深度学习网络模型——RepVGG网络详解
- 0 前言
- 1 RepVGG Block详解
- 2 结构重参数化
- 2.1 融合Conv2d和BN
- 2.2 Conv2d+BN融合实验(Pytorch)
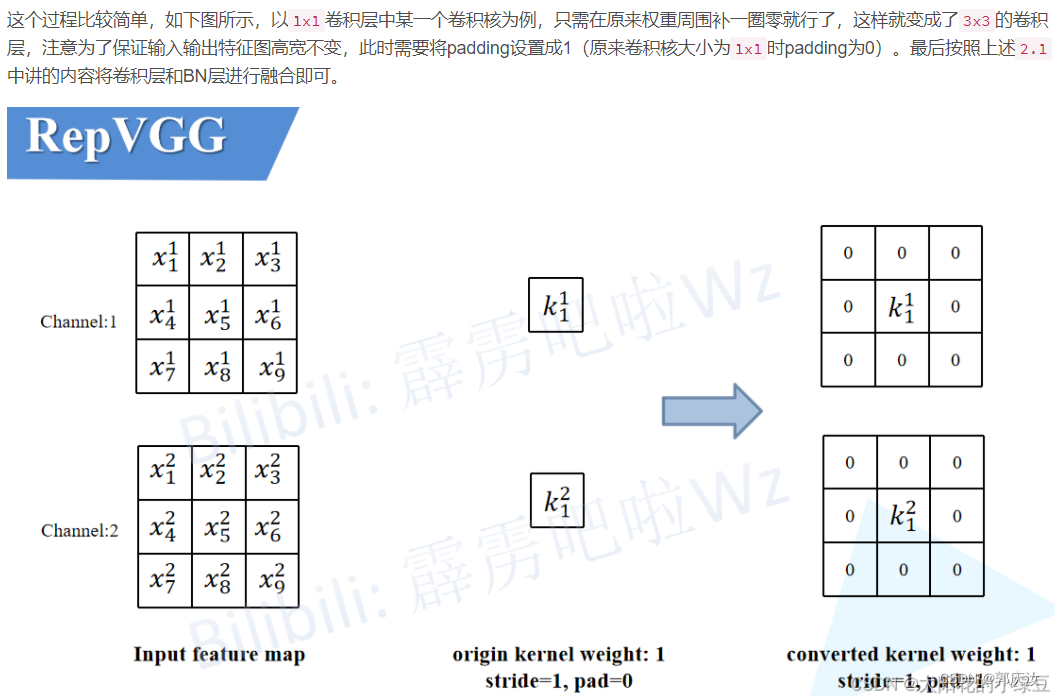
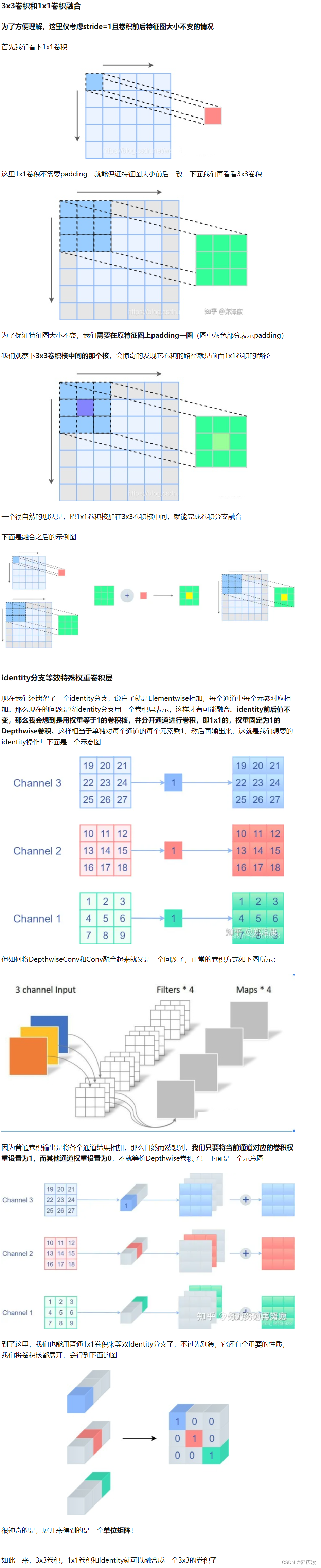
- 2.3 将1x1卷积转换成3x3卷积
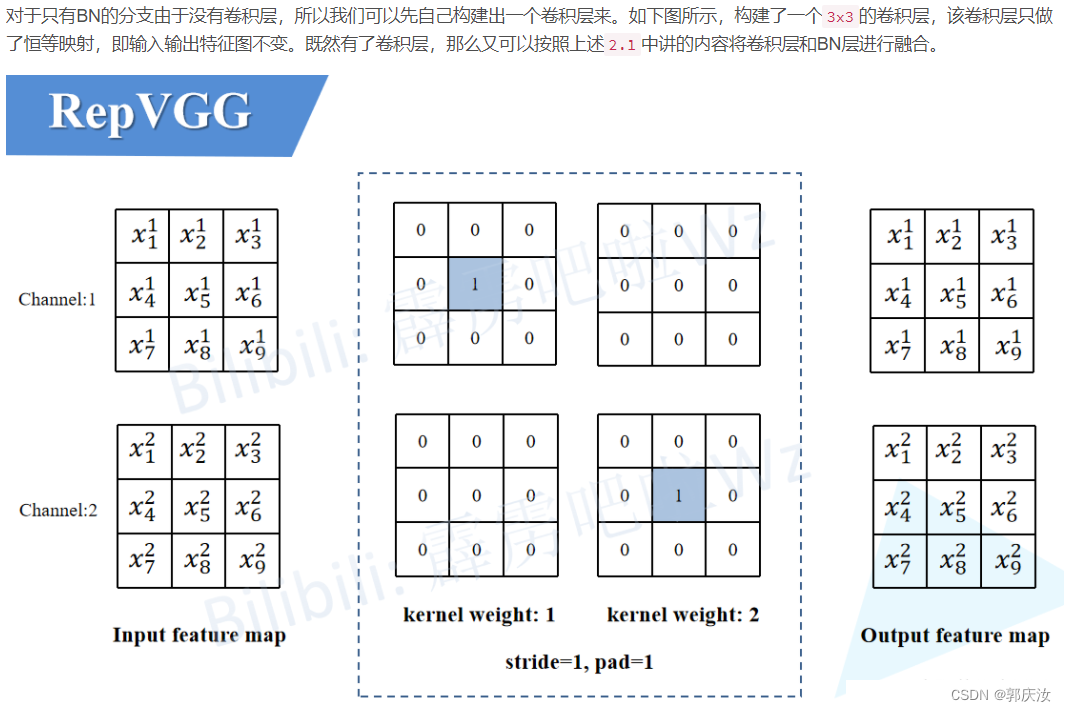
- 2.4 将BN转换成3x3卷积
- 2.5 多分支融合
- 2.6 结构重参数化实验(Pytorch)
- 3 模型配置
论文名称: RepVGG: Making VGG-style ConvNets Great Again
论文下载地址: https://arxiv.org/abs/2101.03697
官方源码(Pytorch实现): https://github.com/DingXiaoH/RepVGG
0 前言
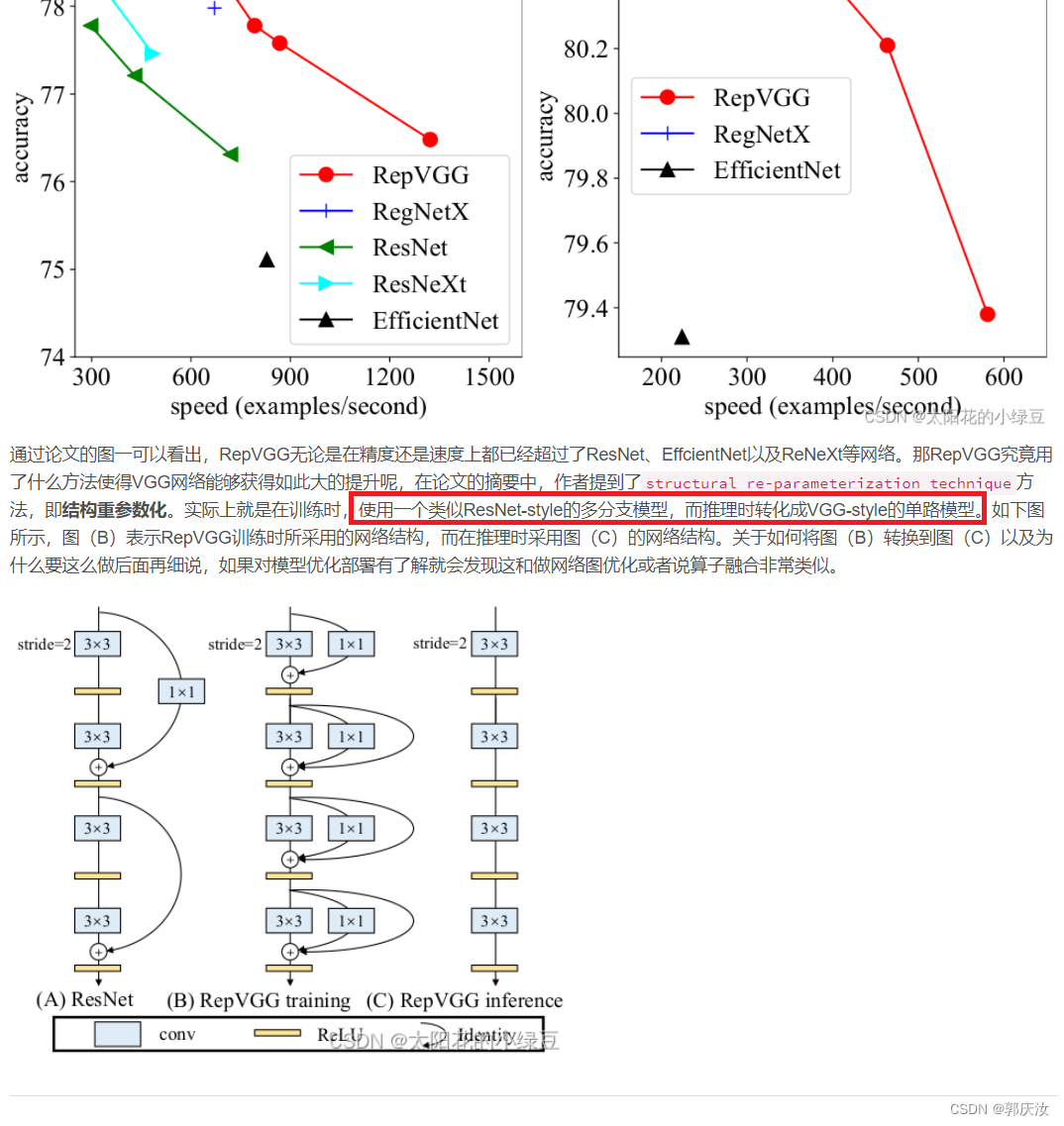
1 RepVGG Block详解

2 结构重参数化
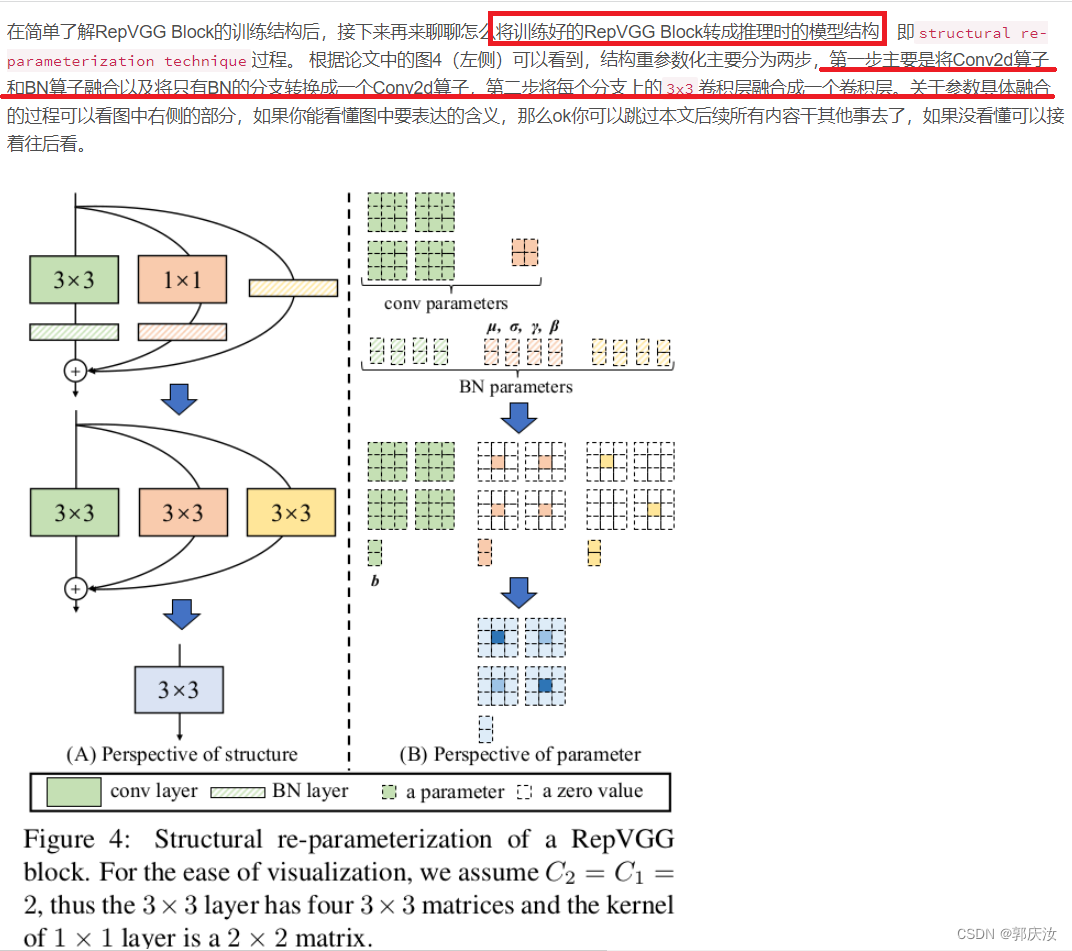
2.1 融合Conv2d和BN


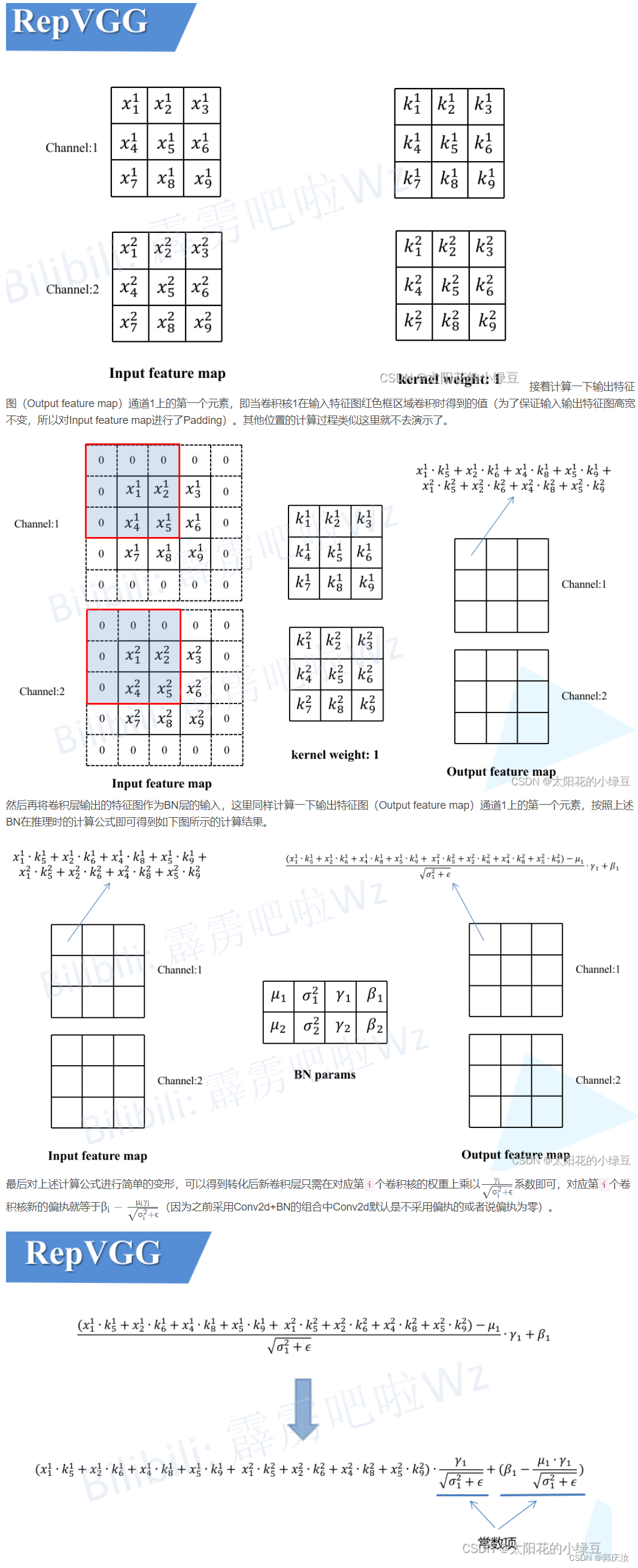
2.2 Conv2d+BN融合实验(Pytorch)

from collections import OrderedDict
import numpy as np
import torch
import torch.nn as nn
def main():
torch.random.manual_seed(0)
f1 = torch.randn(1, 2, 3, 3)
module = nn.Sequential(OrderedDict(
conv=nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1, bias=False),
bn=nn.BatchNorm2d(num_features=2)
))
module.eval()
with torch.no_grad():
output1 = module(f1)
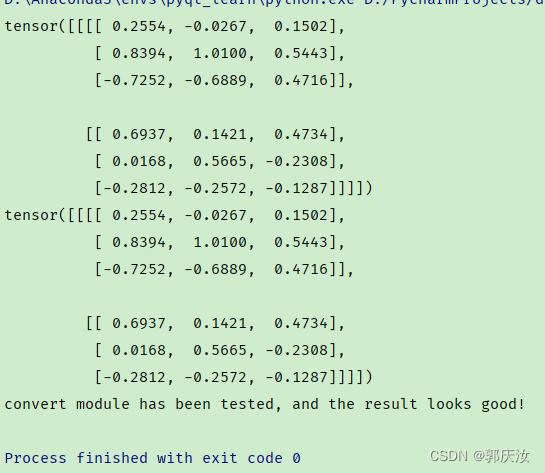
print(output1)
# fuse conv + bn
kernel = module.conv.weight
running_mean = module.bn.running_mean
running_var = module.bn.running_var
gamma = module.bn.weight
beta = module.bn.bias
eps = module.bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1) # [ch] -> [ch, 1, 1, 1]
kernel = kernel * t
bias = beta - running_mean * gamma / std
fused_conv = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1, bias=True)
fused_conv.load_state_dict(OrderedDict(weight=kernel, bias=bias))
with torch.no_grad():
output2 = fused_conv(f1)
print(output2)
np.testing.assert_allclose(output1.numpy(), output2.numpy(), rtol=1e-03, atol=1e-05)
print("convert module has been tested, and the result looks good!")
if __name__ == '__main__':
main()
终端输出结果:
2.3 将1x1卷积转换成3x3卷积
2.4 将BN转换成3x3卷积
代码截图如下所示:
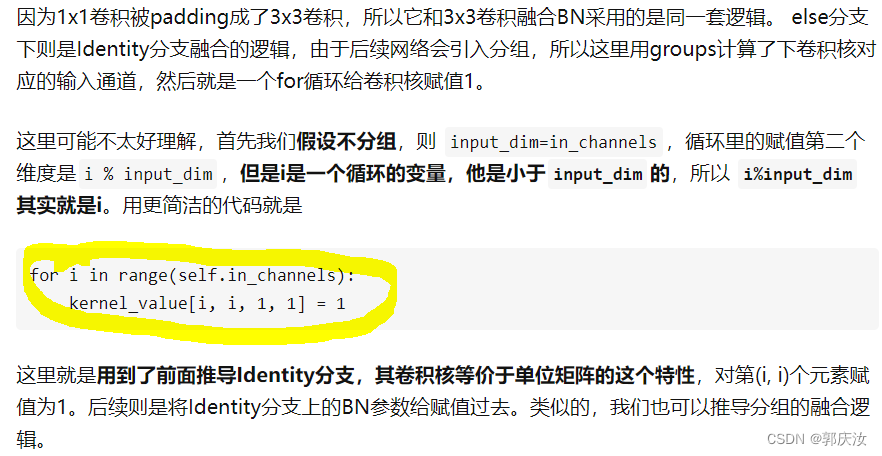
2.5 多分支融合
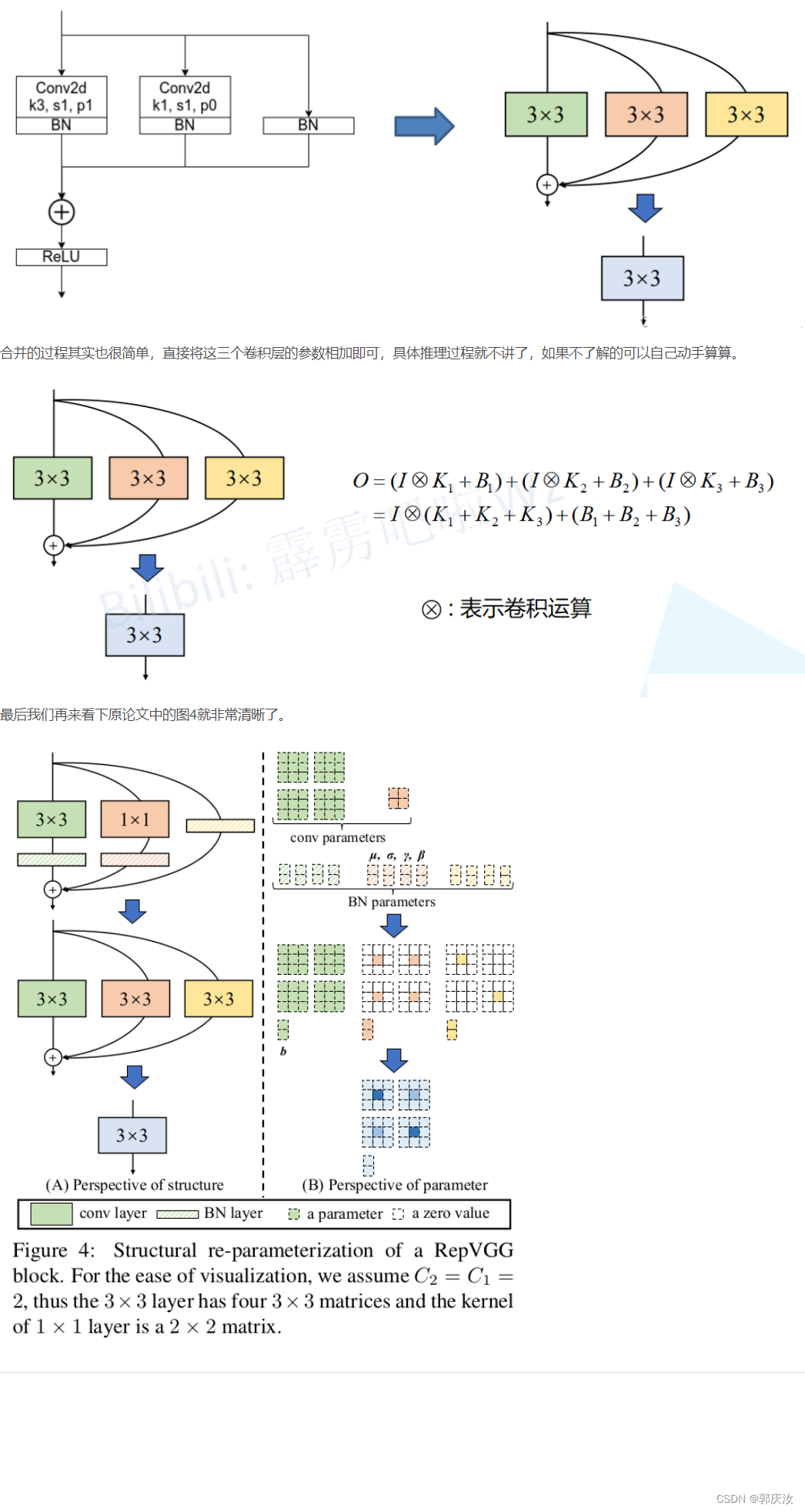
代码截图:
图像演示:
2.6 结构重参数化实验(Pytorch)
import time
import torch.nn as nn
import numpy as np
import torch
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.nonlinearity = nn.ReLU()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups,
bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) \
if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=stride, padding=0, groups=groups)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
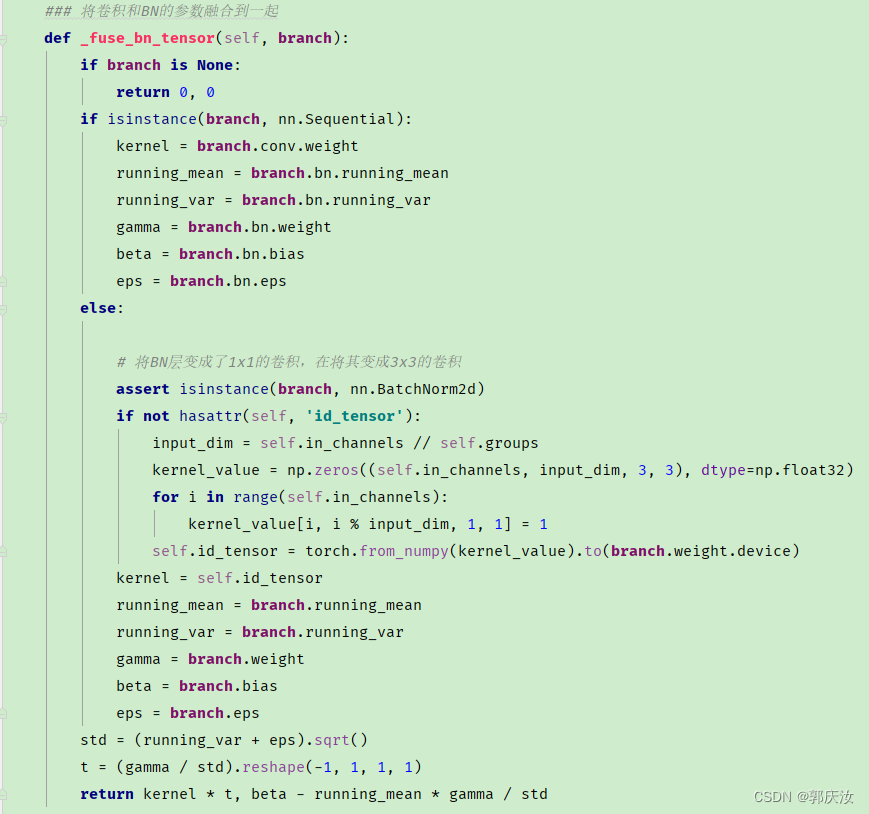
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
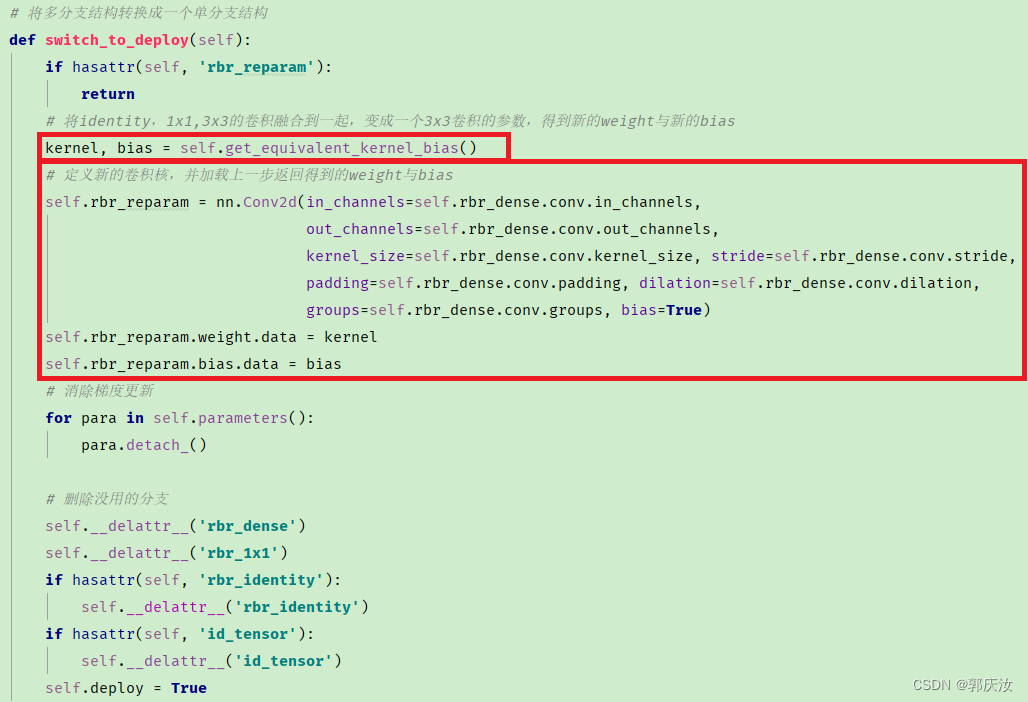
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
def main():
f1 = torch.randn(1, 64, 64, 64)
block = RepVGGBlock(in_channels=64, out_channels=64)
block.eval()
with torch.no_grad():
output1 = block(f1)
start_time = time.time()
for _ in range(100):
block(f1)
print(f"consume time: {time.time() - start_time}")
# re-parameterization
block.switch_to_deploy()
output2 = block(f1)
start_time = time.time()
for _ in range(100):
block(f1)
print(f"consume time: {time.time() - start_time}")
np.testing.assert_allclose(output1.numpy(), output2.numpy(), rtol=1e-03, atol=1e-05)
print("convert module has been tested, and the result looks good!")
