第二章 SparkSQL 概述
Spark SQL允许开发人员直接处理RDD,同时可以查询在Hive上存储的外部数据。Spark SQL的一个重要特点就是能够统一处理关系表和RDD,使得开发人员可以轻松的使用SQL命令进行外部查询,同时进行更加复杂的数据分析。
2.1 前世今生
SparkSQL模块一直到Spark 2.0版本才算真正稳定,发挥其巨大功能,发展经历如下几个阶段。

Shark 框架
首先回顾SQL On Hadoopp框架:Hive(可以说Hive时大数据生态系统中第一个SQL框架),架构如下所示:
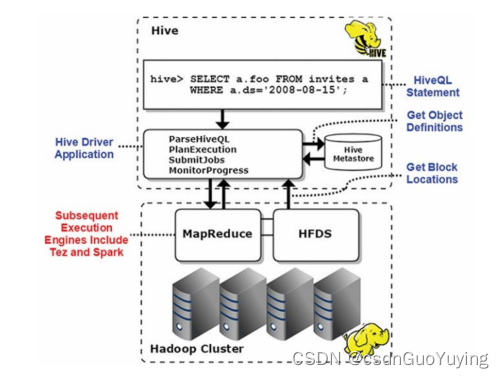
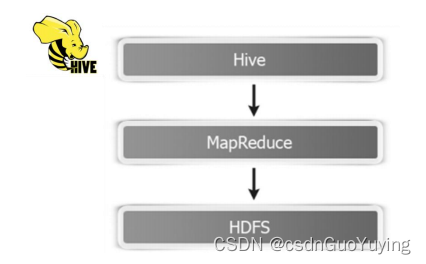
可以发现Hive框架底层就是MapReduce,所以在Hive中执行SQL时,往往很慢很慢。
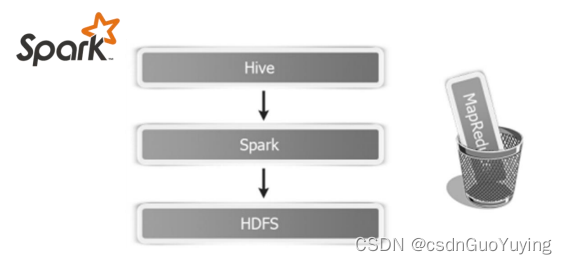
Spark出现以后,将HiveQL语句翻译成基于RDD操作,此时Shark框架诞生了。
Spark SQL的前身是Shark,它发布时Hive可以说是SQL on Hadoop的唯一选择(Hive负责将SQL编译成可扩展的MapReduce作业),鉴于Hive的性能以及与Spark的兼容,Shark由此而生。
Shark即Hive on Spark,本质上是通过Hive的HQL进行解析,把HQL翻译成Spark上对应的RDD操作,然后通过Hive的Metadata获取数据库里表的信息,实际为HDFS上的数据和文件,最后有Shark获取并放到Spark上计算。
但是Shark框架更多是对Hive的改造,替换了Hive的物理执行引擎,使之有一个较快的处理速度。然而不容忽视的是Shark继承了大量的Hive代码,因此给优化和维护带来大量的麻烦。为了更好的发展,Databricks在2014年7月1日Spark Summit上宣布终止对Shark的开发,将重点放到SparkSQL模块上。
文档:https://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.html
