基础介绍
Sentinel 的使用可以分为两个部分:
核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持(见 主流框架适配)。
提供核心库功能,可以在本地单机运行,只依赖JDK,适用于无分布式需求
控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
适用于分布式需求的情况
源码分析
环境准备
1. 引入 Sentinel 依赖
如果您的应用使用了 Maven,则在 pom.xml 文件中加入以下代码即可:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.6</version>
</dependency>
2. 定义资源
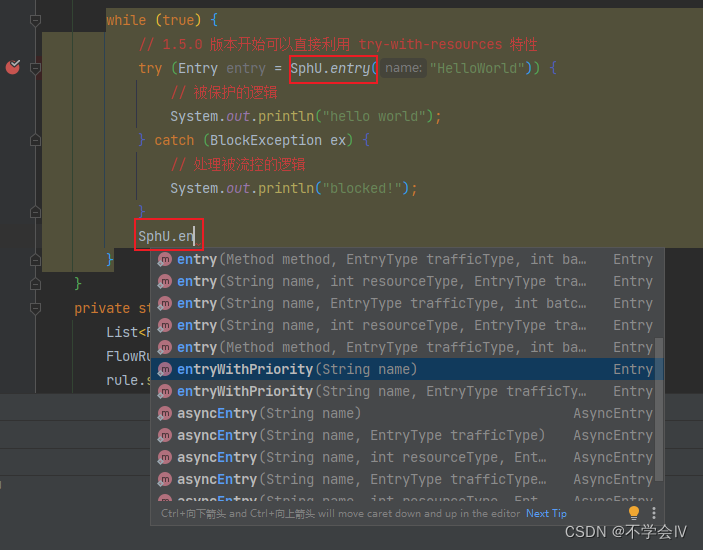
资源 是 Sentinel 中的核心概念之一。最常用的资源是我们代码中的 Java 方法。 当然,您也可以更灵活的定义你的资源,例如,把需要控制流量的代码用 Sentinel API SphU.entry(“HelloWorld”) 和 entry.exit() 包围起来即可。在下面的例子中,我们将 System.out.println(“hello world”); 作为资源(被保护的逻辑),用 API 包装起来。参考代码如下:
public static void main(String[] args) {
// 配置规则.
initFlowRules();
while (true) {
// 1.5.0 版本开始可以直接利用 try-with-resources 特性
try (Entry entry = SphU.entry("HelloWorld")) {
// 被保护的逻辑
