ElasticSearch概述
ElasticSearch(简称 ES) 是一个分布式的使用 REST 接口的搜索引擎,属于非关系型数据库。它是在 lucene 的基础上进行研发的,隐藏了 lucene 的复杂性,提供简单易用的 RESTful Api接口。ES 的分片相当于 lucene 的索引。ES属于Elastic 公司,该公司同时拥有 Logstash 及 Kibana。这个三个项目组合在一起,就是大名鼎鼎的 ELK 。简单地说,Logstash 负责数据的采集,处理,Kibana 负责数据展示,分析,管理,监督及应用。ES 是ELK的核心,它可以帮我们对数据进行快速地搜索及分析,本文将对ElasticSearch的核心概念做重点介绍,来帮助刚刚上手ES的同学快速入门。ES、Logstash以及Kibana三者的关系如下图所示:
文档(Document)
ES是面向文档的,文档是所有可搜索数据的最小单位。
以下内容都属于文档
日志文件中日志项
一首歌、一篇 PDF 文档、一个网页
一条订单数据
分片(Shard)
由于单台机器无法存储大量数据,ES 可以将一个索引中的数据切分为多个分片(Shard),分布在多台服务器上存储。有了分片就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。
分片分为主分片(Primary Shard)和副本分片(Replica Shard)。
主分片主要用以解决水平扩展的问题,通过主分片,就可以将数据分布到集群上的所有节点上,一个主分片就是一个运行的 Lucene 实例,当我们在创建 ES 索引的时候,可以指定分片数。
副本分片用以解决数据高可用的问题,也就是说集群中有节点出现硬件故障的时候,通过副本的方式,也可以保证数据不会产生真正的丢失,因为副本分片是主分片的拷贝,在索引中副本分片数可以动态调整,通过增加副本数,可以在一定程度上提高服务查询的性能。
索引(Index)
索引简单来理解就是结构文档的集合,一个索引就代表了一类类似的或者相同的文档,建立一个用户索引,里面可能就存放了所有的用户数据,也就是所有的用户文档。在一个索引中包括: Mapping 和 Setting,Mapping 定义的是索引当中所有文档字段的类型结构,Setting 主要是指定要用多少的分片以及数据是怎么样进行分布的。
映射(Mapping)
类似于关系数据库中的表定义
字段(Field)
类似于关系数据库中的字段(column)
类型(Type)
在 ES 7.0 之前,每一个索引是可以设置多个 Types。例如一个短视频系统,一个索引,可以定义用户数据 Type,短视频数据 Type,评论数据 Type 等。从 7.0 开始,一个索引只能创建一个 Type
节点(Node)
节点其实就是一个 ES 实例,本质上是一个 Java 进程,一台机器上可以运行多个 ES 进程,但是生产环境一般建议一台机器上只运行一个 ES 实例。
