- paper: https://nvlabs.github.io/eg3d/media/eg3d.pdf
- project: EG3D: Efficient Geometry-aware 3D GANs
- code: GitHub - NVlabs/eg3d
总结:
- 本文提出一种hybrid explicit-implicit 3D representation: tri-plane hybrid 3D representation,该方法不仅有更强的表达能力,速度更快,内存开销更小。
- 同时,为解决多视角不一致问题,引入相机参数矩阵作为StyleGANv2生成器、超分模型、Volume Rendering的控制条件。
- 最后,为解决超分模型导致的信息丢失问题,本文提出dual discrimination strategy,使得超分前后图像保持一致。
skirt the cimputational constraints
inherit their efficiency and expressiveness
xx has started to gain momentum as well
目录
摘要
引言
贡献
近期工作
Neural scene representation and rendering.
Generative 3D-aware image synthesis.
Tri-plane hybrid 3D representation
3D GAN framework
CNN generator backbone and rendering
Dual discrimination
Experiments and results
Ablation study
Application
摘要
- 研究如何基于单视角2D图片,通过无监督方法,生成高质量、多视角一致的3D形状;
- 现有3D GAN存在问题:1)计算开销大;2)不具有3D一致性(3D-consistent);
- 本文提出:1)expressive hybrid explicit-implicit network architecture:提速、减小计算开销;2)decoupling feature generation and neural rendering:可以借助sota 2D GAN,例如:StyleGAN2。
- 在FFHQ和AFHQ Cats的3D-aware synthesis任务上达到sota。
引言
- 现有2D GAN无法显式地建模潜在的3D场景;
- 近期3D GAN,开始解决:1)多视角一致的图片生成;2)无需多视角图片和几何监督,提取3D形状。但是3D GAN生成的图片质量和分辨率仍然远逊于2D GAN。还有一个问题是,目前3D GAN和Neural Rendering方法计算开销大。
- 3D GAN通常由两部分组成:1)生成网络中的3D结构化归纳偏置;2)neural rendering engine提供视角一致性结果。其中,归纳偏置可以被建模为:显式的体素网格或隐式的神经表达。但受限于计算开销,这两种表达方式都不适用于训练高分辨率的3D GAN。目前常用的方法是超分,但超分又会牺牲视觉连续性和3D形状的质量。
