数据湖
数据仓库
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
数据仓库的特点是本身不生产数据,也不最终消费数据。
每个企业根据自己的业务需求可以分成不同的层次。但是最基础的分层思想,理论上分为三个层:操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。

数据湖
数据湖(Data Lake)和数据库、数据仓库一样,都是数据存储的设计模式,现在企业的数据仓库都会通过分层的方式将数据存储在文件夹、文件中。数据湖是一个集中式数据存储库,用来存储大量的原始数据,使用平面架构来存储数据。
数据湖的主要思想是对企业中的所有数据进行统一存储,数据湖的就是原始数据保存区,从原始数据(源系统数据的精确副本)转换为用于报告、可视化、分析和机器学习等各种任务的目标数据。数据湖中的数据包括结构化数据(关系数据库数据),半结构化数据(CSV、XML、JSON等),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像、音频、视频),从而形成一个容纳所有形式数据的集中式数据存储。
国内一般把整个HDFS叫做数据仓库(广义),即存放所有数据的地方,而国外一般叫数据湖(data lake)
数据仓库Data Warehouse与数据湖DataLake 区别
- 数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。
- 数据湖存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。

数据湖并不能替代数据仓库,数据仓库在高效的报表和可视化分析中仍有优势。
- 数据仓库:使用良好范式规范数据,无法生成数据所需的洞察。
- 数据湖:新的原始数据存储和处理范式,缺乏结构和治理,会迅速沦为“数据沼泽”。
湖仓一体DataLake House
Data Lakehouse(湖仓一体)是新出现的一种数据架构,它同时吸收了数据仓库和数据湖的优势,数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能为公司进行数据治理带来更多的便利性。
LakeHouse使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。
湖仓一体LakeHouse:是一种结合数据湖和数据仓库优势的新范式,从根本上简化企业数据基础架构,并且有望在机器学习已渗透到每个行业的时代加速创新。
数据湖框架
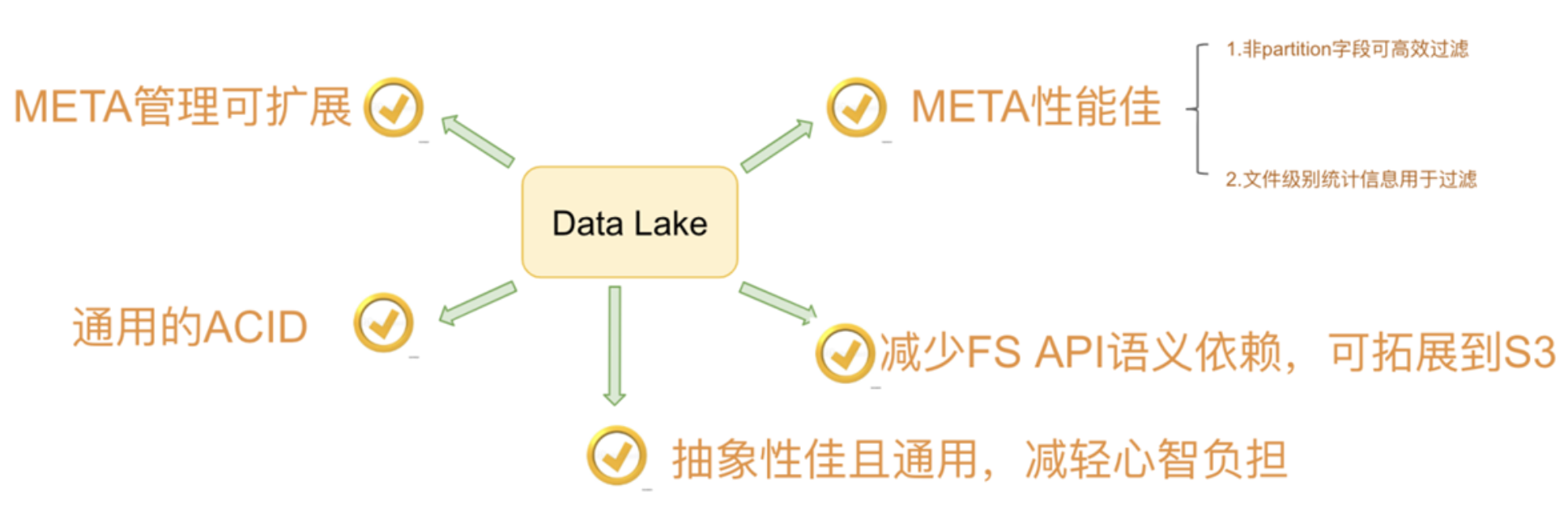
目前市面上流行的三大开源数据湖方案分别为:Delta Lake、Apache Iceberg和Apache Hudi。
- Delta Lake:DataBricks公司推出的一种数据湖方案,网址:https://delta.io/
- Apache Iceberg:以类似于SQL的形式高性能的处理大型的开放式表,网址:https://iceberg.apache.org/
- Apache Hudi:Hadoop Upserts anD Incrementals,管理大型分析数据集在HDFS上的存储,网址:https://hudi.apache.org/
Delta Lake
DeltaLake是一个致力于在数据湖之上构建湖仓一体架构的开源项目。DeltaLake支持ACID事务,可扩展的元数据存储,在现有的数据湖(S3、ADLS、GCS、HDFS)之上实现流批数据处理的统一。

