请记住,这个项目主要是为了稍微熟悉下Golang,您可以复制架构,但该项目缺少适当的 ORM,没有适当的身份验证或授权,我完全无视中间件,也没有测试。
我将在其自己的部分中讨论所有这些问题,但重要的是你要知道这还没有准备好投入生产。
如果我必须从头开始或重新制作项目,我会添加诸如 sqlx 和 Gorm 之类的库。 以及改进 API 和我在下面进行的其他更改。
此外,我想谈谈我正在使用的路由库:Fiber。 请注意,它是版本 2,但是很多教程和博客文章都在展示和谈论 v1,此后发生了一些变化,因此在查找其他信息时确保导入是 github.com/gofiber/fiber/v2。
此外,您绝对应该在项目中有一个配置文件和一个 .env 来隐藏您的数据。
README 中还有一个免责声明:
免责声明
这是一个介绍性的项目,可以稍微了解一下 Golang。 这个项目还没有准备好生产,它有不好的做法,比如分页的工作方式或我们与数据库的交互方式。
通过代码库,您会发现用于调试项目的不同“打印件”,请随意使用它们。 生产就绪缺少什么?
您应该添加适当的记录器、配置、中间件、处理数据的不同方式(可能是 ORM)、处理分页的更好方式以及更好的 API。
请注意,如果您复制并粘贴代码,可能会使自己容易受到 SQL 注入的攻击。 这是出于学习目的而制作的。
Database
您可能应该让 Docker 运行 MySQL(或任何其他 SQL 数据库)。 如果没有,你总是可以在你的系统上安装 MySQL 并使用像 MySQL Workbench 这样的东西来处理它。
Database design
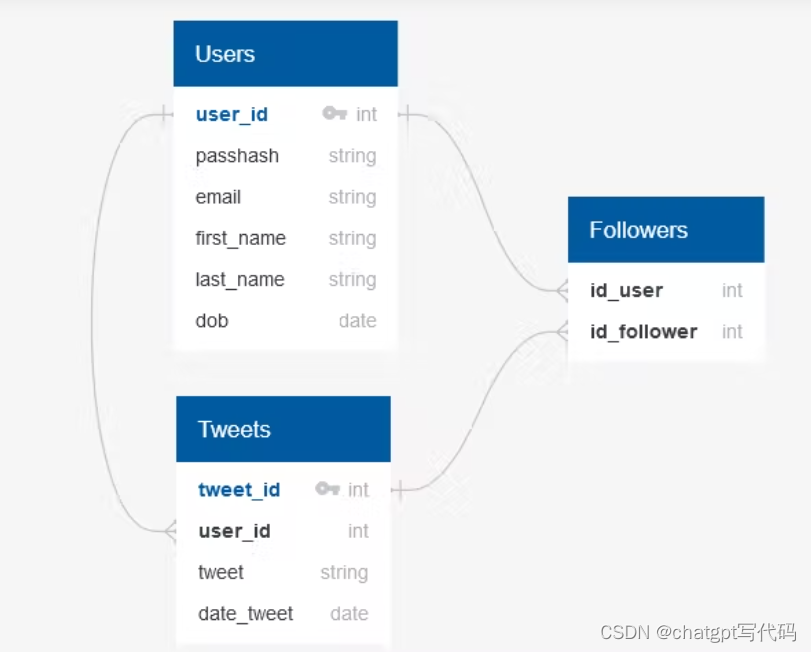
数据库本身相当简单,你有发布推文的用户和一个关注者表来保存谁关注谁的数据。关注者表主要是为我们的用户实现提要/时间线。
Create Database
在脚本文件夹中,您将找到运行以启动 MySQL 数据库的主要脚本:
use twitterdb;
DROP TABLE IF EXISTS tweets;
DROP TABLE IF EXISTS users;
DROP TABLE IF EXISTS followers;
CREATE TABLE users (
user_id INT NOT NULL AUTO_INCREMENT,
user VARCHAR(255) NOT NULL,
passhash VARCHAR(40) NOT NULL,
email VARCHAR(255) NOT NULL,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
dob DATE,
PRIMARY KEY (user_id)
);
CREATE TABLE tweets (
tweet_id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
tweet VARCHAR(140) NOT NULL,
date_tweet DATETIME NOT NULL,
PRIMARY KEY (tweet_id),
FOREIGN KEY user_id(user_id) REFERENCES users(user_id)
ON UPDATE CASCADE ON DELETE CASCADE
);
CREATE TABLE followers (
id_user INT NOT NULL REFERENCES users (user_id),
id_follower INT NOT NULL REFERENCES users (user_id),
PRIMARY KEY (id_user, id_follower)
);
INSERT INTO users (user, passhash, email, first_name, last_name, dob) VALUES
("foo", "asdsad1", "test@gmail.com", "bob", "bobbinson", "2006-01-01"),
("foo2", "asdsad2", "test2@gmail.com", "bob2", "bobbinson2", "1992-01-01"),
("foo3", "asdsad3", "test3@gmail.com", "bob3", "bobbinson3", "1993-01-01"),
("foo4", "asdsad4", "test4@gmail.com", "bob4", "bobbinson4", "1994-01-01"),
