CUDA 流的概念
- CUDA流在加速应用程序方面起到重要的作用,他表示一个GPU的操作队列操作在队列中按照一定的顺序执行,也可以向流中添加一定的操作如核函数的启动、内存的复制、事件的启动和结束等,添加的顺序也就是执行的顺序
- 一个流中的不同操作有着严格的顺序。但是不同流之间是没有任何限制的。多个流同时启动多个内核,就形成了网格级别的并行。
CUDA流中排队的操作和主机都是异步的,所以排队的过程中并不耽误主机运行其他指令,所以这就隐藏了执行这些操作的开销。
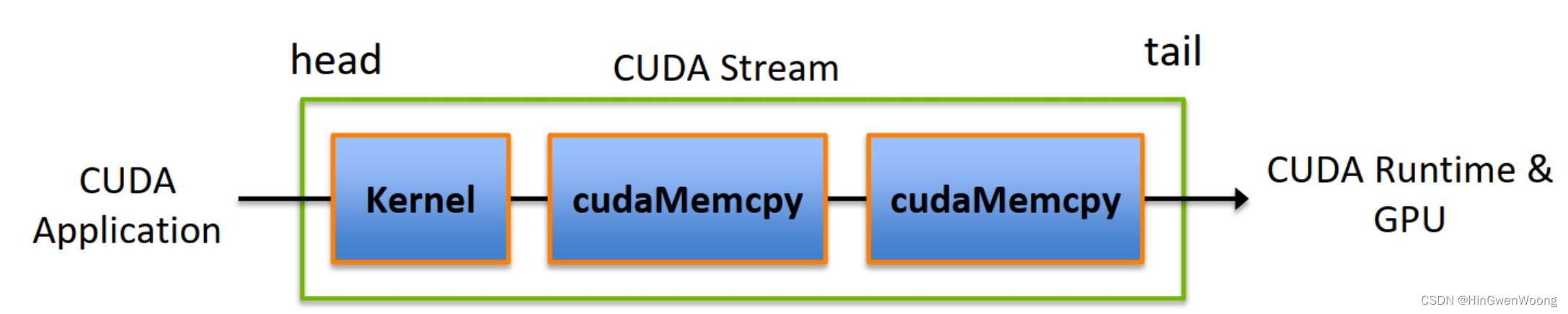
详解
基于流的异步内核启动(Kernel Launch)和数据传输支持以下类型的粗粒度并发:
- 重叠主机和设备计算;
- 重叠主机计算和设备数据传输;
- 重叠主机设备数据传输和设备计算;
- 并发设备计算(多个设备)
当然也有不支持并发的情况:
- 主机上page-locked内存的分配;
- 设备内存的分配;
- 设备内存的设置
Memeset(); - 同一个设备上内存的复制;
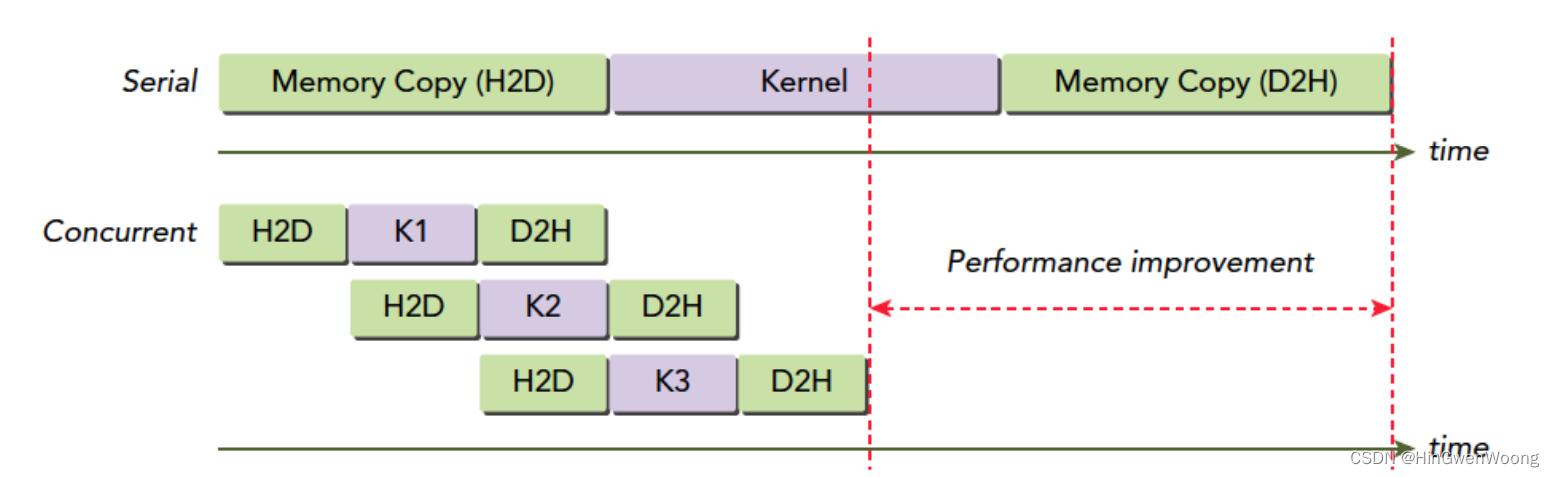
下面是 cudaMemcpyAsync 进行的流演示:

vector 相加例子: A + B = C 的计算过程如下图所示,可以看到有多个流在并行执行,效率大大提升:
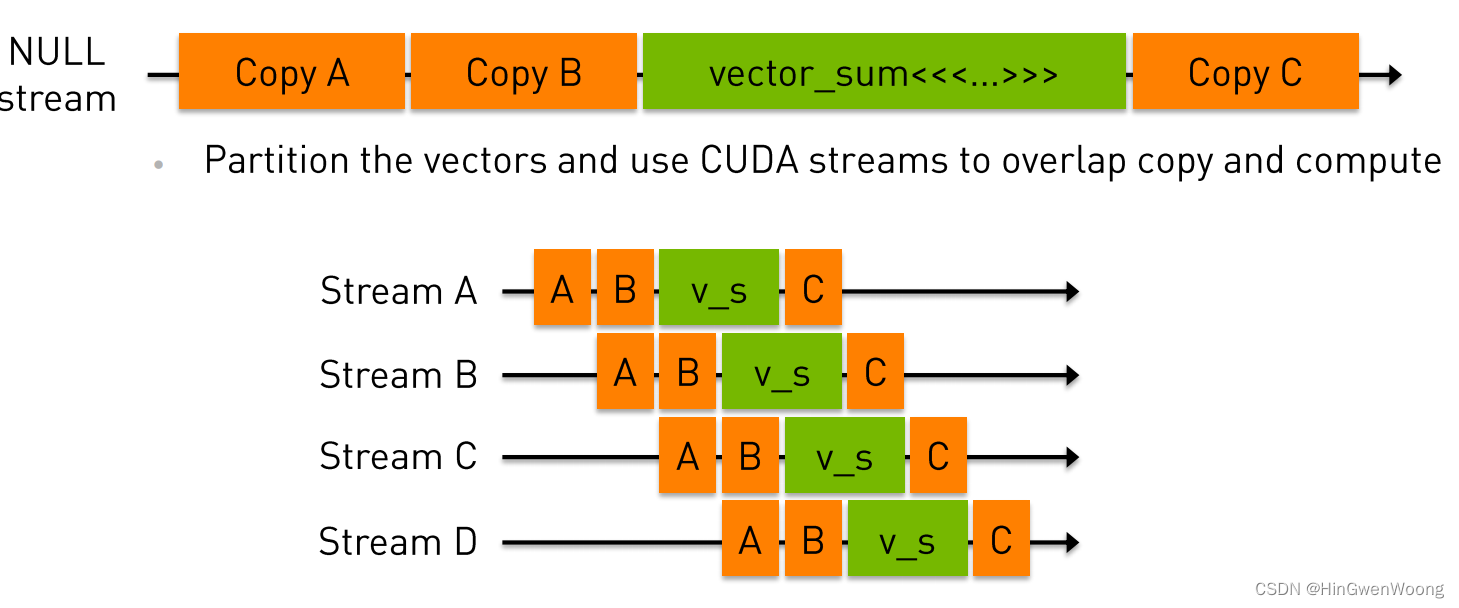
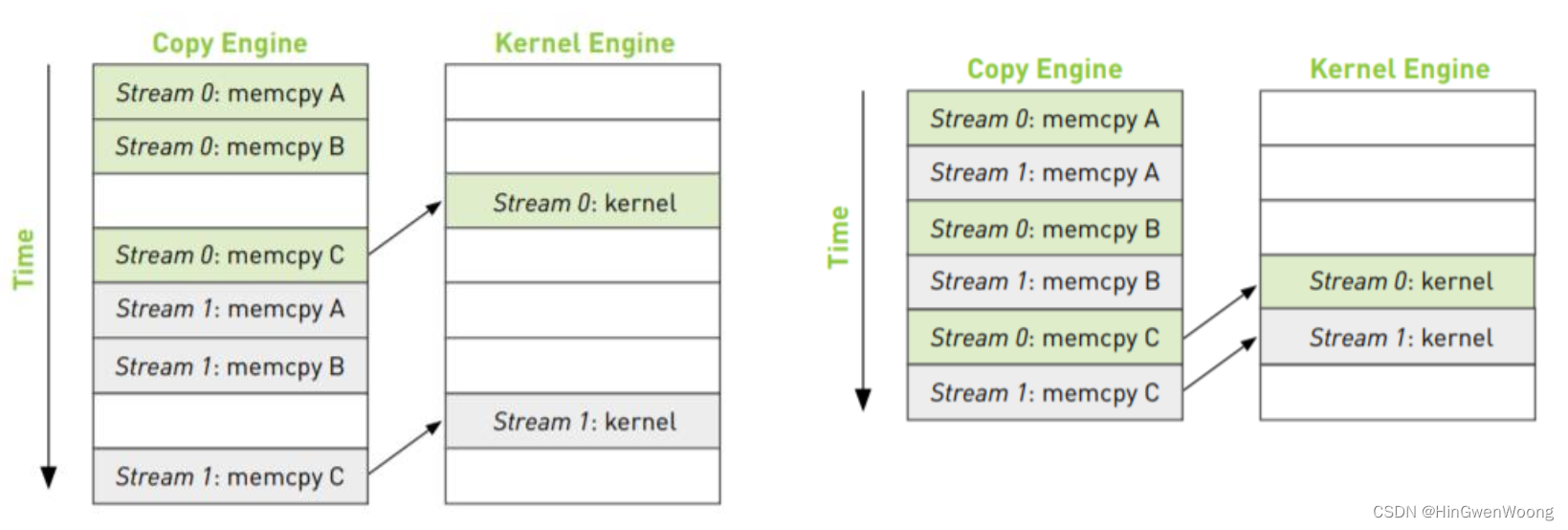
下图可以看到 流 可以让进程并行度进一步提升
代码
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)
__global__ void kernel( int *a, int *b, int *c ) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main( void ) {
cudaDeviceProp prop;
int whichDevice;
CHECK( cudaGetDevice( &whichDevice ) );
CHECK( cudaGetDeviceProperties( &prop, whichDevice ) );
if (!prop.deviceOverlap) {
printf( "Device will not handle overlaps, so no speed up from streams\n" );
return 0;
}
cudaEvent_t start, stop;
float elapsedTime;
cudaStream_t stream0, stream1;
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
int *dev_a1, *dev_b1, *dev_c1;
