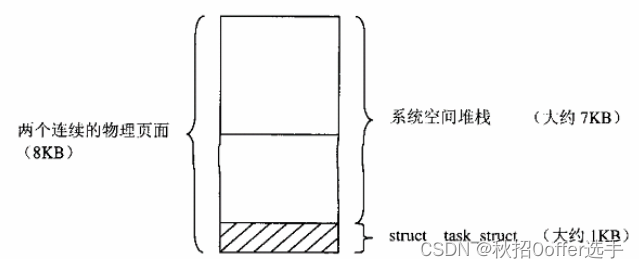
一、两次MD5加密设计
加密:出于安全考虑
- 第一次 (在前端加密,客户端):密码加密是(明文密码+固定盐值)生成md5用于传输,目的,由于http是明文传输,当输入密码若直接发送服务端验证,此时被截取将直接获取到明文密码,获取用户信息。
- 加盐值是为了混淆密码,原则就是明文密码不能在网络上传输。
- 第二次:在服务端再次加密,当获取到前端发送来的密码后。通过MD5(密码+随机盐值)再次生成密码后存入数据库。防止数据库被盗的情况下,通过md5反查,查获用户密码。
- 方法是盐值会在用户登陆的时候随机生成,并存在数据库中,这个时候就会获取到。
二、分布式session
现阶段的分布式web,几乎都是使用redis代替,将redis当做缓存来使用,要用啥往redis里面存,然后取:比如说,用户、验证码、各种内存变量…等等,牢记原则:
- 能不查询数据库就不查询数据库,尽量在redis里面完成
几乎都是前后端分离项目,使用ngnix动静分离、反向代理,然后后端传输动态数据
三、jmeter
Apache JMeter是Apache组织开发的基于Java的压力测试工具。
JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。
做压力测试,一般要使用工具,人工是没办法做的。最常用的工具是LoadRunner, 但是LoadRunner毕竟是收费软件,而且使用上也比较复杂。 现在越来越多的人开始使用Jmeter来做压力测试。免费,而且使用上非常简单。
- 吞吐量:是指在一次性能测试过程中网络上传输的数据量的总和,吞吐量指标反映的是服务器承受的压力
- 吞吐量(承压能力)与request对CPU的消耗、外部接口、IO等密切关联;主要是由TPS和并发数决定
- 影响参数:TPS、并发数、响应时间
什么是TPS和QPS? :https://blog.csdn.net/a745233700/article/details/117917333
四、乐观锁机制
通过乐观锁机制给库存上锁,避免超卖,通过在sql语句中进行判断,当库存大于0时,才进行订单生成,update更新库存减一,利用了mysql自身带的行锁,缩小了上锁的范围,也解决了超卖问题;
五、rabbitmq使用
- 使用redis预减库存,将秒杀商品的库存信息预先写入到redis之中去,当一个请求来到之时,先在redis中判断预减,可以先返回一个信息给用户,提高响应速度,增大QPS。
- 利用rabbitmq来进行流量消峰值,同时使得消息可以异步处理,也解耦了系统,给了用户更好的体验。
- rabbitmq中最重要的是交换机的使用,其中最常见的交换机模式有单播(direct)、广播(faout)、主题(topic)模式。
- 在队列中的消息会发给对应的消费者进行处理,处理的结果是在数据库中插入订单表。客户端发送ajax请求订单的结果;
六、分布式锁的实现
分布式锁,即分布式系统中的锁。在单体应用中我们通过锁解决的是控制共享资源访问的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程。
单体应用中是在单个进程中有多个线程竞争一个资源导致线程安全问题;而分布式锁是解决在多个微服务中多个进程进行资源竞争,分布式场景中,每个JVM中的锁是不一样的。
分布式锁应该具备哪些条件:
- 互斥性:在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
- 高可用的获取锁与释放锁;
- 高性能的获取锁与释放锁;
- 可重入性:具备可重入特性,具备锁失效机制,防止死锁,即就算一个客户端持有锁的期间崩溃而没有主动释放锁,也需要保证后续其他客户端能够加锁成功
- 非阻塞:具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的业务场景:
- 互联网秒杀(商品库存)
- 抢优惠券
分布式锁实现方式:

