CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
ICLR 2023已经放榜,但是今天我们先来回顾一下去年的ICLR 2022!
ICLR 2022将于2022年 4 月 25 日星期一至 4 月 29 日星期五在线举行(连续第三年!)。它是深度学习研究领域规模最大、最受欢迎的会议之一,它汇集了超过 1000 篇论文、19 个研讨会和 8 个特邀报告。主题涵盖 ML 理论、强化学习 (RL)、计算机视觉 (CV) )、自然语言处理 (NLP)、神经科学等等。如果我们想要对这一庞大的内容阵容有所了解,就必须进行挑选,我们根据现有信息,挑选出10篇最能激起我们兴趣的论文。事不宜迟,快来看看吧!
1. Autoregressive Diffusion Models
标题:自回归扩散模型
文章链接:https://openreview.net/forum?id=Lm8T39vLDTE
项目代码:https://github.com/google-research/google-research/tree/master/autoregressive_diffusion
作者的 TL;DR
一个新的离散变量模型类,包括阶不可知自回归模型和吸收离散扩散。扩散模型在过去一年中越来越受欢迎,并且逐渐被吸收到深度学习工具箱中。本文为这些模型提出了一个重要的概念创新。
关键见解
用术语来说,扩散模型通过在像素网格上迭代添加“可微噪声”来生成图像,最终成为真实图像。推理从对某种“白噪声”图像进行采样开始。这项工作建议做一个类似的过程,但不是应用扩散步骤同时迭代解码所有像素,而是一次自回归地解码几个像素,然后在其余过程中保持固定(见下图)。
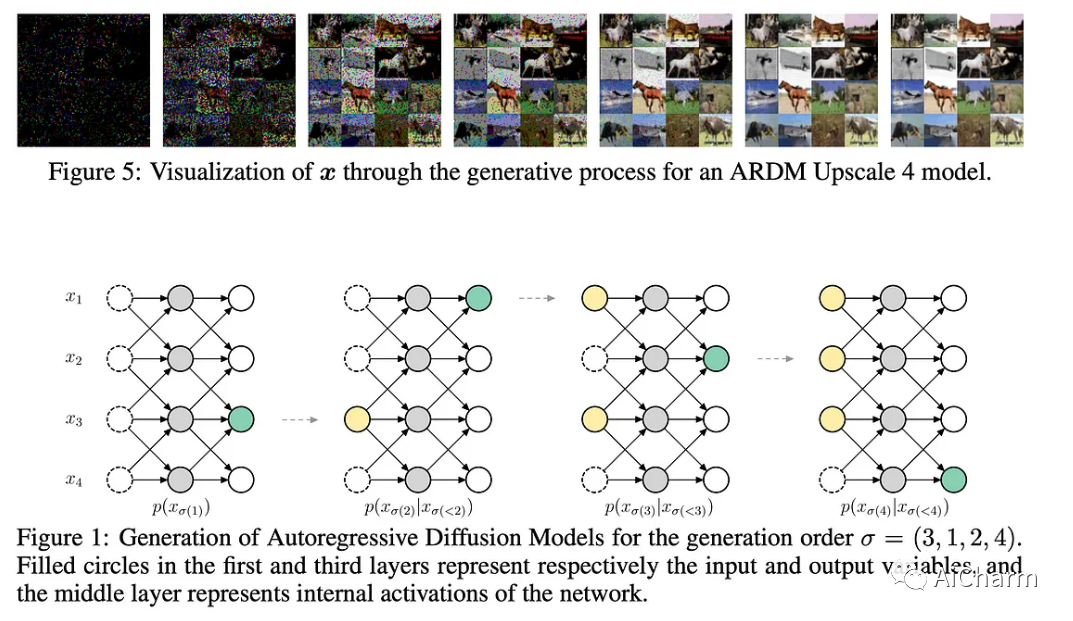
此外,与 DALL·E⁴ 等其他用于图像生成的自回归方法相比,该方法在解码图像时不需要特定的顺序。甚至,在给定整个图像解码步骤的固定预算的情况下,模型可以动态调整每个扩散步骤解码的像素数量!
