引言
过去十年,深度学习在图像识别领域取得了惊人的突破。从2012年ImageNet大赛上的AlexNet,到后来的ResNet、EfficientNet,再到近年来Transformer架构的崛起,AI已经能在许多任务上超越人类,比如人脸识别、目标检测、医学影像分析等。然而,这些系统虽然能识别图像中的物体,却并不真正“理解”它们的含义。
想象这样一个场景:一张图片里有一只狗、一只猫和一个倒在地上的水杯。传统的图像识别模型能准确地告诉你这些物体分别是什么,但却无法理解它们之间的关系——这只狗是不是刚刚撞到了桌子,导致水杯倒下?这只猫是不是在观察水杯,还在犹豫要不要去舔洒出来的水?当前的深度学习模型仍然缺乏这样的情境理解能力。
这正是AI发展的下一个关键挑战——让机器不仅能看到世界,还能理解世界。真正的智能不只是“识别物体”,更是“理解场景”,包括因果关系、行为意图和时间演化等更深层次的信息。
本文将探讨深度学习如何从图像识别迈向情境理解,分析当前的技术瓶颈,并介绍正在推动这一领域进步的新方法和应用场景。
一、从图像识别到情境理解的挑战
尽管深度学习在图像识别方面取得了显著进步,但让AI真正理解视觉场景仍然面临诸多挑战。这些挑战不仅涉及技术层面的问题,也关乎AI如何认知世界的本质。
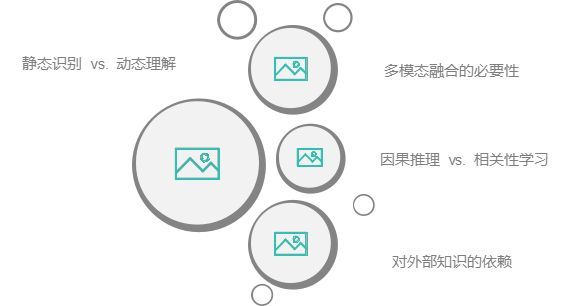
1、静态识别 vs. 动态理解
目前的图像识别技术主要关注单帧图像中的物体分类和检测,即“这是什么?”然而,在现实世界中,我们不仅要识别物体,还要理解它们之间的关系以及事件的动态发展。例如,在一张图片中,AI或许能识别出一个人正在奔跑,但它难以判断这个人是在追赶公交车,还是在逃离某个危险情境。情境理解要求AI能够结合时间、空间和背景信息,分析物体的行为模式和潜在意图。
2、多模态融合的必要性
人类在理解场景时,不仅依赖视觉信息,还会结合语言、声音、常识知识等多种信息来源。例如,在一张餐桌上的图片中,我们可以轻易推测出正在进行的是一场晚餐,而不仅仅是“桌子+盘子+食物”的简单组合。然而,当前的计算机视觉系统往往只依赖于视觉数据,缺乏对语言描述、语音对话甚至触觉信息的融合。这导致AI难以像人类一样,通过多种感官信息来形成完整的认知。
3、因果推理 vs. 相关性学习
深度学习的本质是通过海量数据学习模式和相关性,但它并不具备因果推理能力。例如,如果AI在大量数据中发现“雨天时路上行人打伞的概率很高”,它可以基于模式学习来预测某天的场景中可能会出现打伞的人,但它无法理解“因为下雨,所以人们需要打伞”这一因果关系。这种缺乏因果推理的局限,使得AI在遇到复杂情境时容易产生错误推断。例如,如果它看到一个人摔倒,它可能会简单地把这归结为“人类有摔倒的可能性”,而不是尝试理解是由于地面湿滑、身体失去平衡或其他外部因素导致的。
4、对外部知识的依赖
人类理解世界的方式不仅仅是通过视觉感知,还依赖于丰富的世界知识和经验。例如,一张图片显示一个人在厨房里切菜,人类可以推测出他可能正在准备一顿饭,因为我们拥有关于“做饭”的常识。然而,深度学习模型通常只学习有限的数据集,并不具备对世界的广泛知识,因此难以推理出更高级的情境信息。
挑战总结
要让AI从图像识别迈向真正的情境理解,需要突破以下几个关键难点:
从静态识别迈向动态分析,让AI理解事件的时间发展过程。
整合多模态信息,让视觉AI不仅依赖图像,还能结合语言、声音和知识库。
引入因果推理能力,让AI不只是发现模式,而是理解事件发生的逻辑关系。
让AI具备世界知识,帮助其理解人类社会的规则、物理世界的规律以及人们的行为动机。
