什么是分布式一致性算法Raft
分布式一致性算法Raft:指在分布式场景下实现集群数据同步的解决方案
掌握了这个算法,就可以较容易地处理绝大部分场景的容错和数据一致性需求
Raft三大角色
跟随者(Follower):普通群众,默默接收和来自领导者的消息,当领导者心跳信息超时的时候,就主动站出来,推荐自己当候选人。(大王不在,掀杆而起,自立为王,哈哈)
候选人(Candidate):候选人将向其他节点请求投票 RPC 消息,通知其他节点来投票,如果赢得了大多数投票选票,就晋升当领导者。
领导者(Leader):霸道总裁,一切以我为准。主要功能:处理写请求、管理日志复制(数据同步)和不断地发送心跳信息(保持连接),通知其他节点“我是领导者,我还活着,你们不要”发起新的选举,不用找新领导来替代我。(大王还在,你们不要起义)

现在我们想象一下,有一个单节点系统,这个节点作为数据库服务器,且存储了一个值为 X。

左边绿色的实心圈就是客户端,右边的蓝色实心圈就是节点 a(Node a)。Term 代表任期,后面会讲到。

客户端向单节点服务器发送了一条更新操作,设置数据库中存的值为 8。单机环境下(单个服务器节点),客户端从服务器拿到的值也是 8。一致性非常容易保证。

Raft选举流程
下面就开始讲解 Raft 算法选举领导者的过程。
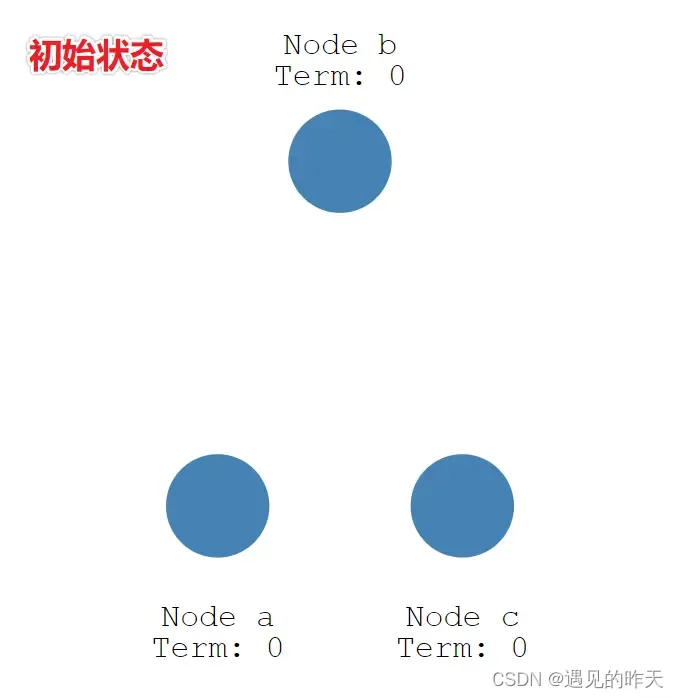
1、初始状态
初始状态下,集群中所有节点都是跟随者的状态。
如下图所示,有三个节点(Node) a、b、c,任期(Term)都为 0。
Raft 算法实现了随机超时时间的特性,每个节点等待领导者节点心跳信息的超时时间间隔是随机的。比如 A 节点等待超时的时间间隔 150 ms,B 节点 200 ms,C 节点 300 ms。那么 a 先超时,最先因为没有等到领导者的心跳信息,发生超时。如下图所示,三个节点的超时计时器开始运行。
为什么follower等待leader心跳,不同节点进行随机超时呢?因为follower节点也想当大王呀,但如果多个follower同一时间点发起投票,进行选举,从而会导致选票相同的情况,又重新进行选举,所以还是每个节点的随机超时的时间是不同的
2、发起投票
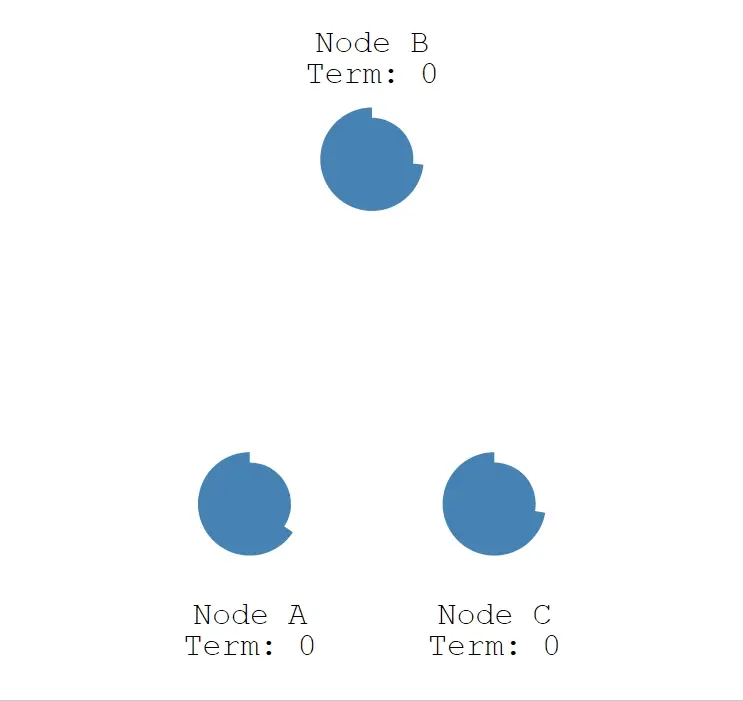
