本文介绍如何使用u版的yolov5 模型转成 onnx模型,使用python代码推理onnx模型,然后再使用c++代码推理onnx模型,本文使用yolov5 s版本,在m,l,x都试过可行
环境配置 :
1 u版的yolov5 4.0 版本,其他版本没有试过 https://github.com/ultralytics/yolov5
2 opencv 4.3 3.4.8 都可以,pytorch版本1.7
3 onnx 版本采用1.8.0,onnxruntime 采用 1.6.0
4 系统版本: ubuntu 20.04
pytorch模型转成onnx模型:
1 训练好pytorch模型后,进行pytorch模型到onnx模型的转换,进入yolov5主目录的models目录,修改export.py文件,修改54行左右的内容,将model.model[-1].export = True 改为 model.model[-1].export = False 即可
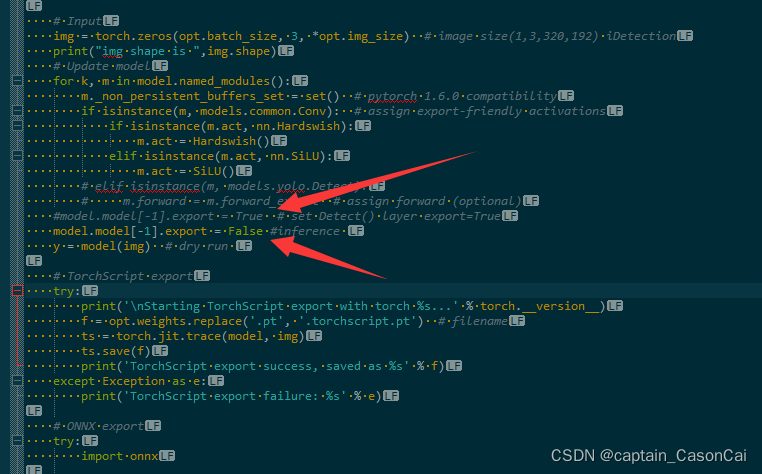
修改完毕后即可导出onnx模型,返回上级yolov5主目录 执行 python models/export.py
onnxruntime c++推理模型
1 c++推理onnx模型所需要的库则是windows版本的onnxruntime库,推理的过程其实就是把python推理onnx模型的过程用c++实现一遍,,这里说明是nms用的是opencv自带的,没有进行加权,而且是用的cpu推理 的。
2.1 步骤主要分为 三步 ,1是初始化模型 2是填充数据进入onnx的输入tensor 3是推理后进行后处理获取输出
2.2 初始化模型,主要是设置好onnx运行时的属性配置,然后载入路径初始化模型,另外还可以进行对模型warm up
/**
初始化模型
* @brief Detector::initModel
* @param model_path //模型路径
* @param class_num //类别数目
* @param conf_thres //分数阈值
* @param iou_thres //iou阈值
* @param input_size // 模型输入的尺寸
*/
void Detector::initModel(std::string &model_path, int class_num,float conf_thres,float iou_thres, std::tuple<int, int, int> &input_size) {
m_classNum = class_num;
m_confThres = conf_thres;
m_iouThres = iou_thres;
m_inputSize = input_size;
#ifdef _WIN32
std::cout<<"is _WIN32 "<<std::endl;
#else
//const char* model_path = "best_640x480.onnx";
const char* modelPath_s = model_path.c_str();
std::cout<<"not _WIN32 "<<std::endl;
#endif
std::cout<<"initModel !!! "<<std::endl;
// initialize enviroment...one enviroment per process
// enviroment maintains thread pools and other state info
//Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "test");
m_env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "test");//创建onnxruntime运行环境
// initialize session options if needed
Ort::SessionOptions session_options;//创建会话设置选项
session_options.SetIntraOpNumThreads(1);//设置运行线程数
session_options.SetInterOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);//设置会话属性
std::cout<<"initModel 2!!! "<<std::endl;
m_session = Ort::Session(m_env, String2WideString(model_path).c_str(), session_options);//创建会话
//配置输入节点
// print model input layer (node names, types, shape etc.)
Ort::AllocatorWithDefaultOptions allocator;
std::cout<<"initModel 1!!! "<<std::endl;
// print number of model input nodes
//size_t num_input_nodes = m_session->GetInputCount();//yolov5 just one input
size_t num_input_nodes = m_session.GetInputCount();//yolov5 just one input
std::cout<<"initModel 0!!! "<<std::endl;
//printf("Number of inputs = %zu\n", num_input_nodes);
m_input_node_names.resize(num_input_nodes);
//std::vector<int64_t> input_node_dims; // simplify... this model has only 1 input node {1, 3, 224, 224}.
