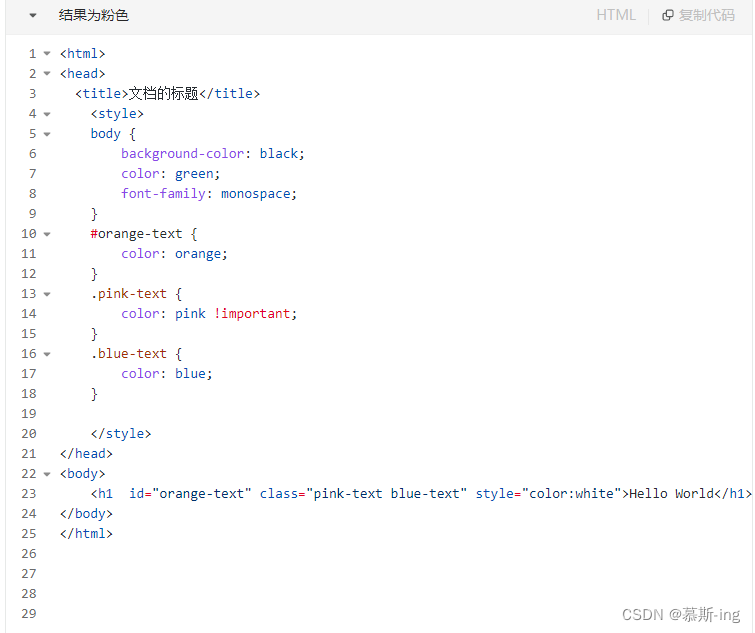
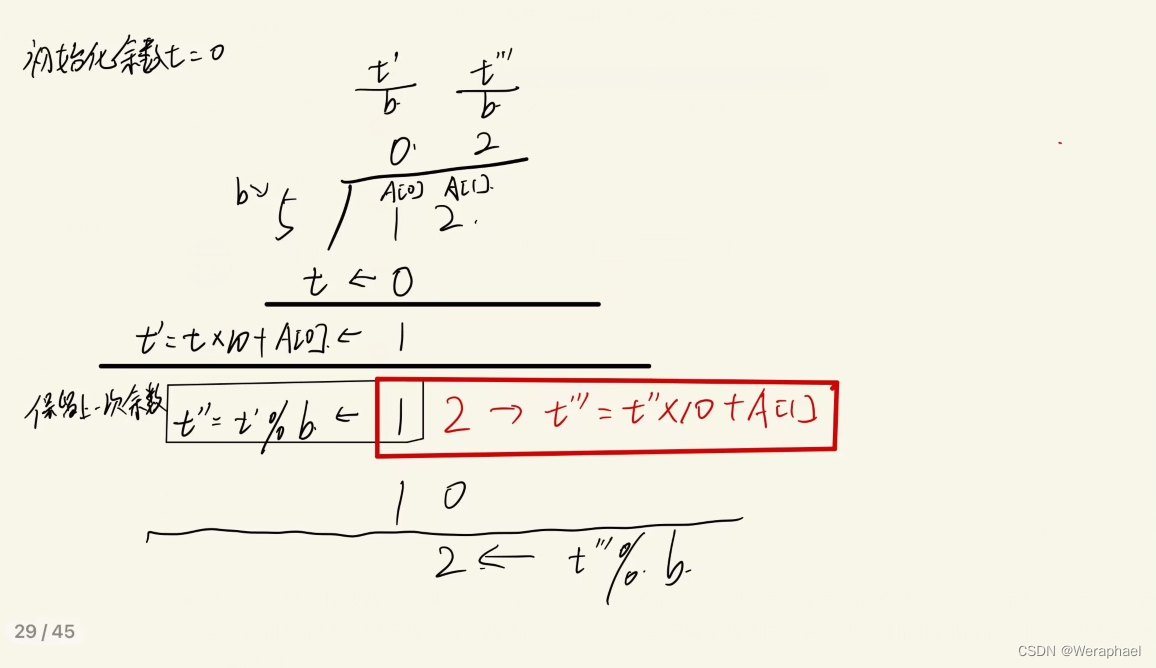Inception-Resnet-v1、Inception-Resnet-v2来自2016年谷歌发表的这篇论文:Inception-v4 Inception-ResNet and the Impact of Residual Connections on Learning,附论文链接:
[1602.07261] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning (arxiv.org)
https://arxiv.org/pdf/1602.07261.pdf (下载)
这篇文章提出了Inception-V4、Inception-ResNet-V1、Inception-ResNet-V2三个模型。 Inception-V4在Inception-V3的基础上进一步改进了Inception模块,提升了模型性能和计算效率,但没有使用残差模块, Inception-ResNet将Inception模块和深度残差网络ResNet结合,提出了三种包含残差连接的Inception模块,残差连接显著加快了训练收敛速度。经过模型集成和图像多尺度裁剪处理后,模型Top-5错误率降低至3.1%。
① Inception-ResNet-V1网络结构(整体结构v1和v2相同,主要区别在于通道数):

相较于原始Inception模块,Inception-Resnet-v1进行了改进:

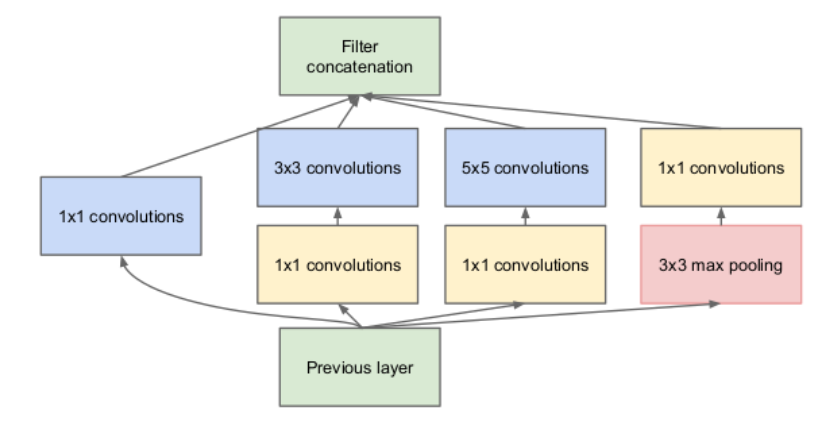
上图是 Inception 架构初始版本 。
Inception初始版本
优点:
- 增加了网络的宽度
- 增加了网络对尺度的适应性
- 加入池化操作,减少空间大小,减少过拟合
- 每个卷积层后跟ReLU,增加了非线性特征
缺点:所有卷积都在上一层的所有输出上做,造成5×5卷积之后特征图厚度过大。
改进:3×3和5×5卷积层前以及池化层后加入1×1卷积降维。
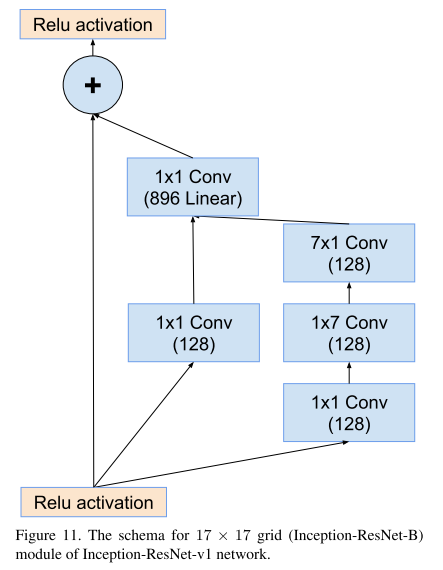
上图是 Inception-Resnet-v1中的Inception架构改良版本
来看看 Inception-Resnet-v1的具体结构吧。

stride 2 代表步长为2 ,V 是TF中的padding="Valid" == pytorch中的padding=0 ,没有标 V 是TF中的padding="Same" == pytorch中的padding=1 with zero padding(用0填充)。
需要注意的是,文中Conv s=2的padding为1;s=1的padding为0。
此外,我对图中结构进行了计算,经过不对称卷积(如IR-B模块,经过1X7,7X1的卷积按照原文特征图的大小会发生变化,但输出的结果表明这里的特征图大小并没有发生变化),它的H和W仍然不变,这里是因为它添加了0,保证特征图的大小不发生变化。

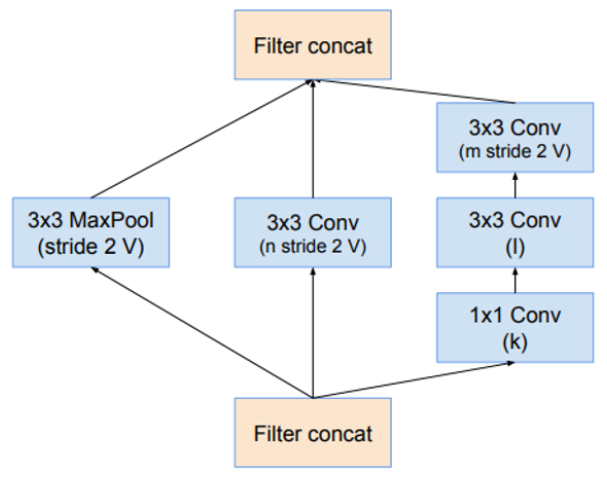
Reduction-A结构
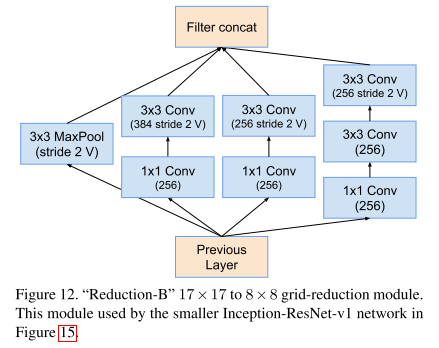
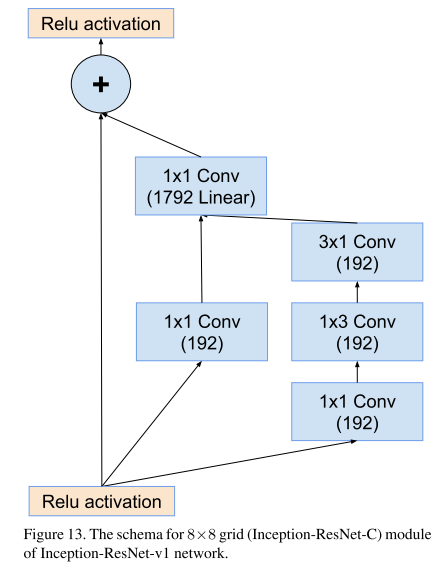
② Inception-ResNet-V2网络结构(整体结构v1和v2相同,主要区别在于通道数):
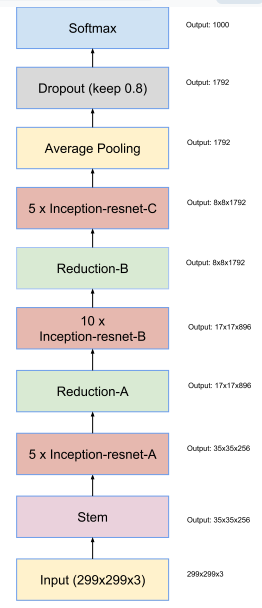
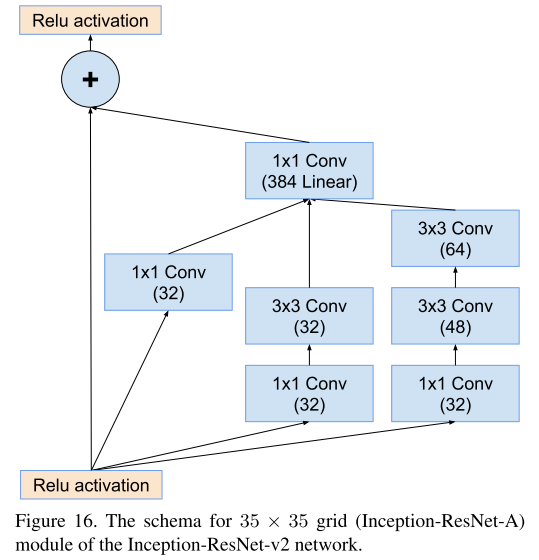
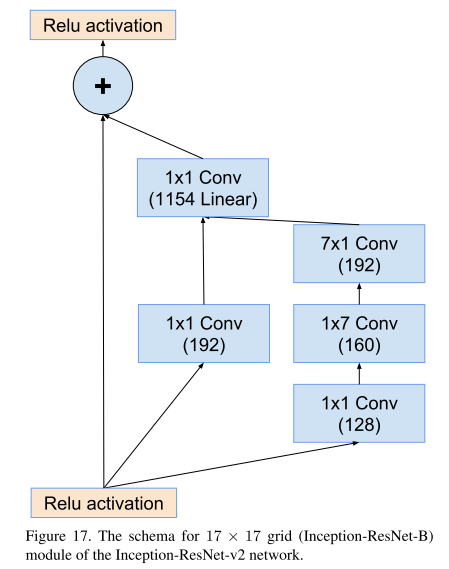
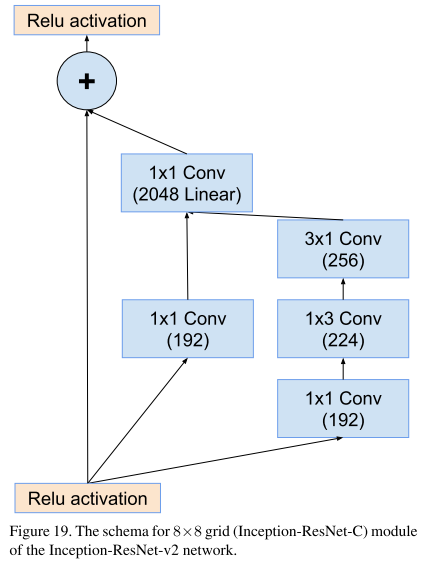
这三个网络中的参数略有不同:
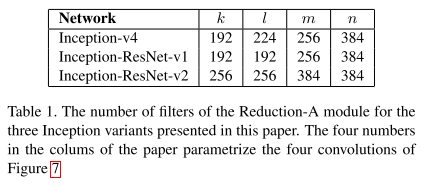
Inception-ResNet-v2网络的35×35→17×17和17×17→8×8图缩减模块A、B:
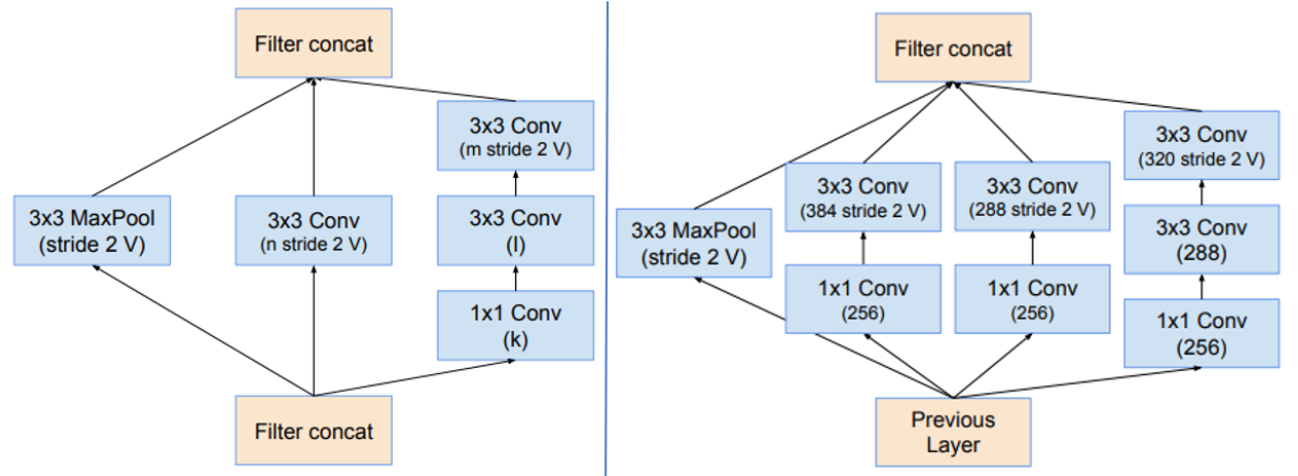
Inception-ResNet-v2网络的Reduction-A、B
Inception-ResNet v1 的计算成本和 Inception v3 的接近;Inception-ResNetv2 的计算成本和 Inception v4 的接近。它们有不同的 stem,两个网络都有模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。
③ 代码实现:
(1)Inception-Resnet-v1:
# 先定义3X3的卷积,用于代码复用
class conv3x3(nn.Module):
def __init__(self, in_planes, out_channels, stride=1, padding=0):
super(conv3x3, self).__init__()
self.conv3x3 = nn.Sequential(
nn.Conv2d(in_planes, out_channels, kernel_size=3, stride=stride, padding=padding),#卷积核为3x3
nn.BatchNorm2d(out_channels),#BN层,防止过拟合以及梯度爆炸
nn.ReLU()#激活函数
)
def forward(self, input):
return self.conv3x3(input)
class conv1x1(nn.Module):
def __init__(self, in_planes, out_channels, stride=1, padding=0):
super(conv1x1, self).__init__()
self.conv1x1 = nn.Sequential(
nn.Conv2d(in_planes, out_channels, kernel_size=1, stride=stride, padding=padding),#卷积核为1x1
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, input):
return self.conv1x1(input)
Stem模块:输入299*299*3,输出35*35*256.
