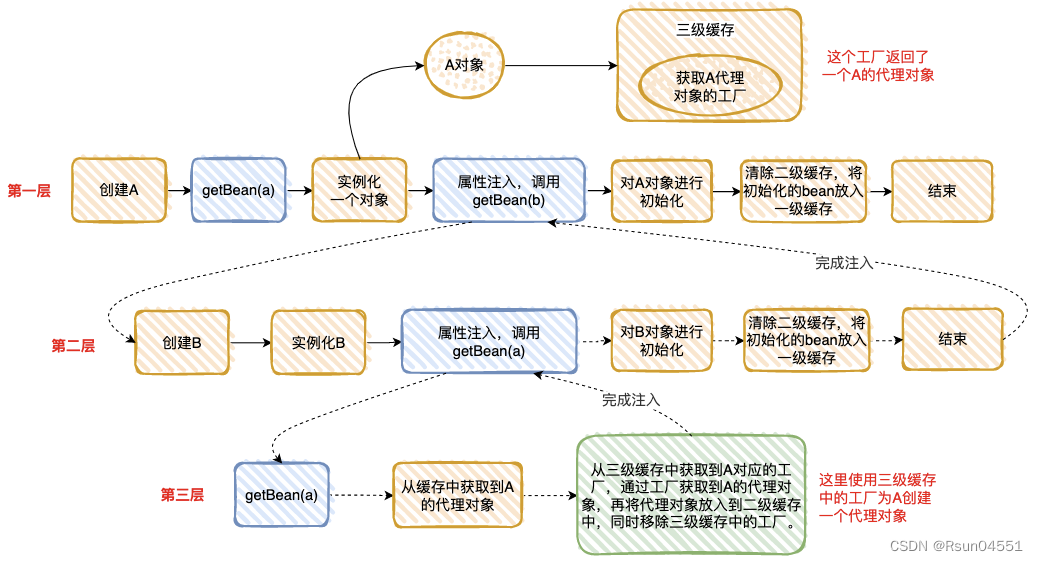
整个执行逻辑如下:
1、在第一层中,先去获取 A 的 Bean,发现没有就准备去创建一个,然后将 A 的代理工厂放入“三级缓存”(这个 A 其实是一个半成品,还没有对里面的属性进行注入),但是 A 依赖 B 的创建,就必须先去创建 B;
2、在第二层中,准备创建 B,发现 B 又依赖 A,需要先去创建 A;
3、在第三层中,去创建 A,因为第一层已经创建了 A 的代理工厂,直接从“三级缓存”中拿到 A 的代理工厂,获取 A 的代理对象,放入“二级缓存”,并清除“三级缓存”;
4、回到第二层,现在有了 A 的代理对象,对 A 的依赖完美解决(这里的 A 仍然是个半成品),B 初始化成功;
5、回到第一层,现在 B 初始化成功,完成 A 对象的属性注入,然后再填充 A 的其它属性,以及 A 的其它步骤(包括 AOP),完成对 A 完整的初始化功能(这里的 A 才是完整的 Bean)。
6、将 A 放入“一级缓存”。
Spring Bean的生命周期
getBean(a)–>实例化A–>属性注入–>初始化A–>销毁
三级缓存的作用:
singletonObjects(一级缓存):存放实例化–>代理–>属性注入–>初始化后的对象
earlySingletonObjects(二级缓存):存放实例化–>代理–>属性注入后的对象
singletonFactories(三级缓存):存放对象工厂,可以从对象工厂中拿到还未属性注入的对象(对象工厂便于创建代理对象)
当未添加三级缓存时候:
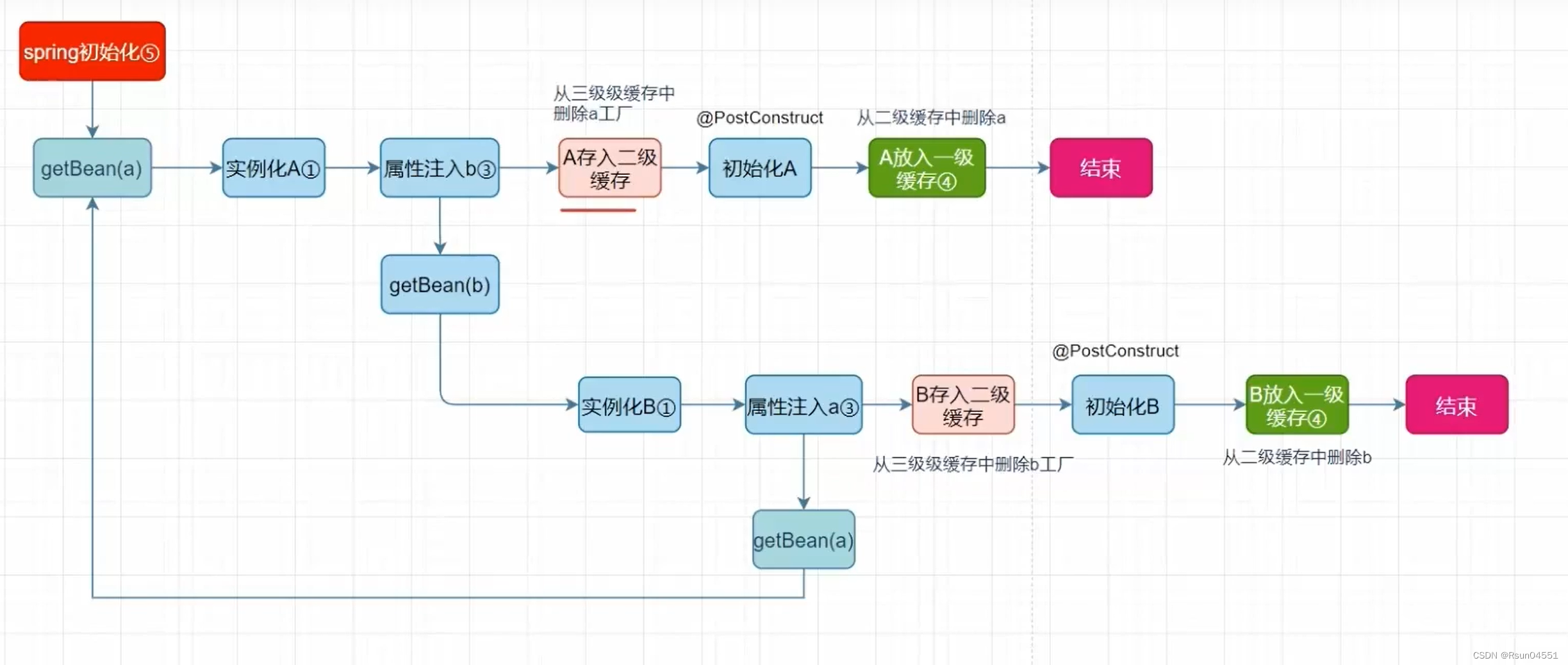
当加入三级缓存后: