一、数组
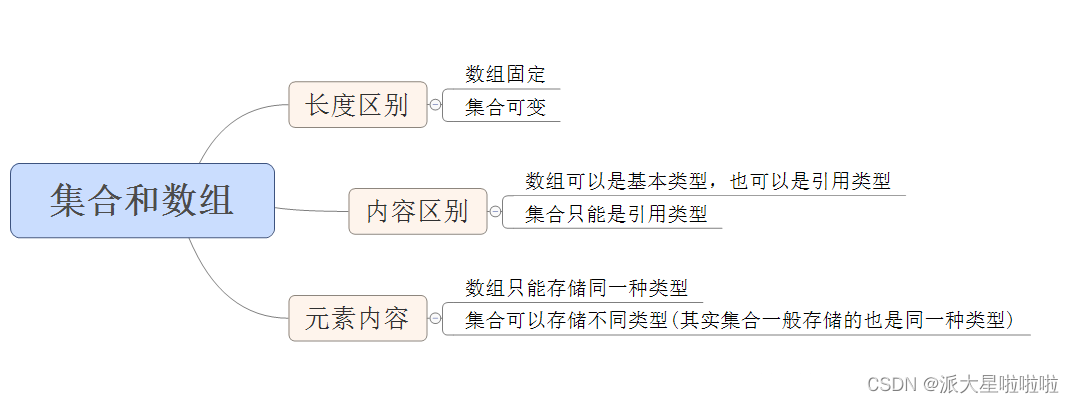
- Java语言中的数组是一种引用数据类型;不属于基本数据类型
- 数组当中既可以存储“基本数据类型”的数据,也可以存储“引用数据类型”的数据(数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是内存地址值)
- 数组是有对应的类,这个类是在JVM运行时创建的,所以没有对应的class 文件;(通过数组创建语法
int[] a = {1, 100, 10, 20};可看出,无法查看 数组类,以及源码);数组的父类是Object - 数组一旦创建,在java中规定,长度不可变。(数组长度不可变)
java中的数组要求数组中元素的类型统一。比如int类型数组只能存储int类型,自定义Person类型数组只能存储Person类型- 数组在内存方面存储的时候,内存地址连续。 这是数组存储元素的特点(特色)。数组实际上是一种简单的数据结构。
- 所有的数组都是拿“第一个小方框的内存地址”作为整个数组对象的内存地址。 (数组中首元素的内存地址作为整个数组对象的内存地址。)
- 数组中每一个元素都是有下标的,下标从0开始,以1递增。最后一个元素的下标是:
length - 1下标非常重要,因为我们对数组中元素进行“存取”的时候,都需要通过下标来进行
二、为什么引入Java容器?
为什么要引入Java容器?
我们知道,如果定义一个int数组,需要一开始就要制定它的大小。在一些情况下,我们根本不知道它的长度是多少,开辟很大的长度会导致空间浪费。
此外,数组还有很多缺点,例如数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。获取数据中实际元素的个数的需求,数组没有现成的属性或方法可用。数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
为了数组能够更灵活的应用,提出了Java容器的概念。
三、集合

Java内部给我们提供了集合类,能存储任意对象,长度是可以改变的,随着元素的增加而增加,随着元素的减少而减少。
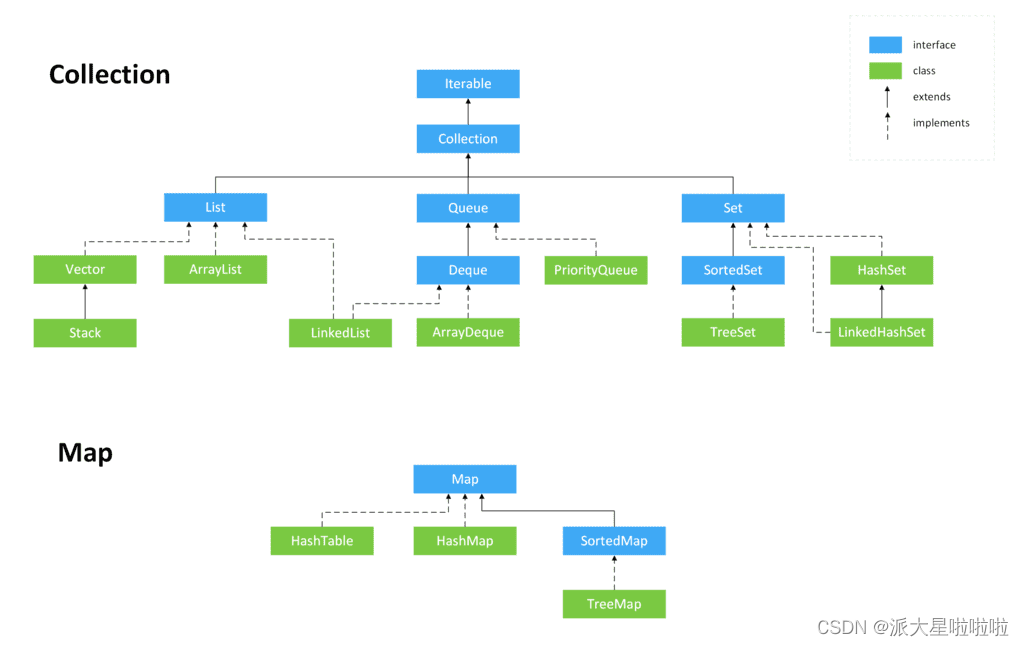
Collection 接口
单列集合的顶层接口,既然是接口就不能直接使用,需要通过实现类!
1.List:
List集合是有序集合,这里的有序指的是存取顺序。- 用户可以精确控制
List中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素 - 与
Set集合不同,List通常允许存储重复的元素
List集合的特点:
- 存取有序
- 可以重复
- 有索引