// Otherwise need vector<vector<>>
std::cout<<"num_input_nodes = "<<num_input_nodes<<std::endl;
// iterate over all input nodes
for (int i = 0; i < num_input_nodes; i++) {
//char* input_name = m_session->GetInputName(i, allocator);
char* input_name = m_session.GetInputName(i, allocator);
m_input_node_names[i] = input_name;
//Ort::TypeInfo type_info = m_session->GetInputTypeInfo(i);
Ort::TypeInfo type_info = m_session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
// print input shapes/dims
m_input_node_dims = tensor_info.GetShape();
}
//配置输出节点
m_output_node_names.push_back("output");
//下面进行warm up,创建一个输入tensor跑一遍网络进行warm up
//创建一个矩阵数据,尺寸是模型输入尺寸
cv::Mat imgRGBFLoat(std::get<1>(m_inputSize),std::get<0>(m_inputSize),CV_32FC3);
//下面进行
//图像预处理
cv::Mat preprocessedImage;
cv::dnn::blobFromImage(imgRGBFLoat, preprocessedImage);//HWC->CHW
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
//创建输入tensor
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info,reinterpret_cast<float*>(preprocessedImage.data),
std::get<0>(m_inputSize)*std::get<1>(m_inputSize)*std::get<2>(m_inputSize),
m_input_node_dims.data(), 4);
//auto output_tensors = m_session->Run(Ort::RunOptions{nullptr}, m_input_node_names.data(), &input_tensor, 1, m_output_node_names.data(), 1);
auto output_tensors = m_session.Run(Ort::RunOptions{nullptr}, m_input_node_names.data(), &input_tensor, 1, m_output_node_names.data(), 1);
//auto output_tensors2= m_session2.Run(Ort::RunOptions{nullptr}, m_input_node_names.data(), &input_tensor, 1, m_output_node_names.data(), 1);
std::get<0>( m_input_w_h) = std::get<0>(m_inputSize);
std::get<1>( m_input_w_h) = std::get<1>(m_inputSize);
std::cout<<"init success !!!"<<std::endl;
}2.3 对输入进的图片先进行尺寸的修改,然后进行归一化填充到输入tensor,最后进行推理获取输出。
/**
* 获取并组织相应格式的输出
* @param inputImg
* @return
*/
std::vector<std::vector<det_box>> Detector::getOutput(cv::Mat &inputImg) {
//auto input_w_h = std::tuple<int,int>(std::get<0>(m_inputSize),std::get<1>(m_inputSize));
//对输入的图片进行按最长边比例缩放,然后填充短边至模型所需要的输入
cv::Mat resized = letterbox_image_v2(inputImg,m_input_w_h);
cv::cvtColor(resized,resized,cv::COLOR_BGR2RGB);
//cv::imwrite("resized.jpg",resized);
//std::cout<<"getOutput 1"<<std::endl;
cv::Mat imgRGBFLoat;
//std::cout<<"getOutput 2"<<std::endl;
//图片类型进行转换,然后除以255进行归一化
resized.convertTo(imgRGBFLoat,CV_32F, 1.0 / 255);//preprocess
//图片填充到opencv的blob然后进行通道变换
cv::Mat preprocessedImage;
cv::dnn::blobFromImage(imgRGBFLoat, preprocessedImage);//HWC->CHW
//std::cout<<"getOutput 3"<<std::endl;
// create input tensor object from data values
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
/* Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4); */
//图片数据填充进输入的tensor
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info,reinterpret_cast<float*>(preprocessedImage.data),
std::get<0>(m_inputSize)*std::get<1>(m_inputSize)*std::get<2>(m_inputSize),
m_input_node_dims.data(), 4);
//std::cout<<"getOutput 5"<<std::endl;
// score model & input tensor, get back output tensor
/* auto output_tensors = session.Run(Ort::RunOptions{nullptr}, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1); */
//auto output_tensors = m_session->Run(Ort::RunOptions{nullptr}, m_input_node_names.data(), &input_tensor, 1, m_output_node_names.data(), 1);
//执行推理获取输出的tensor
auto output_tensors = m_session.Run(Ort::RunOptions{nullptr}, m_input_node_names.data(), &input_tensor, 1, m_output_node_names.data(), 1);