这些挑战正推动计算机视觉和深度学习技术迈向新的方向,而在后续部分,我们将探讨目前正在发展的核心技术,以及它们如何帮助AI更接近真正的“情境理解”。
二、技术突破:迈向情境理解的核心方向
要让深度学习从简单的图像识别进化到真正的情境理解,需要突破多个关键技术瓶颈。目前,学术界和工业界正在从多个方向推进这些技术,包括视觉-语言模型、多模态融合、大规模世界知识整合、3D感知以及因果推理等。这些进展将帮助AI构建更接近人类的视觉认知能力。

1、视觉-语言模型(VLMs):用语言增强视觉理解
目前,像CLIP、BLIP、LLaVA(LLaMA + Vision)等视觉-语言模型,已经开始改变AI对图像的认知方式。它们不仅能识别图像中的物体,还能通过文本理解其含义。例如,CLIP 可以在没有特定标注的情况下,根据文本描述来搜索或分类图片,而LLaVA能像GPT一样分析图片并回答关于场景的复杂问题。
突破点:利用大规模文本数据帮助AI理解视觉概念,使AI不仅能看到物体,还能用语言表达其关系、作用和语境。
应用:智能搜索、视觉问答(VQA)、AI助手对图片的深度理解(如描述艺术作品的风格与情感)。
2、大模型与世界知识的结合:让AI具备“常识”
人类理解一张图片时,会利用过去的经验和世界知识。例如,看到一个人在厨房里切菜,我们能推测他在做饭,而不是随意玩弄刀具。AI当前的一个重大挑战是缺乏这样的常识认知。
突破点:结合大规模知识图谱(如ConceptNet、Wikidata)和大模型(如GPT-4、Gemini),让AI能基于已有知识推理场景的真实含义。
应用:智能客服(基于图片推测用户意图)、医疗诊断(结合病历和影像判断病因)。
3、3D感知与场景重建:从2D到真实世界的理解
传统的图像识别依赖2D图像,但真实世界是三维的。为了更好地理解场景,AI需要具备3D感知能力。
突破点:NeRF(神经辐射场)、三维点云技术、深度学习驱动的3D场景重建,使AI能理解物体的空间关系、尺度以及环境。
应用:自动驾驶(理解道路结构、车辆动态)、机器人导航(精准避障和路径规划)、AR/VR(增强现实与交互体验)。
4、视频理解与事件推理:跨越时间维度的智能
大多数视觉AI仍然局限于单帧图像的理解,而人类认知是基于时间的。视频分析技术正在向深层次的事件推理发展,重点在于预测和理解行为。
突破点:基于Transformer的时序模型(如TimeSformer)、视频大模型(如VideoGPT),能够分析视频中的行为模式,理解因果关系。
应用:安防监控(预测异常行为,如店铺盗窃)、体育分析(理解球员战术和运动轨迹)、影视智能剪辑(自动识别精彩片段)。
5、因果推理:让AI理解“为什么”而非“是什么”
目前的深度学习系统主要依赖数据模式匹配,而不是因果推理。例如,AI可以识别出“雨天人们打伞”这一模式,但难以理解“因为下雨,人们才打伞”。
突破点:因果推理方法(如贝叶斯网络、结构方程建模)正在与深度学习结合,使AI能够建立因果关系,而不仅仅是统计相关性。
应用:医学诊断(推测病因,而不仅是发现病症)、经济预测(分析政策变化对市场的真实影响)、工业故障检测(判断设备损坏的根本原因)。
总结
迈向情境理解,AI需要突破单纯的视觉识别,向更高级的推理能力发展。视觉-语言融合、大模型知识整合、3D感知、时间维度理解以及因果推理,是当前推动深度学习进化的关键技术方向。随着这些技术的不断进步,AI将逐步从“看到”世界迈向“理解”世界,使其在自动驾驶、智能安防、机器人交互、医疗诊断等领域发挥更强大的作用。
三、应用场景:AI如何真正理解世界
