目录
- Hadoop
- 简介
- 特性
- 先决环境配置
- 下载地址
- 安装VMware
- 创建虚拟机
- 安装VMware Tools
- 共享文件夹
- 安装Java
- SSH登录权限设置
- Hadoop伪分布式安装
- 安装单机版Hadoop
- Hadoop伪分布式安装
- Hadoop WebUI管理界面
- 测试HDFS集群以及MapReduce任务程序
- 学习参考
Hadoop
简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和 MapReduce。HDFS是对谷歌文件系统(Google File System,GFS)的开源实现,是面向普通硬件环境的分布式文件系统,具有较高的读写速度、很好的容错性和可伸缩性,支持大规模数据的分布式存储,其冗余数据存储的方式,很好地保证了数据的安全性。MapReduce是针对谷歌MapReduce的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用MapReduce来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。借助于Hadoop,程序员可以轻松地编写分布式并行程序,可将其运行于廉价计算机集群上,完成海量数据的存储与计算。
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科和淘宝等都支持Hadoop。
特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行数据处理,它具有以下几个方面的特性:
高可靠性: 采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。Hadoop按位存储和处理数据的能力,值得人们信赖。
高效性: 作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高可扩展性: Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点。
高容错性: 采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
成本低: Hadoop采用廉价的计算机集群,成本较低,普通用户也很容易用自己的PC上搭建Hadoop运行环境。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,Hadoop是开源的,项目的软件成本因此会大大降低。
运行在Linux平台上: Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
支持多种编程语言: Hadoop上的应用程序也可以使用其他语言编写,如C++。
Hadoop官方真正支持的运行平台只有Linux
先决环境配置
下载地址
VMWare下载地址:
https://customerconnect.vmware.com/cn/downloads/details?downloadGroup=WKST-1701-WIN&productId=1376&rPId=100679
Ubuntu下载地址:
https://ftp.sjtu.edu.cn/ubuntu-cd/22.04.1/ubuntu-22.04.1-desktop-amd64.iso
jdk8下载地址:
https://www.oracle.com/java/technologies/downloads/#java8
Hadoop下载地址:
http://archive.apache.org/dist/hadoop/core/hadoop-3.3.1/hadoop-3.3.1.tar.gz
安装VMware
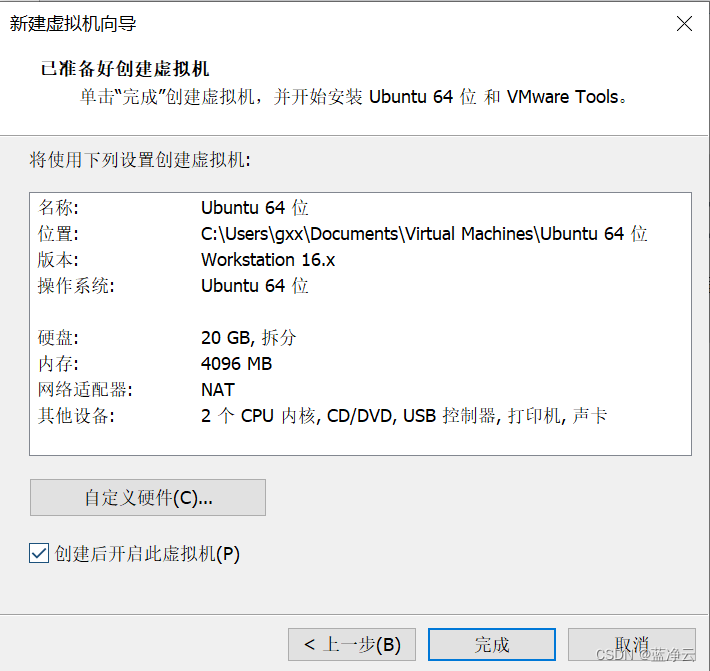
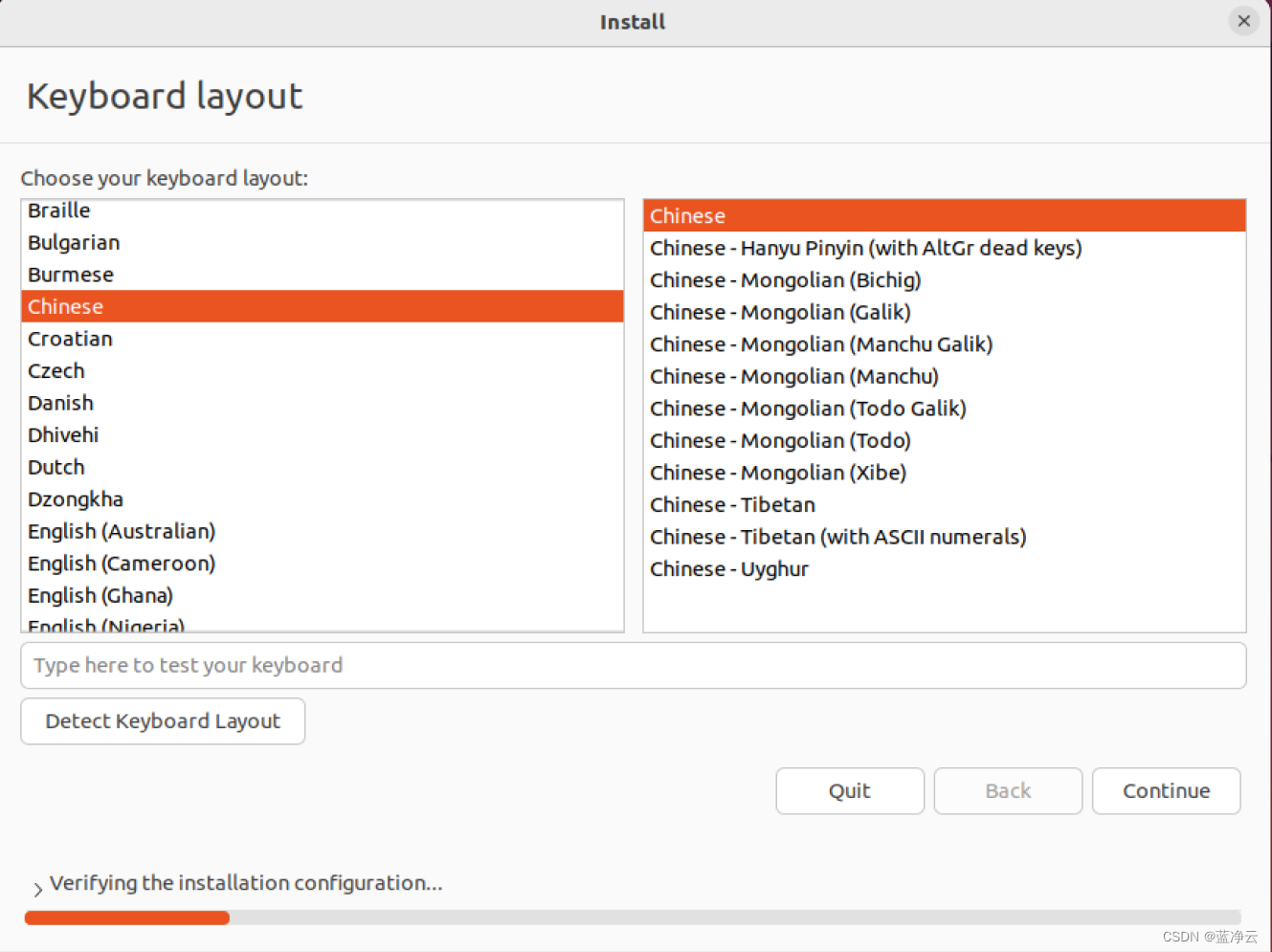
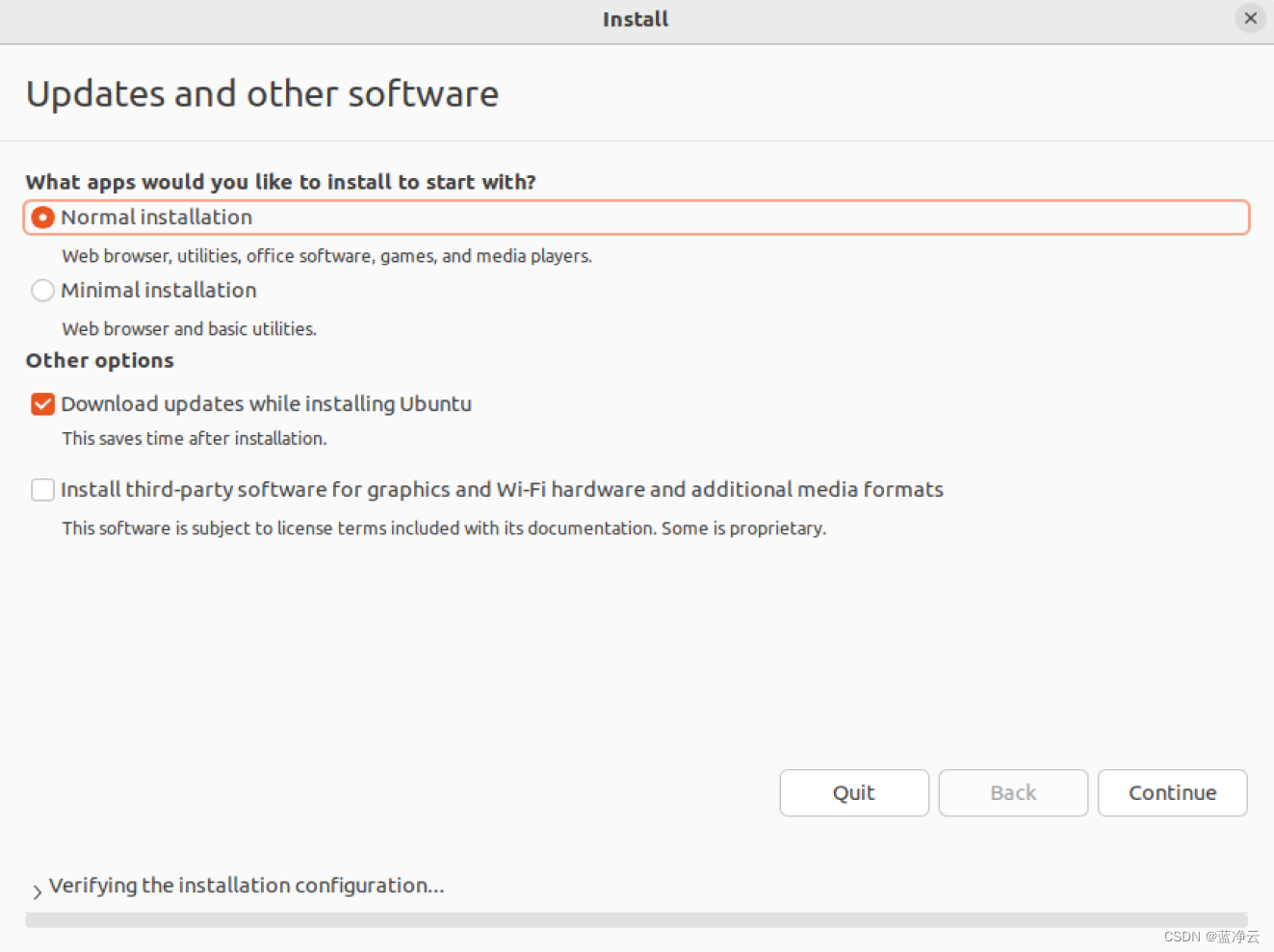
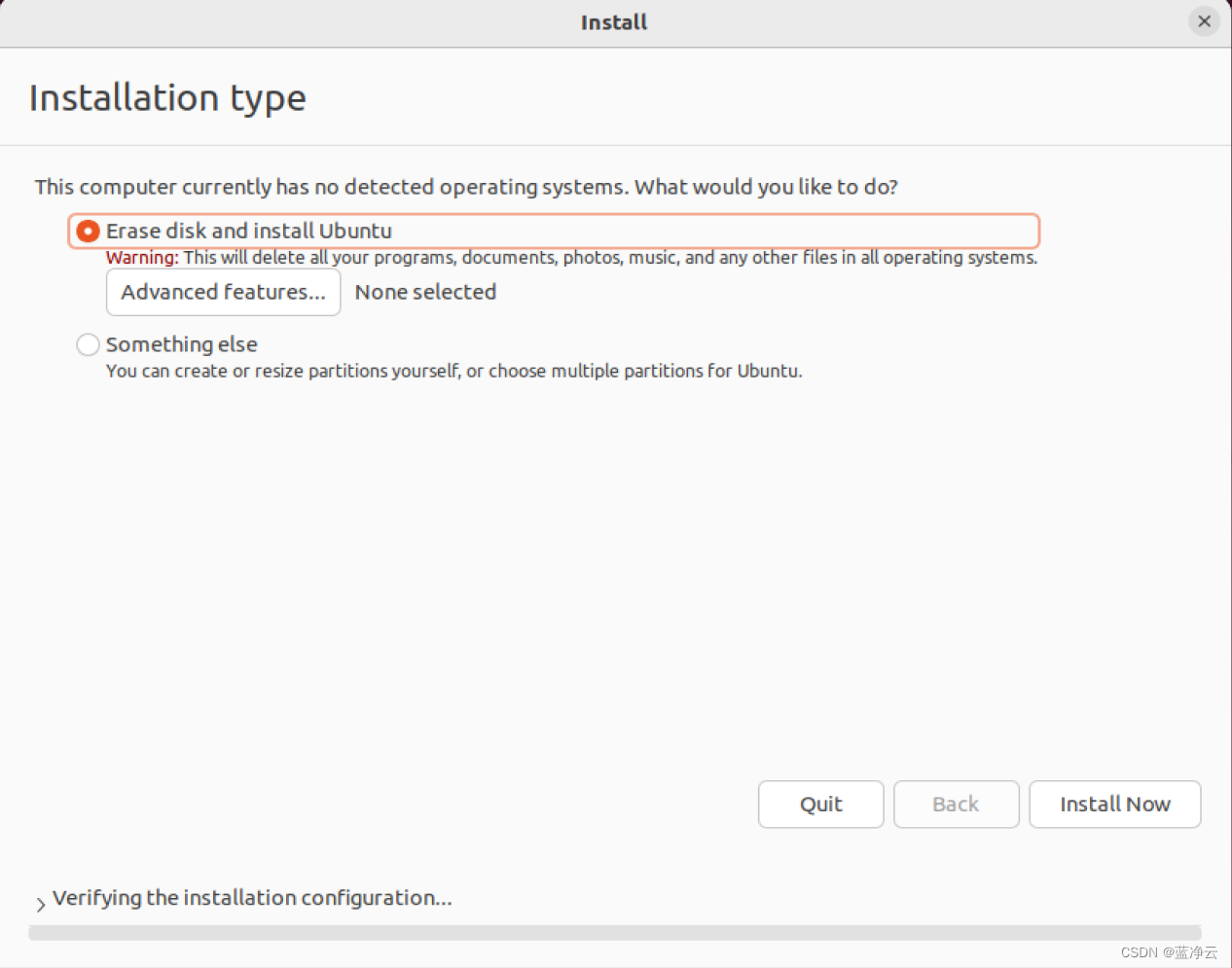
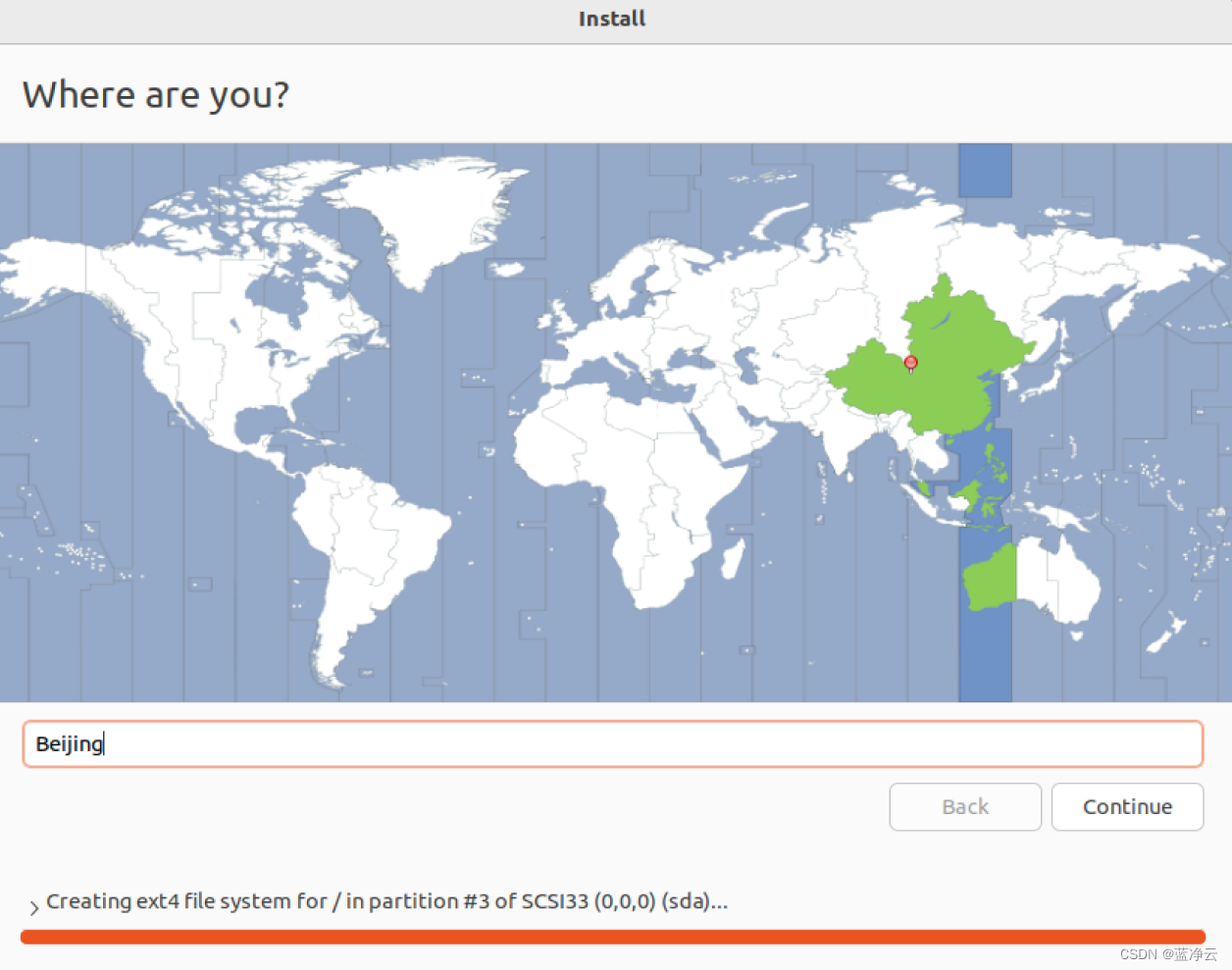
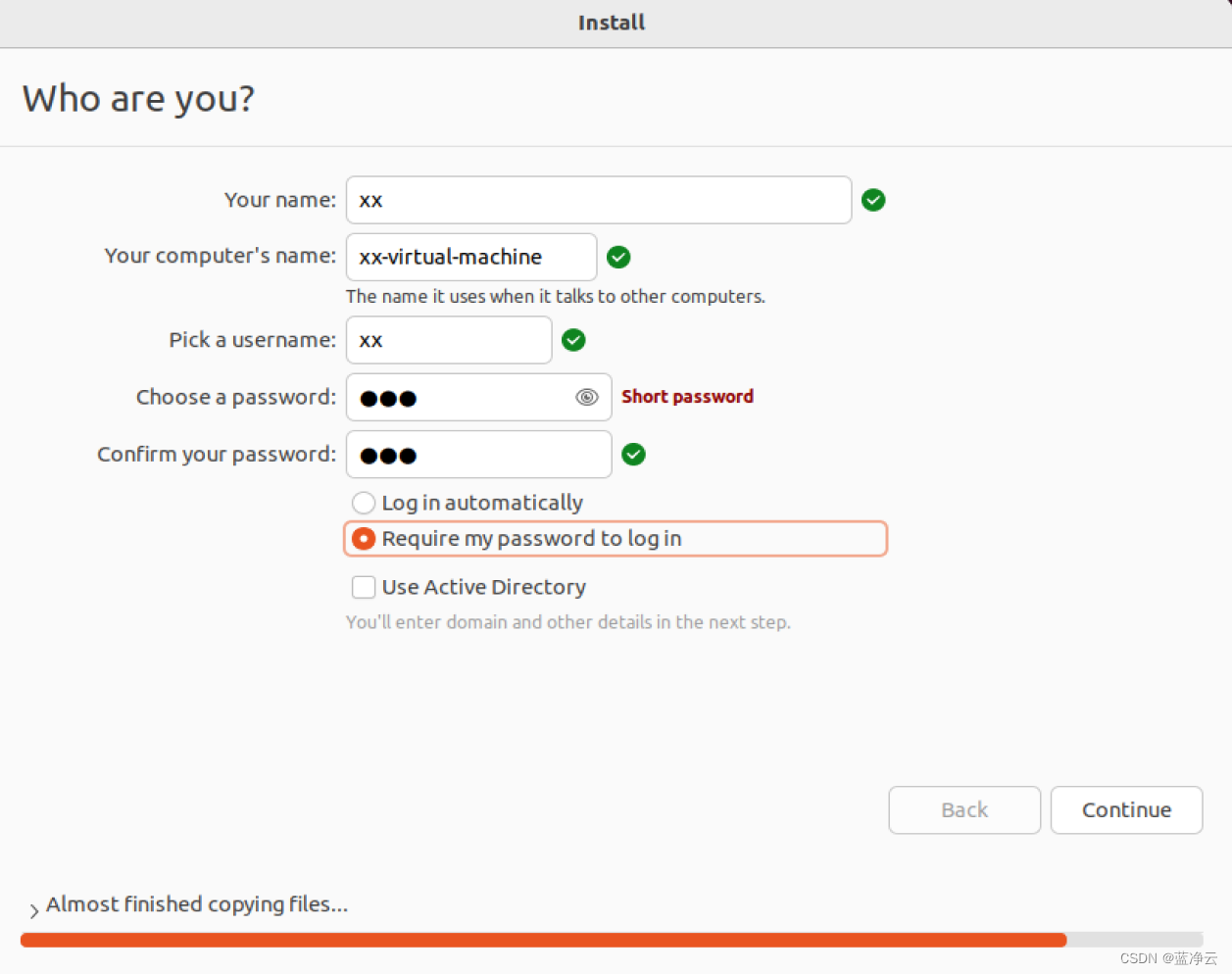
创建虚拟机
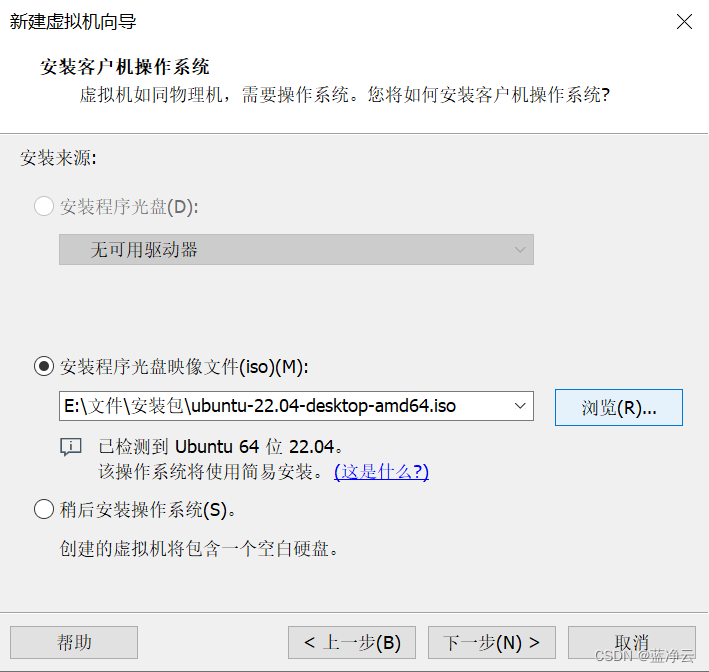
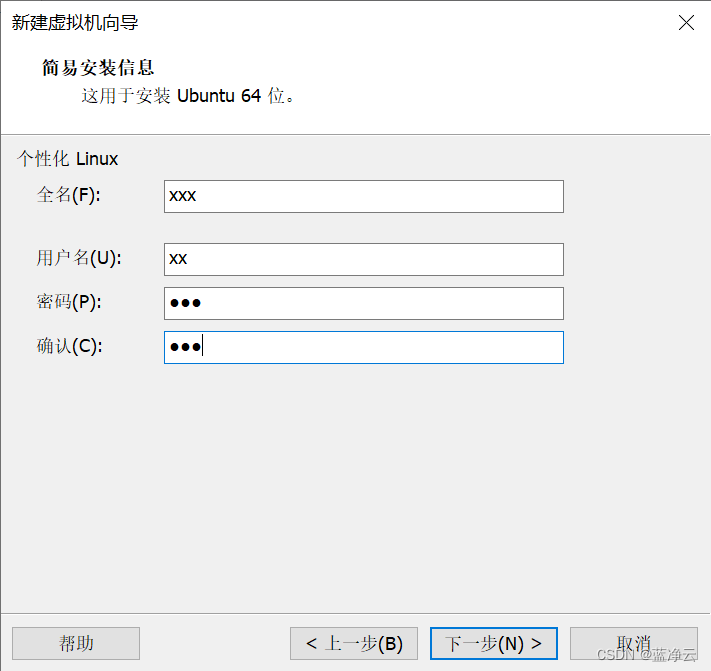
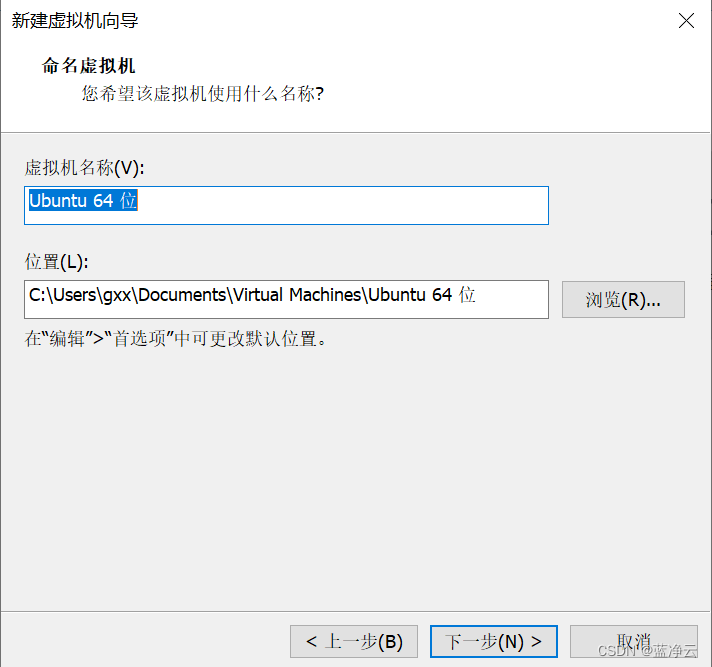
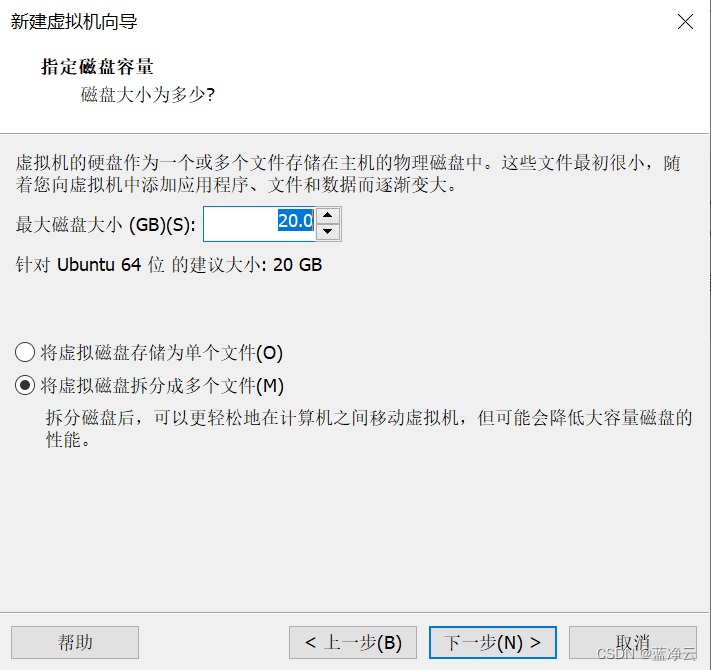
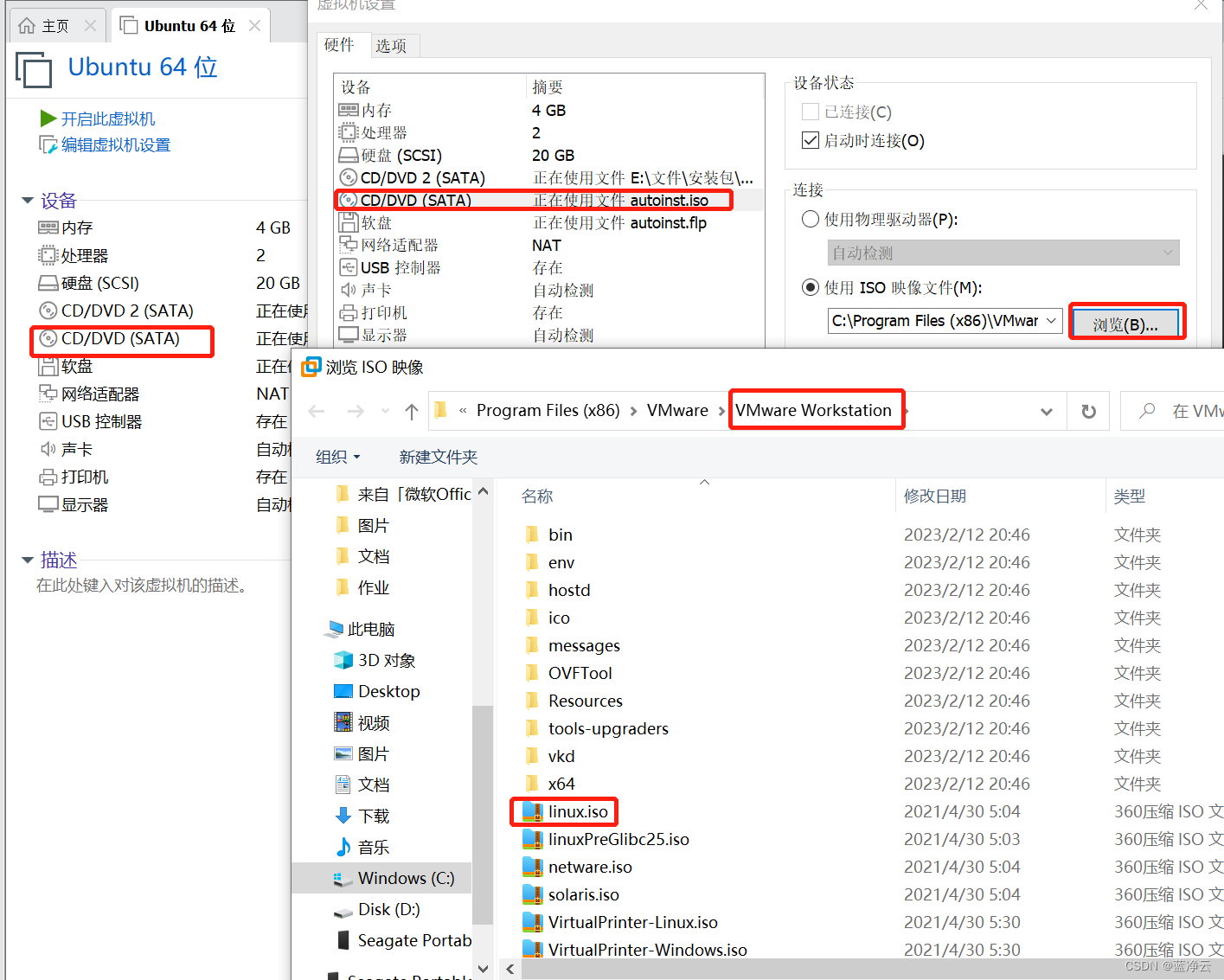
安装VMware Tools
在虚拟机里面没找到VMware Tools,而且重装VMware Tools是灰色,就尝试了一下 手动安装VMware Tools,先把虚拟机关机。
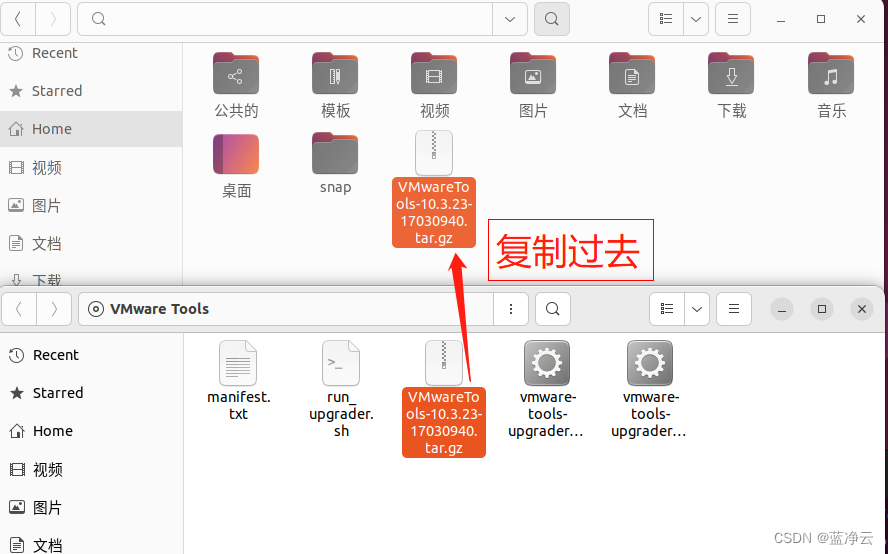
然后我就一路输入 y,然后突然间弹出什么出问题,哈哈哈哈,也不知道是啥毛病,先不管,点取消,哈哈哈哈哈,最终显示VMware tools安装成功了。
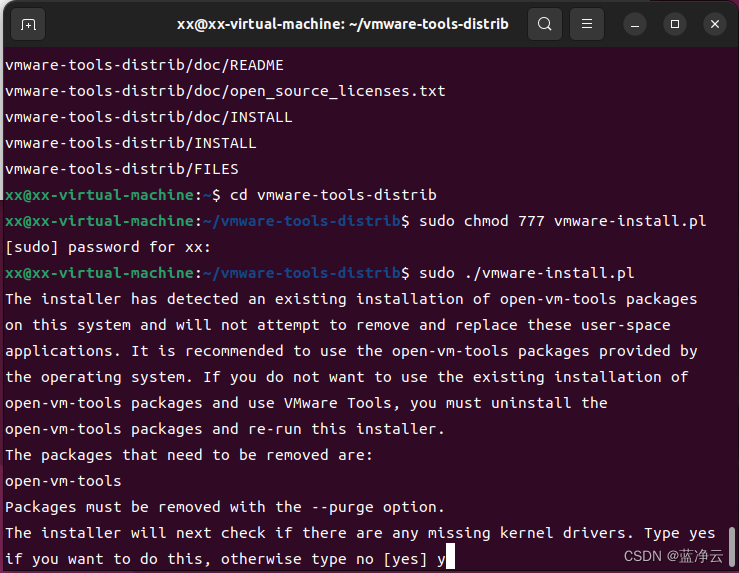