("foo5", "asdsad5", "test5@gmail.com", "bob5", "bobbinson5", "1995-01-01"),
("foo6", "asdsad6", "test6@gmail.com", "bob6", "bobbinson6", "1996-01-01"),
("foo7", "asdsad7", "test7@gmail.com", "bob7", "bobbinson7", "1925-01-01"),
("foo8", "asdsad8", "test8@gmail.com", "bob8", "bobbinson8", "1980-01-01"),
("foo9", "asdsad9", "test9@gmail.com", "bob9", "bobbinson9", "1980-01-01"),
("foo10", "asdsad10", "test10@gmail.com", "bob10", "bobbinson10", "1970-01-01");
INSERT INTO tweets(user_id, tweet, date_tweet) VALUES
(1, "test tweet", "2001-01-01 22:00:00"),
(2, "test tweet2", "2002-01-01 22:00:00"),
(3, "test tweet3", "2003-01-01 22:00:00"),
(4, "test tweet4", "2004-01-01 22:00:00"),
(5, "test tweet5", "2005-01-01 22:00:00");
INSERT INTO followers(id_user, id_follower) VALUES
(5,1),
(4,1),
(3,1),
(2,1),
(6,1),
(2,5),
(4,5);
其他文件是我们稍后将使用的查询示例。
Project Architecture
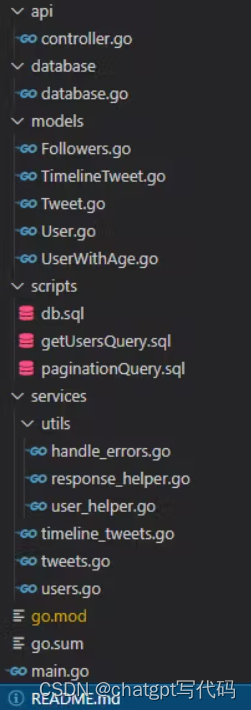
如果您熟悉构建软件,如果不熟悉这应该很熟悉,首先让我告诉您缺少什么,然后我们将遍历每个文件夹。
该项目缺少配置、中间件、记录器和测试等文件夹。 如果你能更好地组织控制器,你就会有一个路由文件夹,你可以更好地组织 API。
关于导入包的说明
在这个项目中,您可能会对以下导入感到困惑:
import (
"goexample/database"
"goexample/models"
"goexample/services/utils"
)
这里的 goexample 是项目的名称,我只是在之后重命名了我的 repo 这样它才有意义,所以我们使用“goexample/database”而不是“mini-twitter-clone/database”来导入数据库包。
对于任何其他新项目,只需使用文件夹的名称。
API
路由存储在 controller.go 中:
package api
import (
"goexample/services"
"github.com/gofiber/fiber/v2"
)
func SetupRoutes(app *fiber.App) {
api := app.Group("/api")
//get all unordened users
api.Get("/users", services.GetUsers)
//get all users ordered by age ASC
api.Get("/users/age", services.GetUsersByAgeAsc)
//get all unordened tweets from db
api.Get("/tweets", services.GetTweets)
//http://localhost:3000/api/feed/1
//get MOST RECENT feed/timeline for the user
api.Get("/feed/:id", services.GetFeedTweets)
//pagination
api.Get("/feed/:id/:limit/:offset", services.GetFeedTweetsPaginated)
//can try https://github.com/gofiber/fiber/issues/193#issuecomment-591976894
//a whole presentation on why you shouldn't do what I did:
//https://use-the-index-luke.com/no-offset
}