由于出自Databricks,Spark的所有数据写入方式,包括基于dataframe的批式、流式,以及SQL的Insert、Insert Overwrite等都是支持的(开源的SQL写暂不支持,EMR做了支持)。
在数据写入方面,Delta 与 Spark 是强绑定的;在查询方面,开源 Delta 目前支持 Spark 与 Presto,但是,Spark 是不可或缺的,因为 delta log 的处理需要用到 Spark。

Apache Iceberg
Iceberg是一个用于处理海量分析数据集的开放表格式,是专门为对象存储(如S3)而设计的,支持 Spark, Trino, PrestoDB, Flink and Hive等计算引擎,操作Iceberg如SQL table一样。官网:https://iceberg.apache.org/
由 Netflix 开发开源的,其于 2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。
一种可伸缩的表存储格式,允许在一个文件里面修改或者过滤数据,多个文件也支持,内置了许多最佳实践。
在查询方面,Iceberg 支持 Spark、Presto,提供了建表的 API,用户可以使用该 API 指定表明、schema、partition 信息等,然后在 Hive catalog 中完成建表。
Apache Hudi
Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同时保持数据的开源文件格式。
Apache Hudi不仅非常适合于流工作负载,而且还允许创建高效的增量批处理管道。
Apache Hudi可以轻松地在任何云存储平台上使用。Hudi的高级性能优化,使分析工作负载更快的任何流行的查询引擎,包括Apache Spark、Flink、Presto、Trino、Hive等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6TXNGWno-1676288779897)(http://image.codekiller.top/img/Hudi/image-20230112180356519.png)]
强调其主要支持Upserts、Deletes和Incrementa数据处理,支持三种数据写入方式:UPSERT,INSERT 和 BULK_INSERT。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tvzLIBtJ-1676288779897)(http://image.codekiller.top/img/Hudi/image-20230112180429202.png)]
功能对比
| 对比项 | DeltaLake | Apache Hudi | Apache Iceberg |
|---|---|---|---|
| update/delete | Yes | Yes | Yes |
| 文件合并 | Manually | Automatic | Manually |
| 历史数据清理 | Automatic | Automatic | Manually |
| 文件格式 | parquet | parquet and avro | Parquet,avro,orc |
| 计算引擎 | Hive/Spark/Presto | Hive/Spark/Presto/Flink | Hive/Spark/Presto/Flink |
| 存储引擎 | HDFS/S3/Azure | HDFS/S3/OBS/ALLUXIO/Azure | HDFS/S3 |
| SQL DML | Yes | Yes | Yes |
| ACID transaction | Yes | Yes | Yes |
| TimeLine | Yes | Yes | Yes |
| 索引 | No | Yes | No |
| 可扩展的元数据存储 | Yes | Yes | Yes |
| Schema约束和演化 | Yes | Yes | Yes |
TimeLine
意思时间线,用于支持时间旅行(Time travel)。即根据用户的提供的时间戳,可以访问到历史某一事件点的数据快照。只要数据快照没有被清理掉,就可以被访问到。
Schema约束和演化
- Schema约束(Schema Enforcement):是指源和目标表的字段的数据类型需要一致,严格时可要求字段的数量一致。
- Schema演化(Schema Evolution):是指目标表可以根据源表的Schema变化而相应的变化,如增减字段,字段类型变更。一般不支持改变字段的顺序。
相同点:
- 都支持update/delete
- 都支持ACID, 原子性、一致性、隔离性、持久性,避免垃圾数据的产生,保证了数据质量
- 都能支持主流的高可用存储HDFS、S3
- 都提供了对Spark的支持,数据的写入都需要一个Spark Job去完成。都是以java package(–jars)方式引入到Spark。
- 读写都是以java library的方式引入到相关的执行引擎(Spark/Hive/Presto/Flink),不需要启动额外的服务
- 都可以自行管理元数据,元数据保存在HDFS/S3
- 都支持Spark/Hive/Presto
- 都支持TimeLine
不同点:
- 文件合并,Hudi支持自动合并,DeltaLake和Iceberg支持手动合并(额外定时调度)
- 数据清理,Hudi和DeltaLake和自动清理过期数据文件; Iceberg支持手动清理(额外定时调度)
- 文件格式:
- DeltaLake支持Parquet的文件格式。
- Hudi数据主要保存在Parquet文件,增量数据以行的方式写入Avro文件,合并操作会把指定时间范围内的Avro文件数据写入Parquet文件。
- Iceberg 支持Parquet、Avro、ORC。
- Hudi支持索引
- Hudi 和 IceBerg支持Flink批流读写











![[小记]注入服务进程/跨session注入](https://img-blog.csdnimg.cn/ccbedd9623f944f4b695d4c1dc5e4de4.png)