class StemV1(nn.Module):
def __init__(self, in_planes):
super(StemV1, self).__init__()
self.conv1 = conv3x3(in_planes =in_planes,out_channels=32,stride=2, padding=0)
self.conv2 = conv3x3(in_planes=32, out_channels=32, stride=1, padding=0)
self.conv3 = conv3x3(in_planes=32, out_channels=64, stride=1, padding=1)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.conv4 = conv3x3(in_planes=64, out_channels=64, stride=1, padding=1)
self.conv5 = conv1x1(in_planes =64,out_channels=80, stride=1, padding=0)
self.conv6 = conv3x3(in_planes=80, out_channels=192, stride=1, padding=0)
self.conv7 = conv3x3(in_planes=192, out_channels=256, stride=2, padding=0)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
return x
IR-A模块*5:输入35*35*256,输出35*35*256.
class Inception_ResNet_A(nn.Module):
def __init__(self, input ):
super(Inception_ResNet_A, self).__init__()
self.conv1 = conv1x1(in_planes =input,out_channels=32,stride=1, padding=0)
self.conv2 = conv3x3(in_planes=32, out_channels=32, stride=1, padding=1)
self.line = nn.Conv2d(96, 256, 1, stride=1, padding=0, bias=True)
self.relu = nn.ReLU()
def forward(self, x):
c1 = self.conv1(x)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c3 = self.conv1(x)
# print("c3", c3.shape)
c2_1 = self.conv2(c2)
# print("c2_1", c2_1.shape)
c3_1 = self.conv2(c3)
# print("c3_1", c3_1.shape)
c3_2 = self.conv2(c3_1)
# print("c3_2", c3_2.shape)
cat = torch.cat([c1, c2_1, c3_2],dim=1)#torch.Size([4, 96, 15, 15])
# print("x",x.shape)
line = self.line(cat)
# print("line",line.shape)
out =x+line
out = self.relu(out)
return out
Reduction-A模块:输入35*35*256,输出17*17*896.
class Reduction_A(nn.Module):
def __init__(self, input,n=384,k=192,l=224,m=256):
super(Reduction_A, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.conv1 = conv3x3(in_planes=input, out_channels=n,stride=2,padding=0)
self.conv2 = conv1x1(in_planes=input, out_channels=k,padding=1)
self.conv3 = conv3x3(in_planes=k, out_channels=l,padding=0)
self.conv4 = conv3x3(in_planes=l, out_channels=m,stride=2,padding=0)
def forward(self, x):
c1 = self.maxpool(x)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c3 = self.conv2(x)
# print("c3", c3.shape)
c3_1 = self.conv3(c3)
# print("c3_1", c3_1.shape)
c3_2 = self.conv4(c3_1)
# print("c3_2", c3_2.shape)
cat = torch.cat([c1, c2,c3_2], dim=1)
return cat
IR-B模块*10:输入17*17*896,输出17*17*896.
class Inception_ResNet_B(nn.Module):
def __init__(self, input):
super(Inception_ResNet_B, self).__init__()
self.conv1 = conv1x1(in_planes =input,out_channels=128,stride=1, padding=0)
self.conv1x7 = nn.Conv2d(in_channels=128,out_channels=128,kernel_size=(1,7), padding=(0,3))
self.conv7x1 = nn.Conv2d(in_channels=128, out_channels=128,kernel_size=(7,1), padding=(3,0))
self.line = nn.Conv2d(256, 896, 1, stride=1, padding=0, bias=True)
self.relu = nn.ReLU()
def forward(self, x):
c1 = self.conv1(x)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c2_1 = self.conv1x7(c2)
# print("c2_1", c2_1.shape)
c2_1 = self.relu(c2_1)
c2_2 = self.conv7x1(c2_1)
# print("c2_2", c2_2.shape)
c2_2 = self.relu(c2_2)
cat = torch.cat([c1, c2_2], dim=1)
line = self.line(cat)
out =x+line
out = self.relu(out)
# print("out", out.shape)
return out
Reduction-B模块:输入17*17*896,输出8*8*1792.