当 A 节点的超时时间到了后,A 节点成为候选者,并增加自己的任期编号,Term 值从 0 更新为 1,并给自己投了一票。
Node A:Term = 1, Vote Count = 1。
Node B:Term = 0。
Node C:Term = 0。
3、成为领导者
我们来看下候选者如何成为领导者的。
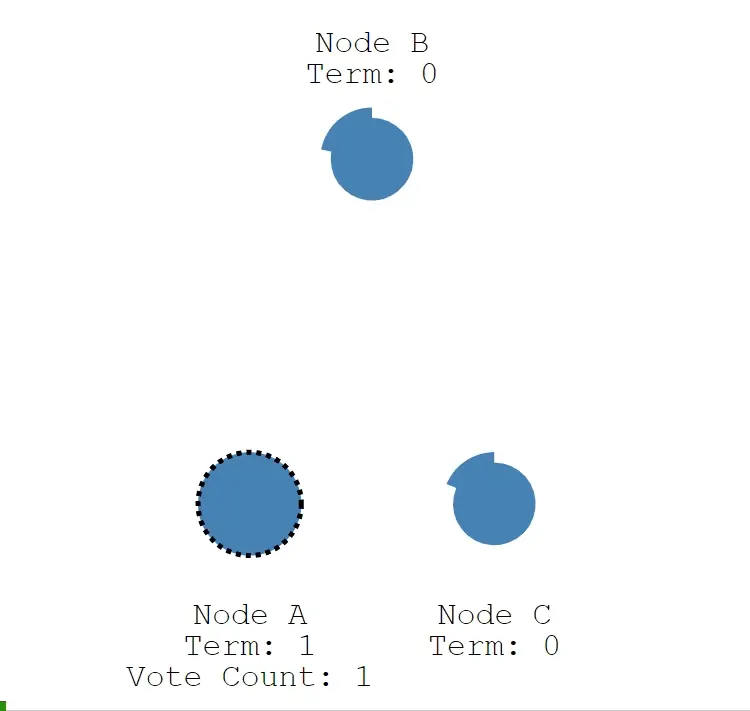
上述处理流程:
- 第一步:节点 A 成为候选者后,向其他节点发送请求投票 RPC 信息,请它们选举自己为领导者。
- 第二步:节点 B 和 节点 C 接收到节点 A 发送的请求投票信息后,在编号为 1 的这届任期内,还没有进行过投票,就把选票投给节点 A,并增加自己的任期编号。
- 第三步:节点 A 收到 3 次投票,得到了大多数节点的投票,从候选者成为本届任期内的新的领导者。
- 第四步:节点 A 作为领导者,固定的时间间隔给 节点 B 和节点 C 发送心跳信息,告诉节点 B 和 C,我是领导者,组织其他跟随者发起新的选举。
- 第五步:节点 B 和节点 C 发送响应信息给节点 A,告诉节点 A 我是正常的。
4、领导者任期
英文单词是 term,领导者是有任期的。
自动增加:跟随者在等待领导者心跳信息超时后,推荐自己为候选人,会增加自己的任期号,如上图所示,节点 A 任期为 0,推举自己为候选人时,任期编号增加为 1。
更新为较大值:当节点发现自己的任期编号比其他节点小时,会更新到较大的编号值。比如节点 A 的任期为 1,请求投票,投票消息中包含了节点 A 的任期编号,且编号为 1,节点 B 收到消息后,会将自己的任期编号更新为 1。
恢复为跟随者:如果一个候选人或者领导者,发现自己的任期编号比其他节点小,那么它会立即恢复成跟随者状态。这种场景出现在分区错误恢复后,任期为 3 的领导者受到任期编号为 4 的心跳消息,那么前者将立即恢复成跟随者状态。
拒绝消息:如果一个节点接收到较小的任期编号值的请求,那么它会直接拒绝这个请求,比如任期编号为 6 的节点 A,收到任期编号为 5 的节点 B 的请求投票 RPC 消息,那么节点 A 会拒绝这个消息。
一个任期内,领导者一直都会领导者,直到自身出现问题(如宕机),或者网络问题(延迟),其他节点发起一轮新的选举。