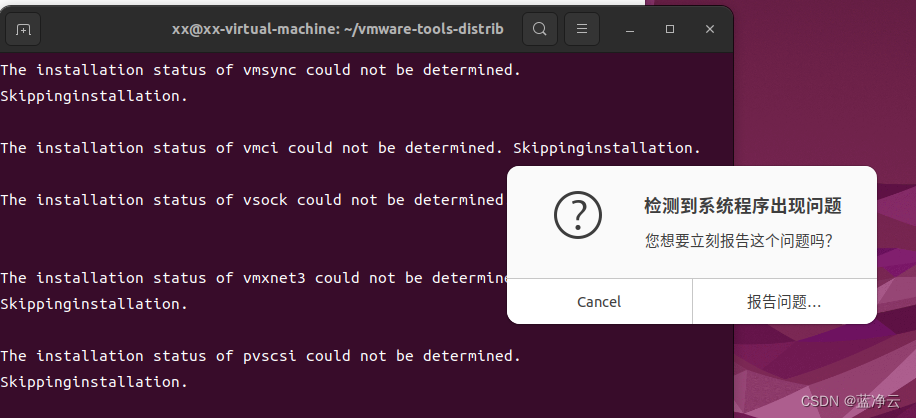
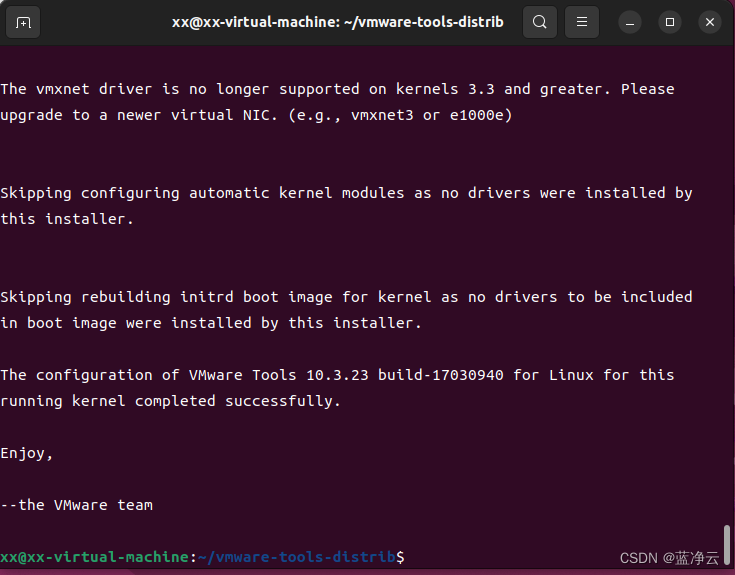
#cd到自己的用户目录
cd /home/xx
#解压安装包
tar -zxvf VMwareTools-10.3.23-17030940.tar.gz
#到解压后的文件夹里面
cd vmware-tools-distrib
#开个权限
sudo chmod 777 vmware-install.pl
#运行安装(其实就是perl安装包)
sudo ./vmware-install.pl
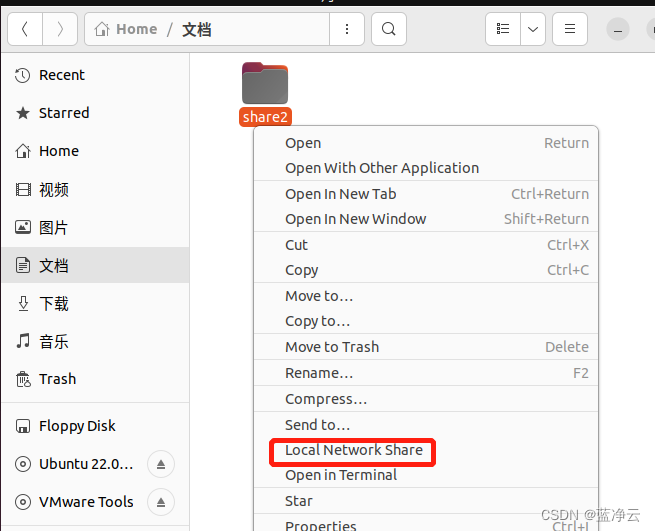
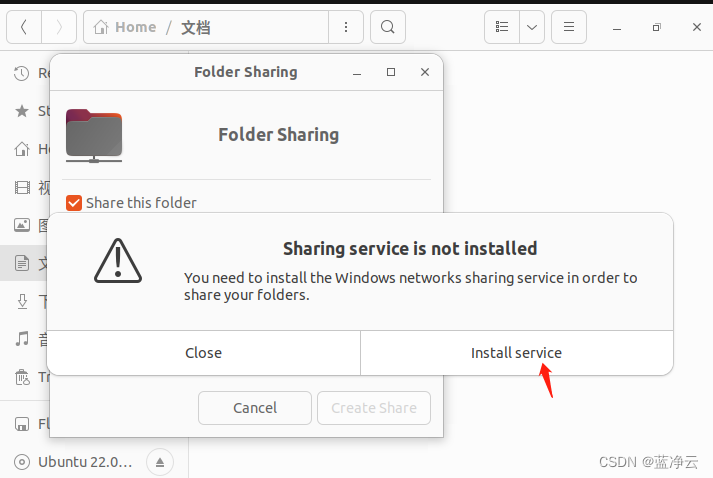
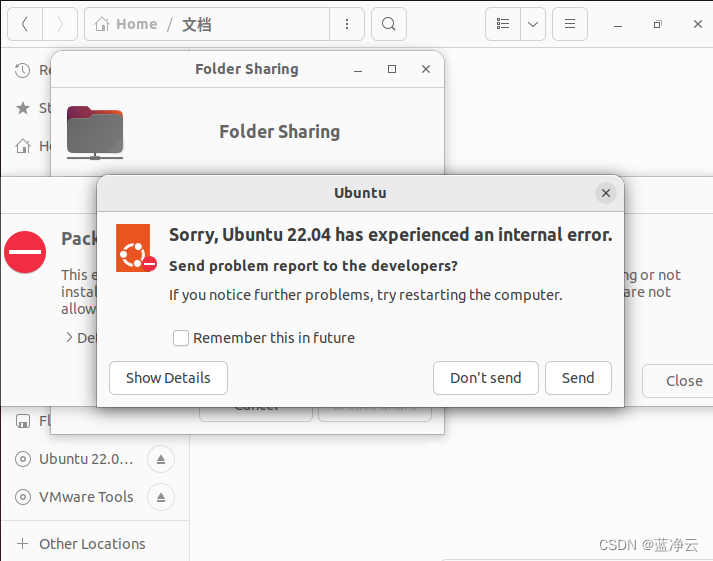
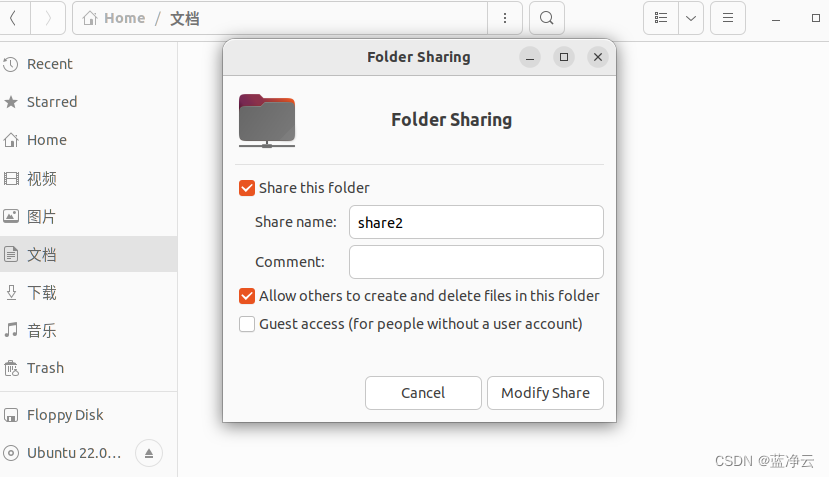
共享文件夹
为了方便,设置一下共享文件夹的。
新建一个文件夹,完成配置。
Details:
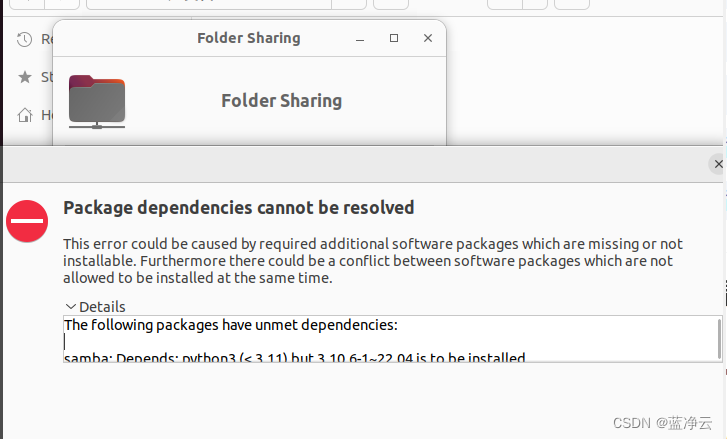
The following packages have unmet dependencies:
samba: Depends: python3 (< 3.11) but 3.10.6-1~22.04 is to be installed
Depends: samba-common (= 2:4.15.13+dfsg-0ubuntu1) but 2:4.15.13+dfsg-0ubuntu1 is to be installed
Depends: samba-common-bin (= 2:4.15.13+dfsg-0ubuntu1) but 2:4.15.13+dfsg-0ubuntu1 is to be installed
Depends: python3:any but it is a virtual package
Depends: libwbclient0 (= 2:4.15.13+dfsg-0ubuntu1) but 2:4.15.13+dfsg-0ubuntu1 is to be installed
Depends: samba-libs (= 2:4.15.13+dfsg-0ubuntu1) but 2:4.15.13+dfsg-0ubuntu1 is to be installed
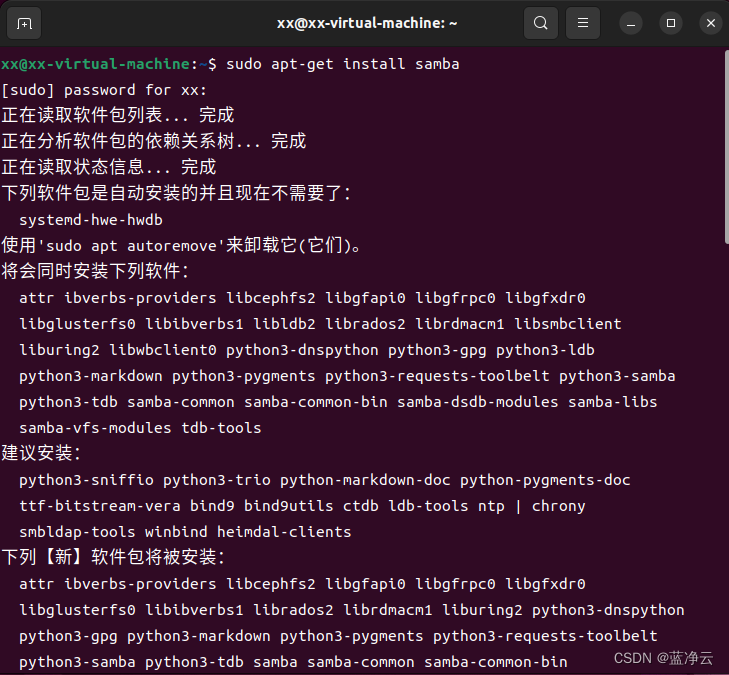
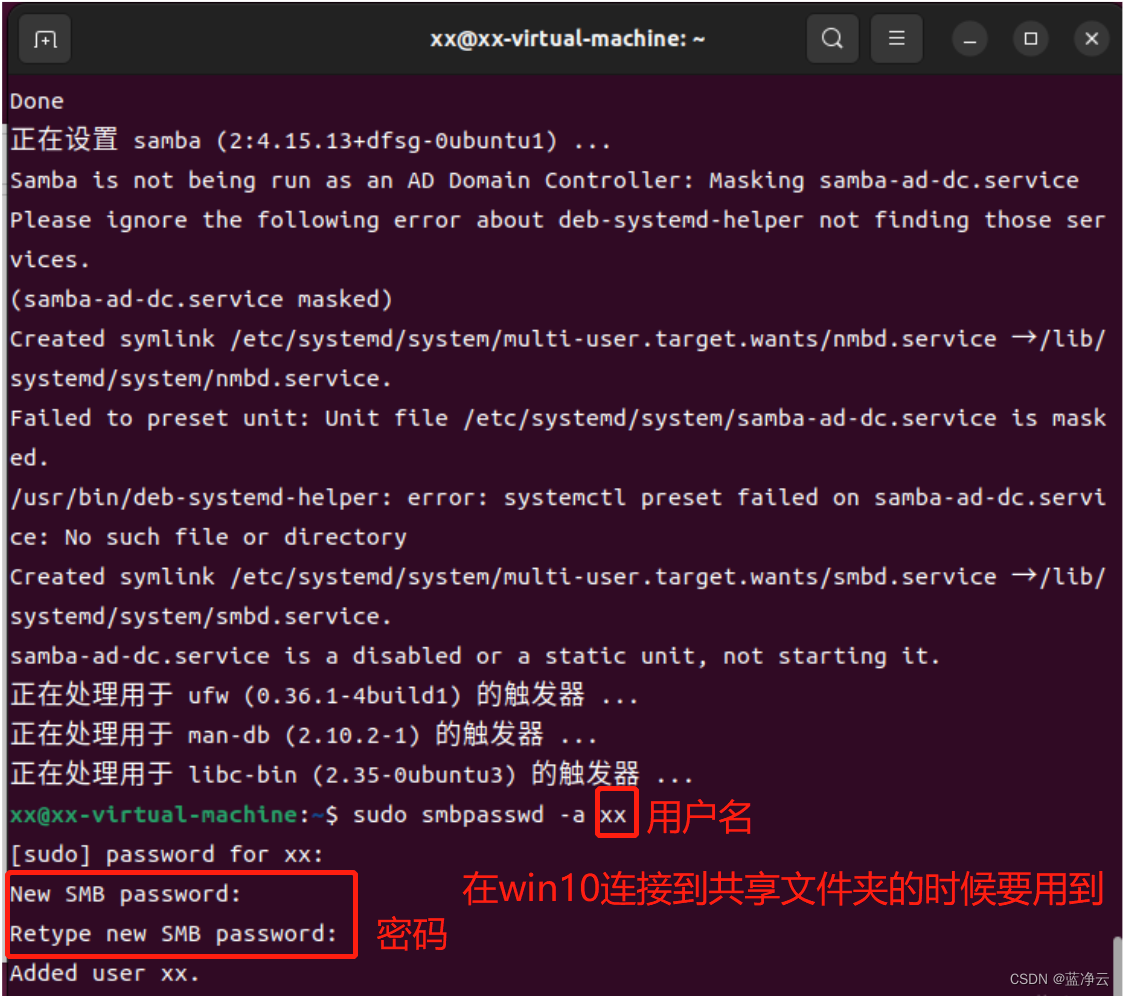
