直接发车🚗
一.雪崩
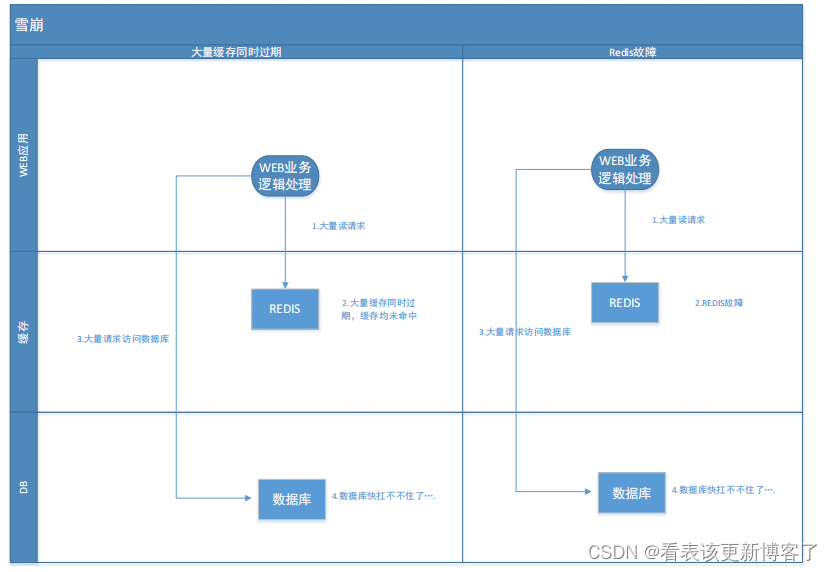
1.触发原因
A.大量缓存数据在同一时间过期(失效)
B.redis故障宕机
上述均导致全部请求去访问数据库,导致DB压力骤增,严重则导致数据库宕机/系统宕机
2.应对策略
不同触发原因,应对策略也不一致
应对A:
1.均匀设置过期时间
给这些key加个随机TTL,反正数据别同时过期就行
2.互斥锁
加锁时机:发现访问的数据不在Redis中,加个互斥锁🔒,锁住从数据库读取数据再将数据更新的redis里的这个过程(构建缓存),构建完成后再释放锁。
若未能拿到锁,要么等锁释放后读取缓存,要么返回空或默认值。
互斥锁时一定设置【超时时间】,防止其他请求一直拿不到锁的情况
3.双KEY策略
相当于给缓存数据做副本
俩KEY-VALUE,key不一致,value一致,备key设置永不过期(TTL = -1)
当业务线程访问不到【主key】的缓存数据时,返回【备Key】的数据,有效避免采用互斥锁(上述第二点)大量线程被锁住,后续再通知后台线程,重新构建【主key】数据。
4.后台更新缓存
让缓存永不过期,业务线程更新缓存的操作交给线程定时任务或者MQ。
虽然设置永不过期,但也存在系统内存紧张被淘汰的命运。
第一种方案:
后台线程不仅负责定时更新缓存,也负责频繁检测缓存是否有效(是否被淘汰),若失效则需要做数据库到缓存的同步(检测间隔不能太久最好毫秒级,无论如何有个间隔时间,用户体验不咋滴)
第二种方案: 业务线程若发现缓存失效,MQ发个消息来通知后台线程来更新缓存,比第一种方案更及时
应对B:
1.服务熔断机制
启动【**服务熔断**】机制,暂停业务应用对缓存服务的冲击,直接返回错误且不再访问数据库侧。(影响业务访问,影响业务使用)