class Reduction_B(nn.Module):
def __init__(self, input):
super(Reduction_B, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv1 = conv1x1(in_planes=input, out_channels=256, padding=1)
self.conv2 = conv3x3(in_planes=256, out_channels=384, stride=2, padding=0)
self.conv3 = conv3x3(in_planes=256, out_channels=256,stride=2, padding=0)
self.conv4 = conv3x3(in_planes=256, out_channels=256, padding=1)
self.conv5 = conv3x3(in_planes=256, out_channels=256, stride=2, padding=0)
def forward(self, x):
c1 = self.maxpool(x)
# print("c1", c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c3 = self.conv1(x)
# print("c3", c3.shape)
c4 = self.conv1(x)
# print("c4", c4.shape)
c2_1 = self.conv2(c2)
# print("cc2_1", c2_1.shape)
c3_1 = self.conv3(c3)
# print("c3_1", c3_1.shape)
c4_1 = self.conv4(c4)
# print("c4_1", c4_1.shape)
c4_2 = self.conv5(c4_1)
# print("c4_2", c4_2.shape)
cat = torch.cat([c1, c2_1, c3_1,c4_2], dim=1)
# print("cat", cat.shape)
return cat
IR-C模块*5:输入8*8*1792,输出8*8*1792.
class Inception_ResNet_C(nn.Module):
def __init__(self, input):
super(Inception_ResNet_C, self).__init__()
self.conv1 = conv1x1(in_planes=input, out_channels=192, stride=1, padding=0)
self.conv1x3 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=(1, 3), padding=(0,1))
self.conv3x1 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=(3, 1), padding=(1,0))
self.line = nn.Conv2d(384, 1792, 1, stride=1, padding=0, bias=True)
self.relu = nn.ReLU()
def forward(self, x):
c1 = self.conv1(x)
# print("x", x.shape)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c2_1 = self.conv1x3(c2)
# print("c2_1", c2_1.shape)
c2_1 = self.relu(c2_1)
c2_2 = self.conv3x1(c2_1)
# print("c2_2", c2_2.shape)
c2_2 = self.relu(c2_2)
cat = torch.cat([c1, c2_2], dim=1)
# print("cat", cat.shape)
line = self.line(cat)
out = x+ line
# print("out", out.shape)
out = self.relu(out)
return out
class Inception_ResNet(nn.Module):
def __init__(self,classes=2):
super(Inception_ResNet, self).__init__()
blocks = []
blocks.append(StemV1(in_planes=3))
for i in range(5):
blocks.append(Inception_ResNet_A(input=256))
blocks.append(Reduction_A(input=256))
for i in range(10):
blocks.append(Inception_ResNet_B(input=896))
blocks.append(Reduction_B(input=896))
for i in range(10):
blocks.append(Inception_ResNet_C(input=1792))
self.features = nn.Sequential(*blocks)
self.avepool = nn.AvgPool2d(kernel_size=3)
self.dropout = nn.Dropout(p=0.2)
self.linear = nn.Linear(1792, classes)
def forward(self,x):
x = self.features(x)
# print("x",x.shape)
x = self.avepool(x)
# print("avepool", x.shape)
x = self.dropout(x)
# print("dropout", x.shape)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
上述代码参考:基于PyTorch实现 Inception-ResNet-v1_NAND_LU的博客-CSDN博客
(2)Inception-Resnet-v2:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 由于后面会经常用到,提前定义3×3卷积 和 1×1的卷积
class conv3x3(nn.Module):
def __init__(self, in_planes, out_channels, stride=1, padding=0):
super(conv3x3, self).__init__()
self.conv3x3 = nn.Sequential(
nn.Conv2d(in_planes, out_channels, kernel_size=3, stride=stride, padding=padding), # 卷积核为3x3
nn.BatchNorm2d(out_channels), # BN层,防止过拟合以及梯度爆炸
nn.ReLU() # 激活函数
)
def forward(self, input):
return self.conv3x3(input)
class conv1x1(nn.Module):
def __init__(self, in_planes, out_channels, stride=1, padding=0):
super(conv1x1, self).__init__()
self.conv1x1 = nn.Sequential(
nn.Conv2d(in_planes, out_channels, kernel_size=1, stride=stride, padding=padding), # 卷积核为1x1
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, input):
return self.conv1x1(input)stem模块:输入299*299*3,输出35*35*384.