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
2.Set:
Set集合也是一个接口,继承自Collection,与List类似,都需要通过实现类来进行操作。
特点:
- 不允许包含重复的值
- 没有索引(就不能使用普通的for循环进行遍历)
(1)HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
(2)LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
(3)TreeSet底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode()和equals()方法,二叉树结构保证了元素的有序性。
Map 接口
Map集合以key和value的方式存储数据:键值对key和value都是引用数据类型。key和value都是存储对象的内存地址。key起到主导的地位,value是key的一个附属品。
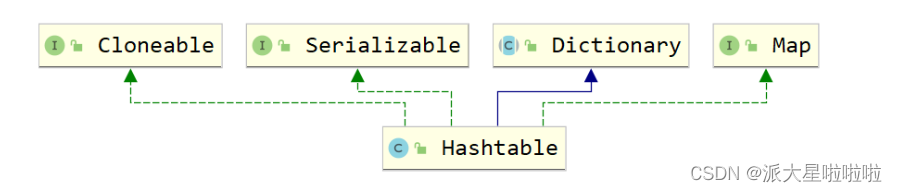
1.HashTable
和HashMap不同,HashTable的实现方式完全不同,这点从二者的类继承关系就可以看出端倪来,HashTable和HashMap虽然都实现了Map接口,但是HashTable继承了DIctionary抽象类,而HashMap继承了AbstractMap抽象类。
2.HashMap
- HashMap底层是哈希表结构的。
- 依赖hashCode方法和equals方法保证键的唯一。
- 如果键要存储的是自定义对象,需要重写
hashCode和equals方法。
1、无序,不可重复。
为什么无序? 因为不一定挂到哪个单向链表上。
不可重复是怎么保证的? equals方法来保证HashMap集合的key不可重复。
如果key重复了,value会覆盖。
2、放在HashMap集合key部分的元素其实就是放到HashSet集合中了。
所以HashSet集合中的元素也需要同时重写hashCode()+equals()方法。
3、HashMap集合的默认初始化容量是16,默认加载因子是0.75
这个默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组以二叉树开始扩容。
重点,记住:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的,这是因为达到散列均匀,为了提高HashMap集合的存取效率,所必须的。
3.TreeMap
- TreeMap底层是红黑树结构
- 依赖自然排序或者比较器排序,对 “键” 进行排序
- 如果键存储的是自定义对象,需要实现Comparable接口或者在创建TreeMap对象时候给出比较器排序规则