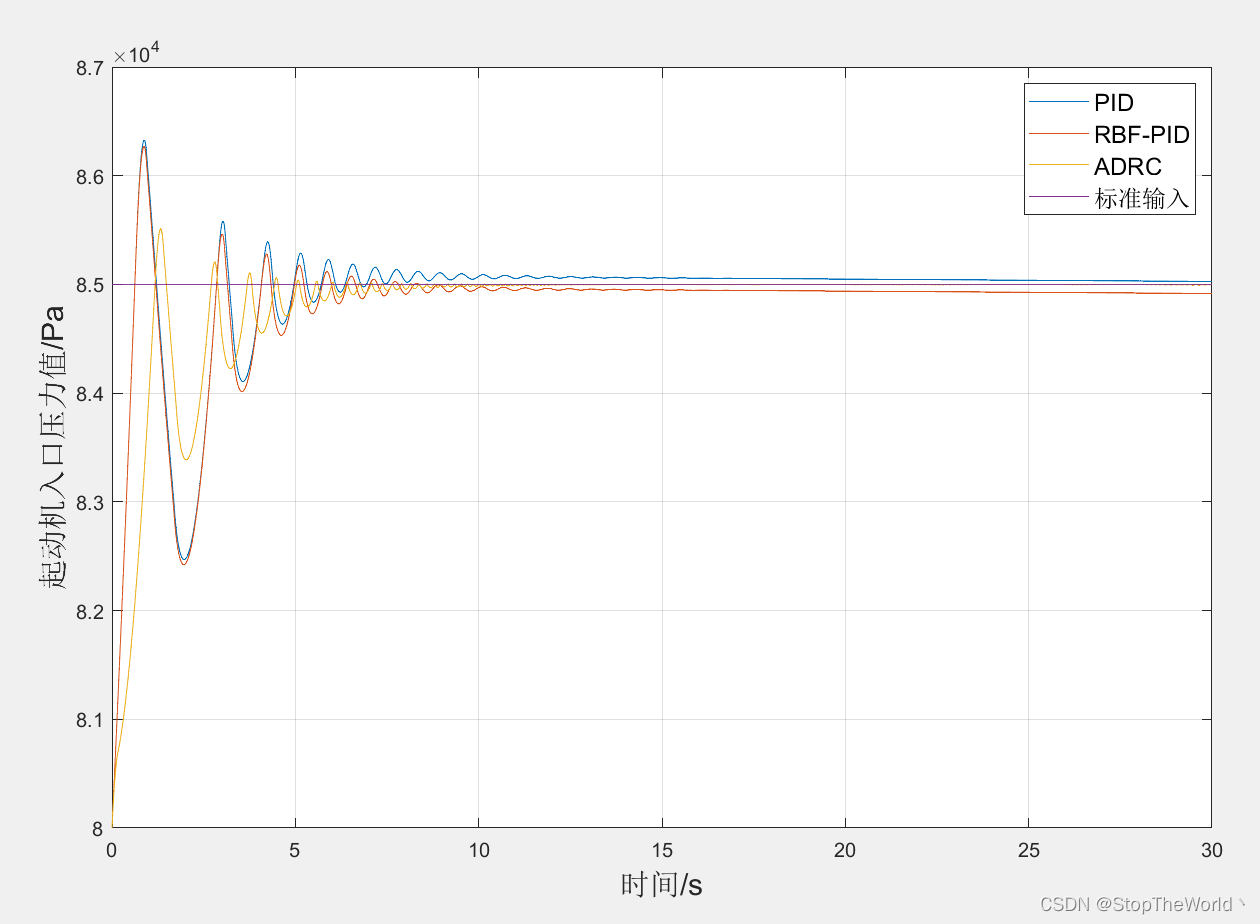
父文章
大数据模型
能做什么?