在一次选举中,每一个服务器节点最多会对一个任期编号投出一张选票,投完了就没了。
假设一个集群由 N 个节点组成,那么大多数就是至少 N/2+1。例如: 3 个节点的集群,大多数就是 2。才能成为领导leader
问题:为什么要定义leader,follower,candidate?
集群数据同步保证一致性一般有两种做法:
1、分布式节点存储:分布式一致性算法解决方案
1、中心化存储:但是要保证中心节点的 高可用(本质上还是要一致性算法解决方案)
定义不同角色??
1、如果想要实现集群数据同步,必然要实现节点数据传送,如果各个节点都是平等地位,那么对于写操作而言,是对于每个节点都生效的,处理起来变得很复杂
2、拿到数据,要统一给每一个集群节点发送,可能会存在并发问题,写覆盖导致数据不一致)
问题:为什么每个follower要随机leader的超时时间?
为了防止多个节点同时发起投票
为了防止多个节点同时发起投票,会给每个节点分配一个随机的选举超时时间。这个时间内,节点不能成为候选者,只能等到超时。比如上述例子,节点 A 先超时,先成为了候选者。这种巧妙的设计,在大多数情况下只有一个服务器节点先发起选举,而不是同时发起选举,减少了因选票瓜分导致选举失败的情况。
问题:leader出现故障怎么办?
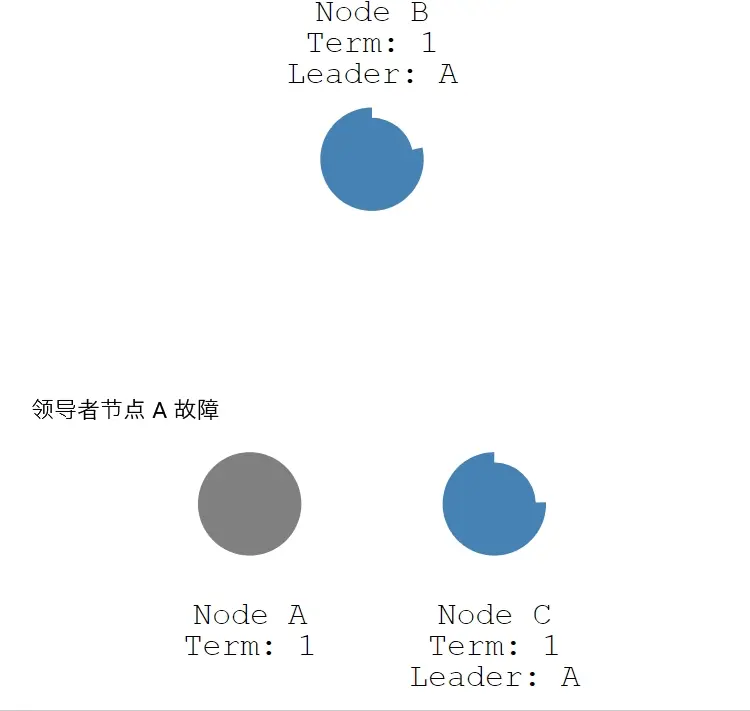
如果领导者节点出现故障,则会触发新的一轮选举。如下图所示,领导者节点 B 发生故障,节点 A 和 节点 B 就会重新选举 Leader。
注意:任期是一直累加的
- 第一步 :节点 A 发生故障,节点 B 和节点 C 没有收到领导者节点 A 的心跳信息,等待超时。
- 第二步:节点 C 先发生超时,节点 C 成为候选人。
- 第三步:节点 C 向节点 A 和 节点 B 发起请求投票信息。
- 第四步:节点 C 响应投票,将票投给了 C,而节点 A 因为发生故障了,无法响应 C 的投票请求。
- 第五步:节点 C 收到两票(大多数票数),成为领导者。
- 第六步:节点 C 向节点 A 和 B 发送心跳信息,节点 B 响应心跳信息,节点 A 不响应心跳信息。
问题:一般情况下,在多节点集群中,Raft 算法如何保证在同一个时间,集群中只有一个领导者呢?