sudo apt-get install samba
sudo smbpasswd -a xx
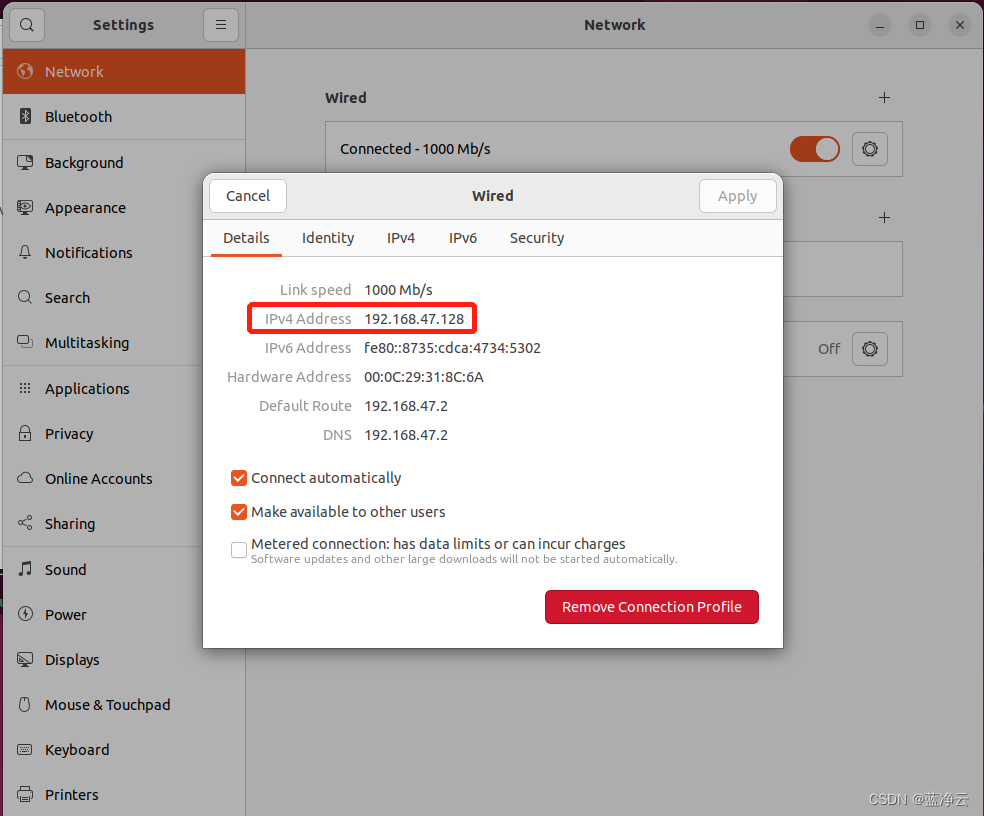
win+r打开
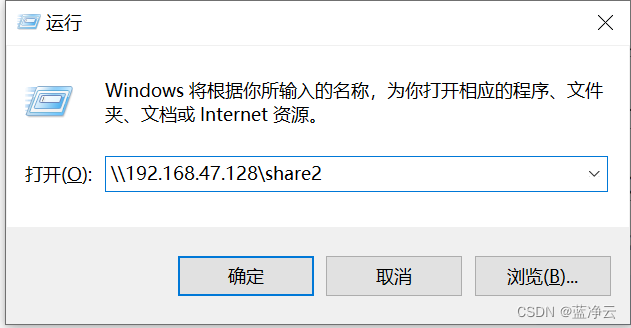
然后弹出来一个框,输入刚刚设置的用户名和密码(忘记截图了)
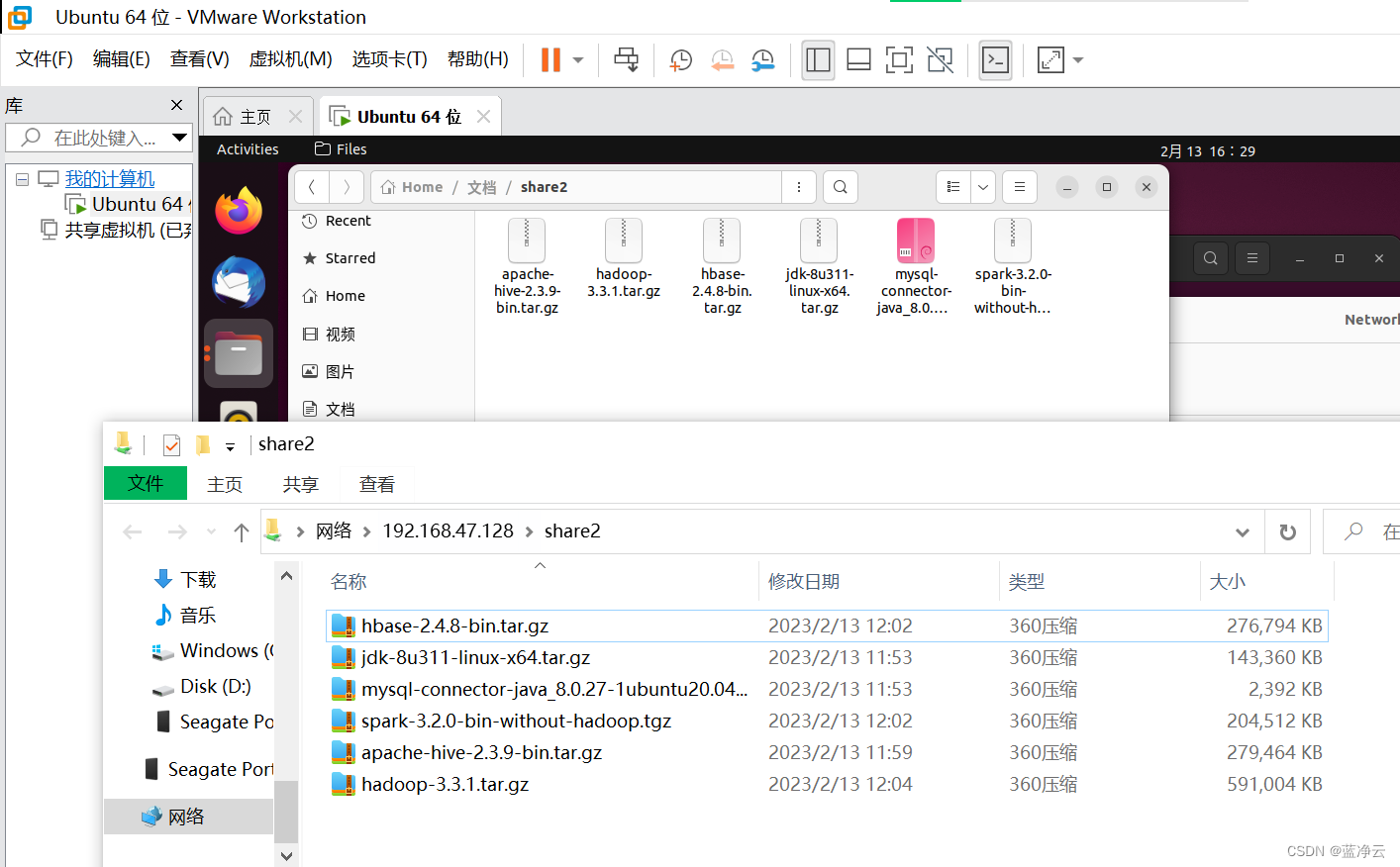
然后就可以看到win10和Ubuntu都可以访问到文件夹share2 。
安装Java
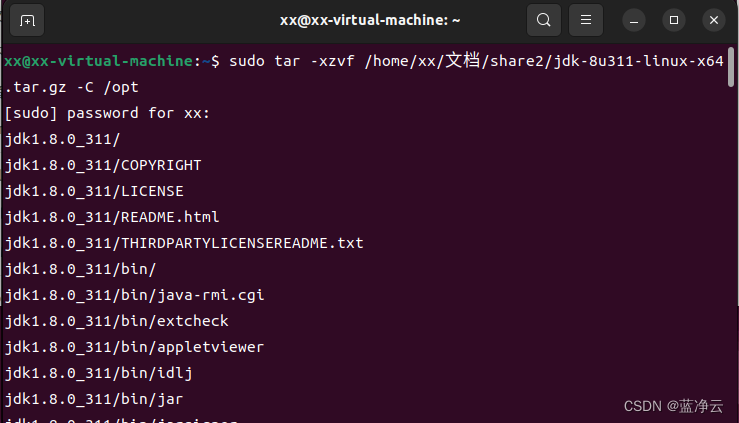
#将/home/xx/文档/share2目录下`jdk-8u311-linux-x64.tar.gz`解压缩到`/opt`目录下
sudo tar -xzvf /home/xx/文档/share2/jdk-8u311-linux-x64.tar.gz -C /opt
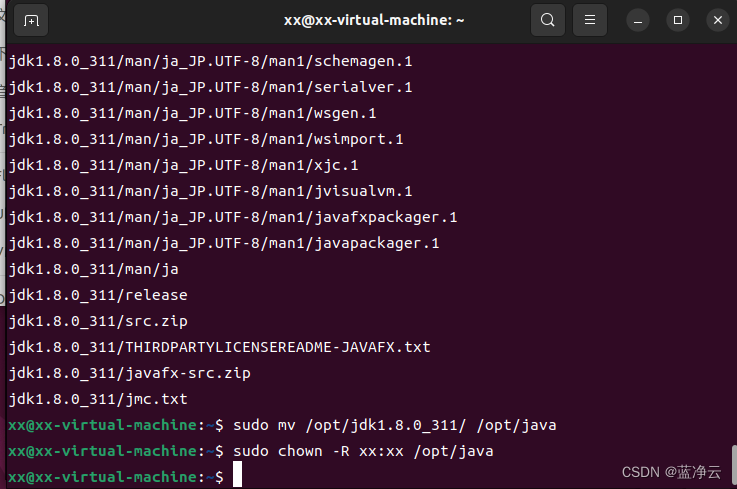
#将jdk1.8.0_311目录重命名为java,执行如下命令:
sudo mv /opt/jdk1.8.0_311/ /opt/java
#修改java目录的所属用户:
sudo chown -R xx:xx /opt/java
修改系统环境变量
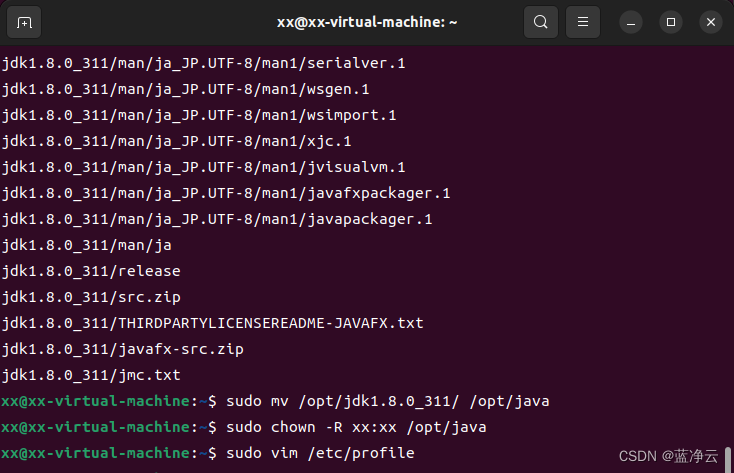
#打开/etc/profile文件
sudo vim /etc/profile
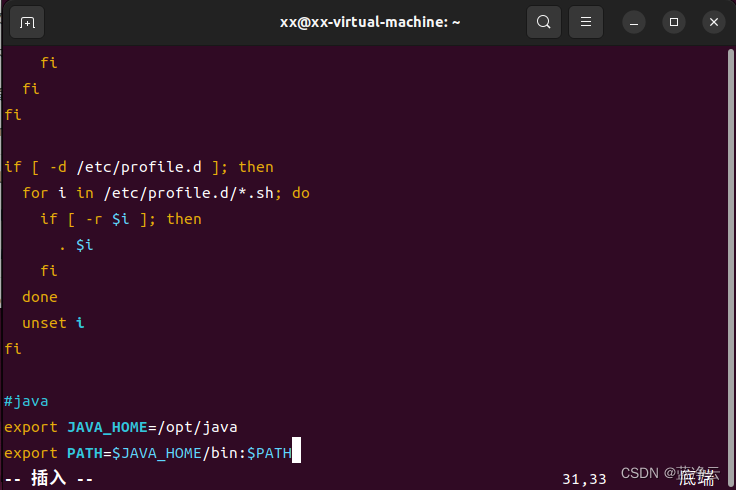
# 在文件后面添加下面这段
#java
export JAVA_HOME=/opt/java
export PATH=$JAVA_HOME/bin:$PATH
输入i 回车,进入插入模式,在该文件末尾,添加内容;
按下esc键,退出编辑;
输入 :wq 保存退出。
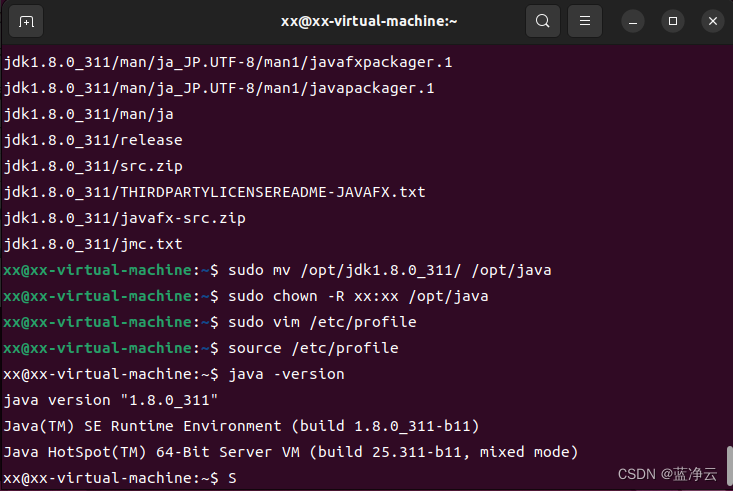
#输入以下命令,使得环境变量生效
source /etc/profile
#执行完上述命令之后,可以通过`JAVA_HOME`目录找到`java`可使用的命令。 通过查看版本号的命令验证是否安装成功
java -version
SSH登录权限设置
对于Hadoop的伪分布和全分布而言,Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程可以通过SSH登录来实现。Hadoop并没有提供SSH输入密码登录的形式,因此,为了能够顺利登录每台机器,需要将所有机器配置为名称节点,可以通过SSH无密码的方式登录它们。