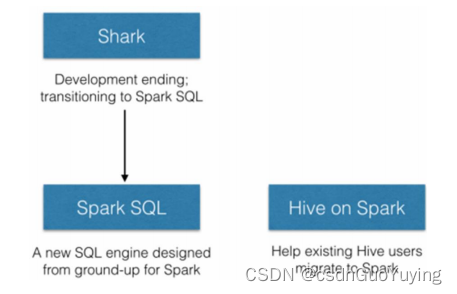
SparkSQL模块主要将以前依赖Hive框架代码实现的功能自己实现,称为Catalyst引擎
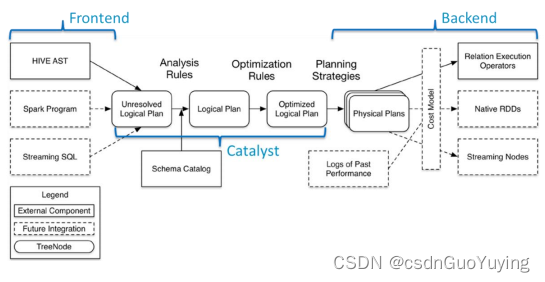
SparkSQL 模块
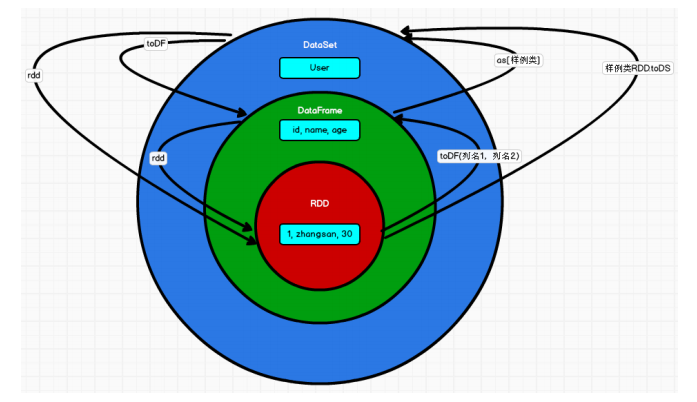
从Spark框架1.0开始发布SparkSQL模块开发,直到1.3版本发布SparkSQL Release版本可以在生产环境使用,此时数据结构为DataFrame = RDD + Schame。
1)、解决的问题
- Spark SQL 执行计划和优化交给优化器 Catalyst;
- 内建了一套简单的SQL解析器,可以不使用HQL;
- 还引入和 DataFrame 这样的DSL API,完全可以不依赖任何 Hive 的组件;
2)、新的问题 - 对于初期版本的SparkSQL,依然有挺多问题,例如只能支持SQL的使用,不能很好的兼容命令式,入口不够统一等;
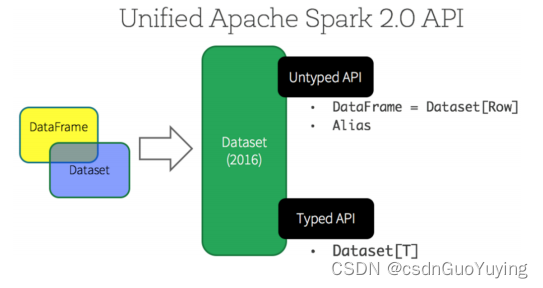
SparkSQL 在 1.6 时代,增加了一个新的API叫做 Dataset,Dataset 统一和结合了 SQL 的访问和命令式 API 的使用,这是一个划时代的进步。在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据,然后使用命令式 API 进行探索式分析。
Spark 2.x发布时,将Dataset和DataFrame统一为一套API,以Dataset数据结构为主(Dataset
= RDD + Schema),其中DataFrame = Dataset[Row]。
Hive 与 SparkSQL
从SparkSQL模块前世今生可以发现,从Hive框架衍生逐渐发展而来,Hive框架提供功能SparkSQL几乎全部都有,并且SparkSQL完全兼容Hive,从其加载数据进行处理。
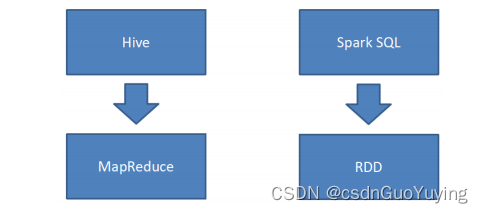
Hive是将SQL转为MapReduce,SparkSQL可以理解成是将SQL解析成RDD + 优化再执行。