本文目录
- 一、 Series
- 1. 将列表强转为Series
- 2. 将字典强转为Series
- 3. 访问Series中的数据
- 3.1 第一套检索方法
- 3.2 第二套检索方法
- 4. Series常用属性
- 二、Pandas日期类型数据处理
- 1. 将字符串转为datetime类型
- 2. 与1等价的方式
- 3. 单独取出年月日
- 4. 日期运算
- 5. 生成一组日期
- 6. 生成工作日(跳过周六周末)
- 三、DataFrame的核心操作
- 1. 创建新的DataFrame
- 1.1 通过列表创建DataFrame
- 1.2 通过列表套字典来创建DataFrame
- 1.3 通过字典套列表来创建DataFrame(常用)
- 1.4 通过字典套Series来创建DataFrame(更常用)
- 1.5 通过字典套series并指定标签的方式来创建DataFrame(更更常用)
- 2. DataFrame的常用属性
- 3. 列级操作——CURD 增删改查
- 3.1 列访问 对象[列名]
- 3.2 列添加
- 3.3 列删除
- (1)删除一列
- (2)删除多列
- 4. 行级操作——CURD 增删改查
- 4.1 行访问(iloc, loc)
- 4.2 行添加 (append)
- 4.3 行的删除(drop)
- 4.4 行和列的修改
- 四、 数据加载
- 1.csv
- 1.1 read_csv(可以读文本文件,包括txt)
- 1.2 to_csv
- 2. json
- 2.1 read_json
- 2.2 to_json
- 五、数据指标
- 1.均值
- 1.1 3种方法求均值
- 1.2 案例:通过csv文件求某列均值
- 1.3 加权平均值
- 2. 最值
- 3.中位数
- 4.标准差
数据结构是计算机存储、组织数据的方式通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率数据结构往往同高效的检索算法和索引技术有关。
Pandas的数据结构只有两种,Series和DataFrame
Series:带索引的一维数组
DataFrame: 带索引的二维数组
一、 Series
Series可以理解为一个一维的数组,只是index名称可以自己改动。类似于定长的有序字典,有Index和 value。
1. 将列表强转为Series
import numpy as np
import pandas as pd
data = [100, 90, 89, 98, 99]
# 创建一个新的Series
s = pd.Series(data)
print(s)
# 输出------------>
0 100
1 90
2 89
3 98
dtype: int64
输出 结果是一个
一维数组,而不是二维,虽然看起来像是二维
import pandas as pd
data = [100, 90, 89, 98]
# 创建一个新的Series
s = pd.Series(data, index=['zs', 'ls', 'ww', 'sl'])
print(s)
# 输出------------>
zs 100
ls 90
ww 89
sl 98
dtype: int64
这种输出格式就是Series
2. 将字典强转为Series
import pandas as pd
data = {'zs': 100, 'ls': 98, 'ww': 93}
# 创建一个新的Series
s = pd.Series(data)
print(s)
# 输出------------>
zs 100
ls 98
ww 93
dtype: int64
import pandas as pd
data = {'zs': 100, 'ls': 98, 'ww': 93}
# 创建一个新的Series
s = pd.Series(data, index=['zp', 'zm', 'zl'])
print(s)
# 输出------------>
zp NaN
zm NaN
zl NaN
dtype: float64
此s
只显示index所对应的值,又因为没有值,所以显示NaN
生成10个0.2
import pandas as pd
import numpy as np
s = pd.Series(0.2, index=range(10))
print(s)
# 输出------------>
0 0.2
1 0.2
2 0.2
3 0.2
4 0.2
5 0.2
6 0.2
7 0.2
8 0.2
9 0.2
dtype: float64
3. 访问Series中的数据
在Series中有
2套索引:位置索引,标签索引
series的切片为series
3.1 第一套检索方法
import pandas as pd
import numpy as np
data = {'zs': 100, 'ls': 98, 'ww': 93}
# 创建一个新的Series
s = pd.Series(data)
print(s)
print(s[0]) # 索引
print(s[0:2]) # 切片
print(s[[0, 2]]) # 标签掩码 只要第一个和第三个元素
# 输出
zs 100
ls 98
ww 93
dtype: int64
100
zs 100
ls 98
dtype: int64
zs 100
ww 93
dtype: int64
3.2 第二套检索方法
import pandas as pd