1、领导者心跳超时,节点定义不同的超时时间,进行选举投票(避免选举时票数相同)
2、先超时先投票
3、一票制,每个节点在一轮选举中只能投一票
4、半数选票原则,相当leader 选举票数必须 大于等于n/2+1
5、任期,通过比较任期大小最终确定leader
问题:在分区错误,网络不通等异常情况下,Raft 算法如何保证在同一个时间,集群中只有一个领导者呢?(脑裂现象)
什么是脑裂:假如在一个集群或系统中,同时出现2个及以上的Leader,这样的现象就是脑裂。
多个Leader会向Follower同时发号施令,Follower不清楚该接受哪个Leader的指令,最终会造成内部混乱。
在没有出现网络分区的情况下,Raft通过以下两条约束来避免脑裂:
- 每个节点在一个任期内,只能投票一次。
- 获得半数以上的选票,才能成为Leader。
在固定的选票下,获得半数以上选票的才能成为Leader,有效避免了脑裂问题。
如果在网络分区下,网络不畅,怎么避免脑裂?
先说结论,其实和Leader宕机恢复很像,低任期的Leader在发现有高任期的Leader后,会主动降级为Follower。
一开始,集群内部只有一个Leader。后来发生了网络分区,L1无法向F3、F4与F5发送心跳。
总结:日志复制(数据同步)+ 领导者自动降级