我正在使用类似于 Express 的 Fiber 库,这里我们有几个端点,我们通过 Get 请求调用这些端点,一旦服务器收到请求,它的响应就是调用我从服务包中公开的函数——那就是 我们的业务逻辑在哪里。
注意:分页未正确实现。
这只是一个简单的示例,此端点与其他端点一样存在安全问题,但您应该通过示例了解库和 Golang 的工作方式。
请注意,在 /feed/:id 中,id 参数与我们要为其获取提要的用户有关。
启动项目
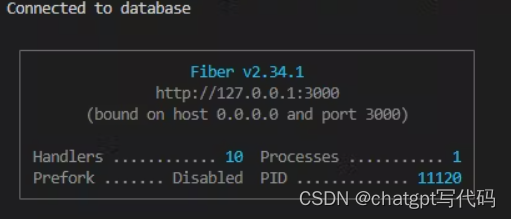
您可以通过执行 go run 来启动项目。 文件夹内。
您的终端应如下所示:
让我们访问不同的端点以查看响应,我将使用普通浏览,但如果您不熟悉调试后端,则应检查 Postman。
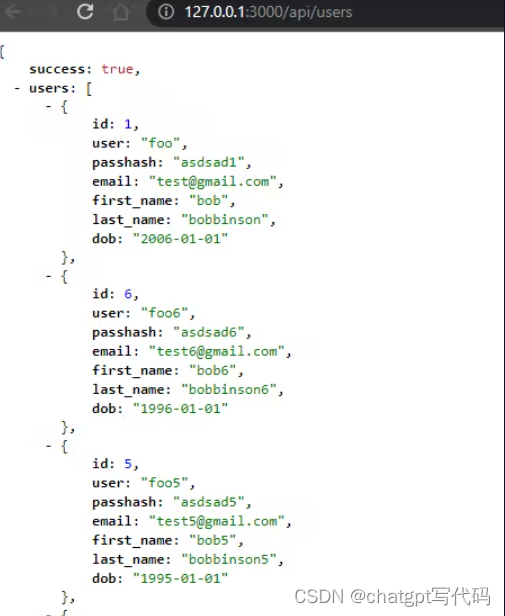
让我们从控制器运行端点:
http://127.0.0.1:3000/api/users
我留下了很多打印输出,所以如果你在每次通话时检查你的终端,你应该会看到如下内容: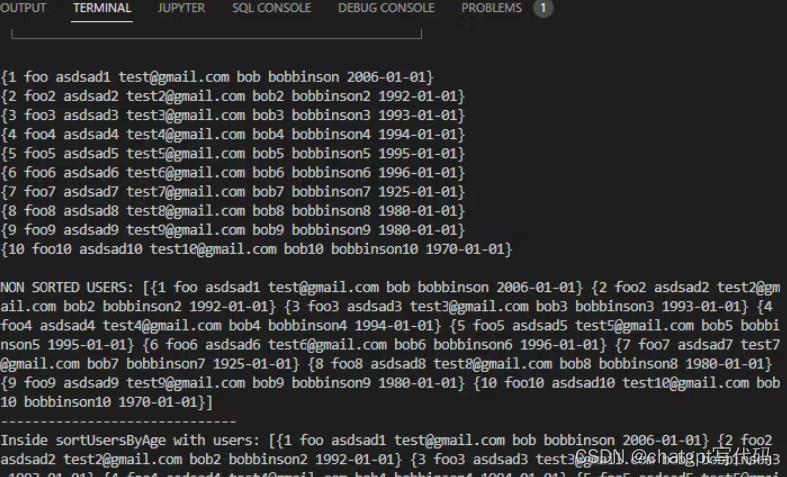
接下来是我们按年龄对用户排序的调用:
http://127.0.0.1:3000/api/users/age
当我们请求推文时,我们会得到所有的推文:
http://127.0.0.1:3000/api/tweets
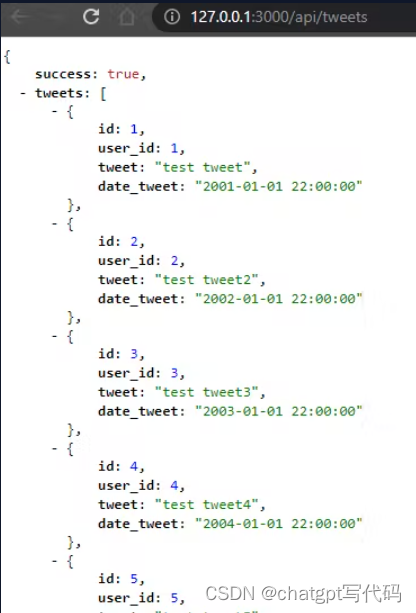
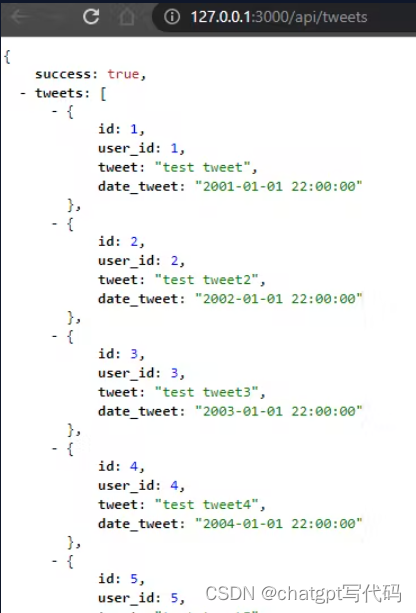
现在我们获取 ID 为 1 的用户的提要或时间线:
http://127.0.0.1:3000/api/feed/1


请记住,分页尚未准备好生产,但核心概念是相同的:
http://127.0.0.1:3000/api/feed/1/2/1

由于我们在服务包中的业务逻辑和我们公开的功能,所有调用都能正常工作。
Services
在服务包中,我们有当某人或某物点击其中一个端点时调用的函数。 请记住,我们通过在包中使用大写字母来公开功能。
让我们看一下 timeline_tweets.go,它包含 controller.go 文件中两个不同端点的两个函数:
package services
import (
"fmt"
"goexample/database"
"goexample/models"
"goexample/services/utils"
"log"
"github.com/gofiber/fiber/v2"
)
func GetFeedTweets(c *fiber.Ctx) error {
//you shouldn't do this by the way, but it's just a demo
// dbQuery := fmt.Sprintf("SELECT users.user_id, users.user, users.first_name, users.last_name, tweets.tweet, tweets.date_tweet FROM users INNER JOIN tweets ON users.user_id = tweets.user_id INNER JOIN followers ON users.user_id = followers.id_user WHERE followers.id_follower = %s ORDER BY tweets.date_tweet DESC;", c.Params("id"))
// rows, err := database.DB.Query(dbQuery)
//avoid the SQL injection by rewriting it like
dbQuery := "SELECT users.user_id, users.user, users.first_name, users.last_name, tweets.tweet, tweets.date_tweet FROM users INNER JOIN tweets ON users.user_id = tweets.user_id INNER JOIN followers ON users.user_id = followers.id_user WHERE followers.id_follower = ? ORDER BY tweets.date_tweet DESC;"
rows, err := database.DB.Query(dbQuery, c.Params("id"))
//check for errors
if err != nil {