# 定义stem模块
class StemV2(nn.Module):
def __init__(self, in_planes=3):
super(StemV2, self).__init__()
self.conv1 = conv3x3(in_planes =in_planes,out_channels=32,stride=2, padding=0)
self.conv2 = conv3x3(in_planes=32, out_channels=32, stride=1, padding=0)
self.conv3 = conv3x3(in_planes=32, out_channels=64, stride=1, padding=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.conv4 = conv3x3(in_planes=64, out_channels=96, stride=2, padding=0)
self.conv5 = conv1x1(in_planes=160, out_channels=64, stride=1, padding=1)
self.conv6 = conv3x3(in_planes=64, out_channels=96, stride=1, padding=0)
self.conv7 = conv1x1(in_planes=160, out_channels=64, stride=1, padding=1)
self.conv8 = nn.Conv2d(in_channels=64, out_channels=64, stride=1, kernel_size=(1, 7), padding=(0, 3))
self.conv9 = nn.Conv2d(in_channels=64, out_channels=64, stride=1, kernel_size=(7, 1), padding=(3, 0))
self.conv10 = conv3x3(in_planes=64, out_channels=96, stride=1, padding=0)
self.conv11 = conv3x3(in_planes=192, out_channels=192, stride=2, padding=0)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x1 = self.maxpool1(x)
x2 = self.conv4(x)
x = torch.cat([x1, x2], dim=1)
x1 = self.conv5(x)
x1 = self.conv6(x1)
x2 = self.conv7(x)
x2 = self.conv8(x2)
x2 = self.relu(x2)
x2 = self.conv9(x2)
x2 = self.relu(x2)
x2 = self.conv10(x2)
x = torch.cat([x1, x2], dim=1)
x1 = self.conv11(x)
x2 = self.maxpool2(x)
x = torch.cat([x1, x2], dim=1)
return xIR-A模块*5:输入35*35*384,输出35*35*256.
# 定义IR-A模块
class Inception_ResNet_A(nn.Module):
def __init__(self, input, scale=0.3):
super(Inception_ResNet_A, self).__init__()
self.conv1 = conv1x1(in_planes =input,out_channels=32,stride=1, padding=0)
self.conv2 = conv3x3(in_planes=32, out_channels=32, stride=1, padding=1)
self.conv3 = conv3x3(in_planes=32, out_channels=48, stride=1, padding=1)
self.conv4 = conv3x3(in_planes=48, out_channels=64, stride=1, padding=1)
self.line = nn.Conv2d(128, 384, 1, stride=1, padding=0, bias=True)
self.scale = scale
self.relu = nn.ReLU()
def forward(self, x):
c1 = self.conv1(x)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c3 = self.conv1(x)
# print("c3", c3.shape)
c2_1 = self.conv2(c2)
# print("c2_1", c2_1.shape)
c3_1 = self.conv3(c3)
# print("c3_1", c3_1.shape)
c3_2 = self.conv4(c3_1)
# print("c3_2", c3_2.shape)
cat = torch.cat([c1, c2_1, c3_2],dim=1)#torch.Size([4, 96, 15, 15])
# print("x",x.shape)
line = self.line(cat)
# print("line",line.shape)
out = self.scale*x+line
out = self.relu(out)
return outReduction-A模块:输入35*35*256,输出17*17*896.
# 定义Reduction-A模块
class Reduction_A(nn.Module):
def __init__(self, input, n=384, k=256, l=256, m=384, scale=0.3):
super(Reduction_A, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.conv1 = conv3x3(in_planes=input, out_channels=n, stride=2,padding=0)
self.conv2 = conv1x1(in_planes=input, out_channels=k, padding=1)
self.conv3 = conv3x3(in_planes=k, out_channels=l, padding=0)
self.conv4 = conv3x3(in_planes=l, out_channels=m, stride=2, padding=0)
self.scale =scale
def forward(self, x):
c1 = self.maxpool(x)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c3 = self.conv2(x)
# print("c3", c3.shape)
c3_1 = self.conv3(c3)
# print("c3_1", c3_1.shape)
c3_2 = self.conv4(c3_1)
# print("c3_2", c3_2.shape)
cat = torch.cat([c1, c2, c3_2], dim=1)
return catIR-B模块*10:输入17*17*896,输出8*8*1792.