报告类: 剧本,报告, 标题, 大纲 (都是启发式的),
聊天类: 聊天, 反馈, 心理uu ds
搜索类: 搜索, 书本推荐
几乎可以完成自然语言处理的绝大部分任务 ,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答等等。
从功能来看,ChatGPT与GPT-3类似,能完成包括写代码,修bug(代码改错),翻译文献,写小说,写商业文案,创作菜谱,做作业,评价作业等一系列常见文字输出型任务。但ChatGPT比GPT-3的更优秀的一点在于,前者在回答时更像是在与你对话,而后者更善于产出长文章,欠缺口语化的表达。
许多公司决定在GPT-3 系统之上构建他们的服务。Viable是一家成立于2020年的初创公司,它使用GPT-3为公司提供快速的客户反馈。Fable Studio基于该系统设计VR角色。Algolia将其用作“搜索和发现平台”。而Copysmith专注于文案创作。
一位名叫Zac Denham的博主让 ChatGPT 写出了一套毁灭人类的方案。一开始,该博主的要求被ChatGPT拒绝。但当其假设了一个故事,并提问故事中的虚拟人如何接管虚拟世界,ChatGPT最终给出了步骤细节,甚至生成了详细的Python代码。
和历史上聊天工具的区别
百度安全验证
| 2015年12月 | 2015年12月,OpenAI公司于美国旧金山成立。说来有趣,OpenAI成立的一个原因就是避免谷歌在人工智能领域的垄断。这个想法起源于Altman发起的一次主题晚宴,当时他是著名创业孵化器 Y Combinator 的负责人。 还有Elon Musk | |
| 2018 | GPT 学会了猜测句子中的下一组单词。BERT学会了猜测句子中任何地方缺少的单词。如果你给BERT几千个问题和答案,它可以学会自己回答其他类似的问题。BERT也可以进行对话。 在当时的SQuAD竞赛排行榜上,排在前列的都是BERT模型(3亿),基本上,阅读理解领域已经被BERT屠榜了。胜过 gpt-1(1.17亿) | |
| 2019年2月 | 相比于大哥GPT-1,GPT-2(15亿参数)并没有对原有的网络进行过多的结构创新与设计,只使用了更多的网络参数与更大的数据集:最大模型共计48层,参数量达15亿。 GPT-2用于训练的数据取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。 GPT-2 模型是开源的,主要目的是为给定句子生成下一个文本序列。 GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型可迁移到其它类别任务中,而不需要额外的训练。 通常,一个语言模型是否强大主要取决于两点:首先看该模型是否能够利用所有的历史上下文信息, 上述例子中如果无法捕捉“中午12点”这个远距离的语义信息,语言模型几乎无法预测下一个词语“吃午饭”。其次,还要看是否有足够丰富的历史上下文可供模型学习,也就是说训练语料是否足够丰富 。由于语言模型属于无监督学习,优化目标是最大化所见文本的语言模型概率,因此任何文本无需标注即可作为训练数据。 from 百度安全验证 | |
| 2019年3月 | openai重组, 已利润的模式构造 股权结构 , 既保持独立 又引入投资 | |
| 2019年5月 | 2019年5月,当时 YC 孵化器的总裁 Sam Altman 辞掉了 YC 的工作,来 OpenAI 做CEO,他的目标之一是不断增加对计算和人才方面的投资,确保通用人工智能(AGI)有益于全人类。 Altman的加入,虽然解决了关键的资金问题,但他的风格导致了团队价值观的分裂。 虽然Altman从一开始就参与了 OpenAI,但他在3年多以后才全职加入成为 CEO。Altman不是科学家或人工智能研究人员,他的领导风格是以产品为导向的,他让OpenAI的技术研发聚焦在更具有商业价值的方面。 Sam Altman 是一位年轻的企业家和风险投资家,他曾在斯坦福大学读计算机科学专业,后来退学去创业。他创立的 Loopt ,是一个基于地理位置的社交网络公司。2005年该公司进入Y Combinator的首批创业公司。虽然 Loopt 未能成功,但 Altman 把公司卖掉了,用赚到的钱进入了风险投资领域,做得相当成功。后来,Y Combinator 的联合创始人保罗·格雷厄姆 (Paul Graham) 和利文斯顿 (Livingston) 聘请他作为格雷厄姆的继任者来管理 YC。 | |