对于训练,类似 BERT 的去噪自动编码器自监督目标就足够了:给定图像,屏蔽一部分像素并预测其中一些像素的值。虽7结果并不惊天动地,但这在概念上是扩散模型的简单而有效的演变,允许它们解码输出自回归并应用于非从左到右的文本生成。如果您想更深入地研究本文,Yannic Kilcher 有一个非常棒的解说视频,强烈推荐!
2.Poisoning and Backdooring Contrastive Learning
标题:中毒和走后门的对比性学习
作者:Nicholas Carlini, Andreas Terzis
文章链接:https://openreview.net/forum?id=iC4UHbQ01Mp
作者的 TL;DR
我们认为中毒和后门攻击是对多模态对比分类器的严重威胁,因为它们明确设计用于在来自 Internet 的未经整理的数据集上进行训练。使用从网络上抓取的数据进行大规模自监督预训练是训练大型神经网络的基本要素之一。对于来自 OpenAI 的著名 CLIP²,来自网络的嘈杂的未经整理的图像文本对用于训练。会出什么问题?
关键见解
本文探讨了对手如何毒害像 CLIP 这样的模型的训练数据的一小部分——使用来自网络的图像文本对的对比学习进行训练——这样模型就会对测试图像进行错误分类。他们尝试了两种方法:
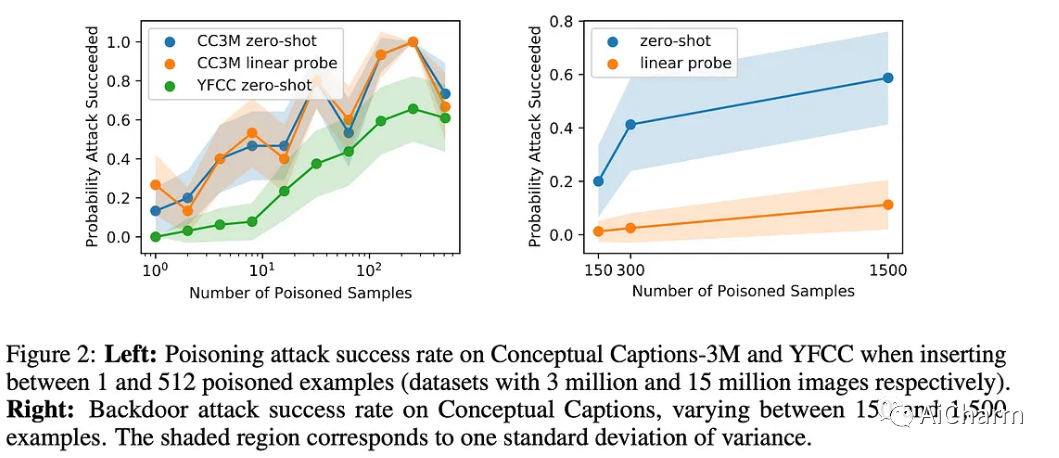
1.有针对性的中毒:通过添加中毒样本来修改训练数据集,目的是让最终模型对带有错误特定标签的特定图像进行错误分类。根据结果,这可以通过仅毒化 0.0001% 的训练数据集来持续实现,例如将 3 个图像对添加到包含 300 万个实例的数据集中。
2.后门攻击:这种方法不是具有特定的目标图像,而是旨在在任何图像上覆盖一小块像素,这样这将被错误分类为所需的错误标签。这种更具野心的攻击可以通过中毒 0.01% 的训练数据集来持续实施,例如从 300 万个实例数据集中毒化了 300 张图像。
