日常我们在开发中,随着业务需求的变更,重构系统是很常见的事情。重构系统常见的一个场景是变更底层数据模型与存储结构。这种情况下就要对数据进行迁移,从而使业务能正常支行。
背景如下:老系统中使用了mongo数据库,由于目前缺乏运维人员,故需要将数据迁移到其他库中。
本文主要介绍技术数据迁移前技术选型。
对于NoSQL数据库,首先想到的MongoDB、ElasticSearch、Redis、HBase、ClickHouse,对于这五种数据库,到底该选择哪个?想必这是开发者在技术选型上遇到的难题。下面就先介绍下这五种热门数据库的优缺点及应用场景,更深刻的理解这几种数据库的特点,然后作出正确的数据库选择。
MongoDB
MongoDB最大特点是表结构灵活可变,字段类型可随时修改。MongDB中的每一行数据只是简单的被转化为JSON格式后存储。缺点当然是在多表查询、复杂事务等高级操作上表现欠佳。
Redis
对于redis,在研发项目中使用的就太多了,一般搭建的是Cluster集群模式,实现了分布式存储,在保证高可用中引入了主从模式。在使用过程中需要关注redis的热key问题(针对于这一点,目前我开发了热key探测,适量增加应用本身些许内存就彻底解决该问题,后续有详细的博文进行介绍)及大key问题。
ElasticSearch
ElasticSearch是一个近实时的分布式搜索分析引擎,它的底层存储完全构建在lucene之上, 其特点就是搜索,因此ES的方方页面也都是围绕搜索设计的。ES除了搜索外,还会自动的对所有字段建议索引,以实现高性能的复杂聚合查询,因此只要写入ES的数据,无论再复杂的聚合查询也可以得到不错的性能。
ES的写入,会经历write -> refresh -> flush -> merge等过程,只有refresh到文件缓存后,才能搜索可见,因此我们说ES是近实时搜索而非实时的原因。ES为了减少磁盘IO保证读写性能,每隔5s才会把lucene里的Segement进行持久化,为了保证数据不丢失,也借鉴了数据库的处理方式,增加了TransLog模块,在每一个shard中,写入流程分为两个部分,先写入luncene,再写入transLog(这里与Mysql中的WAL是相反的,留个思考题,Why?)
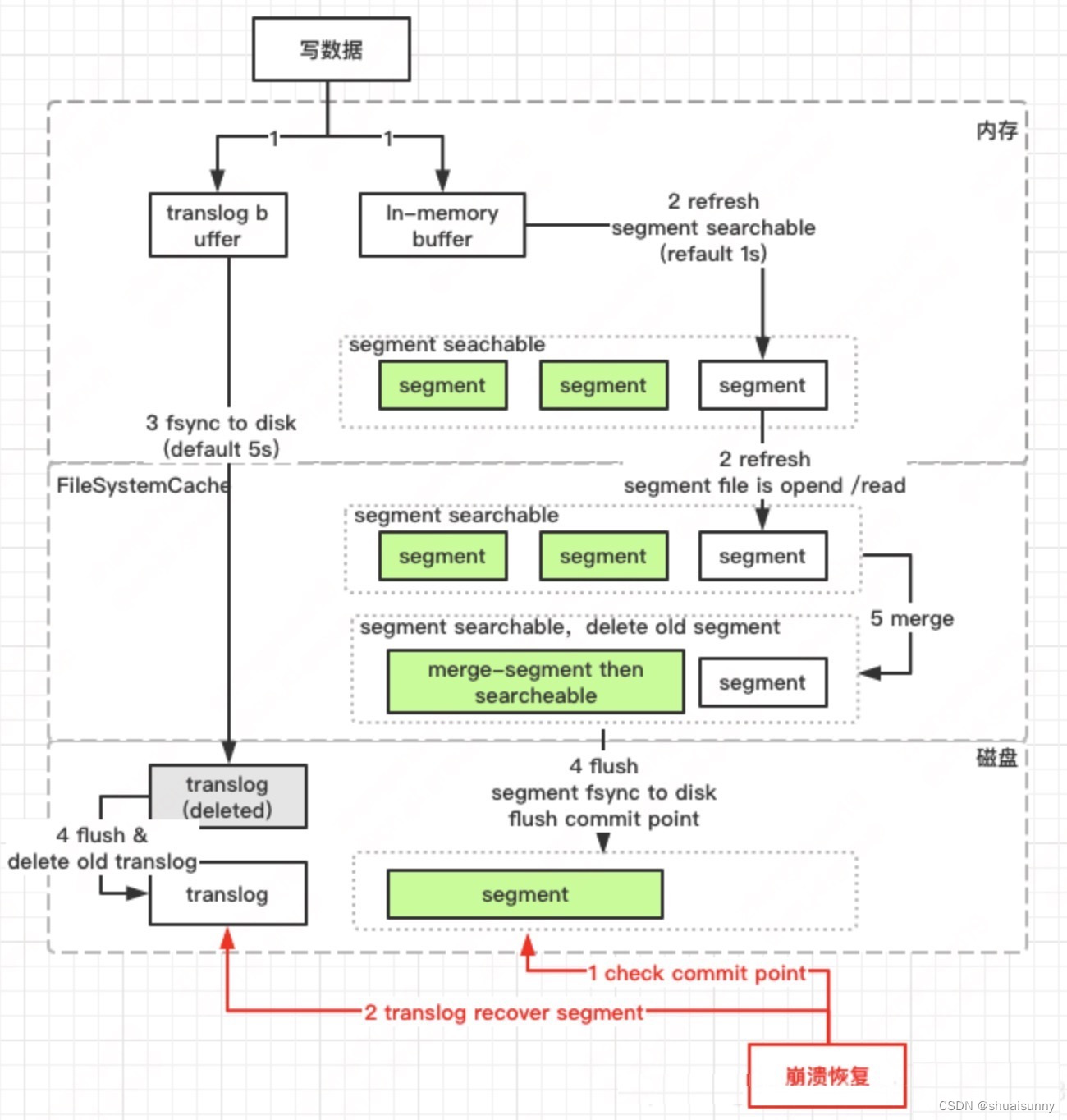
Es在变更主要时,采用『先查原记录-生成新记录-删除原记录-写入新记录』的方式,如果有冲突,通过版本号解决 ;对于ES的读,这里就不详细介绍。
总得来说,Elasticsearch的并发处理能力立足于内存Cache,比较依赖内存的,并且对内存的消耗较大,属于高硬件资源消耗,在性能优化方面,除了机器本身的性能,JVM调调优外,还可以结合业务采取数据预热、冷热分离、读写分离等等。
HBase