System.out.println("hello world");
} catch (BlockException ex) {
// 处理被流控的逻辑
System.out.println("blocked!");
}
}
}
3. 定义规则
接下来,通过流控规则来指定允许该资源通过的请求次数,例如下面的代码定义了资源 HelloWorld 每秒最多只能通过 20 个请求。
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
完成上面 3 步,Sentinel 就能够正常工作了。更多的信息可以参考使用文档。
流程分析
1. FlowRuleManager
不做限流等实际操作,主要管理限流资源规则;
- 注册限流规则变化监听-DynamicSentinelProperty
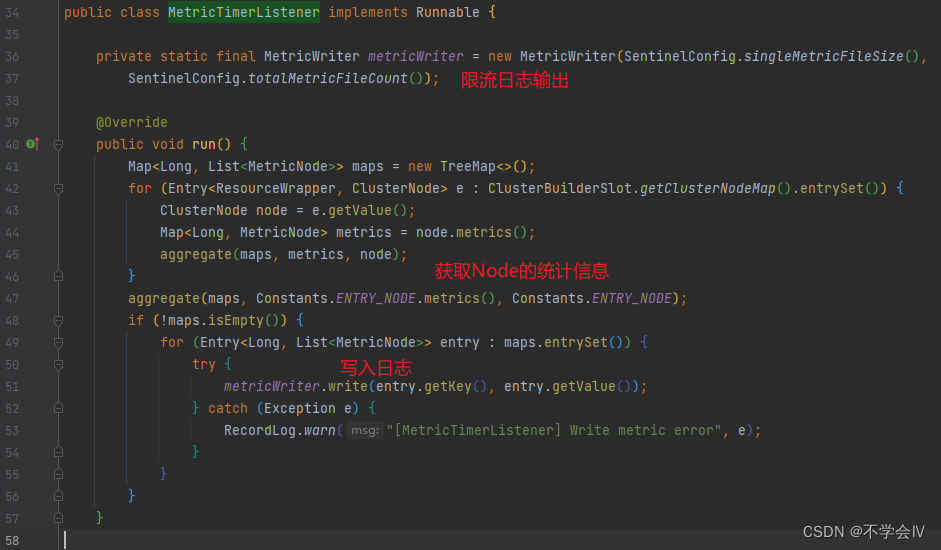
- 启动每秒(默认每秒)记录限流日志-ScheduledExecutorService MetricTimerListener
- 规则转换为Map,后去获取
定时记录日志
com.alibaba.csp.sentinel.node.metric.MetricTimerListener
2. SphU
用于记录统计数据和执行资源规则检查的API入口:
- 同步限流
- 异步限流
- 优先进入
2.1 主流程
- com.alibaba.csp.sentinel.Env: 初始化Sph实现类,初始化限流进入推出回调
- com.alibaba.csp.sentinel.CtSph#lookProcessChain 构建资源独立执行链,同资源共享
- com.alibaba.csp.sentinel.context.ContextUtil#trueEnter 构建上下文对象(独立,存储于ThreadLocal),独立使用