任何人都可以操纵公共互联网数据,这使得这些攻击成为可能。这是在开发和部署模型时应考虑使用未经整理的数据训练模型的新弱点。
3.Bootstrapped Meta-Learning
标题:自举元学习
作者:Sebastian Flennerhag, Yannick Schroecker, Tom Zahavy, Hado van Hasselt, David Silver, Satinder Singh
文章链接:https://openreview.net/forum?id=b-ny3x071E5
作者的 TL;DR
我们提出了一种带有梯度的元学习算法,该算法从自身或其他更新规则中引导元学习器。许多强化学习算法对超参数的选择非常敏感。元学习是一种很有前途的学习范式,用于改进学习者的学习规则(包括超参数),使学习更快、更稳健。
关键见解
在元学习中,学习者配备了一个外部优化循环,可以优化内部优化的“学习规则”,直接优化学习目标(例如通过梯度下降)。用非常简单的术语来说,现有的元学习算法通常依赖于学习者的表现来评估学习规则:让学习者运行 k 步,如果学习提高了就做更多,如果学习变得更糟,就做更少.直接使用学习者目标的问题在于,元学习优化将 (1) 被限制在与学习目标函数相同的几何形状上,并且 (2) 优化将是近视的,因为它只会针对以下范围进行优化k 步,而超出此范围的学习动态可能要复杂得多。
坦率地说,这个过程的理论细节超出了我的理解范围,但其要点是元学习器首先被要求预测学习器在评估的 k 步之外的表现,然后根据预测进行优化;换句话说,元学习器生成自己的优化目标。这使元学习者能够针对更长的时间范围进行优化,而无需实际评估计算量大的如此长的时间范围。
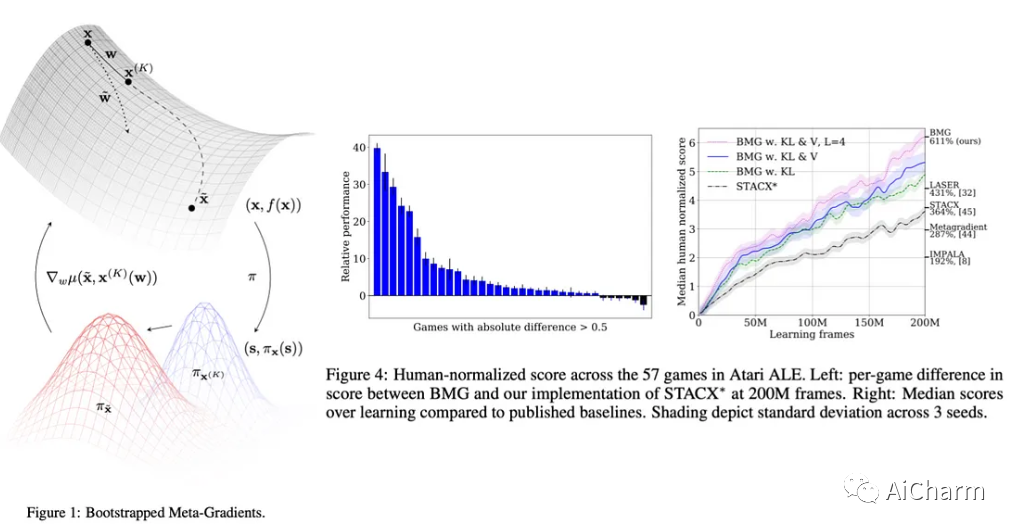