import numpy as np
data = {'zs': 100, 'ls': 98, 'ww': 93}
# 创建一个新的Series
s = pd.Series(data)
print(s)
print(s['zs']) # 索引
print(s['zs':'ww']) # 切片
print(s[['zs', 'ls']]) # 标签掩码 只要第一个和第三个元素
# 输出
zs 100
ls 98
ww 93
dtype: int64
100
zs 100
ls 98
ww 93
dtype: int64
zs 100
ls 98
dtype: int64
注意:使用标签检索进行切片包含最后一个元素,而索引检索不包括
4. Series常用属性
- s1.values所有的值返回一个ndarray
- sl.index所有的索引
- sl.dtype
- sl.size # 元素个数
- sl.ndim # 恒为1
- s1.shape
import pandas as pd
import numpy as np
data = {'zs': 100, 'ls': 98, 'ww': 93}
# 创建一个新的Series
s = pd.Series(data)
print(s.values)
print(s.index)
print(s.index[:2])
# 输出
[100 98 93]
Index(['zs', 'ls', 'ww'], dtype='object')
Index(['zs', 'ls'], dtype='object')
二、Pandas日期类型数据处理
1. 将字符串转为datetime类型
import pandas as pd
import numpy as np
dates = pd.Series(['2022', '2022-02', '2022-8-1', '2022/04/01', '2022/05/01 08:08:08', '01 Jun 2022', '20220701'])
dates = dates.astype('datetime64')
print(dates)
# 输出
0 2022-01-01 00:00:00
1 2022-02-01 00:00:00
2 2022-08-01 00:00:00
3 2022-04-01 00:00:00
4 2022-05-01 08:08:08
5 2022-06-01 00:00:00
6 2022-07-01 00:00:00
dtype: datetime64[ns]
2. 与1等价的方式
import pandas as pd
import numpy as np
dates = pd.Series(['2022', '2022-02', '2022-8-1', '2022/04/01', '2022/05/01 08:08:08', '01 Jun 2022', '20220701'])
dates = pd.to_datetime(dates)
print(dates)
# 输出
0 2022-01-01 00:00:00
1 2022-02-01 00:00:00
2 2022-08-01 00:00:00
3 2022-04-01 00:00:00
4 2022-05-01 08:08:08
5 2022-06-01 00:00:00
6 2022-07-01 00:00:00
dtype: datetime64[ns]
3. 单独取出年月日
import pandas as pd
import numpy as np
dates = pd.Series(['2022', '2022-02', '2022-8-1', '2022/04/01', '2022/05/01 08:08:08', '01 Jun 2022', '20220701'])
dates = pd.to_datetime(dates)
print(dates.dt.month) # 取出月
# 输出
0 1
1 2
2 8
3 4
4 5
5 6
6 7
dtype: int64


4. 日期运算
import pandas as pd
import numpy as np
dates = pd.Series(['2022', '2022-02', '2022-8-1', '2022/04/01', '2022/05/01 08:08:08', '01 Jun 2022', '20220701'])
dates = pd.to_datetime(dates)
dates = dates - pd.to_datetime('20220101')
print(dates.dt.days)
日期相减后
只能获得days,不能获得month,year
5. 生成一组日期
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 以日为频率
datelist = pd.date_range('2019/08/21', periods=5) # 频率默认为日
print(datelist)
# 以月为频率
datelist = pd.date_range('2019/08/21', periods=7, freq='M') # 频率默认为日
print(datelist)
# 构建某个区间的时间序列
start = pd.datetime(2017, 11, 1)
end = pd.datetime(2017, 11, 5)
dates = pd.date_range(start, end)