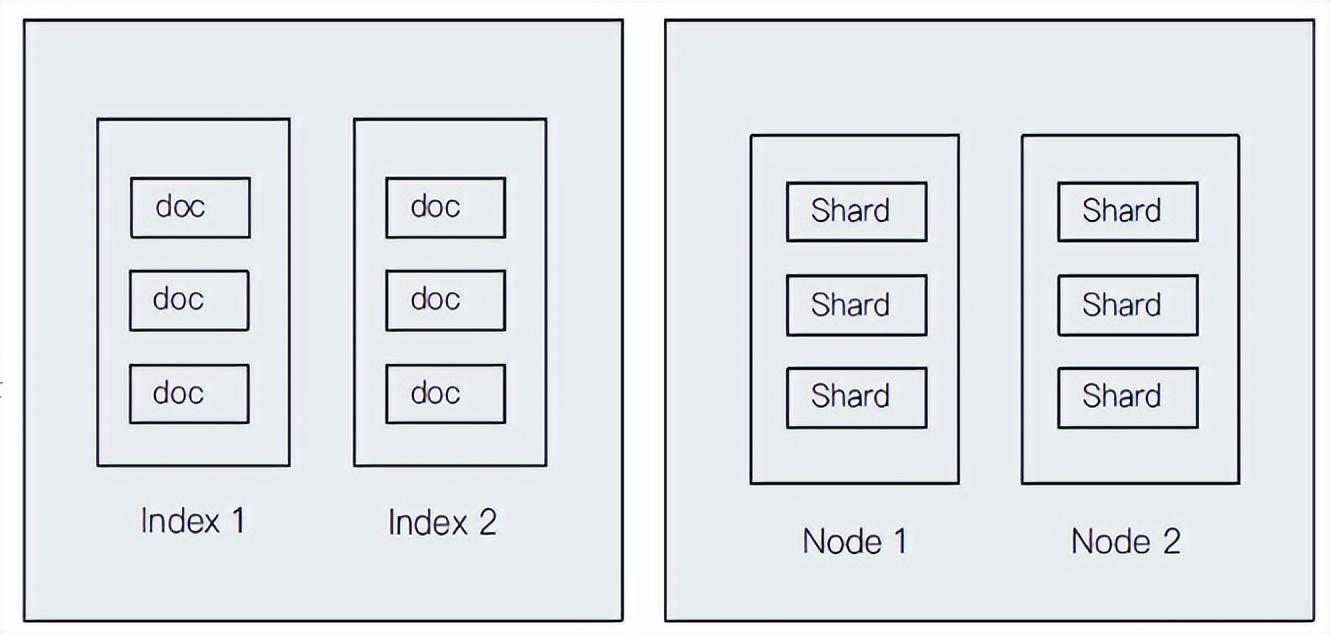
文档和索引以及节点和分片的关系
索引和文档是偏向于逻辑上的概念,节点和分片更偏向于物理上的概念。
集群(Cluster)
ES 通过集群保证高可用,一个集群中可以有一个或者多个节点,用三种颜色来表示集群健康程度:
Green:主分片与副本都正常分配
Yellow:主分片全部正常分配,有副本分片未能正常分配
Red:有主分片未能分配(例如,当服务器的磁盘容量超过 85% 时,去创建了一个新的索引)
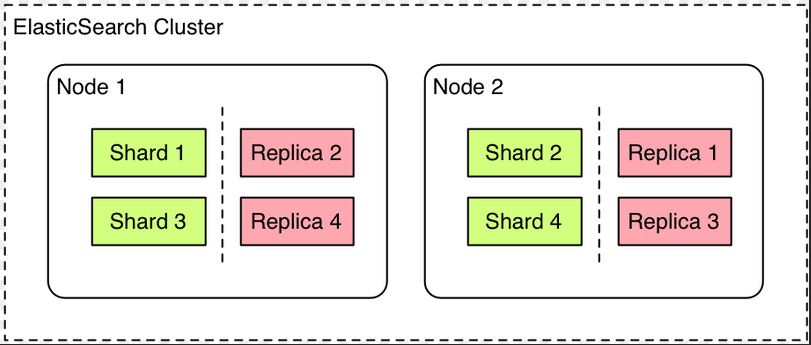
下图就是一个基础的ES集群,可以看到shard 和其对应的replica都保存在不同的node上,这样保证了一个node不可用,另一个node可以正常工作。
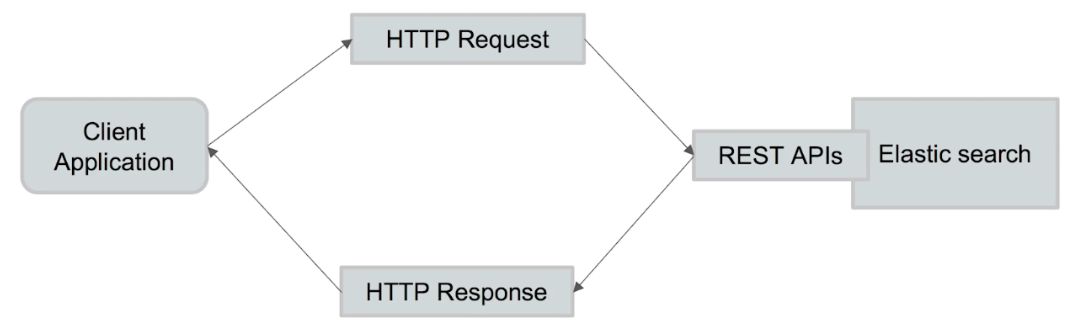
REST API
可以通过REST API来对ES进行增删改查相关操作
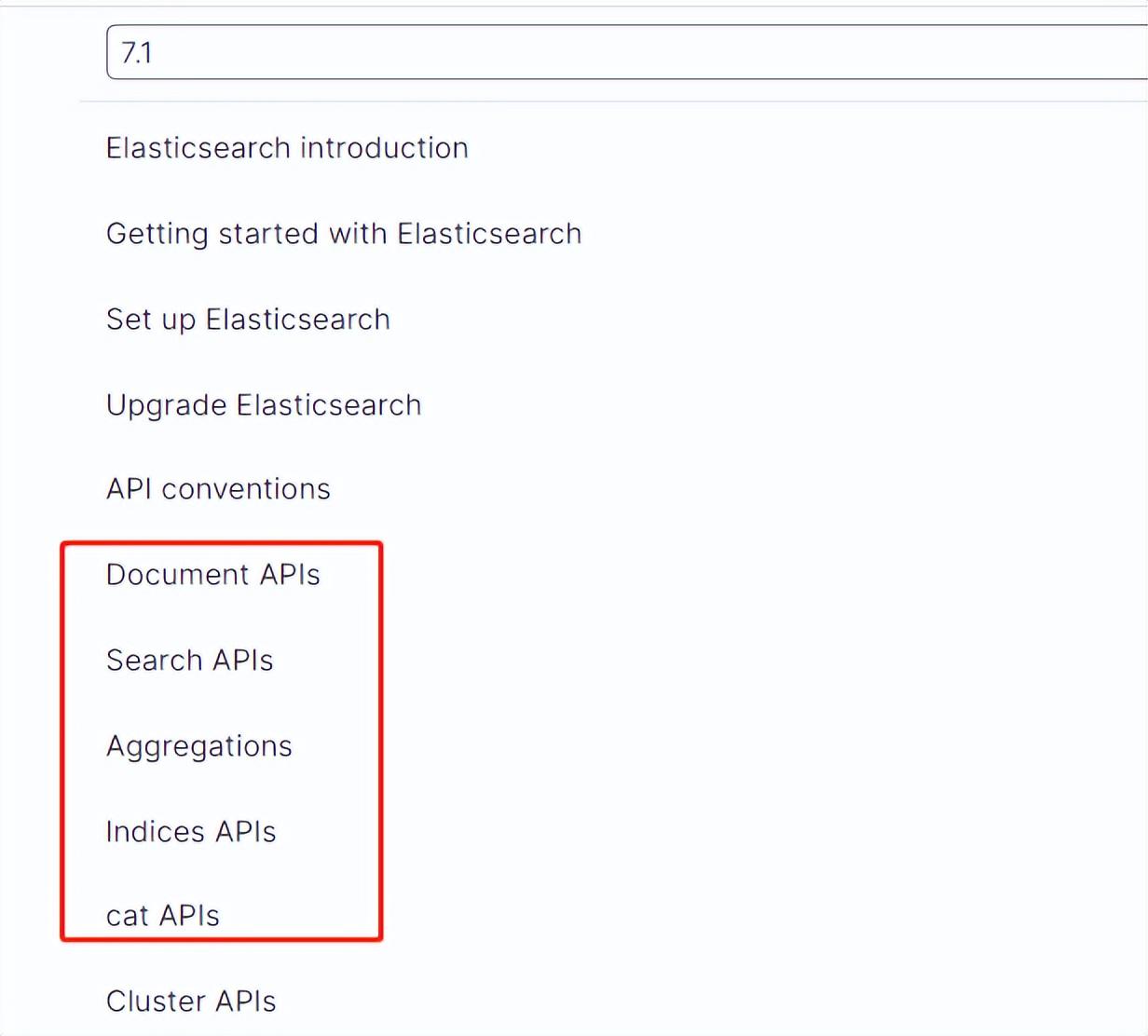
具体rest api链接如下:
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/index.html
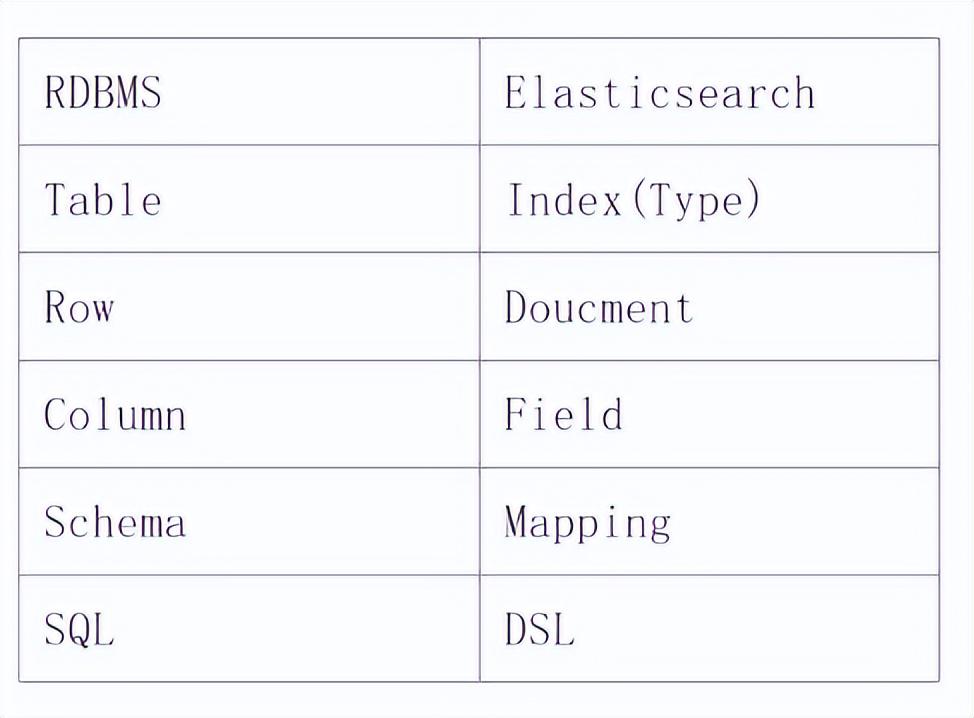
ES和RDBMS区别
区别如下图:
备注:从 7.0 开始,一个索引只能创建一个 Type。