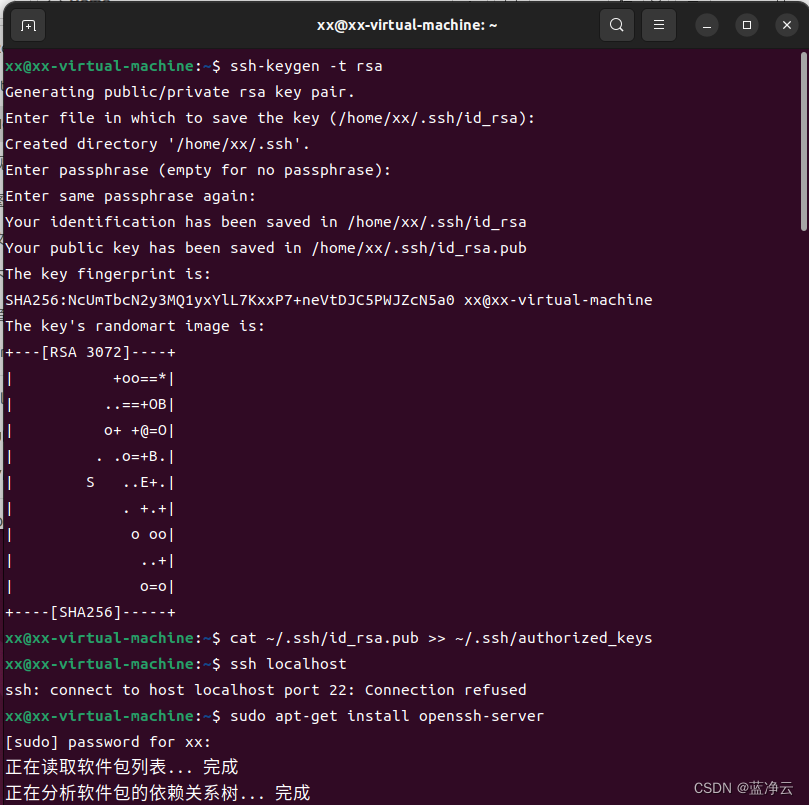
# 为了实现SSH无密码登录方式,首先需要让NameNode生成自己的SSH密钥
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
#将公共密钥发送给集群中的其他机器,将id_dsa.pub中的内容添加到需要SSH无密码登录的机器的~/ssh/authorized_keys目录下
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#或者执行以下命令:
cat /home/datawhale/.ssh/id_rsa.pub >> /home/datawhale/.ssh/authorized_keys
#ssh拒绝连接,安装
sudo apt-get install openssh-server
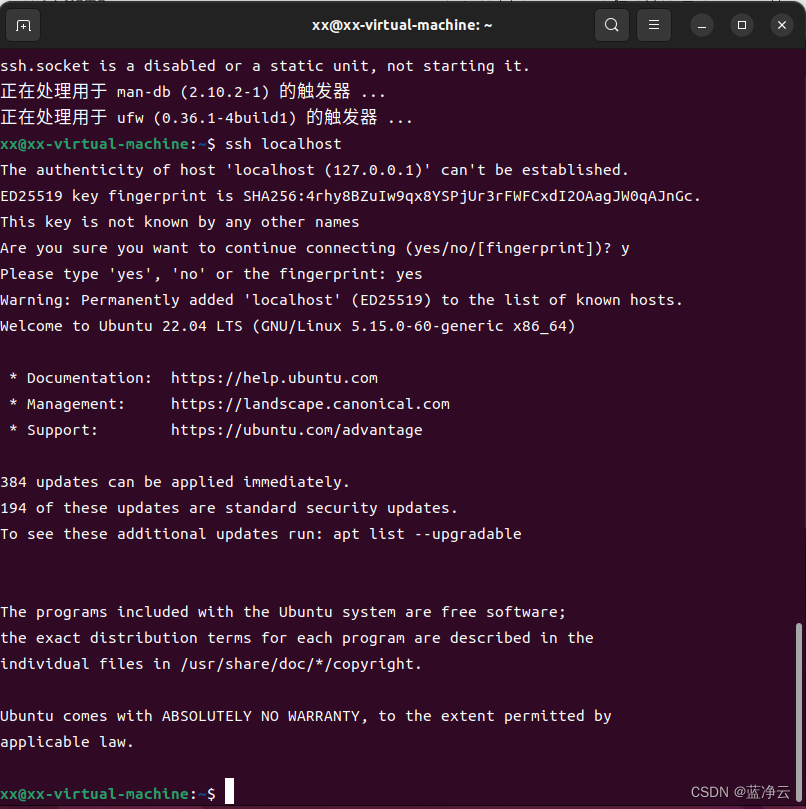
#通过ssh localhost命令来检测一下是否需要输入密码。
ssh localhost
Hadoop伪分布式安装
安装单机版Hadoop
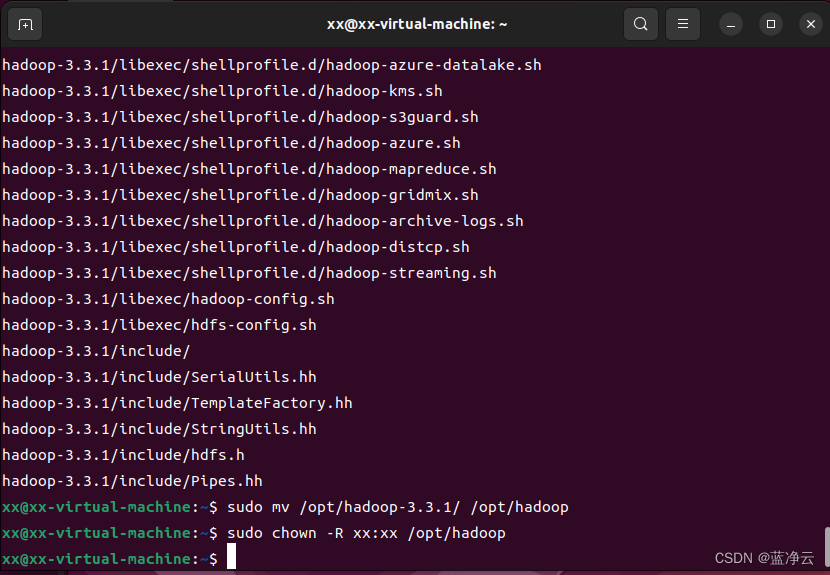
将hadoop-3.3.1.tar.gz放置到自己喜欢的位置,如/home/xx/文档/share2文件夹下,注意,文件夹的用户和组必须都为hadoop。
# 安装Hadoop
# 将`hadoop-3.3.1.tar.gz`解压缩到`/opt`目录下
sudo tar -xzvf /home/xx/文档/share2/hadoop-3.3.1.tar.gz -C /opt/
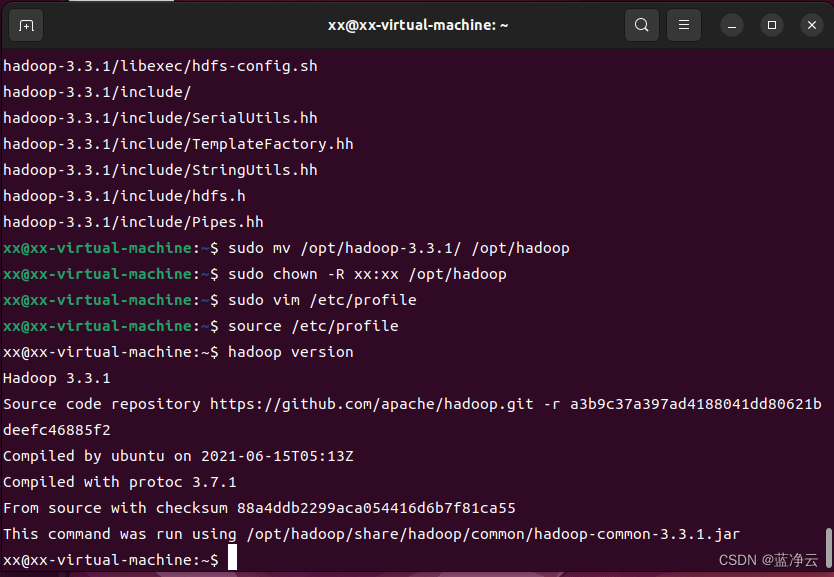
# 为了便于操作,我们也将`hadoop-3.3.1`重命名为`hadoop`
sudo mv /opt/hadoop-3.3.1/ /opt/hadoop
# 修改hadoop目录的所属用户和所属组
sudo chown -R xx:xx /opt/hadoop
# 修改系统环境变量
# 打开`/etc/profile`文件
sudo vim /etc/profile
输入i 回车,进入插入模式,在该文件末尾,添加内容;
按下esc键,退出编辑;
输入 :wq 回车,保存退出。
# 在文件末尾,添加如下内容
#hadoop
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
# 使得环境变量生效
source /etc/profile
# 查看版本号命令验证是否安装成功
hadoop version