return utils.DefaultErrorHandler(c, err)
}
//close db connection
defer rows.Close()
//create a slice of tweets
var timelineTweets []models.TimelineTweet
//loop through the result set
for rows.Next() {
timelineTweet := models.TimelineTweet{}
err := rows.Scan(&timelineTweet.User_id, &timelineTweet.User, &timelineTweet.First_name, &timelineTweet.Last_name, &timelineTweet.Tweet, &timelineTweet.Date_tweet)
if err != nil {
log.Fatal(err)
}
timelineTweets = append(timelineTweets, timelineTweet)
}
fmt.Print(timelineTweets)
utils.ResponseHelperJSON(c, timelineTweets, "timeline", "No timeline found")
return err
}
func GetFeedTweetsPaginated(c *fiber.Ctx) error {
// dbQuery := fmt.Sprintf("SELECT users.user_id, users.user, users.first_name, users.last_name, tweets.tweet, tweets.date_tweet FROM users INNER JOIN tweets ON users.user_id = tweets.user_id INNER JOIN followers ON users.user_id = followers.id_user WHERE followers.id_follower = %s ORDER BY tweets.date_tweet DESC LIMIT %s OFFSET %s;", c.Params("id"), c.Params("limit"), c.Params("offset"))
// avoid a SQL injection by rewriting it like
dbQuery := "SELECT users.user_id, users.user, users.first_name, users.last_name, tweets.tweet, tweets.date_tweet FROM users INNER JOIN tweets ON users.user_id = tweets.user_id INNER JOIN followers ON users.user_id = followers.id_user WHERE followers.id_follower = ? ORDER BY tweets.date_tweet DESC LIMIT ? OFFSET ?;"
rows, err := database.DB.Query(dbQuery, c.Params("id"), c.Params("limit"), c.Params("offset"))
if err != nil {
return utils.DefaultErrorHandler(c, err)
}
defer rows.Close()
var timelineTweets []models.TimelineTweet
for rows.Next() {
timelineTweet := models.TimelineTweet{}
err := rows.Scan(&timelineTweet.User_id, &timelineTweet.User, &timelineTweet.First_name, &timelineTweet.Last_name, &timelineTweet.Tweet, &timelineTweet.Date_tweet)
if err != nil {
log.Fatal(err)
}
timelineTweets = append(timelineTweets, timelineTweet)
}
//TODO: implement a response with pages and all that pagination jazz