print(dates)
# 输出
DatetimeIndex(['2019-08-21', '2019-08-22', '2019-08-23', '2019-08-24',
'2019-08-25'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2019-08-31', '2019-09-30', '2019-10-31', '2019-11-30',
'2019-12-31', '2020-01-31', '2020-02-29'],
dtype='datetime64[ns]', freq='M')
DatetimeIndex(['2017-11-01', '2017-11-02', '2017-11-03', '2017-11-04',
'2017-11-05'],
dtype='datetime64[ns]', freq='D')
以月为频率,生成每个月的最后一天
6. 生成工作日(跳过周六周末)
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 以日为频率
datelist = pd.date_range('2019/08/21', periods=5, freq='B') # 频率默认为日
print(datelist)
# 输出
DatetimeIndex(['2019-08-21', '2019-08-22', '2019-08-23', '2019-08-26',
'2019-08-27'],
dtype='datetime64[ns]', freq='B')
三、DataFrame的核心操作
DataFrame是一个类似于表格(有行有列)的数据类型,可以理解为一个二维数组,索引有两个维度(行级索引,列级索引),可更改。DataFrame具有以下特点
- 列和列之间可以是不同的类型:不同的列的数据类型可以不同
- 大小可变 (扩容)
- 标记轴(行级索引和列级索引)
- 针对行与列进行轴向统计(水平,垂直)
1. 创建新的DataFrame
1.1 通过列表创建DataFrame
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = [1, 2, 3, 4, 5]
df = pd.DataFrame(data)
print(df)
# 通过2维列表创建DataFrame
data = [['zs', 18], ['ls', 29], ['ww', 38]]
df = pd.DataFrame(data)
print(df)
# 在2维列表上加上索引来创建DataFrame
data = [['zs', 18], ['ls', 29], ['ww', 38]]
df = pd.DataFrame(data, index=['s1', 's2', 's3'], columns=['name', 'age'])
print(df)
# 输出
0
0 1
1 2
2 3
3 4
4 5
0 1
0 zs 18
1 ls 29
2 ww 38
name age
s1 zs 18
s2 ls 29
s3 ww 38
1.2 通过列表套字典来创建DataFrame
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = [1, 2, 3, 4, 5]
df = pd.DataFrame([{'name': 'zs', 'age': 18, 'sex': 1}, {'name': 'ww', 'age': 16}])
print(df)
# 输出
name age sex
0 zs 18 1.0
1 ww 16 NaN
1.3 通过字典套列表来创建DataFrame(常用)
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': ['Alex', 'Bob', 'Lena'], 'Age': [18, 20, 21]}
df = pd.DataFrame(data)
print(df)
缺点:不能设置行 标签了, 而且 列的长度不相等会报错
1.4 通过字典套Series来创建DataFrame(更常用)
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena']), 'Age': pd.Series([18, 20])}
df = pd.DataFrame(data)
print(df)
# 输出
Name Age
0 Alex 18.0
1 Bob 20.0
2 Lena NaN
好处:列长度可以不相等
缺点:不知道哪个样本缺数据,NaN不灵活
1.5 通过字典套series并指定标签的方式来创建DataFrame(更更常用)
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20], index=['s1', 's3'])}
df = pd.DataFrame(data)
print(df)
# 输出
Name Age
s1 Alex 18.0
s2 Bob NaN
s3 Lena 20.0
2. DataFrame的常用属性
- axes 返回行/列标签(index)列表。
- columns 返回列标签
- index 返回行标签
- dtypes 返回对象的数据类型(dtype)
- empty 如果系列为空,则返回True
- ndim 返回底层数据的维数,默认定义:2