当AI不仅能识别图像中的物体,还能理解场景、推测意图、预测事件时,它的应用价值将大幅提升。从自动驾驶到智能安防,从医疗诊断到机器人交互,情境理解技术将赋予AI更接近人类的感知能力,让它真正“看懂”世界。
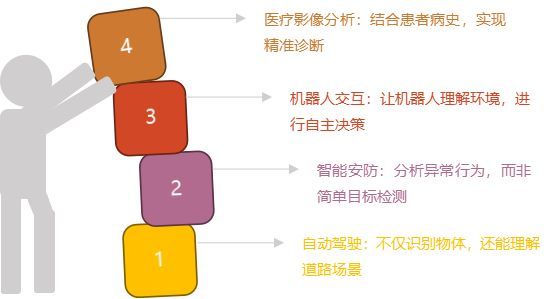
1、自动驾驶:不仅识别物体,还能理解道路场景
传统的自动驾驶算法主要依赖目标检测和路径规划,例如识别红绿灯、行人、车辆等元素。然而,复杂的道路环境需要更深层的理解,例如:
预测行人的意图:AI需要判断一个行人是否只是站在路边,还是即将横穿马路。
识别道路上的隐性风险:比如前方一辆车突然减速,可能是因为前方有障碍物,AI需要据此调整驾驶策略。
结合交通法规和常识:理解非正式交通规则,如某些地区的“礼让行人”文化,或者观察其他驾驶员的行为来预测潜在危险。
情境理解可以让自动驾驶系统更安全、更智能,真正像人类驾驶员一样做出合理决策。
2、智能安防:分析异常行为,而非简单目标检测
当前的安防系统主要依赖于摄像头检测异常物体,比如非法入侵、遗弃物品等。然而,许多危险行为在发生前并不会表现为明显的“异常目标”,而是需要结合背景信息进行推理。例如:
在地铁站,一名乘客徘徊不定,时而接近站台边缘,AI可以结合行人正常行为模式,判断其是否有坠轨风险。
在商场,AI不仅检测到顾客拿起商品,还能分析其购物行为是否符合正常模式,帮助商家识别潜在盗窃行为。
在智慧城市管理中,AI可以通过视频分析,判断人群密集区域是否存在踩踏风险,并提前预警。
情境理解让安防系统从“被动监控”升级为“主动预测”,提升公共安全。
3、机器人交互:让机器人理解环境,进行自主决策
家庭服务机器人、工业机器人乃至人形机器人,只有真正理解环境,才能提供更自然的交互体验。例如:
家用机器人:当机器人看到主人在厨房忙碌,并听到水沸腾的声音,它能推测主人可能需要帮忙关火,而不仅仅是识别“锅”和“水”。
工厂自动化:机器人在生产线上需要根据工人的动作和生产节奏进行调整,而不仅仅是机械地执行预设任务。
智能仓储:AI机器人可以通过摄像头分析货物的摆放情况,理解哪些商品需要补货,而不是仅仅依赖条形码扫描。
有了情境理解,机器人将变得更加智能,真正具备“看懂”世界的能力。
4、医疗影像分析:结合患者病史,实现精准诊断
传统的医学影像AI主要依赖于图像分类,比如判断X光片或MRI扫描是否存在肿瘤。然而,医生在做诊断时,不仅仅依赖单张影像,而是结合患者的病史、症状、实验室检测等多方面信息。因此,AI的情境理解能力对医学诊断至关重要,例如:
在肺部CT扫描中,AI可以结合患者是否有长期吸烟史,调整诊断的置信度,避免误判。
在脑部MRI中,AI可以结合患者的年龄、家族遗传病史,分析是否有阿尔茨海默症的早期迹象。
在急诊中,AI可以实时分析多种传感器数据,例如结合患者的心电图、血压和体温,做出综合判断,而不仅仅依赖影像数据。
通过情境理解,AI可以提供更精准的医学诊断,减少误诊率,提高医疗效率。
总结
AI的情境理解能力正在推动多个行业的智能化升级。从自动驾驶的智能决策,到智能安防的行为预测,从机器人交互的自然化,到医疗诊断的精准化,AI正在从“识别世界”走向“理解世界”。未来,随着多模态学习、因果推理和大模型的发展,AI的情境理解能力将不断提升,使其在更多场景中发挥更大价值。
四、未来展望与挑战
随着深度学习从图像识别迈向情境理解,AI正在逐步接近人类的视觉认知能力。然而,要让AI真正理解世界,而不仅仅是“看见”,仍然面临诸多挑战。未来的发展将集中在更强大的模型、更高效的数据利用、因果推理能力的增强,以及伦理与安全问题的应对。
1、未来展望:AI如何迈向更高层次的理解?
