文章目录
- Requests库网络爬虫
- requests.get()的基本使用框架
- requests.get()的带异常处理使用框架(重点)
- requests库的其他方法和HTTP协议(非重点)
- requests.get()的可选参数
- 网络爬虫引发的问题(非重点)
- 常见问题:网页禁止Python爬虫访问
Requests库网络爬虫
Requests库概述:Requests库是最简单和最基础的Python网络爬虫库,该库提供了七种主要方法。这七种方法中,request方法是最基础的,其他方法都是通过调用request方法来实现的。
requests.get()的基本使用框架
基本语法:r=requests.get(url)
语法解释:构造一个向服务器请求资源的Request对象,返回值是一个包含服务器资源的Response对象。
完整形式语法:requests.get(url,params=None,**kwargs)
- params:在url中增加的额外参数,是可选的参数。
- **kwargs:12个控制访问的参数。
Response对象的属性:
- status_code:状态码。是200表示访问成功,不是200表示访问失败。
- header:网页的头部
- List item
信息。
- text:HTTP响应的字符串形式,也就是url对应的页面内容。
- encoding:从HTTP的头部所猜测的网页编码方式。如果header中不存在charset字段,则默认编码方式为ISO-8859-1。
- apparent_encoding:从HTTP响应的内容中分析出的编码方式。往往需要用apparent_encoding来替代encoding。
- content:HTTP响应内容的二进制形式。
使用get方法的基本流程:检查网页状态码,如果是200则继续,否则产生异常;
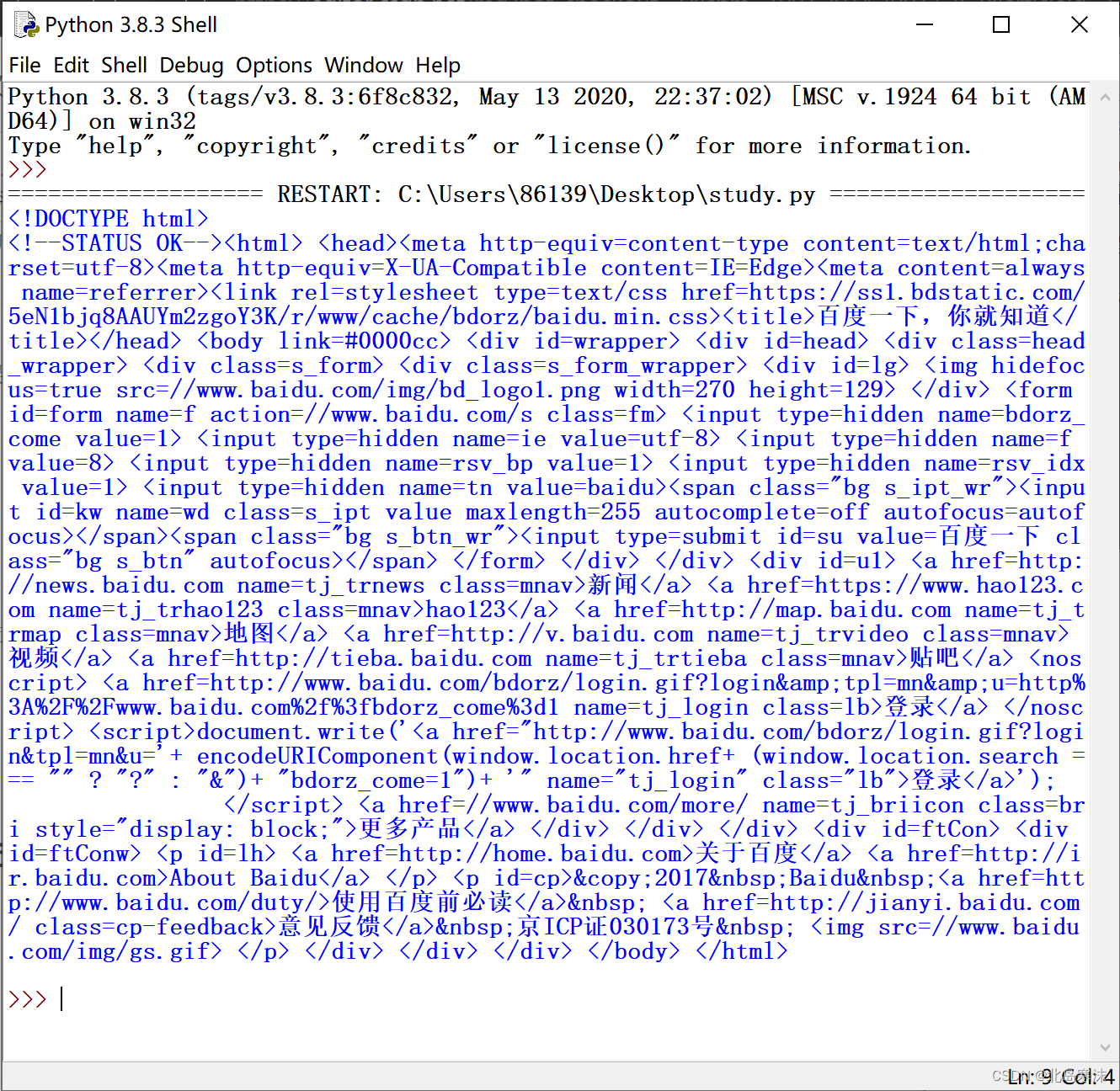
get方法使用的完整例子(爬取百度主页):
# 首先需要导入requests库
import requests
# 使用get方法爬取百度主页的内容
r=requests.get("https://www.baidu.com")
# 判断网页访问是否成功
if r.status_code==200: # 网页访问成功
# 如果header中不存在charset字段,则encoding采用默认编码方式,很可能解析错误
if r.encoding=="ISO-8859-1":
# 将网页内容编码方式修改成从内容分析出的编码方式
r.encoding=r.apparent_encoding
# 输出网页信息
print(r.text)
# 网页访问失败
else:
print("网页访问失败!")
