档案圈的朋友想必对档案领域的“归档”一词已经耳熟能详,按照DA/T 58-2014《电子档案管理基本术语》中的定义,归档(Archiving)是指“按照国家规定将具有保存价值的电子文件及其元数据的保管权交给档案部门的过程”。
今天我们要聊的不是档案领域的“归档”,而是IT领域(更加准确的说是数据存储领域)的“归档”,中文完全一样,英文稍有区别。根据全球网络存储工业协会(Storage Networking Industry Association,SNIA)在《网络存储双语词典》中的定义,归档(Archive)是指“数据集合的一致性拷贝,通常用以长期持久地保存事务或者应用状态记录”,而数据归档(Data Archiving)是“将不再经常使用的数据移到一个单独的存储设备来进行长期保存的过程”。这显然和档案领域的“归档”完全不是一回事。
“归档概述”
OVERVIEW
为什么需要对数据进行归档操作呢?一方面是因为现在已经进入数据爆炸的时代,以数据库文件、电子表格文件、多媒体文件、数据元、数据体、数据集、模型等形式存在的数字资源形式越来越多,伴以存储类型复杂,对存储系统的要求也越来越高。另一方面,在各级单位日常存储设备中80%以上的数据是不会被经常访问的,这些数据严重影响了系统的运行效率,同时还给单位的日常运营带来了巨大的成本负担;同时,虽然这些数据不常用,但却很重要,绝对不能让其遭受损失。因此如何科学有效地存储、管理、开发和利用这部分数字资源,使之发挥最大价值,这是当前存储技术发展过程中亟待研究解决的重要问题。数据归档正是在这样的背景下被提出来的,目的是要把这些需要长期存储却又不会被经常访问的数据迁移到更经济、合理的存储载体上,同时确保迁移出去的数据的完整性、安全性和可访问性,从而简化存储管理,降低系统的整体拥有成本(TCO)

一般情况下,归档通常用以审计和分析的目的,而不是用于数据恢复的目的。也就是说,归档是为参考而创建的数据副本。另外,出于节约存储空间的考虑,数据在归档后通常会删除原件。数据归档由旧的数据组成,但这些旧数据是以后参考所必需且很重要的数据,必须遵从规则来保存。数据归档具有索引和搜索功能,这样归档数据可以很容易地被找到。这些正是归档和备份的主要区别所在。

数据归档时,首先要对数据进行整理,确定数据属性,然后通过归档软件将数据拷贝(或刻录)到光盘、磁盘或者磁带上,也可以存储在云端服务器上。当确认数据需要归档时应做到以下几点:
1
首先确定归档的范围,在实际应用环境下,需要归档的数据一般存在两种情况,即历史数据和超容量数据,历史数据主要是一些需要长期保存的数据,超容量数据则是因为存储系统容量有限,而数据不断增加,这样就需要将不常用的数据从主存储系统中迁移出去。
2
做好所归档的分类,确定归档数据的分类标志,就是将归档的数据按文件大小、最后修改时间、文件类型、所属部门、关键字等进行分类。
3
确定所归档数据的时间和份数,就是确定在什么时候进行一次归档,一般归档的时间都是定期的,如果是超容量的数据归档,那么就要根据实际情况,另外还可以根据任务性质来确定归档时间。
“归档机制”
MECHANISM
通过有效评估数据以及用户访问数据的频率,掌握什么样的数据应该存放在读取速度较快的载体或设备中,什么样的数据应该被放置在响应速度较慢的载体或设备中。这个过程是动态的,随着用户需求的变化而不断变化。数据归档会在响应速度快或慢的载体或设备之间进行动态调整。因此,我们可以将数据归档视作一个智能化流程,它将不活跃的、很少被访问的,但有业务价值的数据进行搬迁,并提供查询和找回这些数据的能力。