# 对于单机安装,首先需要更改`hadoop-env.sh`文件,用于配置Hadoop运行的环境变量
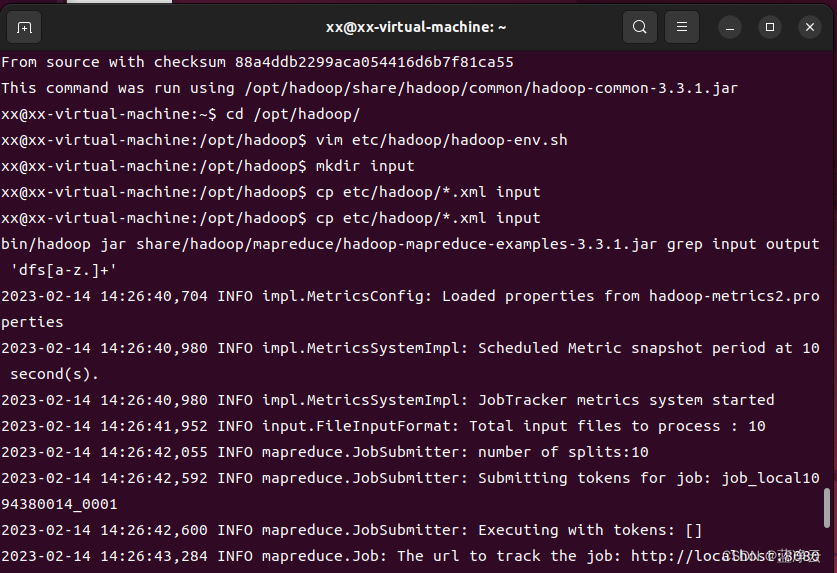
cd /opt/hadoop/
vim etc/hadoop/hadoop-env.sh
输入i 回车,进入插入模式,在该文件末尾,添加内容;
按下esc键,退出编辑;
输入 :wq 回车,保存退出。
# 在文件末尾,添加如下内容
export JAVA_HOME=/opt/java/
Hadoop文档中还附带了一些例子来供我们测试,可以运行WordCount的示例,检测一下Hadoop安装是否成功。运行示例的步骤如下:
- 在
/opt/hadoop/目录下新建input文件夹,用来存放输入数据; - 将
etc/hadoop/文件夹下的配置文件拷贝至input文件夹中; - 在
hadoop目录下新建output文件夹,用于存放输出数据; - 运行
wordCount示例 - 查看输出数据的内容。
mkdir input
cp etc/hadoop/*.xml input
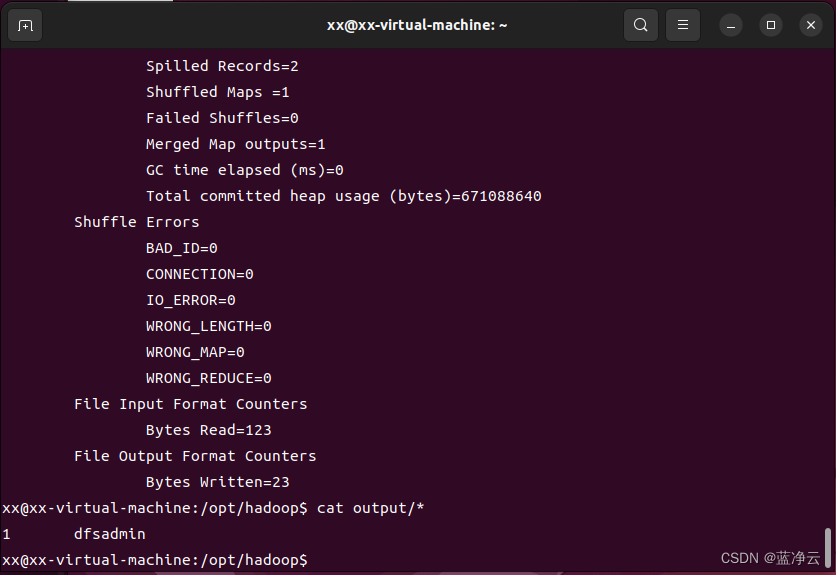
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep input output 'dfs[a-z.]+'
cat output/*
输出结果意味着,在所有的配置文件中,只有一个符合正则表达式dfs[a-z.]+的单词,输出结果。
Hadoop伪分布式安装
伪分布式安装是指在一台机器上模拟一个小的集群。当Hadoop应用于集群时,不论是伪分布式还是真正的分布式运行,都需要通过配置文件对各组件的协同工作进行设置。
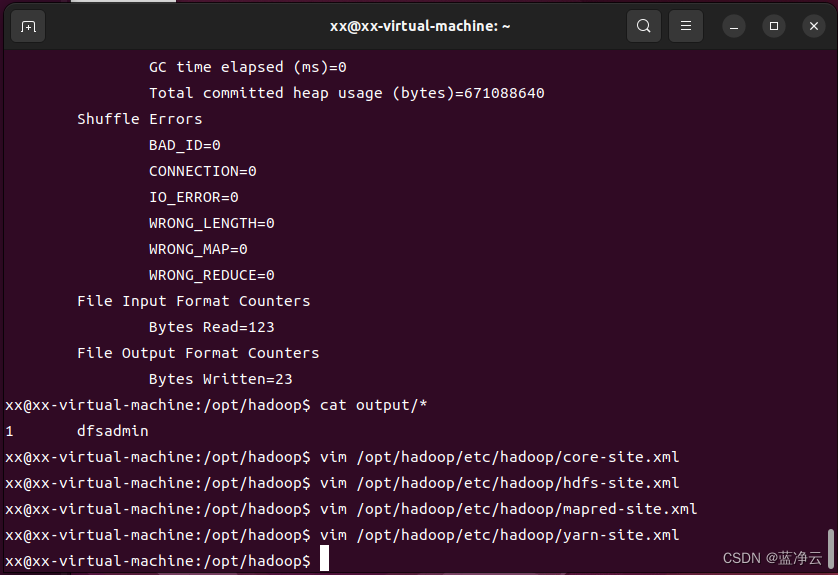
对于伪分布式配置,我们需要修改core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml这4个文件。
# 打开`core-site.xml`文件
vim /opt/hadoop/etc/hadoop/core-site.xml
输入i 回车,进入插入模式,在该文件末尾,添加内容;
按下esc键,退出编辑;
输入 :wq 回车,保存退出。
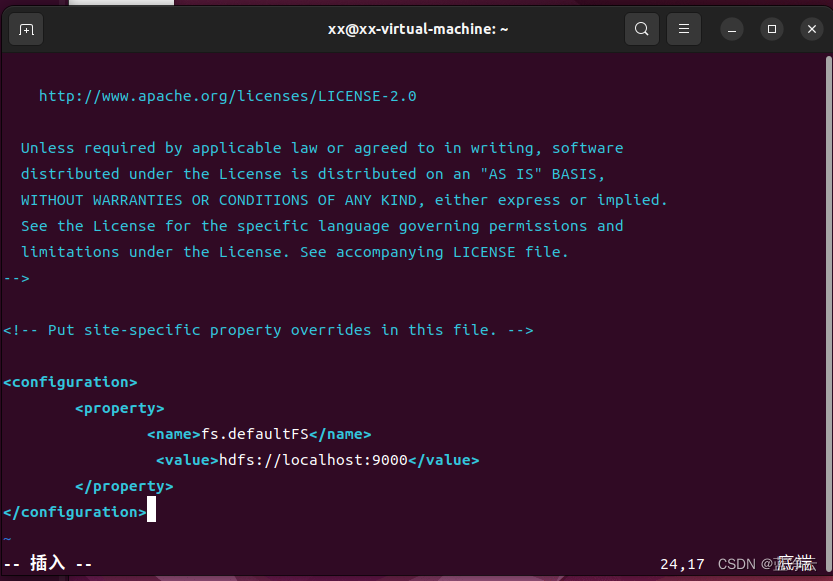
添加下面配置到<configuration>与</configuration>标签之间
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