- 本文提出:1)hybrid explicit-implicit 3D representation由于提速、减小计算开销;2)dual discrimination strategy由于保留输出和neural rendering的一致性;3)对生成器引入pose-based conditioning,解耦pose相关属性,例如人脸表情系数;4)本文框架将特征生成从neural rendering中解耦出来,使得框架可以受益于sota 2D GAN,例如:StyleGAN2。
贡献
- 提出一种tri-plane-based 3D GAN框架。在保持效果的情况下,提速明显;
- 提出一种3D GAN训练策略dual discrimination,用于保持多视角一致性;
- 提出generator pose conditioning,建模pose相关的属性,例如:表情。
- 在FFHQ和AFHQ Cats的3D-aware图片生成中取得sota结果。
近期工作
Neural scene representation and rendering.
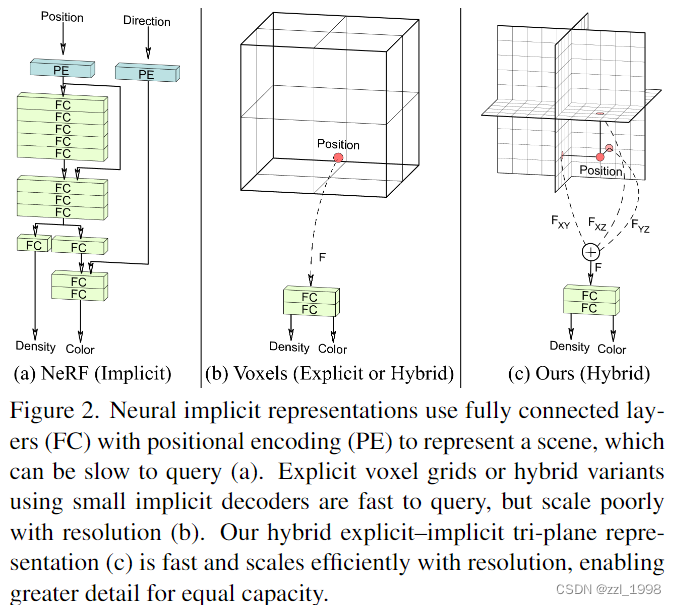
- 显示表达(图b),例如:discrete voxel grids。优点是fast to evaluate,缺点是需要大量的内存开销大;
- 隐式表达(图a):例如:neural rendering。优点是内存使用高效,缺点是slow to evaluate。
- 局部隐式表达和混合显-隐式表达,则兼具了两者优点。
- 受此启发,本文设计了hybrid explicit-implicit 3D-aware network(图c):用tri-plane representation去显示存储沿坐标轴对齐的特征,而特征则是被通过特征解码器隐式的渲染为体素。
Generative 3D-aware image synthesis.
- Mesh-based approaches;Voxel-based GANs,内存开销大,通常需要使用超分,但超分会导致视角不一致;Block-based sparse volume representations:泛化性不好。Fully implicit representation networks,但测试很慢。
- 和StyleGAN2-based 2.5D GAN的区别:他们生成图片和深度图,而我们不需要;
- 和3D GAN,例如StyleNeRF和CIPS-3D的区别:他们在3D形状上表现不佳。
Tri-plane hybrid 3D representation
- 建立xyz三个相互垂直的特征平面,每个特征平面为N x N x C,其中N为平面分辨率,C为特征维度。对于任意一个3D位置,通过双线性插值,可索引到3个特征向量(F_xy, F_xz, F_yz),最终特征F为3个特征向量之和。
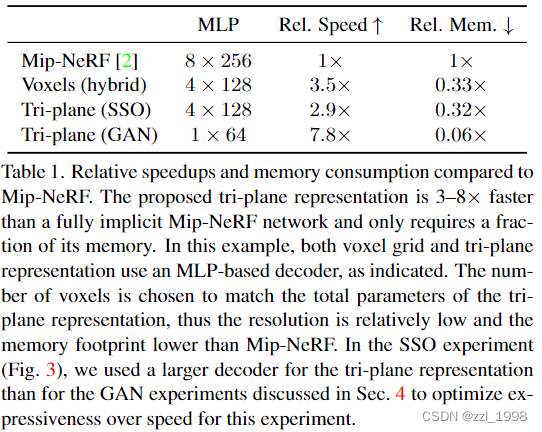
- 通过一个轻量级MLP解码网络,将特征F映射为颜色和强度,最后通过neural volume rendering将他们渲染为RGB图片。下图和下表显示,所提出的Tri-plane在具有更强表现能力的同时,内存开销更小,计算速度更快。