- 执行链:com.alibaba.csp.sentinel.slots.nodeselector.NodeSelectorSlot#entry 创建默认node(DefaultNode);
- 执行链:com.alibaba.csp.sentinel.slots.clusterbuilder.ClusterBuilderSlot#entry 创建ClusterNode
- 执行链:com.alibaba.csp.sentinel.slots.logger.LogSlot#entry 异常捕获后续操作,并输入日志
- 执行链:com.alibaba.csp.sentinel.slots.statistic.StatisticSlot#entry 后置统计线程数请求数等纤细信息
- 执行链-流控:com.alibaba.csp.sentinel.slots.block.authority.AuthoritySlot#entry 认证规则,根据请求来源做请求限制
- 执行链-流控:com.alibaba.csp.sentinel.slots.system.SystemSlot#entry 系统级别的限制规则 包括入站流量,平均CPU use、RT、QPS和线程数等
- 执行链-流控:com.alibaba.csp.sentinel.slots.block.flow.FlowSlot#entry 流控限制
- 执行链-流控: com.alibaba.csp.sentinel.slots.block.degrade.DegradeSlot#entry 性能检测决定是否进行降级
流控先关都已抛出指定异常决定是否结束执行链
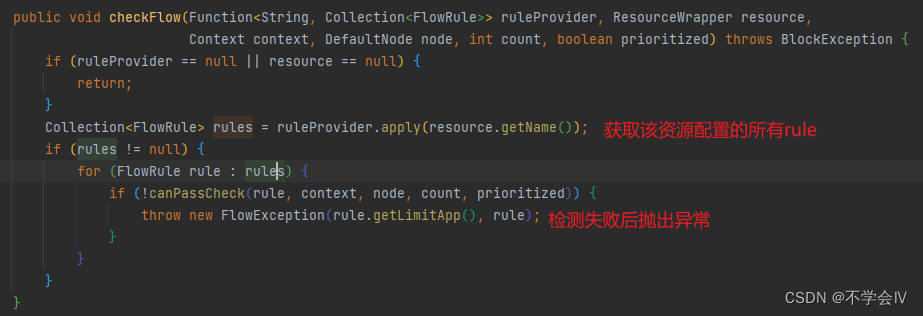
Node
主要用于标识资源(可细分标识)统计资源数据(QPS等各类数据);