6.1 分布式锁:基于数据库
A. 悲观锁(排他锁)
利用select … where xx=yy for update排他锁
注意:这里需要注意的是where xx=yy,xx字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
核心思想:以「悲观的心态」操作资源,无法获得锁成功,就一直阻塞着等待。注意:该方式有很多缺陷,一般不建议使用。
优点:
简单易用,好理解,保障数据强一致性;
缺点:
- 存在性能瓶颈;
- 在 RR 事务级别,select 的 for update 操作是基于
间隙锁(gap lock)实现的,是一种悲观锁的实现方式,所以存在阻塞问题。 - 高并发情况下,大量请求进来,会导致大部分请求进行排队,影响数据库稳定性,也会
耗费服务的CPU等资源。 - 如果优先获得锁的线程因为某些原因,一直没有释放掉锁,可能会导致死锁的发生。
- 锁的长时间不释放,会一直占用数据库连接,可能会将数据库连接池撑爆,影响其他服务。
- MySql数据库会做查询优化,即便使用了索引,优化时发现全表扫效率更高,则可能会将行锁升级为表锁,此时可能就更悲剧了。
- 不支持可重入特性,并且超时等待时间是全局的,不能随便改动。
B. 乐观锁
所谓乐观锁与悲观锁最大区别在于基于CAS思想,表中添加一个时间戳或者是版本号的字段来实现,update xx set version=new_version where xx=yy and version=Old_version,通过增加递增的版本号字段实现乐观锁。不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。
为表添加一个字段,版本号或者时间戳都可以。通过版本号或者时间戳,来保证多线程同时间操作共享资源的有序性和正确性。

抢购、秒杀就是用了这种实现以防止超卖。
实际代码中可以写个while循环不断重试,版本号不一致,更新失败,重新获取新的版本号,直到更新成功
2. 优缺点
优点:
- 实现简单,复杂度低
- 保障数据一致性
缺点:
- 性能低,并且有锁表的风险
- 可靠性差
- 非阻塞操作失败后,需要轮询,占用CPU资源
- 长时间不commit或者是长时间轮询,可能会占用较多的连接资源
6.2 分布式锁:基于Zookeeper
实现思想
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
基于ZooKeeper实现分布式锁的步骤如下:
- 创建一个目录mylock;
- 线程A想获取锁就在mylock目录下创建临时顺序节点;
- 获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
- 线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
整个过程如图:

6.3 分布式锁:基于Redis
1. 实现思想
主要是基于命令:SETNX key value
分布式锁机制: redis单线程命令处理机制+ setnx命令实现抢锁机制
Redis单线程机制:同时只有一个线程有序处理多个命令
setnx命令: ( SET if Not eXists )命令在指定的key不存在时,为key设置指定的值,这种情况下等同SET命令。当key存在时,什么也不做

