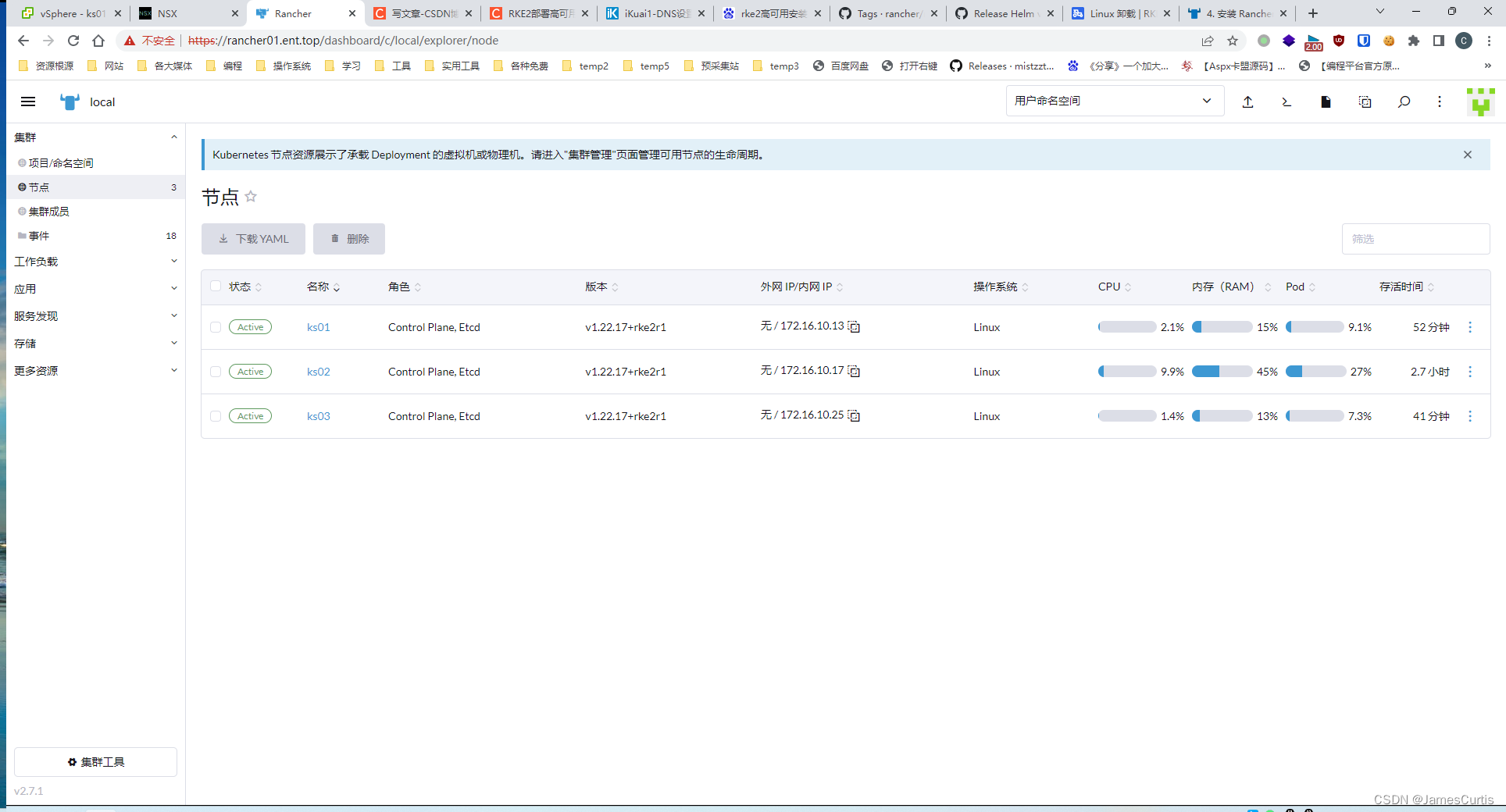
特征工程是将原始数据转换为更好的代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的预测准确性。
特征抽取
文本特征抽取,sklearn的API是sklearn.feature_extraction.text.CountVectorizer。
(1).英文分词
from sklearn.feature_extraction.text import CountVectorizer
#英文分词
def eng_count():
cv = CountVectorizer() #实例化
data = cv.fit_transform(['Today is a good day,i am so happy.','Today is my birthday,she is my girlfriend.']) #里面是一个列表
print(cv.get_feature_names()) #每个词的唯一值,不统计单个的词
print(data.toarray()) #在列表中出现的次数
return None
if __name__ == '__main__':
eng_count()
(2).中文分词,需要用到jieba库
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def jiebac():
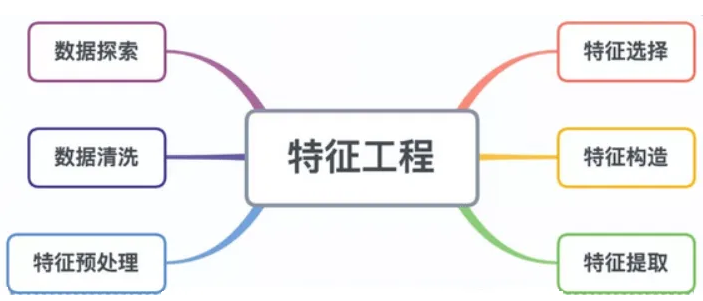
s1 = '今天是一个好天气,真是美好的一天。'
s2 = '今天的你比较美,我很开心,很美好。'
scut1 = jieba.cut(s1) #jieba分词
scut2 = jieba.cut(s2)
list_scut1 = list(scut1) #转换成列表
list_scut2 = list(scut2)
print(list_scut1)
print(list_scut2)
str1 = ' '.join(list_scut1) #空格连接
str2 = ' '.join(list_scut2)
print(str1)
print(str2)
return str1,str2
#中文分词
def chinese_count():
str_s1,str_s2=jiebac()
cv = CountVectorizer() #实例化
data = cv.fit_transform([str_s1,str_s2]) #里面是一个列表
print(cv.get_feature_names()) #每个词的唯一值,不统计单个的词
print(data.toarray()) #在列表中出现的次数
return None
if __name__ == '__main__':
chinese_count()
结论:特征抽取对文本等数据进行特征值化,就是将文本转换为数字。
2.字典的特征值化,sklearn的API是sklearn.feature_extraction.DictVectorizer,
DictVectorizer.fit_transform(x),x是字典或包含字典的迭代器,返回sparse矩阵。
from sklearn.feature_extraction import DictVectorizer
def dicts():
dic = DictVectorizer() #实例化
data = dic.fit_transform([{'city':'北京','tem':100},{'city':'上海','tem':80},{'city':'亳州','tem':120}]) #里面是一个列表
print(dic.get_feature_names()) #返回类名
print(data) #返回sparse矩阵
print(data.toarray()) #返回array,如上海在2出现,列看的话就是0,1,0
return None
if __name__ == '__main__':
dicts()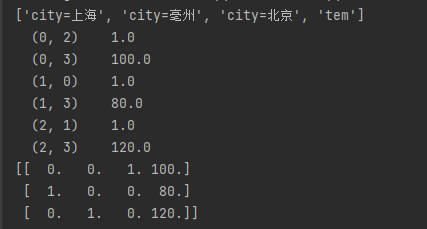
这也为One-hot编码,one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
3.TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency).
TF是统计词频,词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。IDF是逆文本频率指数,为log(总的文档数量/该词出现的文档数量) 一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“母牛”一词。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。如果该词出现的文档数量多,分母变大,总的文档数量不变,log(总的文档数量/该词出现的文档数量) 就越小,就越不重要。 最后的结果是TF*IDF,体现词出现的重要性。sklearn的API是sklearn.feature_extraction.text.CountVectorizer。