std::cout<<"GetInputCount "<< m_session.GetInputCount()<<std::endl;
//std::cout<<"getOutput 6"<<std::endl;
// for(int i = 0; i<100;i++){
// auto output_tensors2 = m_session->Run(Ort::RunOptions{nullptr}, m_input_node_names.data(), &input_tensor, 1, m_output_node_names.data(), 1);
// }
//printf("Number 222 \n");
//get the output and format boxes
//对输出tensor进行后处理获取所需要的格式数据
std::vector<std::vector<det_box>> det_boxes = non_max_suppression_onnx(output_tensors[0], m_confThres,m_iouThres, m_classNum);
//std::cout<<"getOutput 7"<<std::endl;
return det_boxes;
//return std::vector<std::vector<det_box>>();
}
2.3 推理后得到输出的tensor,对输出的tensor进行后处理,主要是进行nms操作,这里的用到的是opencv自带的nms,另外里面用到的是iou,想改进可以考虑giou,ciou等。
/**
* 非极大值抑制算法
* @param input_tensor 神经网络的输出
* @param conf_thres 置信度
* @param iou_thres 交叠阈值
* @param class_num 类别
* @return
*/
inline std::vector<std::vector<det_box>> non_max_suppression_onnx(Ort::Value & input_tensor,float conf_thres = 0.25,float iou_thres = 0.45,int class_num = 1){
//下面进行nms,根据官方的做法来的,对于不同的类,对其坐标进行4096的偏移,比如第二类的,则对其坐标进行x+4096*1,y+4096*1的偏移,这样就不用对于每个类的目标进行nms,可以一次性到位
int min_wh =2,max_wh = 4096;
int max_det = 300,max_nms = 30000;
//float time_limit = 10.0;
//bool redundant = true;
bool multi_label = false;
if(class_num >= 1){
multi_label = true;
}
//获取模型输出tensor的数据指针
const float * prob = input_tensor.GetTensorData<float>();//tensor
//获取目标数量,这里先获取输出tensor的元素数量,然后除以每个目标数据的长度就是目标数量,目标数据的长度是上面说的4+1+class_num
int obj_count = input_tensor.GetTensorTypeAndShapeInfo().GetElementCount()/(class_num+5);
//下面的这些数据容器用于opencv的nms操作
std::vector<cv::Rect> boxes_vec; //目标框坐标
std::vector<int> clsIdx_vec;//目标框类别索引
std::vector<float> scores_vec;//目标框得分索引
std::vector<int>boxIdx_vec; //目标框的序号索引
//std::cout<<"obj_count is "<<obj_count<<std::endl;
//根据目标框数量遍历,根据分数进行过滤
for(int i = 0; i < obj_count ;i++){
if(*(prob+i*(5+class_num)+4) < conf_thres )
continue;
if(multi_label){
for(int cls_idx = 0;cls_idx<class_num;cls_idx++){
float x1 = *(prob+i*(5+class_num)) - *(prob+i*(5+class_num)+2)/2;
float y1 = *(prob+i*(5+class_num)+1) - *(prob+i*(5+class_num)+3)/2;
float x2 = *(prob+i*(5+class_num)) + *(prob+i*(5+class_num)+2)/2;
float y2 = *(prob+i*(5+class_num)+1) + *(prob+i*(5+class_num)+3)/2;
// mix_conf = obj_conf * cls_conf > conf_thres
//这里是官方的目标置信度*类别概率
float mix_conf = (*(prob+i*(5+class_num)+4)) * (*(prob+i*(5+class_num)+5+cls_idx));
if( mix_conf >conf_thres ){
boxes_vec.push_back(cv::Rect(x1+cls_idx*max_wh,
y1+cls_idx*max_wh,
x2 - x1,
y2 - y1)
);
//scores_vec.push_back((*(prob+i*(5+class_num)+4)));
scores_vec.push_back(mix_conf);
//std::cout<<"score "<<(*(prob+i*(5+class_num)+5+cls_idx))<<std::endl;
clsIdx_vec.push_back(cls_idx);
//cv::Rect
}
}
}else{
}
}//obj_count
//下面进行nms,结果是以索引的方式放在boxIdx_vec,根据索引就可以获取符合标准的目标框
cv::dnn::NMSBoxes(boxes_vec, scores_vec, 0.0f, iou_thres, boxIdx_vec);
std::vector<std::vector<det_box>> det_boxes;
det_boxes.resize(class_num);
for(int i = 0; i < boxIdx_vec.size();i++){
det_box det_box_tmp;
det_box_tmp.x1 = boxes_vec[boxIdx_vec[i]].x - clsIdx_vec[boxIdx_vec[i]]*max_wh;
det_box_tmp.y1 = boxes_vec[boxIdx_vec[i]].y - clsIdx_vec[boxIdx_vec[i]]*max_wh;
det_box_tmp.w = boxes_vec[boxIdx_vec[i]].width;
det_box_tmp.h = boxes_vec[boxIdx_vec[i]].height;
det_box_tmp.score = scores_vec[boxIdx_vec[i]];
det_boxes[clsIdx_vec[boxIdx_vec[i]]].push_back(det_box_tmp);
}
return det_boxes;
}