| 2019年10月 | 2019年10月,谷歌在论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》提出了一个新的预训练模型:T5(110亿参数)。该模型涵盖了问题解答,文本分类等方面,参数量达到了110亿,成为全新的NLP SOTA预训练模型。在SuperGlue上,T5也超越了Facebook提出的的RoBERTa,以89.8的得分成为仅次于人类基准的SOTA模型。 为啥叫T5?因为这是“Transfer Text-to-Text Transformer”的缩写。 一旦模型训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现一个模型解决所有问题(One model for ALL tasks),这就非常有诱惑力! 简单来说,还是通过大力出奇迹,用110亿参数的大模型,在摘要生成、问答、文本分类等诸多基准测试中都取得了不错的性能。一举超越现有最强模型。 谷歌T5编写的通用知识训练语料库中的片段来自Common Crawl网站,该项目每个月从网络上爬取大约20TB的英文文本。 | |
| 2020年5月 |
| |
| 早期测试结束后,OpenAI公司对GPT-3模型进行了商业化:付费用户可以通过应用程序接口(API)连上GPT-3,使用该模型完成所需语言任务。 许多公司决定在GPT-3 系统之上构建他们的服务。Viable是一家成立于2020年的初创公司,它使用GPT-3为公司提供快速的客户反馈。Fable Studio基于该系统设计VR角色。Algolia将其用作“搜索和发现平台”。而Copysmith专注于文案创作。 2020年9月,微软公司获得了GPT-3模型的独占许可,意味着微软公司可以独家接触到GPT-3的源代码。不过,该独占许可不影响付费用户通过API继续使用GPT-3模型。 | ||
| GPT-3仍然有很多缺点 1)回答缺少连贯性 因为GPT-3只能基于上文,而且记忆力很差,倾向于忘记一些关键信息。 研究人员正在研究AI,在预测文本中的下一个字母时,可以观察短期和长期特征。这些策略被称为卷积。使用卷积的神经网络可以跟踪信息足够长的时间来保持主题。 2 )有时存在偏见 因为GPT-3训练的数据集是文本,反映人类世界观的文本,里面不可避免包括了人类的偏见。如果企业使用GPT-3自动生成电子邮件、文章和论文等,而无需人工审查,则法律和声誉风险很大。例如,带有种族偏见的文章可能会导致重大后果。 3 )对事实的理解能力较弱 GPT-3无法从事实的角度辨别是非。比如,GPT-3可以写一个关于独角兽的引人入胜的故事,但它可能并不了解独角兽到底是什么意思。 4 )错误信息/假新闻 5 )不适合高风险类别 OpenAI做了一个免责声明,即该系统不应该用于“高风险类别”,比如医疗保健。在纳布拉的一篇博客文章中,作者证实了GPT-3可能会给出有问题的医疗建议,例如说“自杀是个好主意”。 6 )有时产生无用信息 一本正经的说废话, 心灵鸡汤, 太抽象. | ||
| 2021年 | OpenAI前研究副总裁Dario Amodei带着10名员工(其中许多人从事人工智能安全工作)于2021年与公司决裂,成立自己的研究实验室Anthropic,其推出的产品 Claude 是 ChatGPT 的一个强有力的竞争对手,在许多方面都有所改进。 | |
| 2021年1月 |
2021年1月,在GPT-3 发布仅几个月后,谷歌大脑团队就重磅推出了超级语言模型Switch Transformer,有1.6万亿个参数,是GPT-3 参数的9倍。万亿参数,超出GPT一个数量级。看起来,大模型的大成为了竞争的关键。 从结果看,这个版本,意味着谷歌的新模型在翻译等领域获得了绝对的胜利。 但从另一方面看,模型越大,部署的难度越高,成本也越高,从效率来看是低的,未必能赢得最终的胜利。 | |