utils.ResponseHelperJSON(c, timelineTweets, "timeline", "No timeline found")
return err
}
您首先注意到的是我们如何将上下文传递给 GetFeedTweets,然后我们使用变量“c”来使用 Fiber 库所说的上下文。
之后,我们使用包数据库中公开的变量 DB 打开 DB,读取数据,然后关闭它。
为了正确存储和扫描数据,我们使用模型包中的结构。
之后您将看到 utils 包中的几个函数。 这些函数主要是辅助函数,因此您可以查看 Golang 如何执行循环和某些其他操作。
我们的服务包中的其他两个文件非常相似,我们在这里的工作是从数据库中获取数据,通过我们的结构数组扫描它,然后以 JSON 格式将其发送回用户。 以及我们运行 utils 包中的一些功能。
Utils
这个包包含辅助函数,也许最有趣的是在 user_helper 里面,因为它有与切片数据交互的函数,但是要小心,它们的实现并不像你想象的那么好。
让我们看看最有帮助的,response_helper.go
package utils
import (
"github.com/gofiber/fiber/v2"
)
//response JSON for services after you loop and scan
func ResponseHelperJSON(c *fiber.Ctx, data any, dataType string, dataError string) {
if data != nil {
c.Status(200).JSON(&fiber.Map{
"success": true,
dataType: data,
})
} else {
c.Status(404).JSON(&fiber.Map{
"success": false,
"error": dataError,
})
}
}
请注意,此函数包含通用类型的数据,因为我使用关键字 any 并且我正在与 Fiber 通过变量“c”提供的上下文进行交互。
Models
models 文件夹包含我们用作与数据库交互的实体的不同结构,如 services 文件夹中所示。
这是一个示例,请注意,即使您想公开整个结构,所有内容都必须以大写字母开头:
package models
type UserWithAge struct{
Id int `json:"id"`
User string `json:"user"`
Passhash string `json:"passhash"`
Email string `json:"email"`
First_name string `json:"first_name"`
Last_name string `json:"last_name"`
Age int `json:"age"`
}
Database
数据库包非常简单,请记住使用配置文件和 .env 来存储您的敏感数据。
package database
import (
"database/sql"
"fmt"
"log"
)
var DB *sql.DB
func Connect() error{
var err error
//use a config file for this
DB, err = sql.Open("mysql", "root:password@tcp(127.0.0.1:3306)/twitterdb")
if err != nil {
log.Fatal(err)
return err
}
if err = DB.Ping(); err != nil {
log.Fatal(err)
return err
}
fmt.Println("Connected to database")
return nil
}
Main.go
最后,这是我们启动服务器的地方:
package main
import (
"github.com/gofiber/fiber/v2"
"goexample/database"
"log"
"goexample/api"
_ "github.com/go-sql-driver/mysql"
)
func main() {
if err := database.Connect(); err != nil {
log.Fatal(err)
}
app := fiber.New()
api.SetupRoutes(app)
log.Fatal(app.Listen(":3000"))
}
](https://img-blog.csdnimg.cn/img_convert/914a48b3530bdee084a8a9f3fe95c50a.png)