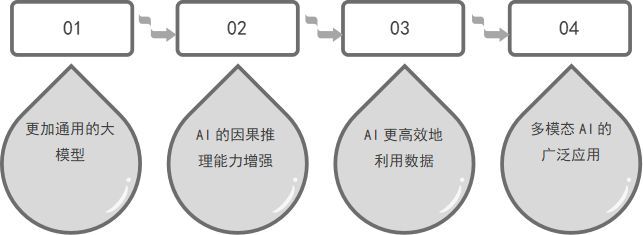
更加通用的大模型
未来的AI不仅需要掌握视觉信息,还要结合语言、语音、文本、物理世界知识,形成“通用情境理解”能力。例如,下一代AI可以在看到一张手术室的照片时,不仅能识别器械和医生,还能基于医学知识推测手术的类型和风险。
具备通用情境理解能力的AI,将在医疗、自动驾驶、智能机器人等领域发挥更大作用。
AI的因果推理能力增强
未来的AI将超越基于相关性的模式学习,逐步具备因果推理能力。例如,在自动驾驶中,AI不仅能识别行人,还能推测行人的意图,判断其是否即将横穿马路。
结合贝叶斯网络、结构因果模型等方法,使AI能够基于情境推测事件的发展,而不仅仅是做静态分类。
AI更高效地利用数据
目前的大模型依赖海量数据训练,未来的AI需要具备“少样本学习”(Few-shot Learning)和“零样本学习”(Zero-shot Learning)能力。
通过强化学习、自监督学习等方法,使AI能在有限的数据情况下,依然具备出色的情境理解能力。
多模态AI的广泛应用
AI将不再仅仅依赖视觉,而是结合语音、文本、物理感知,真正做到“感知+理解”。
例如,未来的智能家居系统,能通过摄像头、语音传感器、温度传感器等多种信息源,判断用户的意图并做出最合理的响应。
2、仍然存在的挑战:AI能否真正理解世界?
计算资源的巨大消耗
训练具备情境理解能力的大模型,需要极高的计算资源。如何提高AI的计算效率,同时降低能耗,是未来技术突破的关键。
数据偏见与泛化能力
AI对情境的理解,往往依赖于训练数据。但如果数据存在偏见,AI的理解能力也可能受到限制。例如,如果某个医疗AI主要基于西方国家的数据训练,它可能无法很好地适用于亚洲患者。
如何让AI具备更强的泛化能力,适应不同的环境,是一个重要挑战。
因果推理的局限性
目前的因果推理方法,仍然无法完全复制人类的思维方式。例如,一个人看到倒地的水杯,会立刻推测它是被某个外力打翻的,而AI仍然难以在没有明确数据支持的情况下做出类似推理。
未来需要结合更多的知识图谱、逻辑推理方法,让AI真正具备因果推理能力。
伦理与安全问题
具备情境理解能力的AI,如果被滥用,可能会带来伦理问题。例如,过于精准的行为分析,可能会侵犯用户隐私。
如何在提升AI智能的同时,确保其在合规、安全的范围内使用,将成为未来发展的重要议题。
结语
从图像识别到情境理解,AI正在从“看得见”走向“看得懂”。尽管面临计算资源、因果推理、数据偏见等挑战,但未来随着大模型、因果推理、多模态融合技术的突破,AI有望在更多复杂场景中发挥作用,实现真正的智能化。
结论
从图像识别到情境理解,深度学习正在迈向一个全新的阶段。过去的AI能够准确识别物体,但缺乏对场景、意图和因果关系的理解。而如今,借助视觉-语言模型、多模态融合、因果推理和3D感知等技术,AI正逐步从“看得见”走向“看得懂”,在自动驾驶、智能安防、医疗诊断、机器人交互等领域展现出巨大的潜力。
然而,真正的情境理解仍然面临诸多挑战,例如计算资源消耗、数据偏见、因果推理的局限性以及伦理安全问题。未来的发展需要更强大的通用模型、更高效的数据利用方式,以及更完善的安全与合规机制,才能让AI真正具备人类般的理解能力。
尽管道路充满挑战,但情境理解无疑是AI发展的下一个关键突破口。当AI不再只是被动地识别信息,而是能够主动推理、预测和决策时,它将彻底改变我们与技术的交互方式,为社会带来前所未有的智能化变革。