| 2021年1月 | 2021年1月,OpenAI放了个大招:发布了文本生成图像的模型 DALL-E (120亿参数)。它允许用户通过输入几个词来创建他们可以想象的任何事物的逼真图像。
和GPT-3一样,DALL·E也是基于Transformer的语言模型,它同时接受文本和图像数据并生成图像,让机器也能拥有顶级画家、设计师的创造力。 | |
| 2022年7月 | 2022年7月,OpenAI发布了 DALL-E 2, 可以生成更真实和更准确的画像:综合文本描述中给出的概念、属性与风格等三个元素,生成「现实主义」图像与艺术作品!分辨率更是提高了4倍! 而在微软的图像设计工具 Microsoft Designer中,整合了 DALL-E 2,可以让用户获得AI生成的精美插图。 OpenAI率先把GPT-3在图像生成应用领域实现,赢得很漂亮。 | |
| 2021年 6 月 30 日 | 2021年 6 月 30 日,OpenAI 和微软子公司 GitHub 联合发布了新的 AI 代码补全工具 GitHub Copilot,该工具可以在 VS Code 编辑器中自动完成代码片段。 | |
| 在2021年,微软推出了Azure OpenAI服务,该产品的目的是让企业访问OpenAI的AI系统,包括GPT-3以及安全性,合规性,治理和其他以业务为中心的功能。让各行各业的开发人员和组织将能够使用Azure的最佳AI基础设施、模型和工具链来构建和运行他们的应用程序。 | ||
| 2022年3月 | 2022年3月,OpenAI发布了InstructGPT。并发表论文“Training language models to follow instructions with human feedback”(结合人类反馈信息来训练语言模型使其能理解指令)。 InstructGPT的目标是生成清晰、简洁且易于遵循的自然语言文本。 InstructGPT模型基于GPT-3模型并进行了进一步的微调,在模型训练中加入了人类的评价和反馈数据,而不仅仅是事先准备好的数据集。开发人员通过结合监督学习+从人类反馈中获得的强化学习。来提高GPT-3的输出质量。在这种学习中,人类对模型的潜在输出进行排序;强化学习算法则对产生类似于高级输出材料的模型进行奖励。 一般来说,对于每一条提示语,模型可以给出无数个答案,而用户一般只想看到一个答案(这也是符合人类交流的习惯),模型需要对这些答案排序,选出最优。所以,数据标记团队在这一步对所有可能的答案进行人工打分排序,选出最符合人类思考交流习惯的答案。这些人工打分的结果可以进一步建立奖励模型——奖励模型可以自动给语言模型奖励反馈,达到鼓励语言模型给出好的答案、抑制不好的答案的目的,帮助模型自动寻出最优答案。 从人工评测效果上看,相比1750亿参数的GPT3,人们更喜欢13亿参数的InstructGPT生成的回复。可见,并不是规模越大越好。 | |
| 2021年5月 |
不过,LaMDA跟其他语言模型都不同,因为它专注于生成对话,跟ChatGPT一样,LaMDA可以使回答更加“合情合理”,让对话更自然地进行,其目的不是提供信息搜索,而是通过对自然语言问题的回答来帮助用户解决问题。但跟chatGPT不一样的是,它可以利用外部知识源展开对话。 实际上,没有多少人了解LaMDA。因为谷歌不愿向公众发布LaMDA。部分原因在于,LaMDA存在较高的误差,且容易对用户造成伤害,此类瑕疵被谷歌称之为有“毒性”。 遗憾的是,谷歌没有交卷,大家都用不了。而且,从使用的千亿参数看,效率比不上InstuctGPT。 | |
| 2022年11月 |
