8.3 Spark Shuffle
首先回顾MapReduce框架中Shuffle过程,整体流程图如下

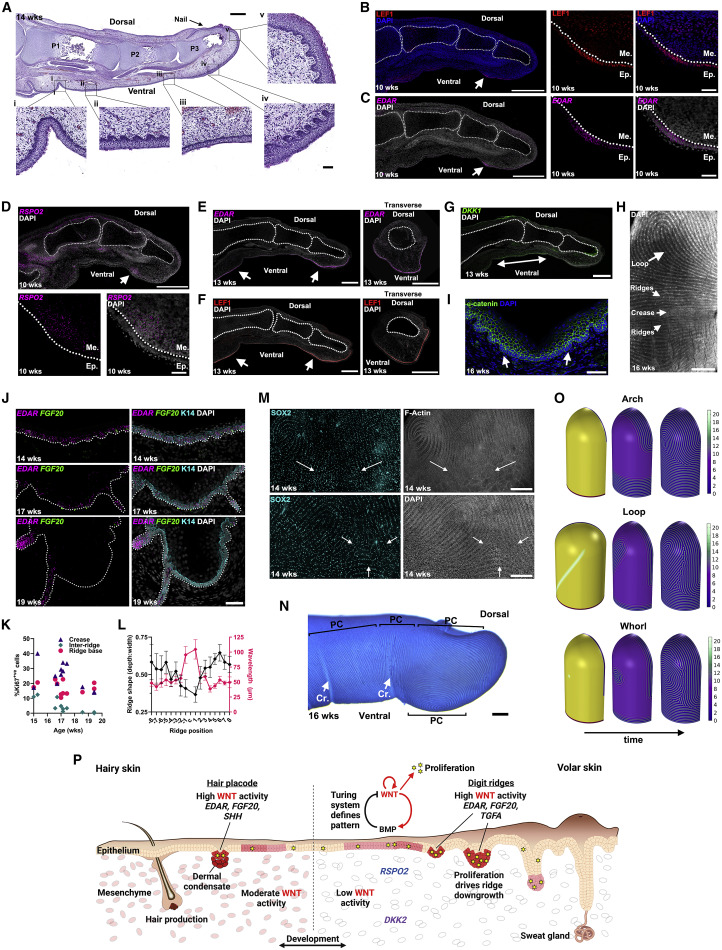
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等。
 Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。
执行Shuffle的主体是Stage中的并发任务,这些任务分ShuffleMapTask和ResultTask两种,ShuffleMapTask要进行Shuffle,ResultTask负责返回计算结果,一个Job中只有最后的Stage采用ResultTask,其他的均为ShuffleMapTask。如果要按照map端和reduce端来分析的话,ShuffleMapTask可以即是map端任务,又是reduce端任务,因为Spark中的Shuffle是可以串行的;ResultTask则只能充当reduce端任务的角色。
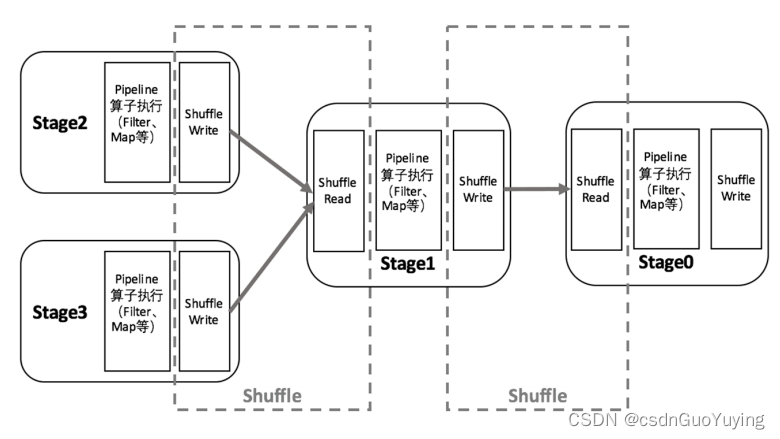
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式,到1.1版本时参考Hadoop MapReduce的实现开始引入Sort Shuffle,在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用,在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式,到的2.0版本,Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。
具体各阶段Shuffle如何实现,参考思维导图XMIND,大纲如下:

8.4 Job 调度流程
Spark Application应用的用户代码都是基于RDD的一系列计算操作,实际运行时,这些计算操作是Lazy执行的,并不是所有的RDD操作都会触发Spark往Cluster上提交实际作业,基本上只有一些需要返回数据或者向外部输出的操作才会触发实际计算工作(Action算子),其它的变换操作基本上只是生成对应的RDD记录依赖关系(Transformation算子)。
当启动Spark Application的时候,运行MAIN函数,首先创建SparkContext对象(构建DAGScheduler和TaskScheduler)。
第一点、DAGScheduler实例对象
- 将每个Job的DAG图划分为Stage,依据RDD之间依赖为宽依赖(产生Shuffle)
第二点、TaskScheduler实例对象 - 调度每个Stage中所有Task:TaskSet,发送到Executor上执行

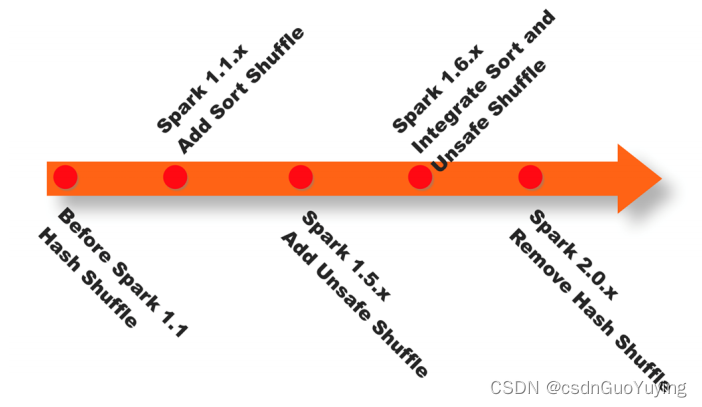
当RDD调用Action函数(比如count、saveTextFile或foreachPartition)时,触发一个Job执行,调度中流程如下图所示:

Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。 - 1)、DAGScheduler负责Stage级的调度,主要是将DAG切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
- 2)、TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。
Spark的任务调度总体来说分两路进行,一路是Stage级的调度,一路是Task级的调度。
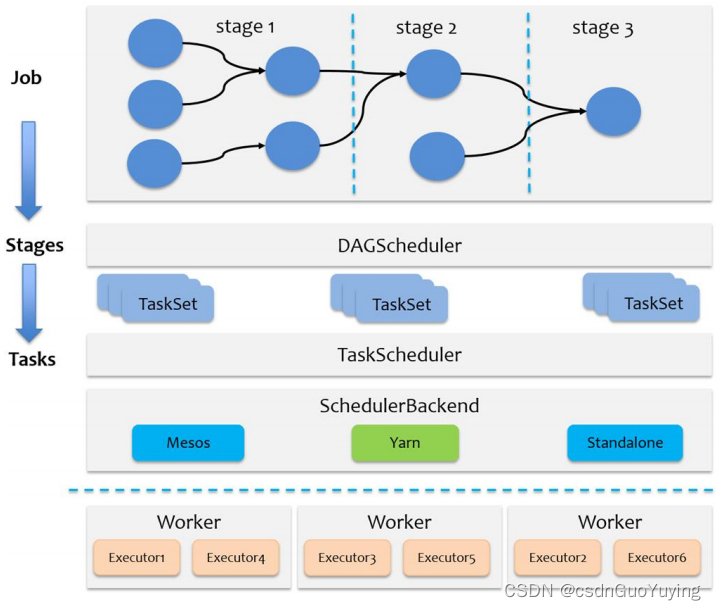
一个Spark应用程序包括Job、Stage及Task:
- 第一:Job是以Action方法为界,遇到一个Action方法则触发一个Job;
- 第二:Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
- 第三:Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。








![字母板上的路径[提取公共代码,提高复用率]](https://img-blog.csdnimg.cn/dcdc077c29f14c2cac0d898ace0b53ae.png)