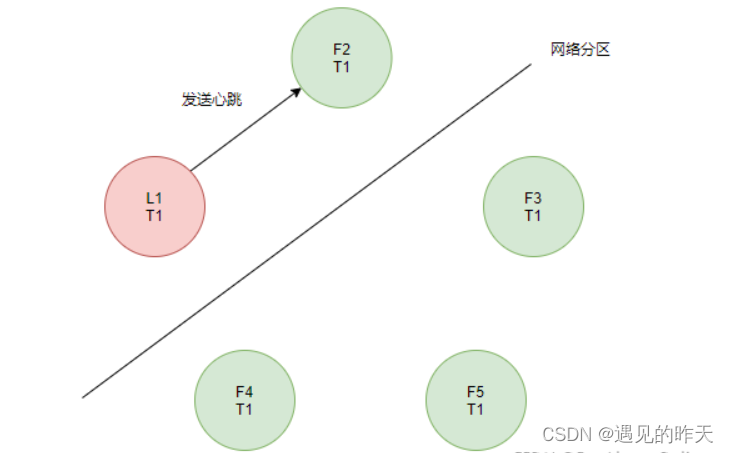
F3、F4与F5将会开启新一轮选举,接着F4获得当前所有的选票,即3份,为半数以上,当选为新的Leader。
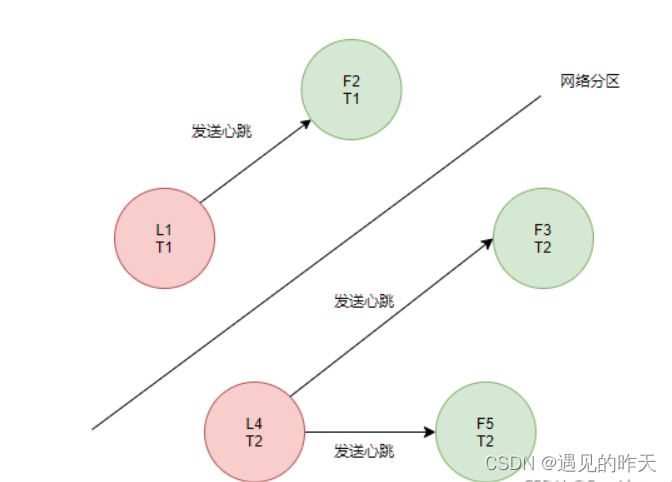
当网络分区结束后,集群内部会短暂的出现两个Leader的情况。
L1发现L4的任期比自己的大,于是主动降级为Follower,并接收来自L4的心跳。
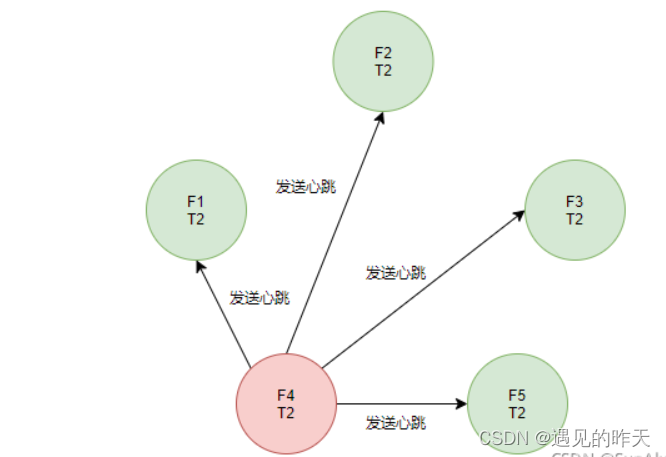
leader自动降级可以一定程度上解决,当然,脑裂的解决少不了日志复制技术
问题:如果有多个服务器节点,怎么保证一致性呢?
日志复制:主要用来实现节点数据同步,保证数据一致性的
1、日志结构
那么日志具有怎样的一个结构呢?
一份日志主要包含以下信息:
- 索引值,可以理解为该条日志在文件中所处的行号
- 任期编号,创建这条日志的Leader所处的任期
- 客户端的指令,在提交后,会被状态机执行
日志复制过程
因此Raft集群的重点在于Leader需要将自己的日志同步到Follower节点,以保证整个Raft集群的数据一致性。
这样我们在访问任意一个节点时,都能获得相同的返回数据。
一个简要的日志复制过程如下:
首先,经过一轮选举后,产生了一个Leader。
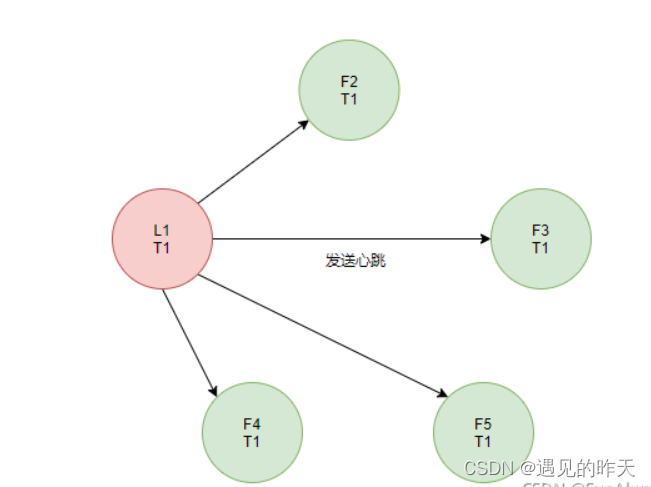
当L1接收到客户端的数据修改的指令后,首先会append到自己的本地日志中,状态为未提交,之后会向Follower节点发起append请求。
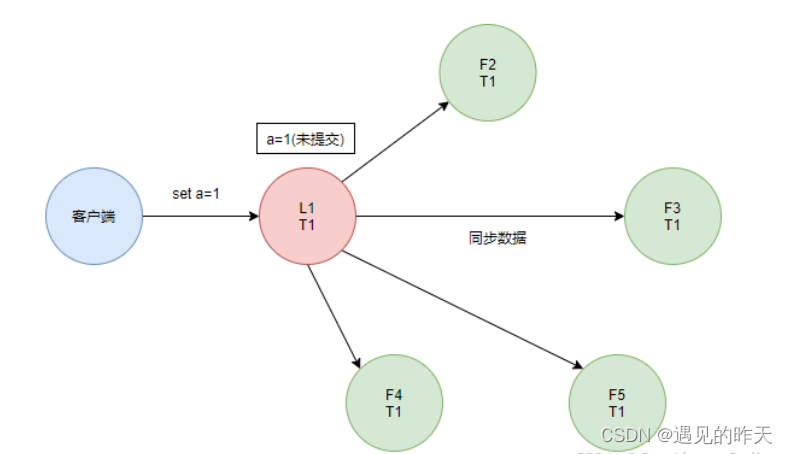
当Follower节点接收到append请求后,同样也会append到自己的本地日志中,状态为未提交。
注意: 当半数以上的Follower写入成功后,Leader会将日志提交,并应用到状态机中执行,同时回应客户端修改成功。
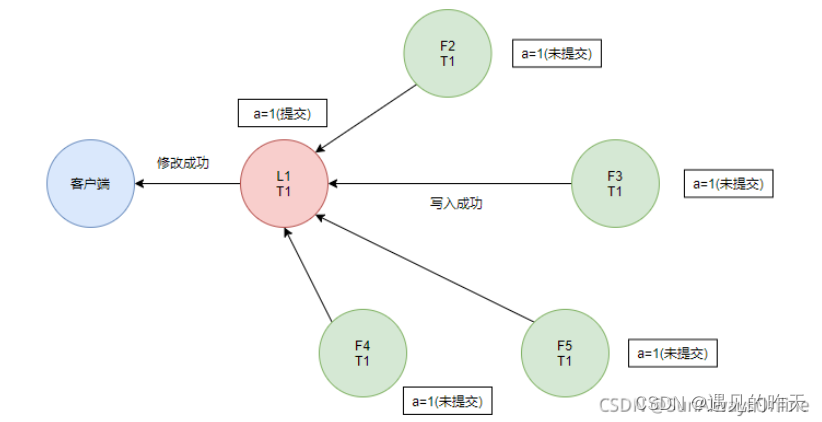
最后Leader通知Follower节点将日志提交
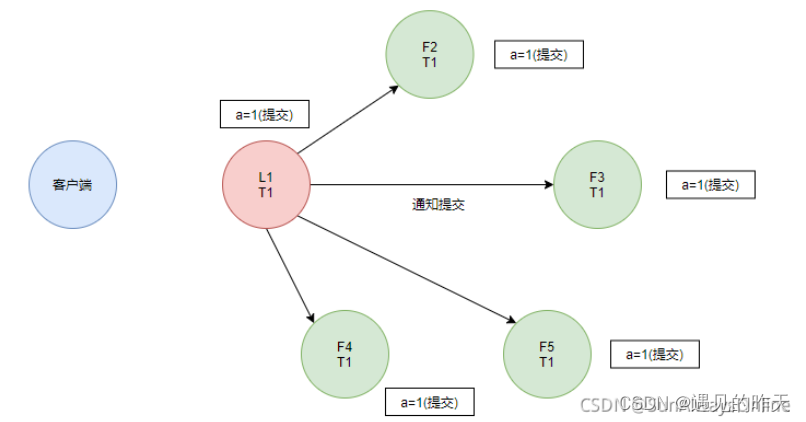
在这个时候,整个Raft集群实现了分布式的数据一致性。
我们整理一下日志复制的过程:
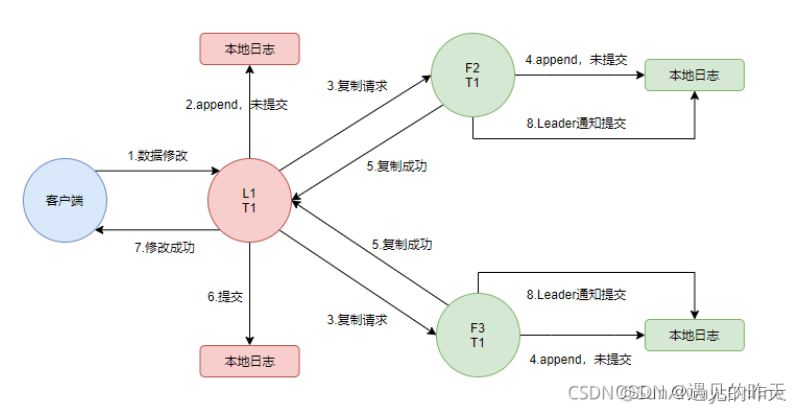
3、日志是如何保持一致的
上图描述的是一个在理想状态下的复制过程,在实际场景中,可能会出现Leader宕机、网络分区的情况,这些情况会导致日志的不一致,那么Raft是怎么保证日志的一致性的呢?
