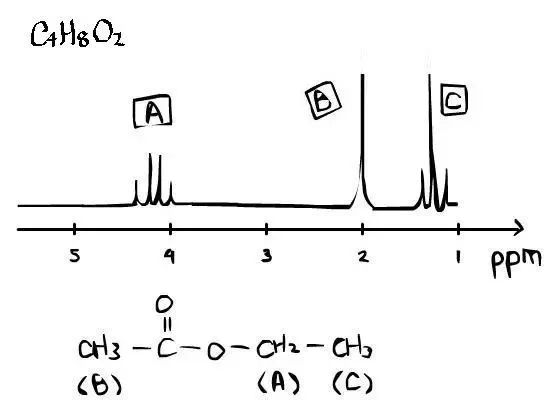
搜索逻辑
代码主要以支撑概率和压力概率来判断均线的优劣
判断为压力: 当日线与测试均线发生金叉或即将发生金叉后继续下行
判断为支撑: 当日线与测试均线发生死叉或即将发生死叉后继续上行
判断结果的天数: 小于6日均线,用金叉或死叉后2个交易日的结果判断;大于等于6日的n日均线,用n/2个交易日判断
判断逻辑: 使用判断点(金叉 or 死叉)后n/2个交易日的收盘价的一次回归线的斜率,大于0为上行,小于0为下行
补充: 把判断点由近似点改成准确点(即日线与均线发生交叉)后,1-压力概率 即为金叉概率,1-压力概率 即为死叉概率
数据处理
数据来源: tushare 或 通信达,我使用的是通信达导出的2015年至今的日线数据
数据处理: 把每只股票的数据按照日期从小到大排列后,取出收盘价即可
如果你有分钟数据,也可以搜索分钟级别的均线压力和支撑
数据处理代码
def readData(self,r_path):
'''
1、r_path: 通信达导出的日线数据所在的目录
2、生成函数,每次获取一支股票2015年至今的收盘数据
'''
files = os.listdir(r_path)
for f_path in files:
f_path = os.path.join('日线_data',f_path)
df = pd.read_csv(f_path
,header=None
,index_col=False
,encoding='gbk'
,names=['trade_date','open','high','low','close','vol','amount']).dropna()
df = df.sort_values('trade_date').reset_index(drop=True)
yield df['close']
查找代码
判断金叉和死叉的逻辑
判断金叉和死叉的代码逻辑一开始属实让我难理解,看四五遍才清除,下面给一个我觉得比较清楚的示例
# 计算均线
ma = data.rolling(5).mean() # 计算5日均线
cmp = data > ma * 0.97 # 有时不触及均线也会有支撑和压力,但不会有金叉和死叉,所以要适当抬高或降低均线,自己设置
'''
计算金叉和死叉,金叉用于计算压力,死叉用于计算支撑
金叉计算逻辑
cmp: F F F T T T F F F
(~cmp).shift(1): T T T F F F T T T
golden_idx: F F F T F F F F F # 金叉结果
反过来就是死叉
'''
golden_idx = cmp & (~cmp).shift(1) #金叉
cmp = data > ma * 1.03 # 计算死叉,抬高均线
death_idx = ~cmp & cmp.shift(1) # 死叉
整体搜索代码
def find_best_ma(self,r_path,days:tuple):
assert days[0] <= days[1],'计算均线日期错误,格式(起始,结束)'
assert days[0] > 1,'最小天数要大于1'
datas = self.readData(r_path)
# 保存结果
result = pd.DataFrame({
'MA':[*range(days[0],days[1]+1)]
,'支撑成功率':np.zeros(days[1]-days[0]+1)
,'支撑成功次数':np.zeros(days[1]-days[0]+1)
,'支撑总次数':np.zeros(days[1]-days[0]+1)
,'压力成功率':np.zeros(days[1]-days[0]+1)
,'压力成功次数':np.zeros(days[1]-days[0]+1)
,'压力总次数':np.zeros(days[1]-days[0]+1)
})
result = result.set_index('MA')
for data in datas:
data_len = len(data) # 数据长度
for day in range(days[0],days[1]+1):
# 计算均线
ma = data.rolling(day).mean()
'''
计算金叉和死叉,金叉用于计算压力,死叉用于计算支撑
金叉计算逻辑
cmp: F F F T T T F F F
(~cmp).shift(1): T T T F F F T T T
golden_idx: F F F T F F F F F
'''
cmp = data > ma * 0.97 # 有时不触及均线也会有支撑和压力,但不会有金叉和死叉,所以要适当抬高或降低均线
golden_idx = cmp & (~cmp).shift(1)
cmp = data > ma * 1.03 # 计算死叉,抬高均线
death_idx = ~cmp & cmp.shift(1)
# 转成索引
golden_idx = golden_idx[golden_idx].index
death_idx = death_idx[death_idx].index
# 把长度加进总数里
result.loc[day,['压力总次数']] += len(golden_idx)
result.loc[day,['支撑总次数']] += len(golden_idx)
'''
设置参考天数,用于判断后续涨跌
如果均线小于等于5天,则用后2天判断
如果均线大于5天,则n天均线准确率用后n/2天的涨势判断
'''
pre_day = 2 if day <=5 else int(day/2)
'''
支撑成功判断:死叉当天到后续pre_day天计算回归,斜率大于0
死叉成功判断:死叉当天到后续pre_day天计算回归,斜率大于0
'''
for idx in golden_idx:
if idx >= data_len-1:
result.loc[day,['压力总次数']] -= 1
continue # 位置太靠后,没有结果参考,跳过
if data_len-idx < pre_day:
pre_day = data_len-idx # 后续数据不足以参考天数,改为用后面剩的几天判断
y = data[idx:idx + pre_day + 1]
x = range(1,len(y)+1)
k,b = np.polyfit(x,y,deg=1) # 线性回归预测
if k < 0:
result.loc[day,['压力成功次数']] += 1 # 小于0则说明均线有压力
for idx in death_idx:
if idx >= data_len-1:
result.loc[day,['支撑总次数']] -= 1
continue # 位置太靠后,没有结果参考,跳过
if data_len-idx < pre_day:
pre_day = data_len-idx # 后续数据不足以参考天数,改为用后面剩的几天判断
y = data[idx:idx + pre_day + 1]
x = range(1,len(y)+1)
k,b = np.polyfit(x,y,deg=1) # 线性回归预测
if k > 0:
result.loc[day,['支撑成功次数']] += 1 # 小于0则说明均线有压力
result['压力成功率'] = round(result['压力成功次数']/result['压力总次数'],4) # 更新一次结果
result['支撑成功率'] = round(result['支撑成功次数']/result['支撑总次数'],4) # 更新一次结果
os.system('cls')
max = result.idxmax()
max_support = result['支撑成功率'].max()
max_presure = result['压力成功率'].max()
print(tabulate(result.head(15), headers='keys', tablefmt='psql'),flush=True)
print('当前最优值',flush=True)
print('支撑\t','MA {}\t'.format(max['支撑成功率']),max_support,flush=True)
print('压力\t','MA {}\t'.format(max['压力成功率']),max_presure,end='',flush=True)
result.to_csv('最优均线.csv',encoding='utf-8-sig')
效果展示,以5到30天均线搜索为例