- size 返回基础数据中的元素数
- values 将系列作为ndarray返回
- head(n) 返回前n行,默认返回5行
- tail(n) 返回最后n行
3. 列级操作——CURD 增删改查
3.1 列访问 对象[列名]
通过列访问 访问某一列
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3'])}
df = pd.DataFrame(data)
print(df)
# 访问1列
print(df["Name"])
# 访问前两列
print(df[df.columns[:2]])
# 输出
Name Age
s1 Alex 18
s2 Bob 20
s3 Lena 22
s1 Alex
s2 Bob
s3 Lena
Name: Name, dtype: object
Name Age
s1 Alex 18
s2 Bob 20
s3 Lena 22
列级索引
只有标签索引,没有位置索引,比如,不能为:df[0]
访问多列,不能切片(切片只能是行级数据),只能掩码
3.2 列添加
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
df = pd.DataFrame(data)
print(df)
df['class'] = ['c1', 'c1', 'c2']
print(df)
# 最好用series以解决列不等长的问题,如果列的值为Series时,需要给出原df的index,否则为NaN
df['class'] = pd.Series(['c1', 'c1', 'c2'])
print(df)
# 最好用series以解决列不等长的问题
df['class'] = pd.Series(['c1', 'c1', 'c2'], index=['s1', 's2', 's3'])
print(df)
# 输出
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s3 Lena 22 97
Name Age Score class
s1 Alex 18 99 c1
s2 Bob 20 98 c1
s3 Lena 22 97 c2
Name Age Score class
s1 Alex 18 99 NaN
s2 Bob 20 98 NaN
s3 Lena 22 97 NaN
Name Age Score class
s1 Alex 18 99 c1
s2 Bob 20 98 c1
s3 Lena 22 97 c2
如果列的值为Series时,需要给出原df的index
3.3 列删除
(1)删除一列
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
df = pd.DataFrame(data)
print(df)
# 删除一列
del(df['Name'])
print(df)
df.pop('Score')
print(df)
# 输出
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s3 Lena 22 97
Age Score
s1 18 99
s2 20 98
s3 22 97
Age
s1 18
s2 20
s3 22
(2)删除多列
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
df = pd.DataFrame(data)
print(df)
df2 = df.drop(['Age', 'Score'], axis=1)
print(df2)
删除多列 drop 轴向axis=1是必须给的默认axis=0删除行的不会修改原数据
inplace=False 默认不修改原数据
若要修改,改为inplace=True即可
4. 行级操作——CURD 增删改查
4.1 行访问(iloc, loc)
访问行直接位置索引切片(访问一行数据时,不能使用位置索引,如df[1],也不能使用标签索引,如df[‘Name’](因为这是列索引的方法),所以只能使用位置索引切片)
访问列直接标签索引切片:列数据不能位置索引切片,只能标签掩码索引
以后取行数据都直接使用loc(标签索引)方法和iloc(位置索引),为了避免列数据不能位置索引,行数据不能标签索引让人混淆,Panda提供了loc和iloc方法取行数据和列数据。
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
df = pd.DataFrame(data)
print(df)
print(df.loc['s2'])
print(df.iloc[1:])
# 掩码索引
print(df.loc[['s1', 's2']])
print(df.iloc[[0, 1]])
# 输出
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s3 Lena 22 97
Name Bob
Age 20
Score 98
Name: s2, dtype: object
Name Age Score
s2 Bob 20 98
s3 Lena 22 97
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
df = pd.DataFrame(data)
print(df)
# 取所有行不要最后一列
print(df.iloc[:, :-1])