面试官:业务系统执行失败没有及时删除key会出现什么问题?怎么解决?
回答一:业务失败锁还在,就会产生死锁,可以加一个过期时间自动释放锁,但是自动释放可能出现释放掉其他jvm锁的情况,所以要给锁加一个唯一标识,删除前先看看是不是本机持有的锁,是的话再删除,还要保证查询和删除是一个原子操作,可以使用lua脚本
回答二:产生死锁现象,导致虚拟机实例无法再次获取资源,可以设置失效时间,缺陷:因为不确定业务执行时间的长短,所以失效时间的设置具有不确定性。优化:使用try catch finally 语句块,在finally语句中调用del方法删除key完成释放锁的目的,这样下次虚拟机实例请求资源时便能通过setNx()方法获取到锁,执行响应业务逻辑!
实现思想的具体步骤:
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
- 获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
- 释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
- 具体改进步骤见:https://blog.csdn.net/jiandanokok/article/details/114296755
-
虽然通过上面的方式解决了会删除其他进程的锁的问题,但是超时时间的设置依然是没有解决的,设置成多少依然是个比较棘手的问题,设置少了容易导致业务没有执行完锁就被释放了,而设置过大万一服务出现异常无法正常释放锁会导致出现异常锁的时间也很长。
怎么解决这个问题呢?
目前大公司的一个方案是这样子的:
- 在加锁成功之后,启动一个守护线程
- 守护线程每隔1/3的锁的超时时间就去延迟锁的超时时间,比如说锁设置为30秒,那就是每隔10秒就去延长锁的超时时间,重新设置为30秒
- 业务代码执行完成,关闭守护线程
2. 优缺点
优点:
- 性能非常高
- 可靠性较高
- CAP模型属于AP
缺点:
- 复杂度较高
- 无一致性算法,可靠性并不如Zookeeper
- 锁删除失败 过期时间不好控制
- 非阻塞,获取失败后,需要轮询不断尝试获取锁,比较消耗性能,占用cpu资源
3.缺点详解
使用 Redis 做分布式锁的缺点在于:如果采用单机部署模式,会存在单点问题,只要 Redis 故障了,加锁就不行了。
采用 Master-Slave 模式/集群模式,如下:
- 线程1加了锁去执行业务了,刚好Redis的 master 发生故障挂掉了,此时还没有将数据同步到 slave 上
集群会选举一个新的 master 出来,但是新的 master 上并没有这个锁,线程2可以在新选举产生的 master 上去加锁,然后处理业务 - 这样的话,就导致了两个线程同时持有了锁,锁就不再具有安全性。
针对这个问题,有两个解决方案:
- RedLock
- Zookeeper【推荐】
1. RedLock
基于以上的考虑,Redis的作者提出了一个RedLock的算法。
这个算法的意思大概是这样的:假设 Redis 的部署模式是 Redis Cluster,总共有 5 个 Master 节点。
通过以下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒。
- 轮流尝试在每个 Master 节点上创建锁,过期时间设置较短,一般就几十毫秒。
- 尝试在大多数节点上建立一个锁,比如 5 个节点就要求是 3 个节点(n / 2 +1)。
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了。
- 要是锁建立失败了,那么就依次删除这个锁。
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。

但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确,不太推荐。
注意:除了RedLock之外目前并没有有效解决Redis主从切换导致锁失效的方法。在这种情况下(一致性要求非常高的情况下)一般是不会使用Redis,而推荐使用Zookeeper。
4.Redisson
目前业界对于Redis的分布式锁有了现成的实现方案了,比较出名的是Redisson开源框架。
Redisson 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持。
Redission 通过 Netty 支持非阻塞 I/O。
Redisson 封装了锁的实现,让我们像操作我们的本地 Lock一样来使用,除此之外还有对集合、对象、常用缓存框架等做了友好的封装,易于使用。
除此之外,Redisson还实现了分布式锁的自动续期机制、锁的互斥自等待机制、锁的可重入加锁于释放锁的机制,可以说Redisson对分布式锁的实现是实现了一整套机制的。
注意:Redison并不能有效的解决Redis的主从切换问题的,目前推荐使用Zookeeper分布式锁来解决。
5. 分段锁
怎么在高并发的场景去实现一个高性能的分布式锁呢?
分段锁
假如产品1有200个库存,可以将这200个库存分为10个段存储(每段20个),每段存储到一个cluster上;将key使用hash计算,使这些key最后落在不同的cluster上。
每个下单请求锁了一个库存分段,然后在业务逻辑里面,就对数据库或者是Redis中的那个分段库存进行操作即可,包括查库存 -> 判断库存是否充足 -> 扣减库存。
具体可以参照 ConcurrentHashMap 的源码去实现,它使用的就是分段锁。
6.4 分布式锁对比
从理解的难易程度角度(从低到高):数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高):Zookeeper >= 缓存 > 数据库
从性能角度(从高到低):缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低):Zookeeper > 缓存 > 数据库
6.5 总结
总结:
- 追求数据可靠性/强一致性:使用Zookeeper
- 追求性能:选择Redis,推荐Redisson
- Redis分布式锁目前最大问题在于:主从模式下/集群模式下,master节点宕机,异步同步数据导致锁丢失问题
- Redis的RedLock算法具有很大争议性,一般不推荐使用
存 > 数据库
从性能角度(从高到低):缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低):Zookeeper > 缓存 > 数据库
6.5 总结
总结:
- 追求数据可靠性/强一致性:使用Zookeeper
- 追求性能:选择Redis,推荐Redisson
- Redis分布式锁目前最大问题在于:主从模式下/集群模式下,master节点宕机,异步同步数据导致锁丢失问题
- Redis的RedLock算法具有很大争议性,一般不推荐使用