“深度学习刷 SOTA 有哪些 trick?”,此问题在知乎上有超 1700 人关注,浏览量超 32 万,相信是大家都非常关心的问题,快一起看看下面的分享吧,希望可以帮助到大家~
对于图像分类任务,让我们以 Swin-Transformer 中使用到的 trick 为例,简单梳理一下目前深度学习中常用的一些 trick:
Stochastic Depth
这一方法最早在 Deep Networks with Stochastic Depth 一文中被提出,原文中被称为 stochastic depth。在 EfficientNet 的实现中被 Google 称为 drop connect。因为和 DropConnect 撞名,在 timm 的实现中又被改名为 drop path(但是这个名字也和 DropPath 撞名了,尴尬)。因此大家听到这几个名词的时候最好注意区分一下到底是哪个。
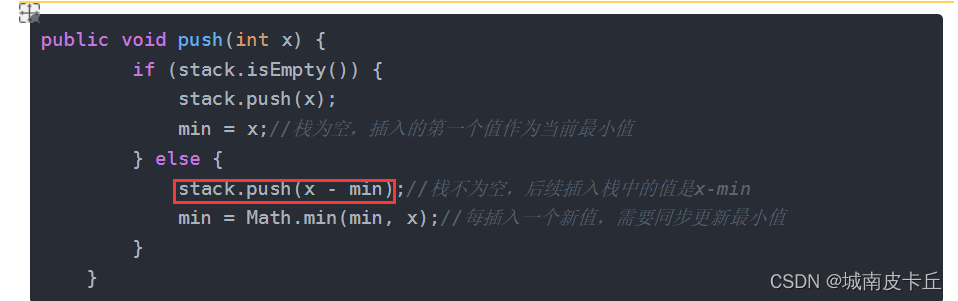
stochastic depth 类似于 dropout,但又有所不同。简单来说 dropout 在训练时随机地抛弃了一部分激活值,而 stochastic depth 则直接抛弃了一部分样本,即将这些样本的值设为零。因此这一方法一般只能放在残差结构中,将网络输出中的一部分样本直接抛弃,再与 shortcut 相加,从而实现部分样本 “跳过” 这一残差结构的效果。
通过跳过部分残差结构,实际上起到了多种深度网络组合的效果,类似集成学习,从而提高网络的性能。
Mixup & CutMix
二者都是图像混合增强手段,即在训练时,我们将两个样本按照某种方式进行混合,并相应地混合它们的标签。其中 Mixup 和 CutMix 的区别就在于按照什么方式对图像进行混合。
这种图像混合增强的目的是使图像经过神经网络映射后嵌入的低维流形变得平滑,从而提高网络的泛化能力。
关于图像混合增强手段的详细介绍参见 https://zhuanlan.zhihu.com/p/436238223
RandAugment
这是一种组合数据增强手段,相比传统数据增强的随机裁剪、随机翻转,这种方法设置了一个包含各种数据增强变换的集合,并对每个样本随机应用其中若干个增强,大大扩展了增强后的图像空间。
关于 RandAugment 的详细介绍参见 https://zhuanlan.zhihu.com/p/436238223
RandomErasing
这一方法出自 Random Erasing Data Augmentation,其核心思想十分简单,随机选择并填充图像中的一块区域。它模拟了实际任务中需要识别的目标可能被物体遮挡的情况,从而提高模型的泛化能力
CosineAnnealingLR
Cosine 学习率衰减,在近期的图像分类任务中是最主流的学习率衰减方法。大家都知道衰减学习率可能让网络在前期以较高的学习率帮助网络找到最优解,在后期以较低的学习率使网络最终收敛于最优解。虽然现在的优化器,如 Adam 拥有参数自适应学习率的能力,但通过衰减学习率限制优化器的优化步幅往往仍然是必要的。
而 cosine 学习率衰减提供了一种平滑的学习率衰减曲线,其公式如下:

Weight decay
Weight decay 是一种正则化方法,它通过将网络参数的 L2 范数加入 loss 的一部分,限制了网络中部分参数的范围。过大的个别参数可能会导致网络仅依赖这些参数,从而使网络 “变窄”,影响其泛化能力。
以上 trick 均在 MMClassification 的 swin-transformer 配置文件中使用。
欢迎参考 https://github.com/open-mmlab/mmclassification/tree/master/configs/swin_transformer 使用 MMClassification 和这些 trick 来提升网络性能。
本文内容首发于:https://www.zhihu.com/question/540433389/answer/2629056736)