if __name__ == '__main__':
main()
终端输出结果如下:
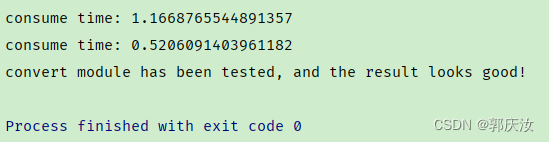
通过对比能够发现,结构重参数化后推理速度翻倍了,并且转换前后的输出保持一致。
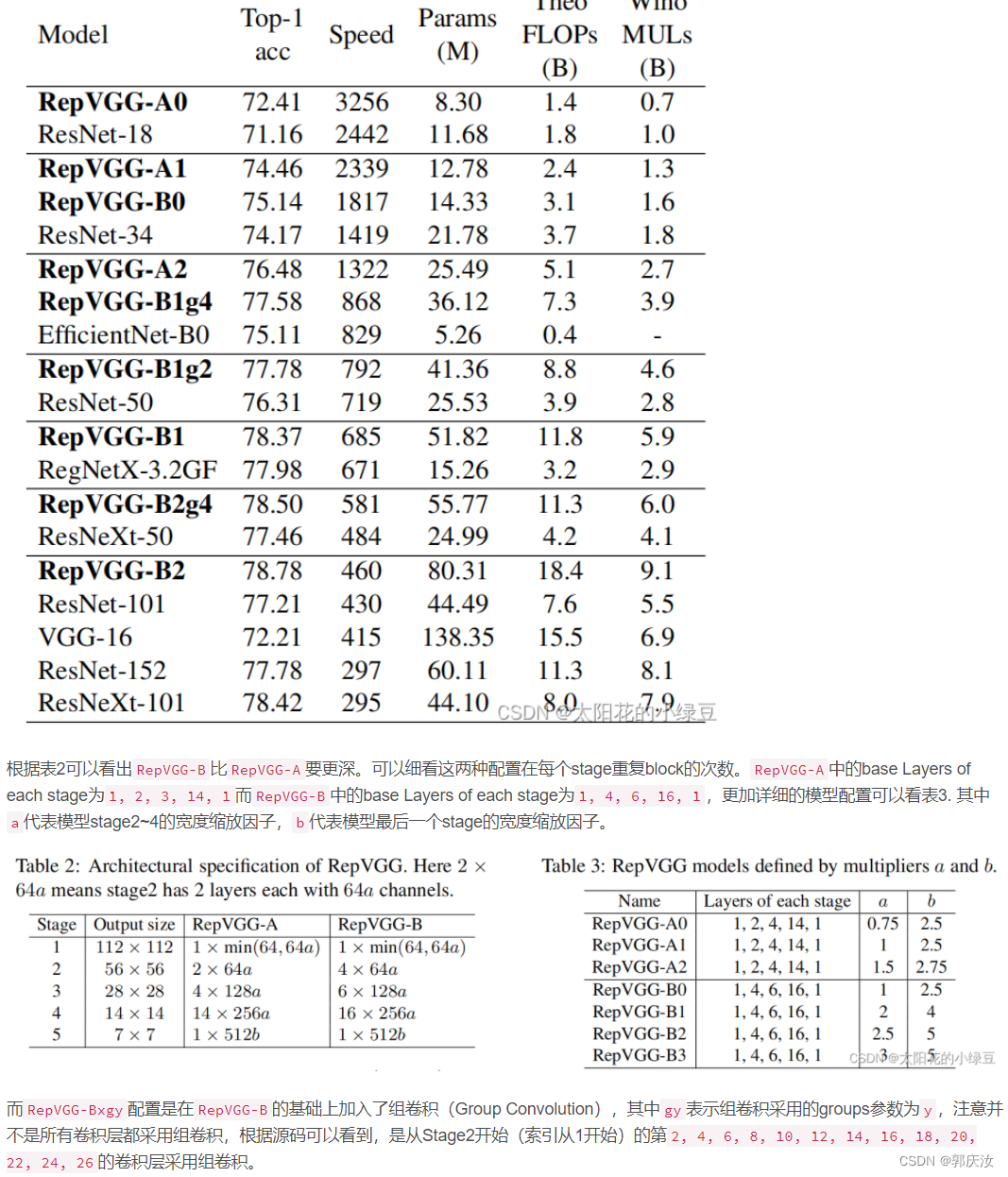
3 模型配置




![【QA】[vue/element-ui] 日期输入框的表单验证问题](https://img-blog.csdnimg.cn/272b25f10c0d45ff90af194c61ce655f.png)



![P1307 [NOIP2011 普及组] 数字反转](https://img-blog.csdnimg.cn/005fa6e676344e7385e7ea0b184658b0.png)