作者证明了这种方法的一些很好的理论特性,并且实证结果在 ATARI ALE 基准 1 上实现了最新的技术水平 (SOTA),并提高了多任务学习的效率。
4.Equivariant Subgraph Aggregation Networks
标题:等变子图聚合网络
作者:Beatrice Bevilacqua、Fabrizio Frasca、Derek Lim、Balasubramaniam Srinivasan、Chen Cai、Gopinath Balamurugan、Michael M. Bronstein、Haggai Maron
文章链接:https://openreview.net/forum?id=dFbKQaRk15w
作者的 TL;DR
我们提出了一个可证明的表达图学习框架,该框架基于将图表示为子图的多集并使用等变架构处理它们。消息传递神经网络 (MPNN) 在图上的有限表现力——属于图神经网络 (GNN) 的范畴——是阻碍 GNN 研究人员晚上睡个好觉的基本问题之一。
关键见解
你怎么知道两个图是否相同?你可能认为只看它们就足够了,但你错了。同一个图可以通过重组或允许节点的顺序以不同的方式表示,这样给定两个图就很难确定它们是否相同,即同构。
Weisfeiler-Leman (WL) 测试是一种算法,它根据图的直接邻域递归地对图的节点进行分类。如果在所有这些过程之后,两个图的节点具有“不同的分类”,这意味着测试失败,这意味着两个图是不同的(非同构)。另一方面,如果两个图在 WL 测试后“仍然相同”,则它们可能是同构的,但不能保证!WL 测试无法区分某些图形结构。
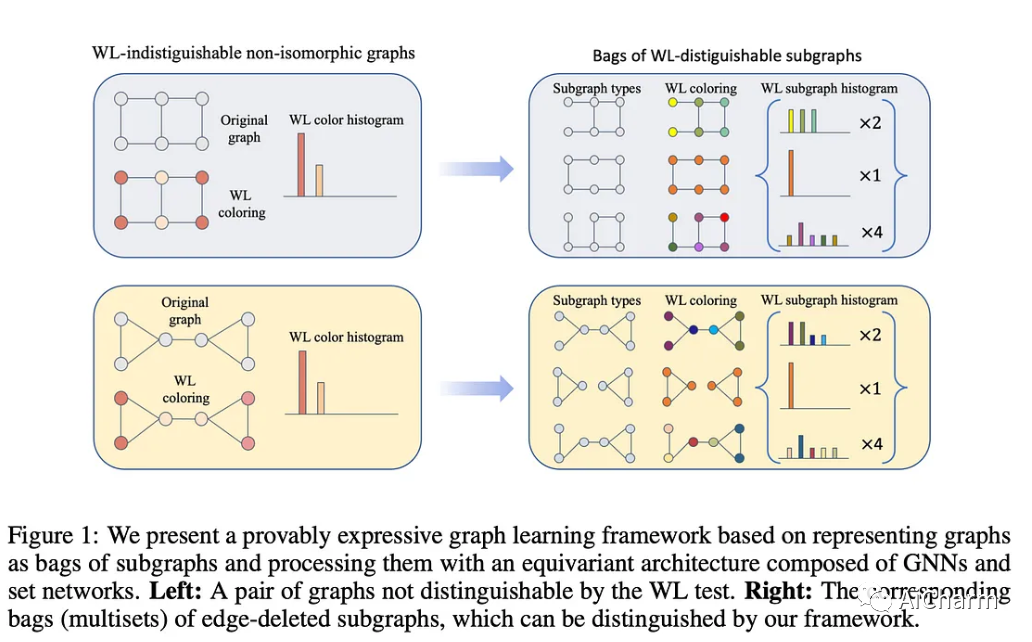
MPNNs GNNs 可以理解为 WL 测试的可微模拟,这就是为什么 MPNNs 继承了 WL 测试的表达力限制:它们无法区分某些图子结构。更进一步,根据 MPNN 如何聚合来自其邻居的信息,它们的表达能力甚至可能低于 WL 测试!