DefaultNode: 默认同资源可能多种统计,可区分同资源下的更加细分;
ClusterNode: 同资源共享统计数据;
Node父类(StatisticNode)中包含Qps等数据的计算,那可以基本判断出限流算法也在这里实现
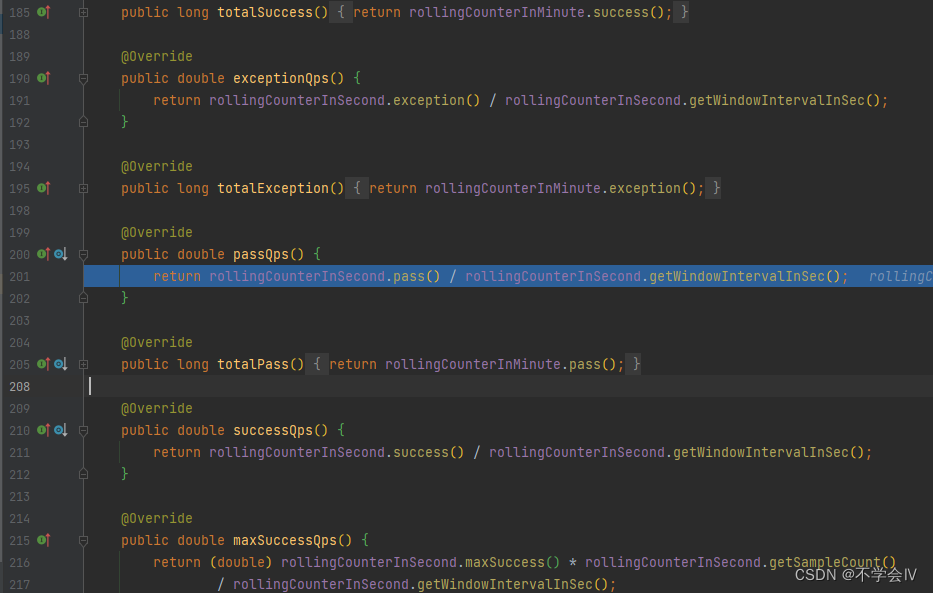
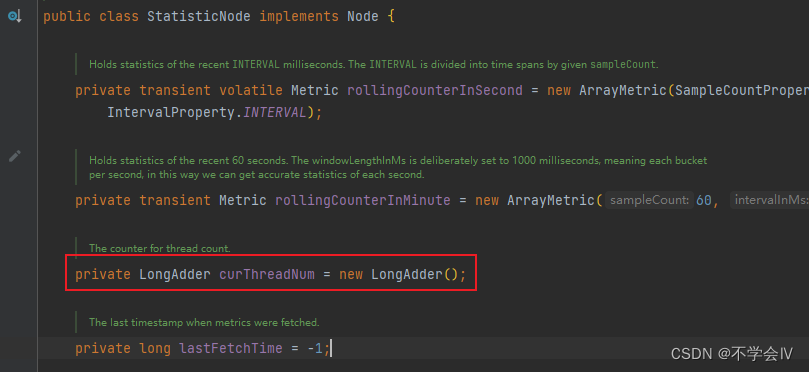
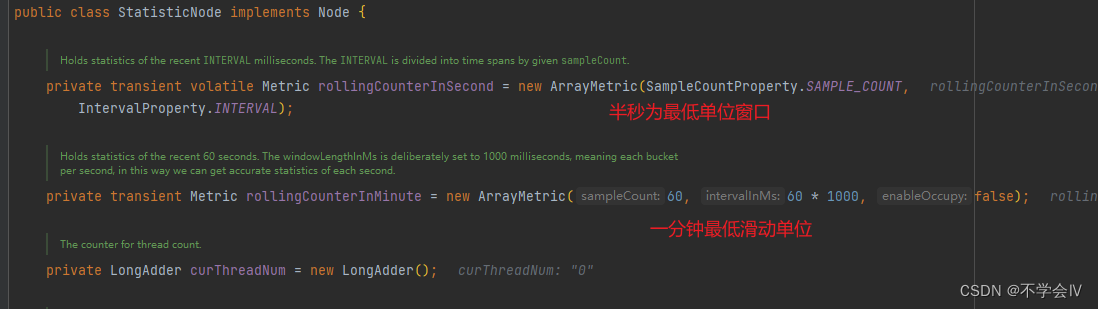
StatisticNode
作为统计数据决定限流的核心类,主要包括以下三种实时统计指标:
- 秒级度量(rollingCounterInSecond)
- 分钟级别的度量(rollingCounterInMinute)
- 线程数
使用滑动窗口实时记录和统计资源统计情况。ArrayMetric背后的滑动窗口基础设施是LeapArray。
滑动窗口
滑动窗口实时记录和统计资源统计情况。ArrayMetric背后的滑动窗口基础设施是LeapArray。
与滑动窗口的先关是: 令牌、漏桶等
下文是几个来自源码中的案例介绍
案例一
当第一个请求进入时,Sentinel将创建一个指定时间跨度的新窗口桶来存储运行的静态信息,例如总响应时间(rt),进入请求(QPS),块请求(bq)等。时间跨度由样本数量定义。
0 100ms
+-------+--→ Sliding Windows
^
|
request
Sentinel使用有效桶的静态信息来决定请求是否可以通过。例如,如果一个规则定义只能通过100个请求,它将对有效桶中的所有qps求和,并将其与rule中定义的阈值进行比较。
案例二
连续的请求
0 100ms 200ms 300ms
+-------+-------+-------+-----→ Sliding Windows