运行效果:
requests.get()的带异常处理使用框架(重点)
上面的内容中我们通过if语句来判断状态码从而进行后续的步骤,但是状态码的判断本身应该属于异常处理的范畴,通过if语句判断会破坏程序的主体框架,因此有必要使用异常处理的方法来判定状态码。
Requests库的六种常用异常:
- ConnectionError:网络连接错误异常,如DNS查询失败和拒接连接等。
- HTTPError:HTTP错误异常。
- URLRequired:URL缺失异常。
- TooManyRedirects:由于超过最大重定向次数导致的重定向异常。
- ConnectTimeOut:连接远程服务器超时异常。
- TimeOut:请求URL超时产生的超时异常。
raise_for_status方法:如果Response对象的状态码不是200,则产生HTTPError异常。
经过改进的get方法使用例子:
# 首先需要导入requests库
import requests
# 使用get方法爬取百度主页的内容
r=requests.get("https://www.baidu.com")
# 对可能抛出异常的部分放入try块中
try:
# 检测Response对象的状态码,判断是否抛出异常
r.raise_for_status()
# 如果header中不存在charset字段,则encoding采用默认编码方式,很可能解析错误
if r.encoding=="ISO-8859-1":
# 将网页内容编码方式修改成从内容分析出的编码方式
r.encoding=r.apparent_encoding
# 输出网页信息
print(r.text)
# 检测到异常后执行的语句
except:
print("网页访问失败!")
requests库的其他方法和HTTP协议(非重点)
HTTP概述:
- 定义:超文本传输协议,是一个基于请求和响应模式的、无状态的应用层协议。
- URL:HTTP协议采用URL作为定位网络资源的标识,也就是一个URL就对应一个数据资源。
URL格式:https://host[:port][path]
- host:合法的Internet主机域名或IP地址;
- port:端口号,默认端口号为80。
- path:请求资源的路径。
Reuquests库的其他方法:
- request():构造一个请求,是支撑以下各个方法的基础方法。
- get():获取HTML网页的主要方法。
- head():获取HTML网页头部信息的方法。在一些网页资源很大时可以采用此方法以节约带宽。
- post():向HTML网页提交POST请求的方法。可以在URL位置的资源后增加新的数据。
- put():向HTML网页提交PUT请求的方法。向URL位置存储一个资源,覆盖原先URL位置的资源。
- patch():向HTML网页提交局部修改请求的方法。修改该处资源的部分内容。
- delete():向HTML网页提交删除请求的方法。请求删除URL位置存储的资源。