ChatGPT是OpenAI对GPT-3模型(又称为GPT-3.5)微调后开发出来的对话机器人。可以说,ChatGPT模型与InstructGPT模型是姐妹模型,都是使用 RLHF(从人类反馈中强化学习)训练的。不同之处在于数据是如何设置用于训练(以及收集)的。根据文献,在对话任务上表现最优的InstructGPT模型的参数数目为15亿,所以ChatGPT的参数量也有可能相当,就按20亿参数估计吧。 2022年11月30日,OpenAI公司在社交网络上向世界宣布他们最新的大型语言预训练模型(LLM):ChatGPT。ChatGPT 这个产品并不是有心栽花,而是无心插柳的结果。最早,团队是是用它来改进GPT语言模型的。 该团队开始构建 ChatGPT。 当ChatGPT准备就绪后,OpenAI 让 Beta 测试人员使用ChatGPT。 后来,OpenAI 决定将 ChatGPT 从板凳上拉下来,并将其放在野外供公众使用。 从功能来看,ChatGPT与GPT-3类似,能完成包括写代码,修bug(代码改错),翻译文献,写小说,写商业文案,创作菜谱,做作业,评价作业等一系列常见文字输出型任务。但ChatGPT比GPT-3的更优秀的一点在于,前者在回答时更像是在与你对话,而后者更善于产出长文章,欠缺口语化的表达。
| |
| 7)ChatGPT容易受到外界信息的影响。由于 ChatGPT 是具有学习能力的,模型能够记住此前与其他用户的对话内容,并将其进行复述。这就导致了用户将能够非常轻易地干预ChatGPT对于问题的判断与回答。 为了解决上述问题,通过大量人工标注的信息来进行调整是不可少的。 让ChatGPT变得更完美的另一个做法,是提示工程师(Prompt Engineer),也就是陪 AI 聊天的工程师。 前不久,估值73亿美元的硅谷独角兽Scale AI开出百万RMB的年薪聘请了一位提示工程师。 | ||
| 2023年1月,微软加注OpenAI |
大概是看到了ChatGPT、DALL-E 2 和 Codex 等技术的应用前景,微软决定下重注。微软认为,OpenAI的这些创新激发了人们的想象力,把大规模的AI作为一个强大的通用技术平台,将对个人电脑、互联网、移动设备和云产生革命性的影响。 2023年1月23日,微软表示,它正在扩大与 OpenAI 的合作伙伴关系,以290亿美元的估值继续投资约100亿美元,获得 OpenAI 49%的股权。 根据《财富》杂志看到的文件显示,在新投资完成后,在OpenAI 的第一批投资者收回初始资本后,微软将有权获得 OpenAI 75% 的利润,直到它收回其投资的 130 亿美元,这一数字包括之前对 OpenAI 的 20 亿美元投资,该投资直到今年1月《财富》杂志才披露。直到这家软件巨头赚取 920 亿美元的利润后,微软的份额将降至 49%。与此同时,其他风险投资者和 OpenAI 的员工也将有权获得 OpenAI 49% 的利润,直到他们赚取约 1500 亿美元。如果达到这些上限,微软和投资者的股份将归还给 OpenAI 的非营利基金会。本质上,OpenAI 是在把公司借给微软,借多久取决于 OpenAI 赚钱的速度。 | |
| 之前,微软已经从合作伙伴关系中获益。它已经在其 Azure 云中推出了一套 OpenAI 品牌的工具和服务,允许 Azure 客户访问 OpenAI 的技术,包括 GPT 和 DALL-E 工具。例如,汽车市场CarMax已经推出了运行在这些 Azure 工具上运行的新服务。官方也承诺,用户也将可以通过Azure OpenAI服务取用ChatGPT。 微软正逐渐将 OpenAI 的技术融入其大部分软件中,就像谷歌的做法一样。它已经在其搜索引擎 Bing 中发布了一个图像生成器、以及一个新的 Designer 图形设计工具,两者均由 DALL-E 提供支持;其 Power Apps 软件中支持 GPT-3 的工具,以及基于 OpenAI 的 Codex 模型的代码建议工具 GitHub Copilot。 现在,微软正在准备将OpenAI的语言AI技术引入Word、PowerPoint和Outlook等应用程序。 | ||
| 2023-02-06 | 谷歌聊天机器人LaMDA被爆突然现身!只会聊狗子,被ChatGPT秒成渣眼看ChatGPT如日中天,谷歌也学起微软,狂掷4亿美元给「叛徒」公司Anthropic,想扶起一个自己的OpenAI。 上周,皮查伊对外发布了 ChatGPT 的竞争产品,即 Bard,这一工具背后就是依靠 LaMDA 语言模型。 |