# 取所有行只要最后一列
print(df.iloc[:, -1])
# 输出
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s3 Lena 22 97
Name Age
s1 Alex 18
s2 Bob 20
s3 Lena 22
s1 99
s2 98
s3 97
Name: Score, dtype: int64
4.2 行添加 (append)
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data1 = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
data2 = {'Name': pd.Series(['zs', 'ls', 'ww'], index=['s4', 's5', 's6']), 'Age': pd.Series([17, 23, 21], index=['s4', 's5', 's6']), 'Score': pd.Series([100, 92, 95], index=['s4', 's5', 's6'])}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# print(df1)
# print(df2)
df1 = df1.append(df2)
print(df1)
# 输出
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s3 Lena 22 97
s4 zs 17 100
s5 ls 23 92
s6 ww 21 95
4.3 行的删除(drop)
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 通过列表创建DataFrame
data1 = {'Name': pd.Series(['Alex', 'Bob', 'Lena'], index=['s1', 's2', 's3']), 'Age': pd.Series([18, 20, 22], index=['s1', 's2', 's3']), 'Score': pd.Series([99, 98, 97], index=['s1', 's2', 's3'])}
data2 = {'Name': pd.Series(['zs', 'ls', 'ww'], index=['s4', 's5', 's6']), 'Age': pd.Series([17, 23, 21], index=['s4', 's5', 's6']), 'Score': pd.Series([100, 92, 95], index=['s4', 's5', 's6'])}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# print(df1)
# print(df2)
df1 = df1.append(df2)
print(df1)
df1 = df1.drop(['s3', 's4'], axis=0)
print(df1)
# 输出
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s3 Lena 22 97
s4 zs 17 100
s5 ls 23 92
s6 ww 21 95
Name Age Score
s1 Alex 18 99
s2 Bob 20 98
s5 ls 23 92
s6 ww 21 95
4.4 行和列的修改
通过列找行进行修改
通过行找列进行修改(此种方法不可行,底层没有赋值过程)

四、 数据加载
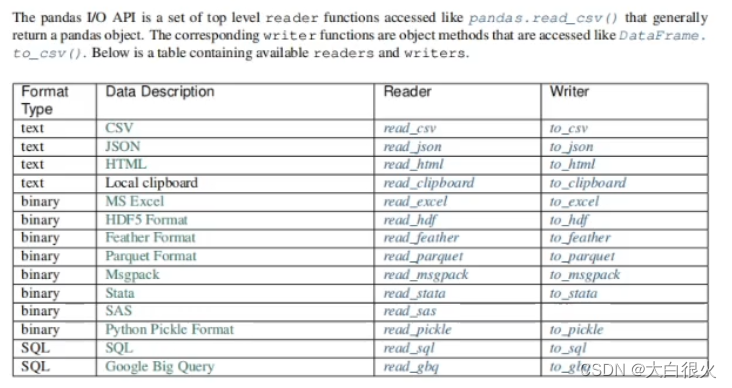
1.csv
1.1 read_csv(可以读文本文件,包括txt)
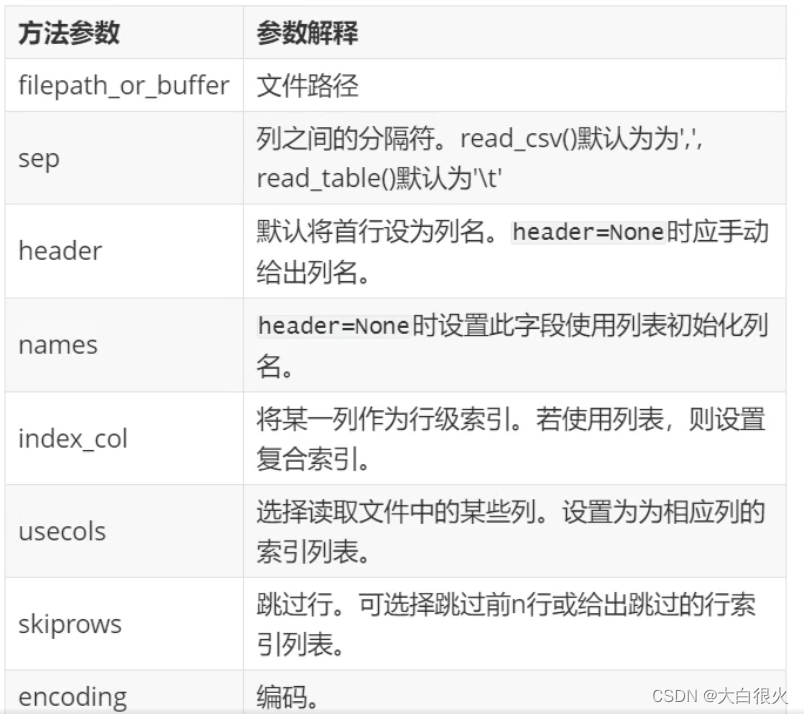
import pandas as pd
import warnings
data = pd.read_csv('data1.csv')
print(data)
1.2 to_csv
2. json
2.1 read_json

import pandas as pd
import warnings
data = pd.read_json("test1.py", encoding='utf-8')
2.2 to_json
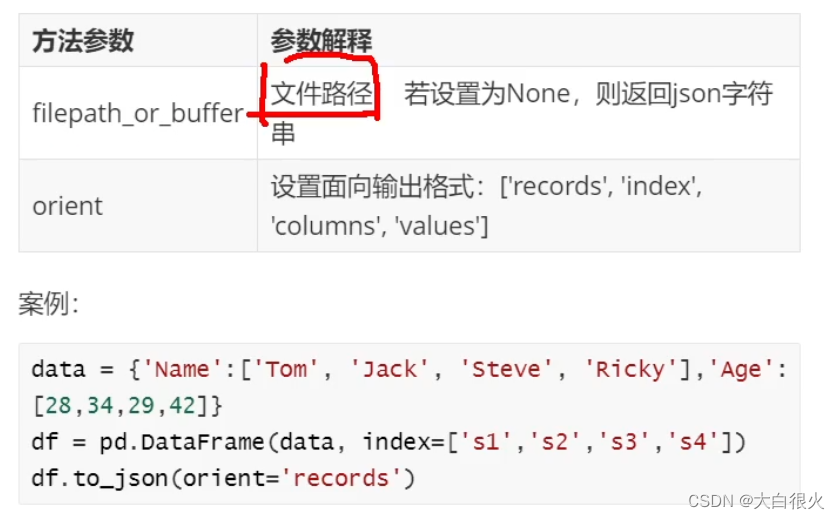
import pandas as pd
import warnings
data = {'Name': ['Tom', 'Jack', 'Steve', 'Ricky'], 'Age': [28, 27, 32, 20]}
df = pd.DataFrame(data, index=['s1', 's2', 's3', 's4'])
print(df)
# records: 每行数据生成一个字典
res = df.to_json(orient='records')
print(res)
# index: 行索引作为键
res = df.to_json(orient='index')
print(res)
# columns: 列索引作为键
res = df.to_json(orient='columns')
print(res)
# values: 只保存值
res = df.to_json(orient='values')
print(res)