# 定义IR-B模块
class Inception_ResNet_B(nn.Module):
def __init__(self, input, scale=0.3):
super(Inception_ResNet_B, self).__init__()
self.conv1 = conv1x1(in_planes =input,out_channels=192,stride=0, padding=1)
self.conv2 = conv1x1(in_planes =input,out_channels=128,stride=0, padding=1)
self.conv1x7 = nn.Conv2d(in_channels=128,out_channels=160,kernel_size=(1,7), padding=(0,3))
self.conv7x1 = nn.Conv2d(in_channels=160, out_channels=192,kernel_size=(7,1), padding=(3,0))
self.line = nn.Conv2d(384, 1152, 1, stride=1, padding=0, bias=True)
self.scale = scale
self.relu = nn.ReLU()
def forward(self, x):
c1 = self.conv1(x)
# print("c1",c1.shape)
c2 = self.conv2(x)
# print("c2", c2.shape)
c2_1 = self.conv1x7(c2)
# print("c2_1", c2_1.shape)
c2_1 = self.relu(c2_1)
c2_2 = self.conv7x1(c2_1)
# print("c2_2", c2_2.shape)
c2_2 = self.relu(c2_2)
cat = torch.cat([c1, c2_2], dim=1)
line = self.line(cat)
out =self.scale*x+line
out = self.relu(out)
# print("out", out.shape)
return outReduction-B模块:输入8*8*1792,输出8*8*1792.
# 定义Reduction-B模块
class Reduction_B(nn.Module):
def __init__(self, input):
super(Reduction_B, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.conv1 = conv1x1(in_planes=input, out_channels=256, padding=1)
self.conv2 = conv3x3(in_planes=256, out_channels=288, stride=2, padding=0)
self.conv3 = conv3x3(in_planes=256, out_channels=288, stride=2, padding=0)
self.conv4 = conv3x3(in_planes=256, out_channels=288, padding=1)
self.conv5 = conv3x3(in_planes=288, out_channels=320, stride=2, padding=0)
def forward(self, x):
c1 = self.maxpool(x)
# print("c1", c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c3 = self.conv1(x)
# print("c3", c3.shape)
c4 = self.conv1(x)
# print("c4", c4.shape)
c2_1 = self.conv2(c2)
# print("cc2_1", c2_1.shape)
c3_1 = self.conv3(c3)
# print("c3_1", c3_1.shape)
c4_1 = self.conv4(c4)
# print("c4_1", c4_1.shape)
c4_2 = self.conv5(c4_1)
# print("c4_2", c4_2.shape)
cat = torch.cat([c1, c2_1, c3_1, c4_2], dim=1)
# print("cat", cat.shape)
return catIR-C模块*5:输入8*8*1792,输出8*8*1792.
# 定义IR-C模块
class Inception_ResNet_C(nn.Module):
def __init__(self, input, scale=0.3):
super(Inception_ResNet_C, self).__init__()
self.conv1 = conv1x1(in_planes=input, out_channels=192, stride=1, padding=0)
self.conv1x3 = nn.Conv2d(in_channels=192, out_channels=224, kernel_size=(1, 3), padding=(0,1))
self.conv3x1 = nn.Conv2d(in_channels=224, out_channels=256, kernel_size=(3, 1), padding=(1,0))
self.line = nn.Conv2d(448, 2048, 1, stride=1, padding=0, bias=True)
self.relu = nn.ReLU()
self.scale = scale
def forward(self, x):
c1 = self.conv1(x)
# print("x", x.shape)
# print("c1",c1.shape)
c2 = self.conv1(x)
# print("c2", c2.shape)
c2_1 = self.conv1x3(c2)
# print("c2_1", c2_1.shape)
c2_1 = self.relu(c2_1)
c2_2 = self.conv3x1(c2_1)
# print("c2_2", c2_2.shape)
c2_2 = self.relu(c2_2)
cat = torch.cat([c1, c2_2], dim=1)
# print("cat", cat.shape)
line = self.line(cat)
out = self.scale*x+ line
# print("out", out.shape)
out = self.relu(out)
return out# IR v2
class Inception_ResNet_v2(nn.Module):
def __init__(self, classes=2):
super(Inception_ResNet_v2, self).__init__()
blocks = []
blocks.append(StemV2(in_planes=3))
for _ in range(5):
blocks.append(Inception_ResNet_A(input=384))
blocks.append(Reduction_A(input=384))
for _ in range(10):
blocks.append(Inception_ResNet_B(input=1152))
blocks.append(Reduction_B(input=1152))
for _ in range(10):
blocks.append(Inception_ResNet_C(input=2146))
self.features = nn.Sequential(*blocks)
self.avepool = nn.AvgPool2d(kernel_size=3)
self.dropout = nn.Dropout(p=0.2)
self.linear = nn.Linear(2048, classes)
def forward(self, x):
x = self.features(x)
# print("x",x.shape)
x = self.avepool(x)
# print("avepool", x.shape)
x = self.dropout(x)
# print("dropout", x.shape)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x