HBase是一种构建在HDFS之上的分布式、面向列的存储系统,每一行数据都有rowKey,本质上讲,HBase相当于把逻辑的一张大表按照列族分拆成若干小表分别进行存储,对于行簇当达到一定数量后也会再被拆分,这种存储特性带来了海量数据规模的支持和极强的扩展能力。缺点就是对于复杂的查询(如查询条件涉及多列或无法获取查询的rowKey)时查询效率是相当低下的。
优点:
(1) 继承了hadoop项目的优点,适合对海量数据的支持
(2) 极强的横向扩展能力
(3) 使用廉价的PC机就能够搭建起海量数据处理的大数据集群
缺点:
对数据的读取带来了局限,只有同一列族的数据才能够放在一起,而且所有的查询都必须依赖于key,这就使得很多复杂的查询难以实现
应用场景:
由于列式存储的能力带来了海量数据的容纳能力,因此非常适合数据量极大、查询条件简单、列与列之间联系不大的场景
ClickHouse
ClickHouse是战斗民族Yandex开发的完全列式存储计算的分析型数据库。与ES的写入相比,CK所有的数据写入时直接落盘,同时也就省略了传统的写redo日志阶段。在极高写入吞吐要求的场景下,es和CK都需要为了提升吞吐而放弃部分写入实时可见性。只不过CK主推的做法是把数据延迟批量写入交给客户端来实现,在多副本同步上,CK依赖于zk做异步的磁盘文件同步(data shipping),而es是实时同步(即写入请求必须写完多个副本才会返回,因此副本的数量对es的写入性能也是有影响的)。
上面提到CK是分析型数据库,这种场景,数据一般是不变的,因此CK对update、delete的支持较弱(通过alter方式异步实现)。
| HBase | ClickHouse | |
| 数据存储 | Zookeeper保存元数据,将数据写入HDFS中(非结构化的数据) | Zookeeper保存元数据,数据存储在本地,且会极致压缩 |
| 查询 | 使用Phoenix协助处理器 | 高效的查询能力 |
| 数据读写 | 支持随机读写,删除。更新操作是插入一条新的timestamp的数据 | 支持读写,但不能删除与更新 |
数据迁移方案:
在mongo数据迁移的过程中,上述哪一种存储方案都存在缺点,即然一种存储方案都不能有效解决,最好的方式就是组合,吸取每种存储的做点。目前存储在mongo的数据,属于读多写少的场景,数据量大,查询字段较固定,同时没有提供全文检索功能,考虑到降本等因素,最终选择的方案是mysql+hbase。其中mysql采取分库策略,存储查询的关键字组合+rowkey,hbase中保存文档的具体内容。
hbase非常适合存储PB级别的海量数据(百亿等级级条记录),如果根据rowKey来查询,能在几十到百毫秒内返回数据。另外,由于业务本身的特点,存放在hbase中的列属性主要包含两类数据,这两类数据适用于的业务场景也不同,列簇机制是最优选择。
总结
技术本身没有优劣之分,每种技术都是由业务决定的,最适合业务的技术才是最有价值的技术。