core-site.xml配置文件的格式十分简单,<name>标签代表了配置项的名字,<value>项设置的是配置的值。对于该文件,我们只需要在其中指定HDFS的地址和端口号,端口号按照官方文档设置为9000即可。
# 打开`hdfs-site.xml`文件
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
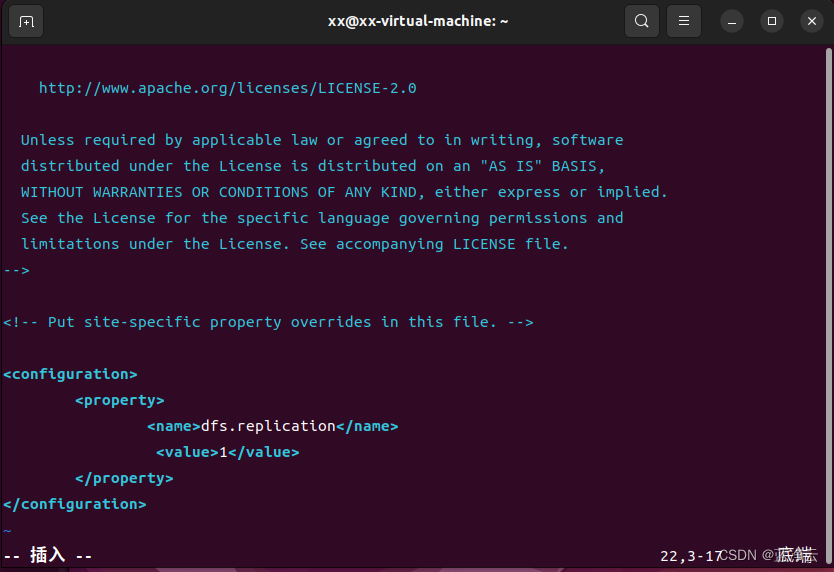
# 添加下面配置到`<configuration>与</configuration>`标签之间
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
对于hdfs-site.xml文件,我们设置replication值为1,这也是Hadoop运行的默认最小值,用于设置HDFS文件系统中同一份数据的副本数量。
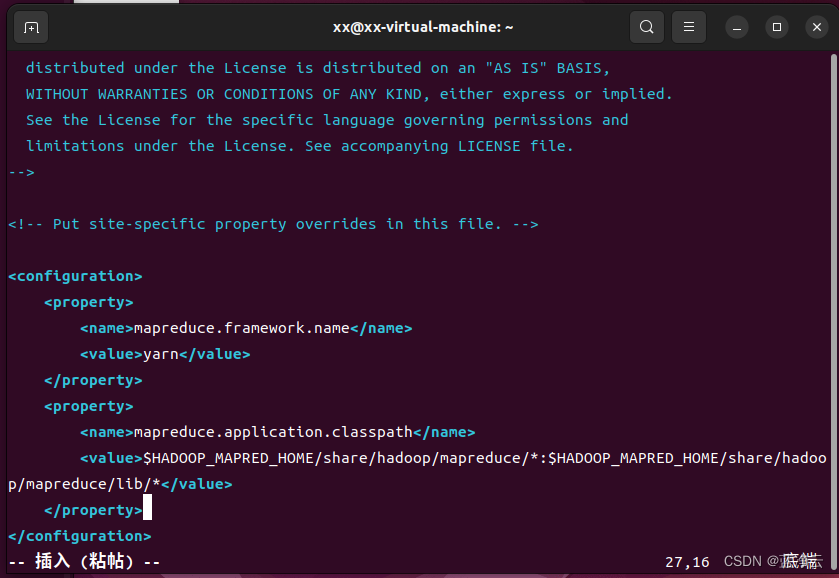
# 打开`mapred-site.xml`文件
vim /opt/hadoop/etc/hadoop/mapred-site.xml
# 添加下面配置到`<configuration>与</configuration>`标签之间
```html
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
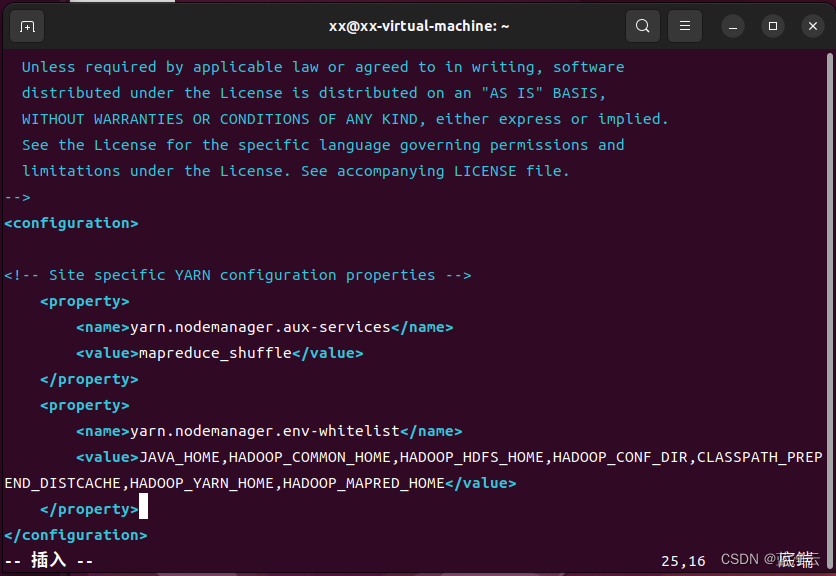
# 修改yarn-site.xml文件配置
vim /opt/hadoop/etc/hadoop/yarn-site.xml
# 添加下面配置到`<configuration>与</configuration>`标签之间
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
;对于本实验,通过上述配置后,就已经满足运行要求了。这里再给出一个官方文档的详细地址,感兴趣的小伙伴可以查看文档配置的其他项(网址如下:https://hadoop.apache.org/docs/stable )
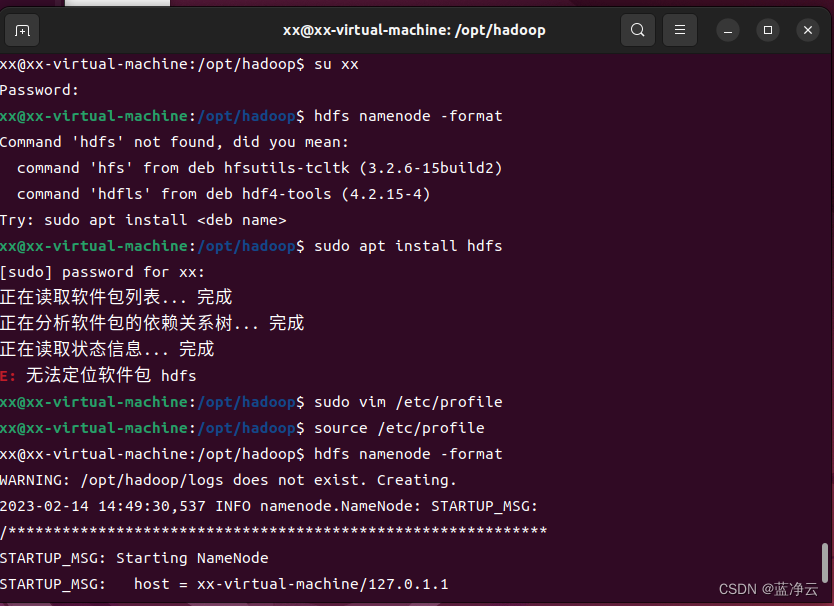
在配置完成后,首先需要初始化文件系统,由于Hadoop的很多工作是在自带的 HDFS文件系统上完成的,因此,需要将文件系统初始化之后才能进一步执行计算任务。执行初始化的命令如下:
# 格式化分布式文件系统
hdfs namenode -format
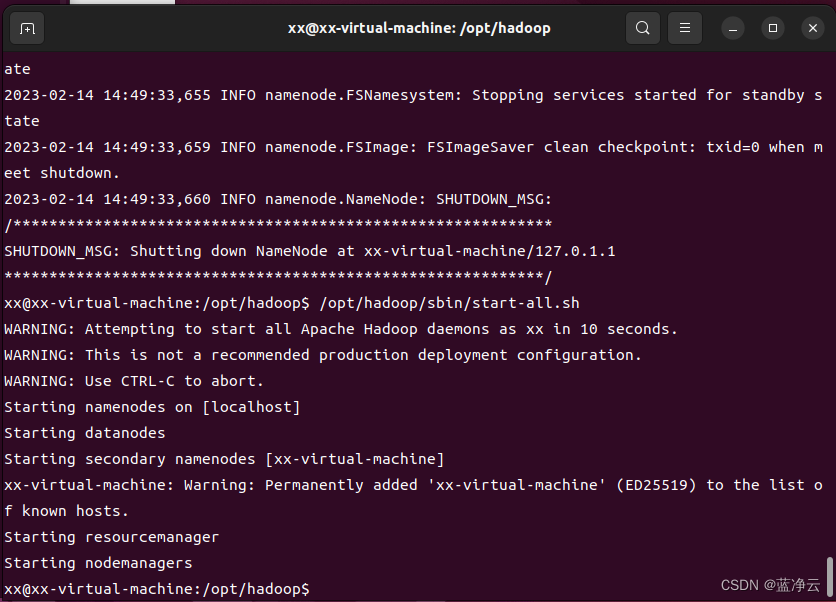
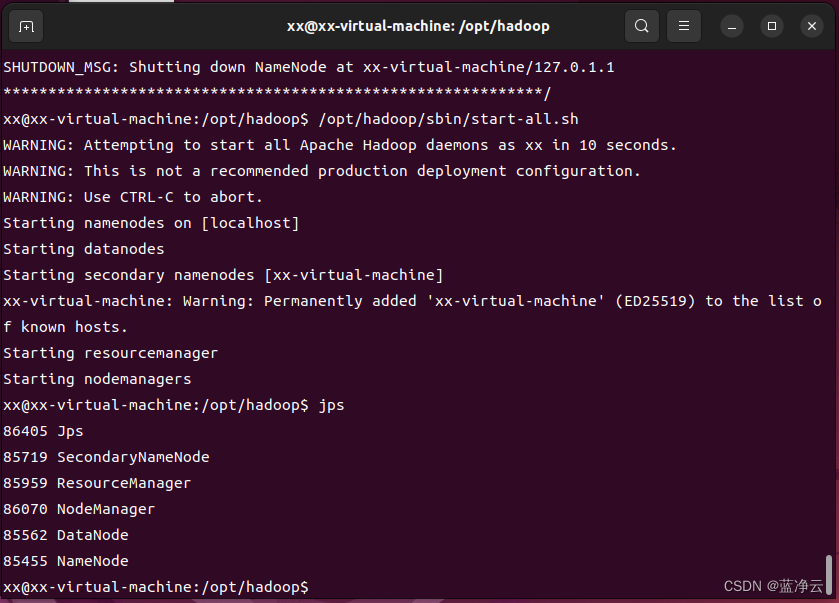