^
|
request
案例三
请求不断到来,之前的桶将失效
0 100ms 200ms 800ms 900ms 1000ms 1300ms
+-------+-------+ ...... +-------+-------+ ...... +-------+-----→ Sliding Windows
^
|
request
滑动窗口应该变成:
300ms 800ms 900ms 1000ms 1300ms
+ ...... +-------+ ...... +-------+-----→ Sliding Windows
^
|
request
其实不难理解: 如一秒内不能超过20个请求, 新的请求进来(1.23秒)计算的范围应该是当前往前0.23到.1.23,而不是固定的0到1,1到2,且窗口只能往前,不能因为并发后退;
具体实现
对于具体的滑动实现还是读者自己去看吧
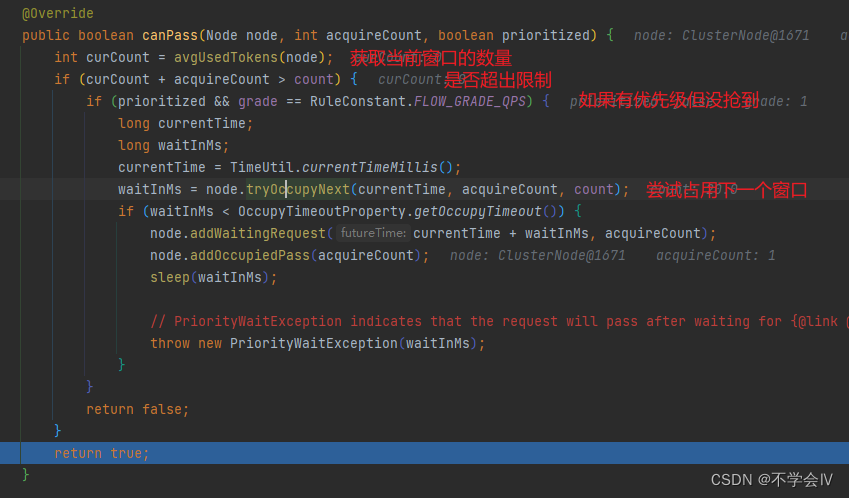
2、3点特性
同资源可以进入同一个执行链,但上下文的资源可以不同,以达到区分的效果;
context: 决定了node的创建,对于默认情况下该node只有一个用于统计信息,而在集群下,context决定了产生不同的node,用于区分集群下同资源的统计;
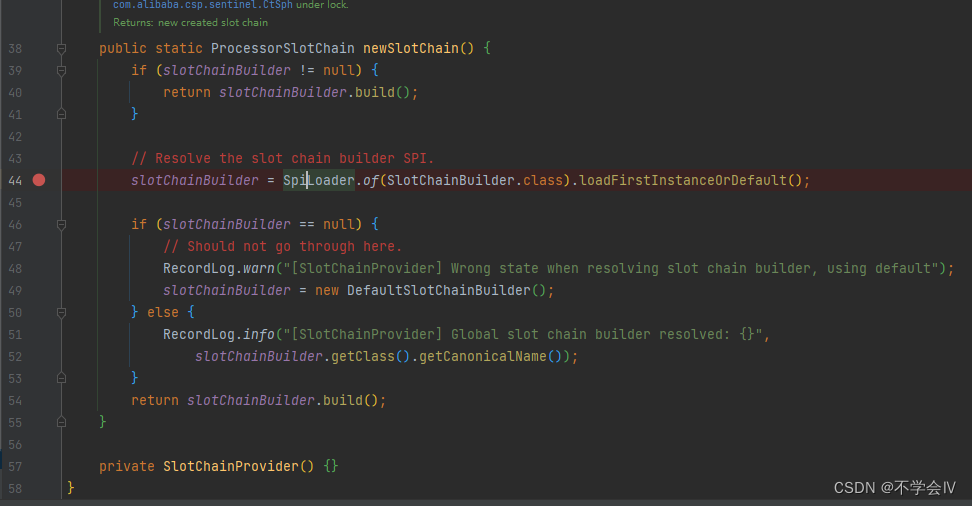
Spi(服务提供者接口模式)在基础服务中被基础使用
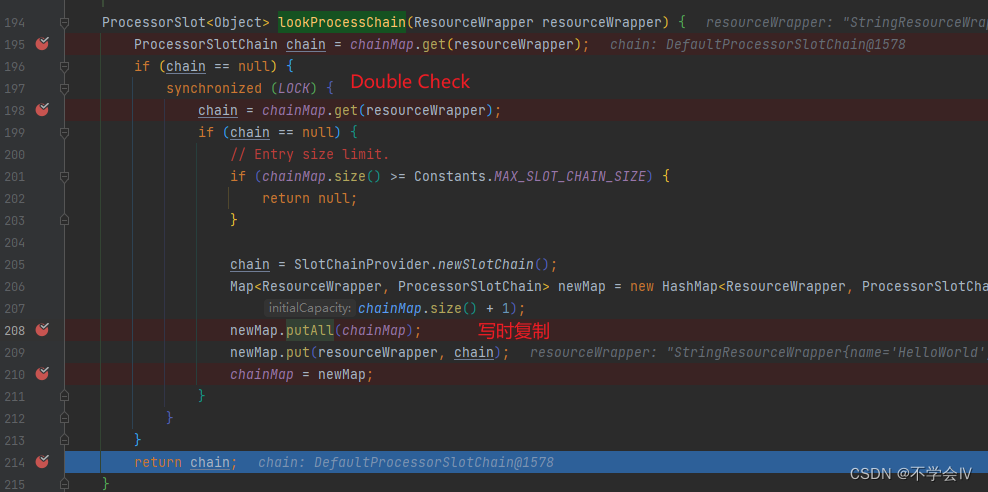
Double Check + 写时复制 被该项目大量使用
对于读多写少且写时都在锁内的map,使用该方法可以提升性能(需要加volatile)
使用LongAdder而非AtomicLong
在不要求增长保持连续性,而是作为统计,该类跟适合。使用数组中cas,减少锁竞争