目录
- 1. 查询下压设置
- 2. Sparder查询引擎详细介绍
- 3. HDFS文件目录含义
1. 查询下压设置
如果未开启查询下压,则查询有很多限制。这是因为只能查询cube中的数据,而不能通过spark sql查询Hive中的源数据
开启查询下压,优先从cube中查询数据,如果查询不到,则通过spark sql从Hive中进行查询
在kylin.properties中进行开启
.runner-class-name=org.apache.kylin.query.pushdown.PushDownRunnerSparkImpl
可以进行重启kylin服务,或者在每个kylin的Web界面的System-Configuration-Reload Config让配置生效
2. Sparder查询引擎详细介绍
Sparder(SparderContext)是一个一直运行的spark application。Sparder可以接收kylin的查询,进行数据的查询。
Sparder的Spark资源是由kylin.properties中,以kylin.query.spark-conf开头的参数决定的
可以设置在kylin启动的时候,就运行Sparder,kylin.properties参数设置如下:
kylin.query.auto-sparder-context-enabled-enabled=true
3. HDFS文件目录含义
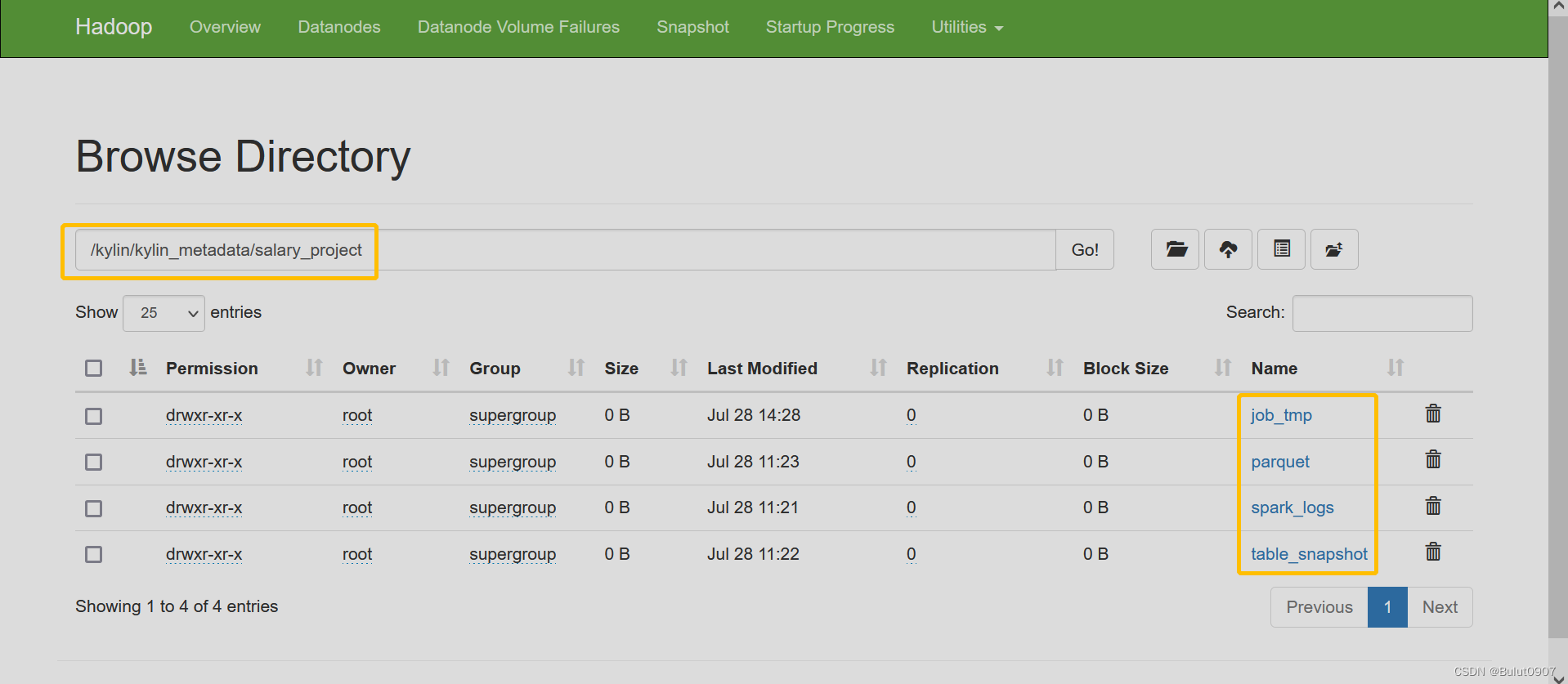
job_tmp:临时文件存储目录
parquet/salary_cube/FULL_BUILD_PMB:Cuboid文件存储目录
spark_logs:Spark运行日志目录
table_snapshot:维度表快照存储目录