# 输出
Name Age
s1 Tom 28
s2 Jack 27
s3 Steve 32
s4 Ricky 20
[{"Name":"Tom","Age":28},{"Name":"Jack","Age":27},{"Name":"Steve","Age":32},{"Name":"Ricky","Age":20}]
{"s1":{"Name":"Tom","Age":28},"s2":{"Name":"Jack","Age":27},"s3":{"Name":"Steve","Age":32},"s4":{"Name":"Ricky","Age":20}}
{"Name":{"s1":"Tom","s2":"Jack","s3":"Steve","s4":"Ricky"},"Age":{"s1":28,"s2":27,"s3":32,"s4":20}}
[["Tom",28],["Jack",27],["Steve",32],["Ricky",20]]
orient参数
records:一行数据对应一个字典
index: 行索引作为键
columns: 列索引作为键
‘values’:只保存值
更多参见:https://www.pypandas.cn/docs/user_guide/io.html
五、数据指标
1.均值
1.1 3种方法求均值
import pandas as pd
import numpy as np
import warnings
data = [1, 2, 3, 4, 5, 6]
ard = np.array(data)
m1 = ard.mean()
print(m1)
m2 = np.mean(data)
print(m2)
m3 = pd.Series(data).mean(axis=0)
print(m3)
# 输出
3.5
3.5
3.5
1.2 案例:通过csv文件求某列均值
data.csv数据
1,1,792.83,-10.45,0,0,0,0,25,0
2,1,121.67,-21.14,0,0,0,0,25,0
3,1,-55.66,,0,0,0,0,2,1
4,1,241.5,-288.34,0,1,0,1,25,0
5,1,1629.67,-23.66,0,0,0,1,25,0
6,1,182,-115.86,0,1,0,1,25,0
7,1,196.33,221.29,0,1,0,1,23,0
8,1,539.5,81.16,0,1,0,0,25,0
9,1,1037.17,8.34,0,1,0,1,25,0
10,2,289,-131.78,0,0,0,1,25,0
11,1,1541.8,-136.39,0,1,0,0,12,1
12,1,90,-27.69,0,1,0,0,2,1
13,1,407.5,112.79,0,1,0,1,25,0
14,1,157.83,45.26,1,1,0,0,25,0
15,2,-307.17,-356.35,0,0,0,1,25,0
python代码
import pandas as pd
import numpy as np
data = pd.read_csv("data.csv", header=None, names=['s' + str(i) for i in range(9)])
print(data)
print(data['s7'].mean())
1.3 加权平均值
语法:
a=np.average(array, weights=volumns)
import pandas as pd
import numpy as np
import warnings
data = pd.read_csv("data1.csv", header=None, names=['s' + str(i) for i in range(9)])
print(data)
s = data.iloc[:8, 7]
print(s)
print(np.average(s, weights=[1, 8, 1, 8, 1, 1, 1, 1]))
2. 最值
np.max()
np.min()
np.argmax() 返回一个数组中最大元素的下标
np.argmin():返回一个数组中最小元素的下标
在np中,使用argmax获取到最大值的下标
print(np.argmax(a),np.argmin(a))
在pandas中,使用idxmax获取到最大值的下标
print(series,idxmax(),series.idxmin())
print(dataframe.idxmax(),dataframe.idxmin())
3.中位数
先对样本进行排序,取中间位置的元素
若样本数量为偶数,中位数为最中间的两个元素平均值
若样本数量为奇数,中位数为最中间的元素
np.median(obj)
4.标准差
obj.std()
import pandas as pd
import numpy as np
import warnings
data = pd.read_csv("data1.csv", header=None, names=['s' + str(i) for i in range(9)])
#
s = data.iloc[:8, 7]
print(s.std()) # 样本方差
print(np.std(s))
print(np.std(s, ddof=1)) # numpy默认是总体方差
# 输出
8.061150219239366
7.540515565927836
8.061150219239366