requests.get()的可选参数
params:
- 内容:字典或字节序列,作为参数增加到URL中。
- 作用:将一些键值对增加到URL中,使得访问URL时能够对资源进行筛选。
data:字典、字节序列或文件对象,主要用于向服务器提交内容。
json:
- 内容:json格式的数据(也是HTTP协议最常使用的数据格式)
- 作用:可以作为内容部分向服务器提交。
head:
- 定制访问某个URL的HTTP协议的协议头。
- 可以模拟任何浏览器的任何版本对网站进行访问。
timeout:
- 内容:设置超时时间,以秒为单位。
- 作用:如果超过指定时间内还没有访问成功,将产生TimeOut异常。
proxies:
- 内容:字典类型,设置访问的代理服务器;
- 作用:使用该字段可以有效隐藏用户爬取网页的源IP地址信息。
网络爬虫引发的问题(非重点)
网络爬虫的分类:
- 小规模爬虫:以爬取网页为目的,数据量小,对爬取速度不敏感。类型代表:Requests库。
- 中规模爬虫:用于爬取系列网站,数据量较大,对爬取速度敏感。典型代表:Scrapy库。
- 大规模爬虫:爬取速度非常关键,对于所有网络信息进行爬取,只能定制开发而不能借助第三方库。典型代表:搜索引擎。
网络爬虫带来的问题:
- 资源开销:受限于编写水平和目的,网络爬虫会给Web服务器带来巨大的资源开销。
- 法律风险:服务器上的数据可能有产权归属,因此使用网络爬虫获取数据可能带来法律风险。
- 隐私泄露:网络爬虫可以突破简单的访问控制,从而获得个人被保护的数据。
网络爬虫的限制:
- 来源审查:检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问。
- 发布Robots协议:告知所有爬虫网站的爬取策略,要求爬虫遵守。
Robots协议:
- 全称:网络爬虫排除标准;
- 作用:告知网络爬虫哪些界面可以抓取,哪些不行;
- 形式:在网站根目录下的robots.txt文件。
- 举例(百度的Robots协议):www.baidu.com/robots.txt

备注:Robots协议是建议而非约束性的,也就是说网络爬虫可以不遵守Robots协议,但是这样可能带来法律风险。如果一个网络爬虫的访问次数和人类访问类似,那么从原则上可以不遵守Robots协议。
常见问题:网页禁止Python爬虫访问
解决方法:设置get函数的header参数,将爬虫伪装成浏览器来访问网页。
方法举例:
-
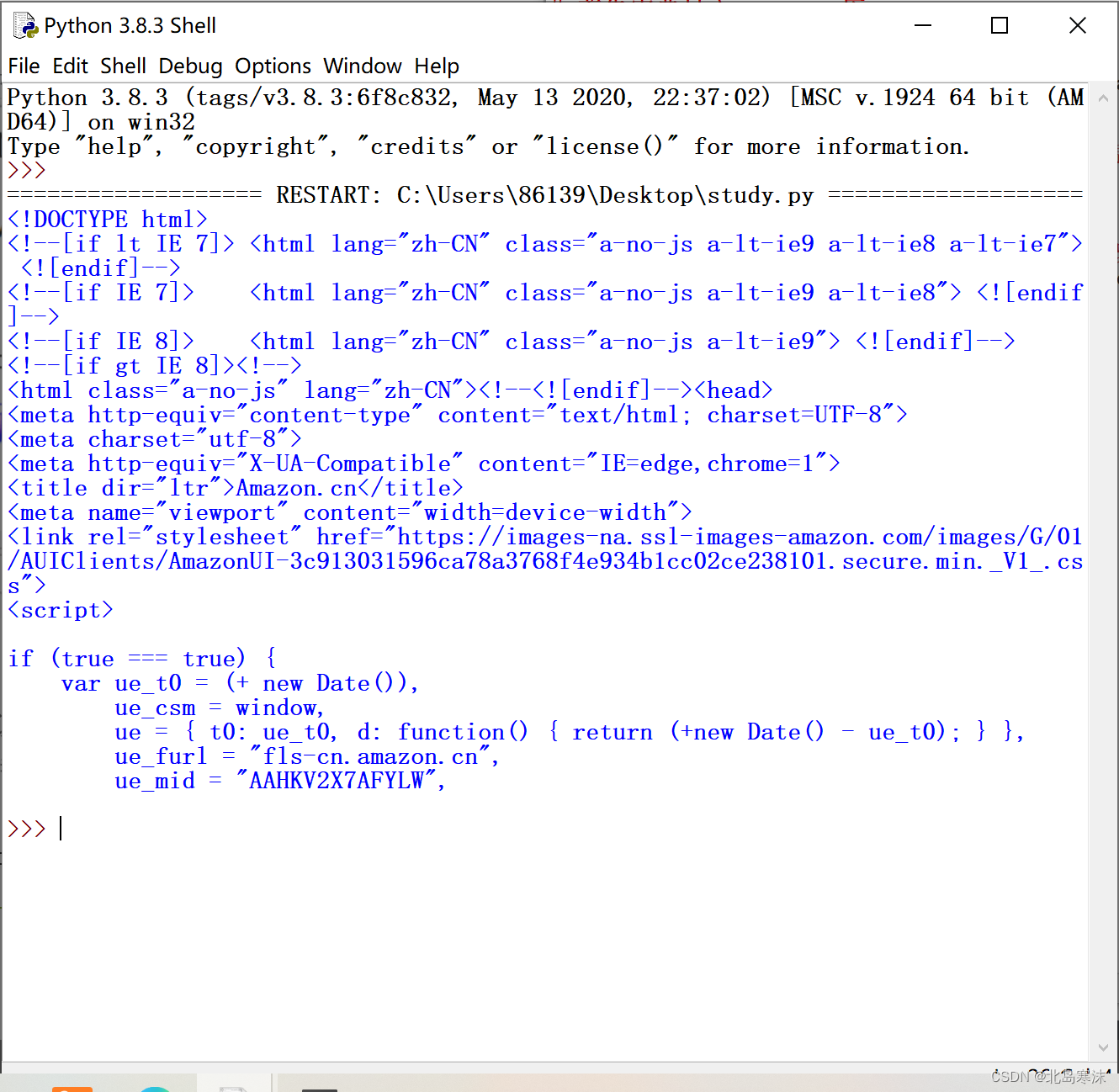
直接使用Requests爬虫访问亚马逊商城的官网主页,访问失败。

-
在get方法中设置headers参数的内容,模拟使用版本号为5的Mozilla浏览器进行访问(其他内容都不用修改)。
r=requests.get("https://www.amazon.cn/",headers={"user-agent":"Mozilla/5.0"})
- 网页爬取成功(只截取了部分爬取内容)。