2.请求限流机制
为减少对业务的影响,启用【**请求限流**】机制,只将少部分请求放过,再多的请求直接在入口出直接拒绝,等redis恢复且把缓存数据预热后再解除。
二.击穿
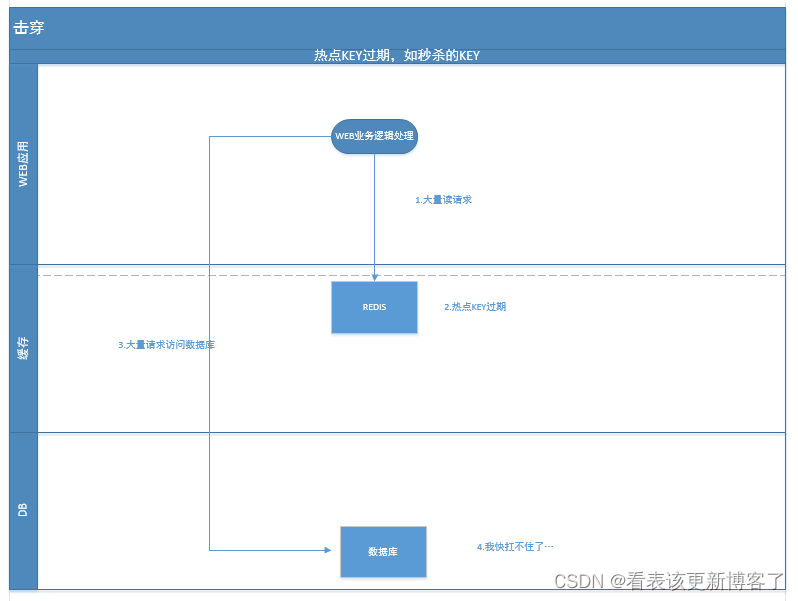
应对方案
1.互斥锁
2.热点Key永不过期,由后台异步更新缓存(当被淘汰时) / 热点数据准备过期时,提前通知后台线程更新缓存即重置过期时间
三.穿透
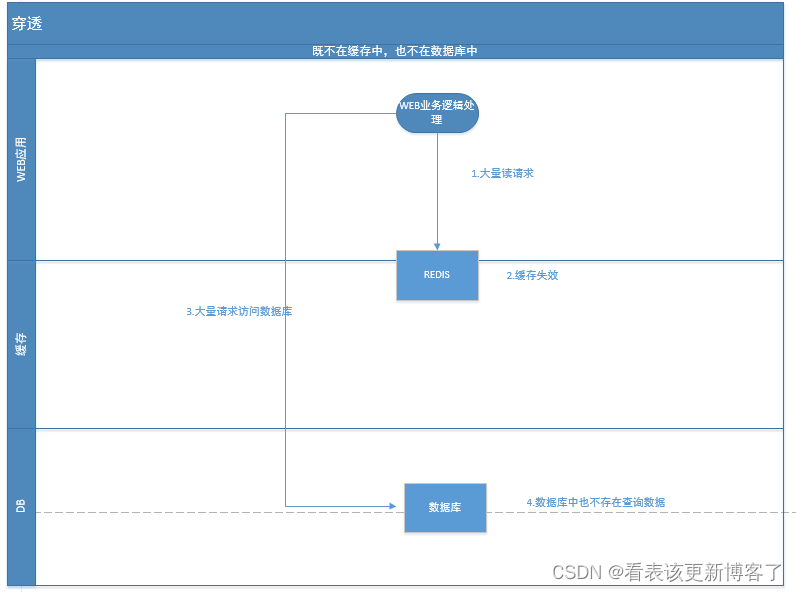
一般出现的两种情况
1.恶意攻击,故意访问大量读取不到的业务数据
2.业务误操作将缓存和数据库中的数据都删除了
应对方案
1.非法请求限制
判断参数合理性/参数中是否有非法值,若判断出时恶意请求直接响应错误
2.缓存空值/默认值
缓存空置或者默认值:若发现有缓存穿透的数据时,手动在缓存种存个默认值或空值
3.布隆过滤器
在写入数据库时,使用过滤器做个标记。当下次请求过来确认缓存失效后,再通过查询布隆过滤器判断数据是否存在,若不存在也不去查数据库了
总结
| 缓存异常 | 产生原因 | 应对方案 |
|---|---|---|
| 缓存雪崩 | 大量key同一时间过期 | 1.打散过期时间 2.互斥锁 3.双key策略 4.后台更新缓存,定时更新,消息通知更新 |
| redis故障宕机 | 1.服务熔断 2.请求限流 3.构建redis高可用集群 | |
| 击穿 | 频繁访问过期热点数据 | 1.互斥锁 2.热点数据永不过期 |
| 穿透 | 访问缓存和数据库种均不存在的数据 | 1.拦截非法请求 2.缓存空置或默认值 3.使用过滤器判断 |