from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ['This is the first document.', 'This document is the second document.', 'And this is the third one.', 'Is this the first document?']
tf = TfidfVectorizer()
re = tf.fit_transform(corpus)
print(tf.get_feature_names()) #每个词的唯一值,不统计单个的词
print(re.toarray())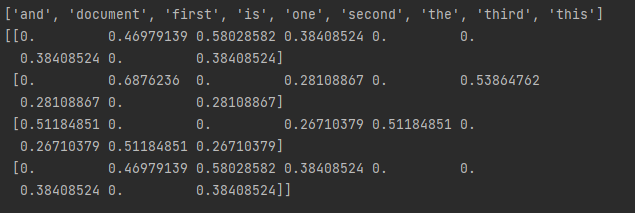
手工计算:对于document,tf=1/5=0.2,1是出现1此,5是在第一个文本中总的词数
idf = log((1+4)/(1+3))+1使用平滑处理,是以e为底,计算为1.22314355131
tf-idf = 0.2*1.22314355131=0.24462871026与sklearn计算不一致,原因为sklearn做了归一化处理,
计算每个tf-idf 的平方根
(0.24462869**2 + 0.30216512**2 + 0.2**2 + 0.2**2 + 0.2**2)**0.5 = 0.5207177313
document:0.24462869/0.5207177313=0.469791
特征预处理 sklearn API是sklearn.preprocessing
归一化

sklearn API是sklearn.preprocessing.MinMaxScaler

from sklearn.preprocessing import MinMaxScaler
def mm():
m = MinMaxScaler(feature_range=(0,1)) #实例化
data = m.fit_transform([[3,4,5],[5,4,6],[7,6,7]])
print(data)
return None
if __name__ == '__main__':
mm()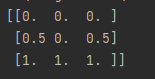
归一化缺点,如果异常值多的话,会对平均值影响大。
2.标准化
特点:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内

sklearn API是sklearn.preprocessing.StandardScaler
from sklearn.preprocessing import StandardScaler
def std():
st = StandardScaler() #实例化
data = st.fit_transform([[3,4,5],[5,4,6],[7,6,7]])
print(data)
return None
if __name__ == '__main__':
std()

3.缺失值处理
一般使用pandas进行处理缺失值,在sklearn中的API是:sklearn.impute.SimpleImputer
是按列进行填充,
from sklearn.impute import SimpleImputer
import numpy as np
def im():
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
data = imp.fit_transform([[1,2,3],[3,np.nan,8],[5,6,np.nan]])
print(data)
return None
if __name__ == '__main__':
im()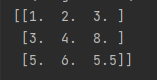
One-Hot编码
独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
在sklearn中的API是:sklearn.preprocessing.OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
def one():
onehot = OneHotEncoder() #实例化
data = onehot.fit([[1,2,3],[3,5,8],[5,6,7]]) #训练,3个数据,3个特征
data1 = onehot.transform([[1,5,7]]) #测试,数据包含于训练数据
print(data1.toarray())
return None
if __name__ == '__main__':
one()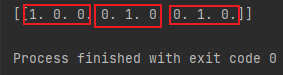
输出结果是进行排序了,