这项工作建立了所有这些联系,并提出了一种最大化 MPNN 表达能力的方法,该方法包括将图分解为子图袋并将 MPNN 应用于这些子图袋。
5.Perceiver IO: A General Architecture for Structured Inputs & Outputs
标题:感知器 IO:结构化输入和输出的通用架构
作者:Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier J Henaff, Matthew Botvinick, Andrew Zisserman, Oriol Vinyals, Joao Carreira
文章链接:https://openreview.net/forum?id=fILj7WpI-g
作者的 TL;DR
我们提出了 Perceiver IO,这是一种通用架构,可处理来自任意设置的数据,同时随输入和输出的大小线性缩放。通过对数据做出尽可能少的假设来建模数据很有趣,因为它有可能很好地转移到不同的模式。
关键见解
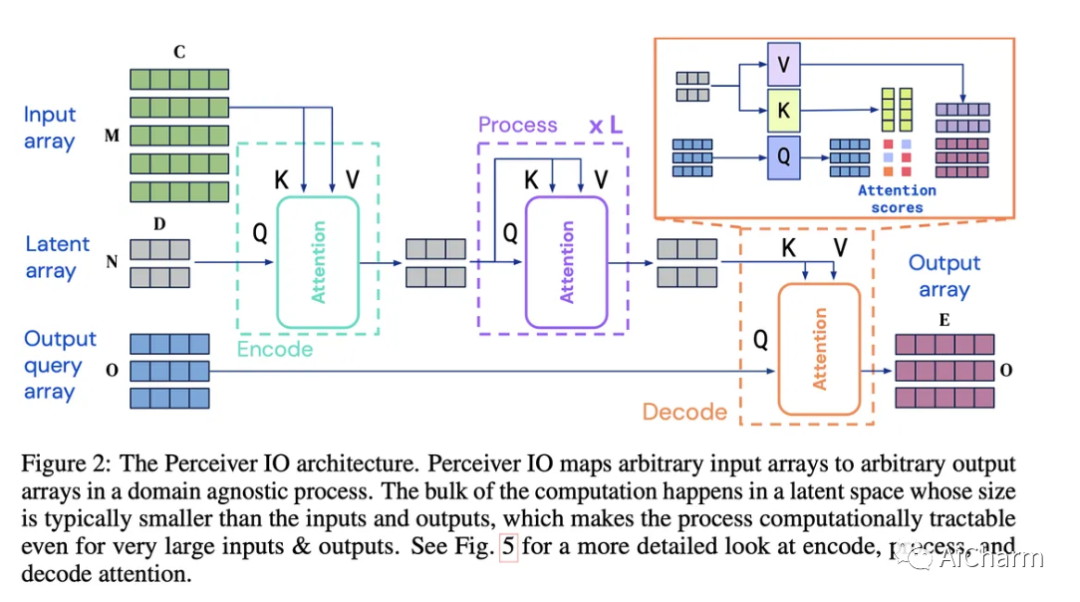
这项工作遵循与原始 Perceiver³ 相似的路线,通过使用灵活的查询机制对其进行扩充,该机制使模型具有任意大小的输出,而不是在模型末尾需要特定于任务的架构。支持各种大小和语义的输出,消除了对特定任务架构工程的需求。通过查看下图可以理解模型的概述:输入可以是任意长的嵌入序列,这些序列被映射到潜在数组编码中。这个过程允许对非常长的输入序列进行建模,假设潜在数组大小是固定的,当输入变得非常长时,二次复杂度不会爆炸。在这个“编码步骤”之后,模型应用了由自注意力层和前馈层组合组成的公共 L 变换器块。最后,解码步骤采用输出查询数组并将其与输入的潜在表示相结合以生成所需维度的输出数组。
许多现有的学习技术,例如 Masked Language Modeling 或对比学习,也可以应用于此架构。遵循针对每种模态进行训练的常见现有方法,该模型在 NLP 和视觉理解、多任务和多模态推理以及光流方面产生了很好的结果。该死,他们甚至将其插入 AlphaStar(取代现有的 Transformer 模块),在具有挑战性的星际争霸 II 游戏中取得了强劲的成绩!
更多Ai资讯:公主号AiCharm







![【QA】[vue/element-ui] 日期输入框的表单验证问题](https://img-blog.csdnimg.cn/272b25f10c0d45ff90af194c61ce655f.png)