// start the timers
CHECK( cudaEventCreate( &start ) );
CHECK( cudaEventCreate( &stop ) );
// initialize the streams
CHECK( cudaStreamCreate( &stream0 ) );
CHECK( cudaStreamCreate( &stream1 ) );
// allocate the memory on the GPU
CHECK( cudaMalloc( (void**)&dev_a0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_b0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_c0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_a1, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_b1, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_c1, N * sizeof(int) ) );
// allocate host locked memory, used to stream
CHECK( cudaHostAlloc( (void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
CHECK( cudaHostAlloc( (void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
CHECK( cudaHostAlloc( (void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
for (int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand();
host_b[i] = rand();
}
CHECK( cudaEventRecord( start, 0 ) );
// now loop over full data, in bite-sized chunks
for (int i=0; i<FULL_DATA_SIZE; i+= N*2) {
// enqueue copies of a in stream0 and stream1
CHECK( cudaMemcpyAsync( dev_a0, host_a+i, N * sizeof(int), cudaMemcpyHostToDevice, stream0 ) );
CHECK( cudaMemcpyAsync( dev_a1, host_a+i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1 ) );
// enqueue copies of b in stream0 and stream1
CHECK( cudaMemcpyAsync( dev_b0, host_b+i, N * sizeof(int), cudaMemcpyHostToDevice, stream0 ) );
CHECK( cudaMemcpyAsync( dev_b1, host_b+i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1 ) );
kernel<<<N/256,256,0,stream0>>>( dev_a0, dev_b0, dev_c0 );
kernel<<<N/256,256,0,stream1>>>( dev_a1, dev_b1, dev_c1 );
CHECK( cudaMemcpyAsync( host_c+i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0 ) );
CHECK( cudaMemcpyAsync( host_c+i+N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1 ) );
}
CHECK( cudaStreamSynchronize( stream0 ) );
CHECK( cudaStreamSynchronize( stream1 ) );
CHECK( cudaEventRecord( stop, 0 ) );
CHECK( cudaEventSynchronize( stop ) );
CHECK( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time taken: %3.1f ms\n", elapsedTime );
// cleanup the streams and memory
CHECK( cudaFreeHost( host_a ) );
CHECK( cudaFreeHost( host_b ) );
CHECK( cudaFreeHost( host_c ) );
CHECK( cudaFree( dev_a0 ) );
CHECK( cudaFree( dev_b0 ) );
CHECK( cudaFree( dev_c0 ) );
CHECK( cudaFree( dev_a1 ) );
CHECK( cudaFree( dev_b1 ) );
CHECK( cudaFree( dev_c1 ) );
CHECK( cudaStreamDestroy( stream0 ) );
CHECK( cudaStreamDestroy( stream1 ) );
return 0;
}