# 启动Hadoop的所有进程,可以通过提示信息得知,所有的启动信息都写入到对应的日志文件。如果出现启动错误,则可以查看相应的错误日志
/opt/hadoop/sbin/start-all.sh
# 查看Hadoop进程:可以查看所有的`Java`进程
jps
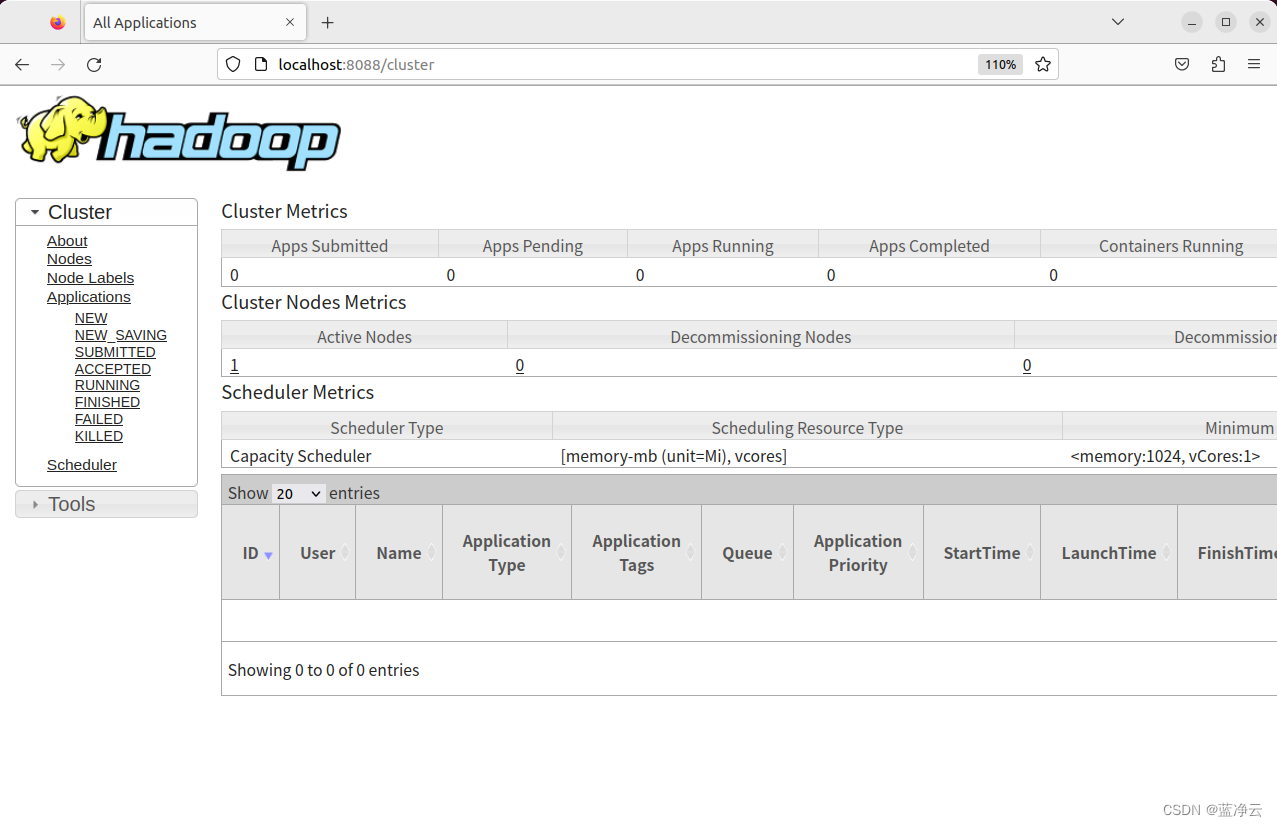
Hadoop WebUI管理界面
可以通过http://localhost:8088访问Web界面,查看Hadoop的信息。
测试HDFS集群以及MapReduce任务程序
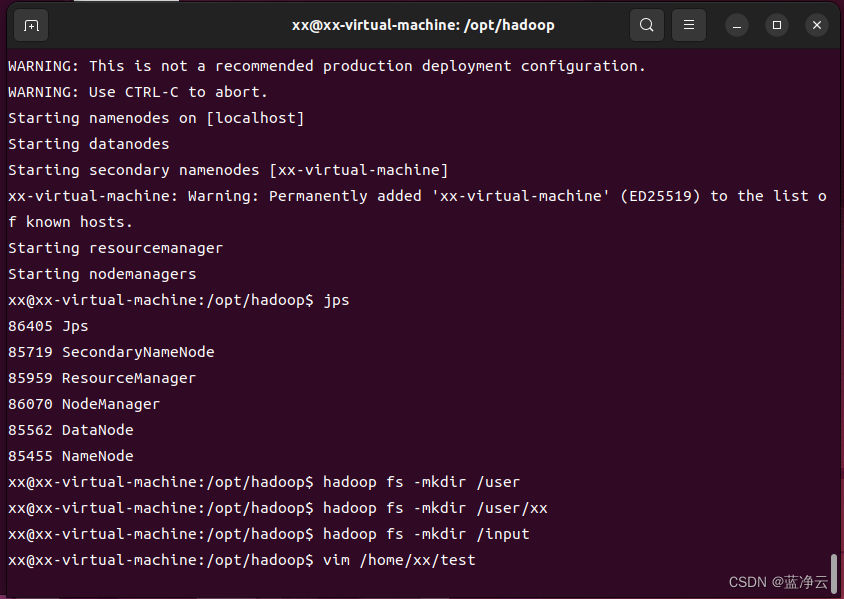
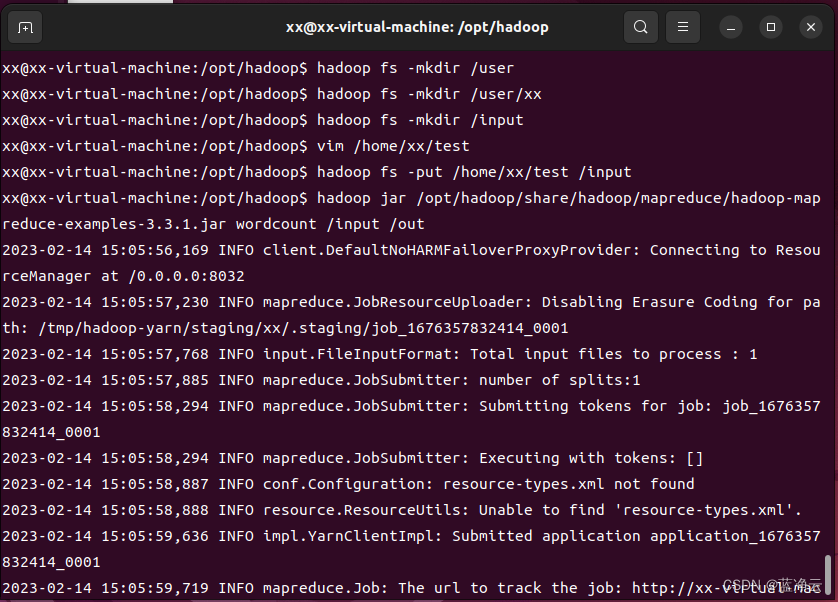
利用Hadoop自带的WordCount示例程序进行检查集群,并在主节点上进行如下操作,创建执行MapReduce任务所需的HDFS目录:
hadoop fs -mkdir /user
hadoop fs -mkdir /user/xx
hadoop fs -mkdir /input
创建测试文件
vim /home/xx/test
输入i 回车,进入插入模式,在该文件末尾,添加内容;
按下esc键,退出编辑;
输入 :wq 回车,保存退出。
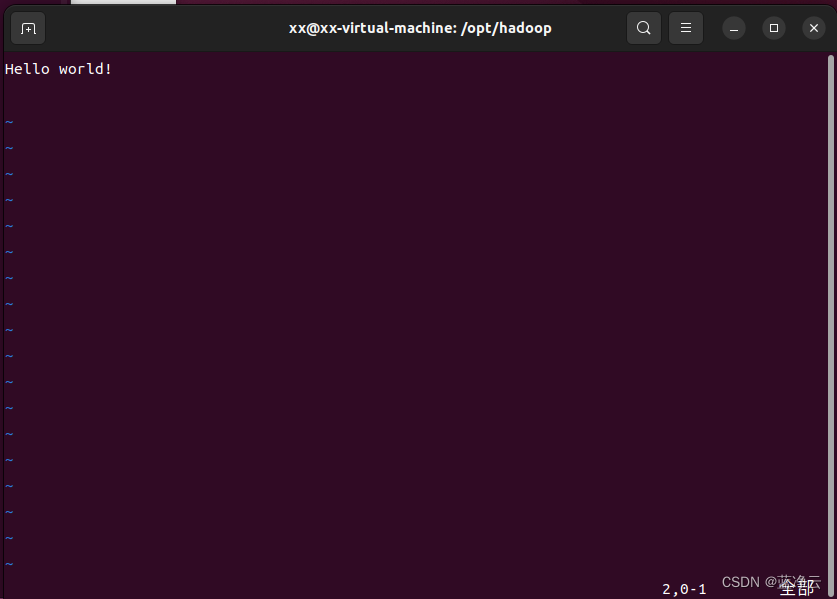
在test文件中,添加以下内容:
Hello world!
# 将测试文件上传到Hadoop HDFS集群目录
hadoop fs -put /home/xx/test /input
# 执行wordcount程序
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /out
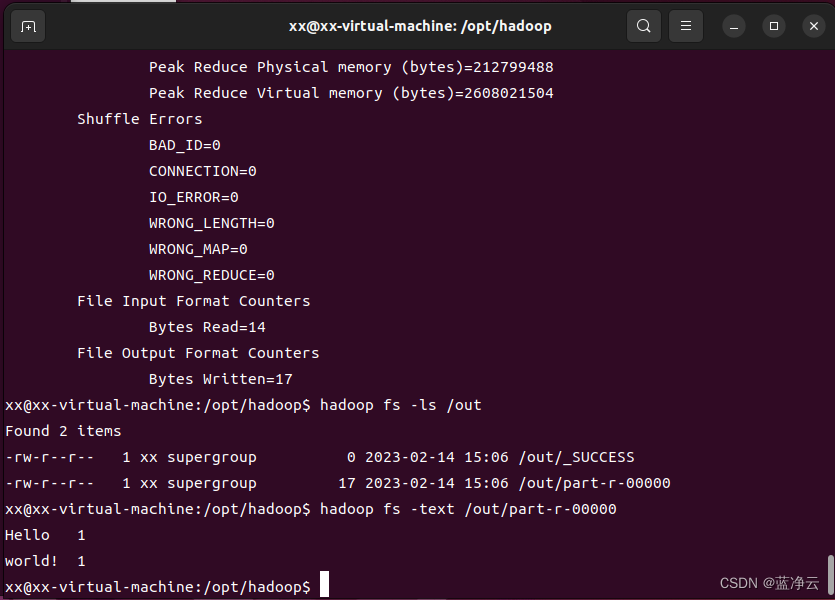
# 查看执行结果:
hadoop fs -ls /out
# 可以看到,结果中包含`_SUCCESS`文件,表示Hadoop集群运行成功。
# 查看具体的输出结果
hadoop fs -text /out/part-r-00000
学习参考
https://github.com/datawhalechina/juicy-bigdata
![[CVPR‘22] EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks](https://img-blog.csdnimg.cn/1d57395630814531971c1b44b12e7aee.png)
![GDI+绘图轻松入门[6]-路径变形和表盘的绘制](https://img-blog.csdnimg.cn/ea33b5ce2d7844ef8cc3668e73bcc751.png)