3D GAN framework
对每张训练图片,本文使用离线pose检测器计算其相机内外参数。算法整体pipeline如下: 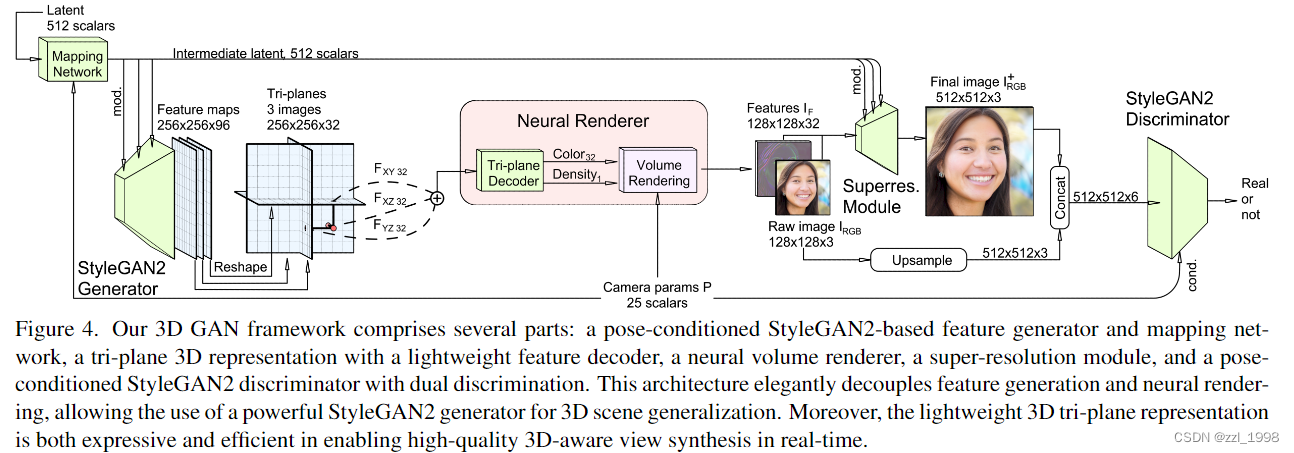
训练方法1:随机初始化,使用non-saturating GAN loss with R1 regularization,训练方法跟随StyleGAN2;训练方法2:两阶段训练策略,先训64 x 64的neural rendering,然后接128 x 128的fine-tune。实验显示,正则化有助于减少3D形状的失真。
CNN generator backbone and rendering
- decoder:MLP,每层包含64个神经元和softplus activation functions。MLP的输入可以是连续坐标,输出是scalar density和32维的特征
- Volume rendering:输入feature images,而不是RGB图片。因为,feature images包含更多可在超分中使用的信息。
Dual discrimination
- 鉴别器输入为6通道。本文认为feature image I_F的前三个通道是低分辨率RGB图片I_RGB。dual discrimination首先要求I_RGB和超分图片I_RGB^+保持一致(?),这一步通过双线性上采样得到。然后将超分超分图片和上采样图片拼接在一起送入鉴别器。对于真实图片,则是将真实图片和经过blur处理的真实图片拼接在一起送入鉴别器。
- 将相机内外参数送入鉴别器,作为条件标签。
Modeling pose-correlated attributes
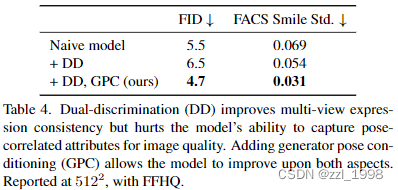
- 大多数现实世界数据集包含偏置,例如在FFHQ中,人脸表情和相机位置相关,通常来说,当相机正对人脸时,人是在笑的。本文提出generator pose conditioning,用于解耦训练图片中位姿和其他属性(可以理解为想要去除什么bias,就以bias为条件作为输入?)。
- 为增强模型对输入位姿的鲁棒性,在训练中,会以50%概率将相机参数矩阵P中的位姿替换为随机位姿。
- 消融实验发现,在训练时加入位姿作为条件很重要。未来的工作会考虑去除它。

Experiments and results
- Datasets:FFHQ真实人脸数据集,AFHQv2 Cats,真实猫脸数据集。
- Baselines:3个3D-aware image synthesis领域的sota方法:pi-GAN、GIRAFFE和Lifting StyleGAN。
- Qualitative results:

- Quantitative evaluations:
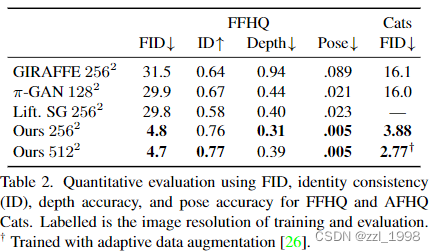
- Runtime:

Ablation study
Application
- Style mixing:

- Single-view 3D reconstruction:使用pivotal tuning inversion (PTI)

![GDI+绘图轻松入门[6]-路径变形和表盘的绘制](https://img-blog.csdnimg.cn/ea33b5ce2d7844ef8cc3668e73bcc751.png)