Raft集群是一个strong leader的系统,因此会强制Follower复制Leader的日志。
日志复制细节
Leader会在心跳信息中,将已提交的日志数据不断发送给Follower,复制请求中包含上一条日志的索引值与任期(记为L.pre.index与L.pre.term),当前日志的索引值与任期(记为L.cur.index与L.cur.term)。
Follower在收到复制请求后,先查找自身L.pre.index索引值的日志term,是否等于L.pre.term,如果等于,则将L.cur.index与L.cur.term追加到本地日志中,并返回复制成功。
如果Follower中L.pre.index索引值的日志term,不等于L.pre.term,则返回复制失败。此时Leader会将更前面一条的日志发送过来,如果依然复制失败,则继续往前,一直从后往前找到第一个共同的日志。并从这里开始往后复制,使得Follower与Leader的日志一致。
举个例子:
假设该集群在运行一段时间后,Leader与其中一个Follower的日志情况如下:
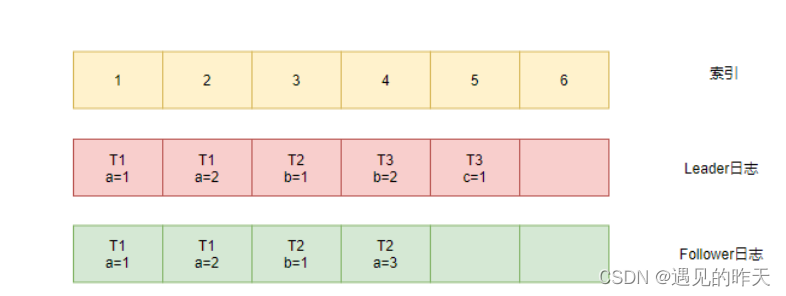
1、此时Leader需要Follower复制索引为5的日志,于是将索引4和5的日志一起发送给了Follower。
2、Follower发现索引4的日志,任期和Leader日志不一致,因此返回复制失败。
3、Leader发现复制失败后,将索引3和4的日志一起发送给了Follower。
4、Follower发现索引3的日志,任期是一致的,这就找到了和Leader共同的日志项,于是覆盖索引4的本地日志,返回复制成功。
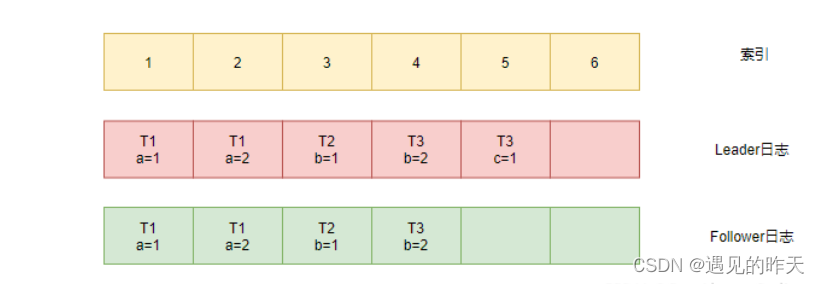
5、Leader发现复制成功,便不再往前递归寻找。
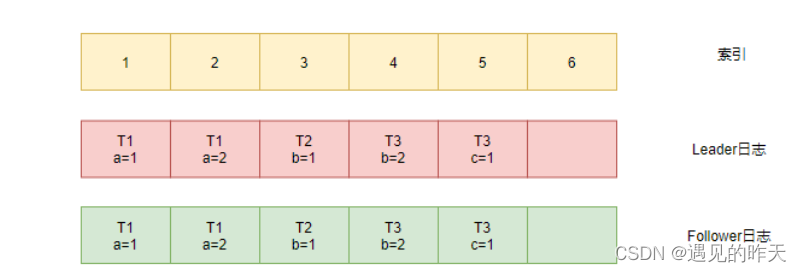
6、下一轮的心跳信息中,Leader将索引4和5的日志一起发送给了Follower。
7、Follower比对发现索引4的日志一致,于是将索引5的Leader日志追加到本地日志中,此时Leader与Follower的日志一致了。
参考
https://www.coonote.com/distributed-system/raft-algorithm.html
https://www.cnblogs.com/crazymakercircle/p/14343154.html#autoid-h2-1-8-0