目录
- 说明
- 使用
- 布隆过滤器使用测试
- Java 本地使用布隆过滤器
- Java集成Redis使用布隆过滤器
说明
布隆过滤器是用来防止缓存穿透的,我们需要知道如何使用布隆过滤器。
使用
Google 的 Guava 库提供了使用布隆过滤器的 API 类(BloomFilter.class),它是线程安全的。
首先创建布隆过滤器:
//创建存储整型的布隆过滤器
bloomFilter =
BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
创建布隆过滤器的方法有以下几个入参:
| 入参 | 说明 |
|---|---|
| Funnels 实例 | 用于后续把类对象转换为相应的 hash 值 |
| expectedInsertions | 期望插入过滤器的元素个数 |
| fpp | 误识别率,该值必须大于 0 且小于 1.0 |
Funnel 类定义了如何把一个具体的对象类型分解为原生字段值,从而将值分解为 Byte 以供后面 BloomFilter 进行 hash 运算。也就是说 Guava 的布隆过滤器会根据Funnel 类的定义,计算一个对象的哈希值,放入过滤器。
Guava 官方提供了这样一个创建可插入自定义类的布隆过滤器示例。
首先创建一个 Person 类:
@Data
@AllArgsConstructor
public class Person {
private String firstName;
private String lastName;
private int age;
}
然后创建一个 PersonFunnel 类,它实现了 Funnel 类中的 funnel(Person from, PrimitiveSink into) 方法:
public class PersonFunnel implements Funnel<Person> {
@Override
public void funnel(Person from, PrimitiveSink into) {
into.putUnencodedChars(from.getFirstName()).putUnencodedChars(from.getLastName()).putInt(from.getAge());
}
}
这个方法主要是把 Person 类中的各个属性(名字、年龄)写入 PrimitiveSink 对象。 PrimitiveSink 提供了支持各种写入类型的方法:
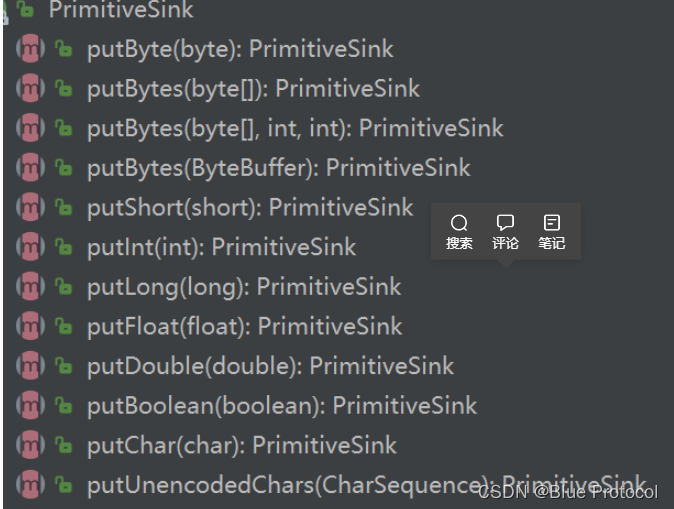
接着把元素放入布隆过滤器:
bloomFilter.put(new Person("deniro","lee",20));
bloomFilter.put(new Person("lily","lee",16));
Funnels 是个工具类,内置了一些创建基本类型的 Funnel:
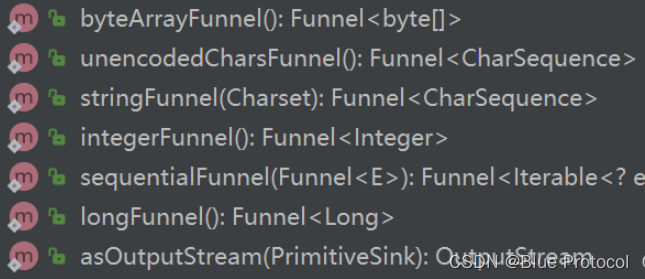
我们可以利用这些 Funnel,来创建包含基本类型元素的布隆过滤器,比如创建一个包含整型元素的布隆过滤器:
BloomFilter<Integer> bloomFilter =
BloomFilter.create(Funnels.integerFunnel(), size, fpp);
布隆过滤器使用测试
Java 本地使用布隆过滤器
引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
测试
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000000;
/** 误判率 */
private static Double fpp = 0.01;
/** 布隆过滤器 */
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
public static void main(String[] args) {
// 插入 1千万数据
for (int i = 0; i < expectedInsertions; i++) {
bloomFilter.put(i);
}
// 从10000000开始,用1千万数据测试误判率
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions *2; i++) {
if (bloomFilter.mightContain(i)) {
count++;
}
}
System.out.println("一共误判了:" + count);
}
}
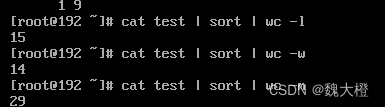
测试结果:
// 大概是expectedInsertions(1千万)的0.01,这与我们设置的 p = 0.01非常接近。
一共误判了:100055
参数说明:
在guava包中的BloomFilter源码中,构造一个BloomFilter对象有四个参数:
- Funnel funnel:数据类型,由Funnels类指定即可
- long expectedInsertions:预期插入的值的数量
- fpp:错误率
- BloomFilter.Strategy:hash算法
通过断点BloomFilter类中的构造函数,发现我们调整expectedInsertions和误判率p时,位数组BitArray的大小m(numBits)和Hash函数的个数k(numHashFunctions)都会自适应变化;
Java集成Redis使用布隆过滤器
Redis经常会被问道缓存击穿问题,比较优秀的解决办法是使用布隆过滤器,也有使用空对象解决的,但是最好的办法肯定是布隆过滤器,我们可以通过布隆过滤器来判断元素是否存在,避免缓存和数据库都不存在的数据进行查询访问;在如下的代码中只要通过bloomFilter.contains(xxx)即可,我这里演示的还是误判率;
引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.0</version>
</dependency>
测试:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedisBloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000;
/** 误判率 */
private static Double fpp = 0.01;
public static void main(String[] args) {
// Redis连接配置,无密码
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.211.108:6379");
// config.useSingleServer().setPassword("123456");
// 初始化布隆过滤器
RedissonClient client = Redisson.create(config);
RBloomFilter<Object> bloomFilter = client.getBloomFilter("user");
bloomFilter.tryInit(expectedInsertions, fpp);
// 布隆过滤器增加元素
for (Integer i = 0; i < expectedInsertions; i++) {
bloomFilter.add(i);
}
// 统计元素
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions*2; i++) {
if (bloomFilter.contains(i)) {
count++;
}
}
System.out.println("误判次数" + count);
}
}