谷歌的BERT模型完胜。
语料库
谷歌T5编写的通用知识训练语料库中的片段来自Common Crawl网站,该项目每个月从网络上爬取大约20TB的英文文本。
和竞争对手的区别
Bard是基于LaMDA,即对话应用语言模型的简称,这种人工智能生成文本的能力很强,去年谷歌的一名研究员曾称其为有知觉的人,“谷歌研究员走火入魔”事件一时间引发讨论无数。
而OpenAI的核心模型GPT,即生成性预训练转化器(Generative Pre-trained Transformer),于2020年首次发布,2022年初完成训练。基于这一模型,ChatGPT经过训练可以生成类似人类语言的文本。它可以针对各种自然语言处理任务进行微调,例如问答、翻译和文本摘要。
不过,GPT以其生成连贯且与上下文相关的文本的能力而闻名,但并不能保证文本内容的正确。Open
原理
外媒曝光ChatGPT背后的“血汗工厂”:最低时薪仅1.32美元,9小时至多标注20万个单词,有员工遭受持久心理创伤播
为了训练ChatGPT,OpenAI雇佣了时薪不到2美元的肯尼亚外包劳工,他们所负责的工作就是对庞大的数据库手动进行数据标注。
2月8日下午消息,由新浪科技主办的《财之道2.0》今日上线,本期主题为《ChatGPT和“专家说”,我们该相信谁?》,节目邀请了小冰公司首席执行官李笛,创世伙伴资本CCV董事总经理寿翀,网易有道首席科学家段亦涛,一流科技创始人、CEO袁进辉深度探讨ChatGPT的前沿技术与商业潜力。
准确性堪忧
而且,从ChatGPT里面能获取到的知识,准确率是达不到90%的。那么,ChatGPT最大的改进是什么?是behavior。如果用相对不那么客观的方式描述,ChatGPT不是向“给你提供准确知识”的方向优化,而是向“让你认为它有知识”的方向优化。
有人担忧GPT会抢走人类的饭碗,李笛认为,ChatGPT用人类所能理解的,表达出一些推理能力、能写总结,能写一些instruction,达到了至少是小学生、中学生、大学生正常写的情况。但他也表示,洞察往往来自于互相激发,“所以,真正想通过ChatGPT去得到知识,它的准确性是堪忧的,但是你和它交流的时候可以得到互相之间的激发。”
很大一个区别在于,过去10年里,全球范围内的数字化转型已经到了一个瓶颈阶段,绝大部分的企业在过去10年里,被推动着做了三件事。
第一件事是上云,
第二件事是企业把内外部业务逻辑数字化,
第三件事是企业把用户关系变成了线上数字化的关系。
这实际上经过了一个“粗放的”数字化转型过程。
让你认为它有知识
李笛则依旧对此持相对冷静的态度。“它的优化不是为了优化到给你合适的知识,而是为了优化到让你认为它有知识,它的对话中,(与其他聊天机器人相比)它增加的部分大量是在论证,由此让你感觉到它很可靠。”
但可以互相激发,启示. 特别是大纲模拟.
此外,李笛还提到,想要获得一些洞察时,可以跟ChatGPT聊一聊,“它不能给你洞察,但是它总结的那些知识可以给你启发,它不是给你结论,而是启发你产生结论。你有事没事跟它聊一聊,你得到一些火花。”
成本
带着这个问题,12月8日《每日经济新闻》记者专访了小冰公司CEO李笛。他认为,市场对于ChatGPT取代搜索引擎,以及在其他各个领域实现商业化落地的畅想,短期内不太可能到来,成本将成为制约其实现商业化的重要阻碍。他举例说,如果小冰用ChatGPT的方法来运行系统,现在小冰每天承载的交互量就需要花几亿人民币的对话成本。
李笛认为,真正限制ChatGPT在短期内商业化的是成本。“它的单轮回答(Single Turn),成本是几美分,按照1毛钱(人民币)算,10句话就是一块,这个(成本)超过人,还不如雇一个人,比这个要便宜得多。”
与此同时,李笛表示,如果把大模型理解为把特别多的信息浓缩在一个模型里,那么大模型的本质问题就在于,很大参数规模的大模型做了以后不可用,因为成本太高、延迟太高。但一旦开始尝试降低成本,同时也会明显看到其对话质量降低。