采用分散采集、集中处理、集中交换、集中管理、全局应用的建设思路,把来自不同来源、不同存储方式、不同格式和不同质量的业务源数据,根据数据特点及时采集,对数据文件进行解析,从而确定归档的方式。考虑到数据量非常大,在归档时也可以采取压缩的方式,特别是对一些数据容量特别大的场景来说,这种方式比较合适,就是将经过整理的数据进行压缩,然后存入磁盘、光盘、磁带、固态硬盘等载体或设备中,有效减少存储空间,而且还增强了数据的保密性。当然,数据压缩之后对于直接查找和阅读都会带来困难,有时候为了查找一个文件,需要对整个压缩包进行解压,但是这样做也就相应地压缩了归档数据对存储空间的占用,并提高了数据的安全性。
和数据备份工作一样,数据归档工作也是一个专业性很强同时需要常规执行的工作,需要借助专业的备份工具来完成数据归档过程。如果说合理的备份方案应该是数据一旦受到破坏而能使影响降至最低,并最大限度地减少各类数据丢失的风险,那么数据归档就是在各需求单位实施备份方案后进一步对数据的梳理,以降低数据存储成本,确保数据安全。所以备份是前提,归档是提升。
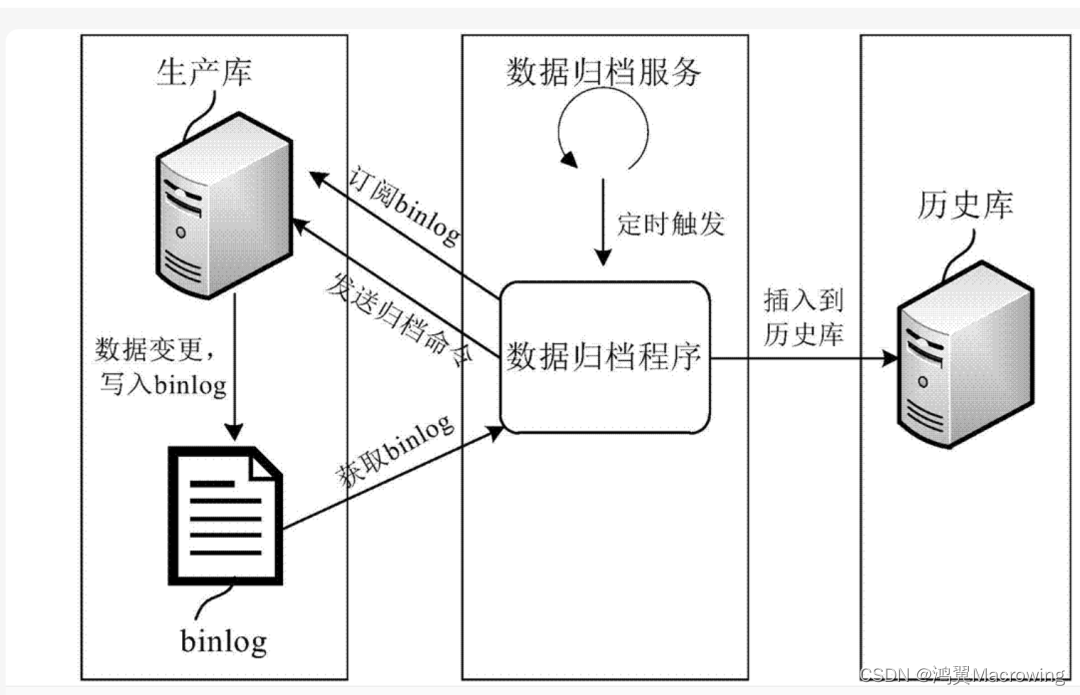
“关键问题”
CRITICAL PROBLEMS
虽然随着数据量的不断膨胀,数据归档的需求正在逐步崛起,但是摆在我们面前的难题其实还有很多。其中最主要的有两个难点:长期保存和法规遵从。数据长期保存需求远远超过存储管理软件和存储载体的寿命。比如,对于要求长期保存50年以上的数据,存储载体的寿命可能只有10年,存储环境(软硬件设备)的寿命可能只有5年。这就使数据归档工作变得更加困难,不仅仅是在物理上要保持数据的完整性,而且还要在逻辑上保持数据的可读性和可理解性。在法规遵从方面,随着越来越多的数据采用数字方式进行记录和存储,制定用以管理数据的相关法律法规越来越多,未能遵从这些法规而造成的后果也变得越来越严重。除必须遵从政府的法律法规之外,各单位还需要制定自己的内部政策和规程,层层的法规遵从也给数据归档增加了难度。
SNIA调查得出的结论是:“绝大部分人希望数据保存50年甚至100年”,那么有没有什么方法,既可以长期保存数据,又可以增加容量,还能快速读取数据呢?SNIA长期归档和法规遵从存储计划(LTACSI)主席Gary Zasman 给出的建议是:针对操作系统、应用程序及数据存储库实施信息生命周期管理流程(Information Lifecycle Management,ILM),以在数据的生命周期中解决数据管理的效率问题,根据数据访问频次的不同,将其存储在不同的载体之上。
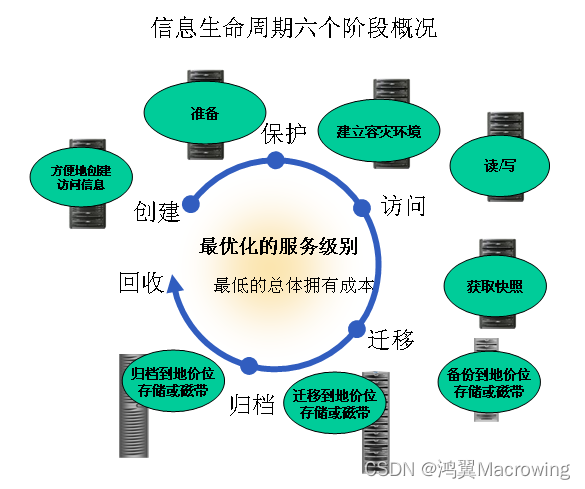
通常意义上,我们可以将数据分为三类:经常被访问并且需要快速响应的数据(热数据);访问比较频繁但访问速度要求不高的数据(温数据);很少查询或访问但需要长期保存的数据(冷数据)。从存储的角度,我们可以将这三种数据分为在线数据、近线数据和离线数据。
在线数据可以在网络中提供对数据信息的即时访问,以保证业务系统的快速处理。在线数据要求随时能支持生产、运行、更新等各种活动,此类数据需要备份但不涉及归档。近线数据需要定期对访问频率和访问速度要求不高的数据采用灵活归档方式保存,通过这种方式,可以实现较为及时的、并且成本较低的数据访问。归档存储载体及设备(比如蓝光光盘和光盘库)的成本要比在线存储成本(比如固态硬盘和存储阵列)低很多,数据访问的速度要慢一些,也不能随时更新非活动数据。
离线数据针对那些访问速度要求很低、存储时间长、访问频率更低的数据,可以将其打包归档存放在成本更低、容量更大的存储载体和设备中,比如磁带、光盘、胶片等等,当数据需要被访问时,才将其恢复到在线存储设备中。因此,通过数据归档是将大量不被经常访问但需要长期保存的数据迁移至大容量、低成本的载体上,为新的数据存储腾出空间,从而减少了数据备份量并提高了存储资源的利用率。